
Comment monitorer mon Kubernetes ?
Durant ces dernières années, les conteneurs se sont imposés dans nos infrastructures, rapidement suivis par la nécessité de gérer les conteneurs par des orchestrateurs, puis des gestionnaires de packages, puis…

Sommaire
Dans cette transformation, un point à ne pas oublier concerne le monitoring de toutes ces nouveautés.
Dans cet article, nous allons traiter du monitoring, qui consiste à remonter des métriques et des alertes et non du problème de centralisation des logs.
Problématique
Un des premiers problèmes, lorsque l’on parle de monitorer un écosystème de conteneurs est la dynamique des objets. Ce qui fait la grande force de la solution est un vrai problème pour les solutions de monitoring historiques qui font une indexation statique des métriques.
Dans notre cas on aurait besoin d’une solution qui permet de :
- monitorer les VMs ou des serveurs sur lesquels tournent Kubernetes
- monitorer Kubernetes
- monitorer chaque conteneur lancé
- monitorer les éléments existant en dehors de Kubernetes
- agréger / requêter / obtenir les métriques
- lever des alertes sur des remontées de métriques
- visualiser ces informations sur un dashboard user friendly (ou presque)
- intégrer les métriques de vos applications
Solutions du marché
Pour répondre à ces problématiques, je vais vous présenter dans ce chapitre deux solutions du marché. J’approfondirai dans les chapitres suivants l’une d’entre elles.
DataDog
Une solution payante qui permet à la fois de résoudre vos problématiques de monitoring et propose également une solution d’APM (Application Performance Management) pour analyser vos applications. Il peut donc remplacer un produit comme AppDynamics en faisant de l’introspection de code pour vous afficher le temps passé dans chacune de vos fonctions.
Un de ses points forts est une gestion participative de l’analyse des informations, chaque membre peut commenter un schéma (ou une partie) pour garder une trace ou pour débattre d’un possible problème.
Par exemple, si vous constatez une augmentation de la charge d’une de vos applications, vous pouvez lancer un débat directement sur Datadog au lieu d’envoyer une capture d’écran par email, réfléchir à qui mettre en copie…
Il propose un large choix de technologies permettant de monitorer toutes vos applications et infrastructure.
Prometheus
Une solution gratuite qui offre de nombreux outils de gestion de vos métriques.
Prometheus ne gère pas (ou très peu) l’affichage des données, l’interface est très simpliste et ne peut servir qu’à apprendre l’utilisation de ses APIs. Il nécessite donc l’ajout d’une interface pour être utilisable.
La recommandation de Prometheus est également de ne pas stocker les données au delà du temps maximum par défaut : 15 jours. Sauf à ne pas respecter cette recommandation, il vous faudra donc également prévoir une base permettant de stocker ces données. Une bonne question à se poser alors est : de quelles données ai-je besoin au delà de ce seuil ?
Zoom sur Prometheus
Parce que c’est la solution gratuite… et OpenSource.
Déploiement
Prometheus peut se déployer intégralement sur votre cluster Kubernetes. Vous pouvez utiliser l’ensemble des conteneurs sur le site de quay.io ou du DockerHub.
Il existe de nombreux exemples de “Deployment” Kubernetes sur internet, l’idée est d’utiliser une “ConfigMap” associée pour déployer le fichier de configuration. L’ajout d’un “Service“ permettra un accès dans ou à l’extérieur de votre cluster.
Vous pouvez d’ailleur utiliser Helm pour le déploiement, ce qui vous facilitera la tâche, ou encore ce projet de CoreOS.
Récupération des données
Pour comprendre comment Prometheus récupère les informations, on peut observer le schéma qu’ils proposent dans leur documentation :

Sur la partie gauche du schéma, on constate que Prometheus Server fait du pulling vers :
- d’autres Prometheus Server dans le cadre de la résilience
- des “exporters”
- une pushgateway
La pushgateway permet à des applications avec une durée de vie très courte de pousser les données vers celle-ci, ces données sont ensuite récupérées par Prometheus.
Il existe de nombreux type d’”exporters”, ils sont déployés sur vos VMs et permettent de remonter des informations (via le pulling du server) spécifiques, pour en citer quelques uns :
- node-exporter : fournit les métriques d’un OS : CPU, RAM, Disque, …
- haproxy-exporter : pour les métriques spécifiques à HAProxy
- mysqld-exporter : pour les métriques spécifiques à MySQL/MariaDB
- consul-exporter
- etc.
Vous pouvez également faire vos propres APIs de métriques en suivant les tutoriels sur le site de Prometheus, une dizaine de langages sont proposés ou en passe de l’être.
Mais… si c’est un système de pulling qui est utilisé, comment Prometheus découvre les services existant ?
Il existe deux systèmes de découverte de services :
- par configuration, vous pouvez indiquer quelles/où sont vos APIs à puller
- par “service discovery”, via Consul, Kubernetes, EC2, DNS, etc.
Sur la partie droite du schéma on constate la présence d’un système d'émission d’alertes via de nombreux canaux grâce à un logiciel “Alertmanager”. Ce dernier répartit les alertes dans les différents canaux qui lui ont été configurés.
Les alertes sont définies et lancées au niveau du Prometheus Server ou directement depuis vos applications vers l’’Alertmanager” via un POST HTTP.
Les alertes doivent être définies dans un des fichiers de configuration de Prometheus, ce qui les rend difficilement dynamiques.
Nous pouvons constater également dans ce schéma la présence d’outils de visualisation, nous y reviendrons.
Requêtage
Les requêtes sont écrites en PromQL, pour Prometheus Query Language, et elles contiennent des clefs, des filtres et des opérateurs.
Par exemple, je souhaite voir le nombre de métriques reçues par appel http :
http_requests_total
puis je veux mettre en place un filtre :
http_requests_total{label1="value1",label2="value2"}
http_requests_total{environment=~"staging|testing|development",method!="GET"}
Comme vous pouvez le constater, il est possible d’appliquer des comparaisons (‘=’ ou ‘!=’ ou …) et des regex.
Vous pouvez préciser la période de résultat :
http_requests_total{label="value"}[5m]
Il existe également de nombreux opérateurs d'agrégation : obtenir le maximum, le minimum, la somme des éléments, etc.
Enfin, des fonctions viennent compléter le langage, parmi lesquelles on va trouver des fonctions retournant le nombre de jours dans un mois ou encore un opérateur nous retournant un histogramme d’un quantile particulier… de quoi répondre à de nombreuses problématiques.
La visualisation des données
À la fin de l’installation de Prometheus, nous avons ce genre de dashboard, fourni par Prometheus :
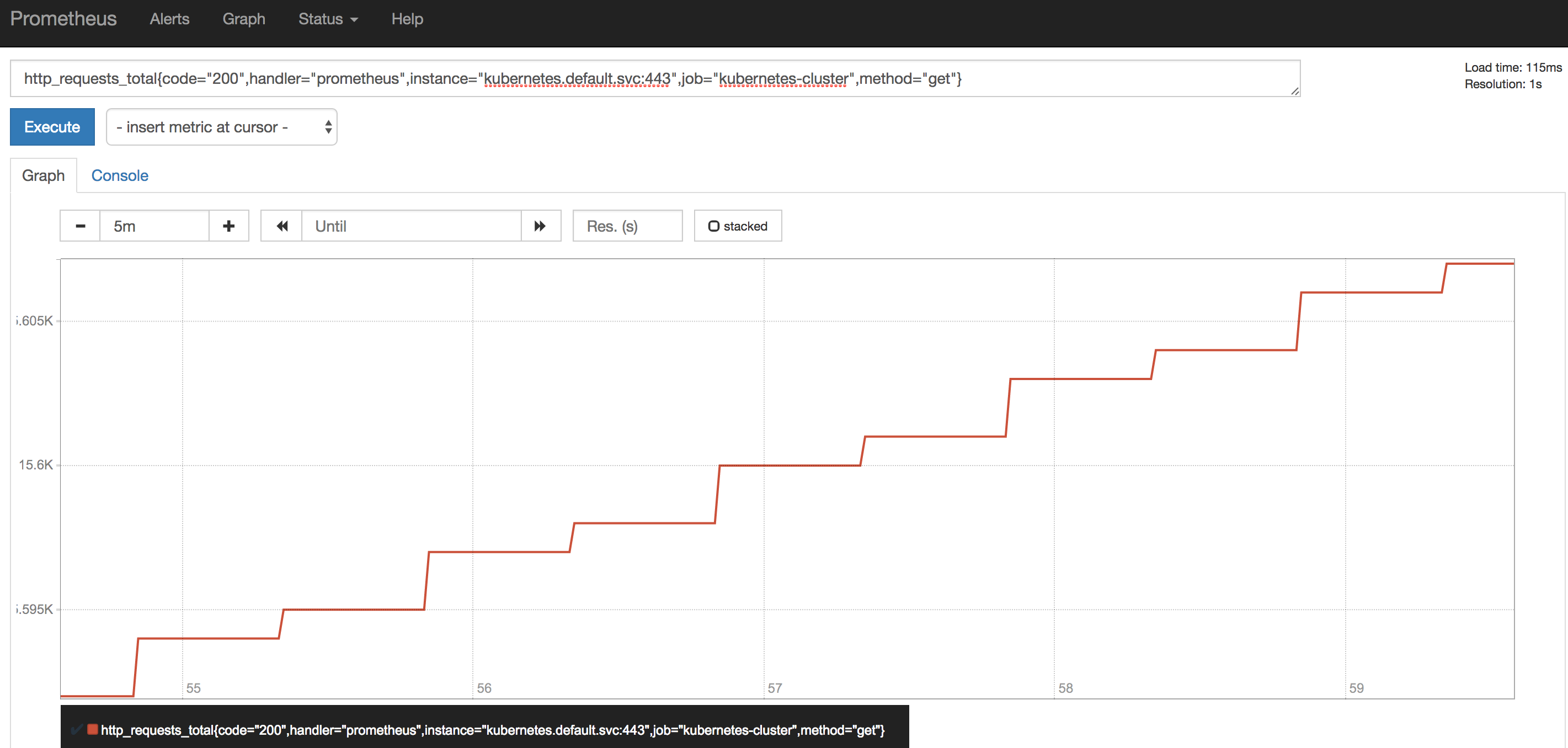
C’est pratique pour apprendre le PromQL et tester nos requêtes mais ce n’est pas forcément praticable pour tous vos utilisateurs.
On va donc mettre en place un Grafana pour avoir des dashboards plus intuitifs et surtout plus user-friendly…
Mais pourquoi Grafana dans cet exemple ? Parce que Grafana implémente en source de données… Prometheus ! C’est donc très pratique à configurer.
Grafana a également une base importante de dashboards prête à être utilisée, ce qui est très pratique au début de votre apprentissage…
Par exemple :
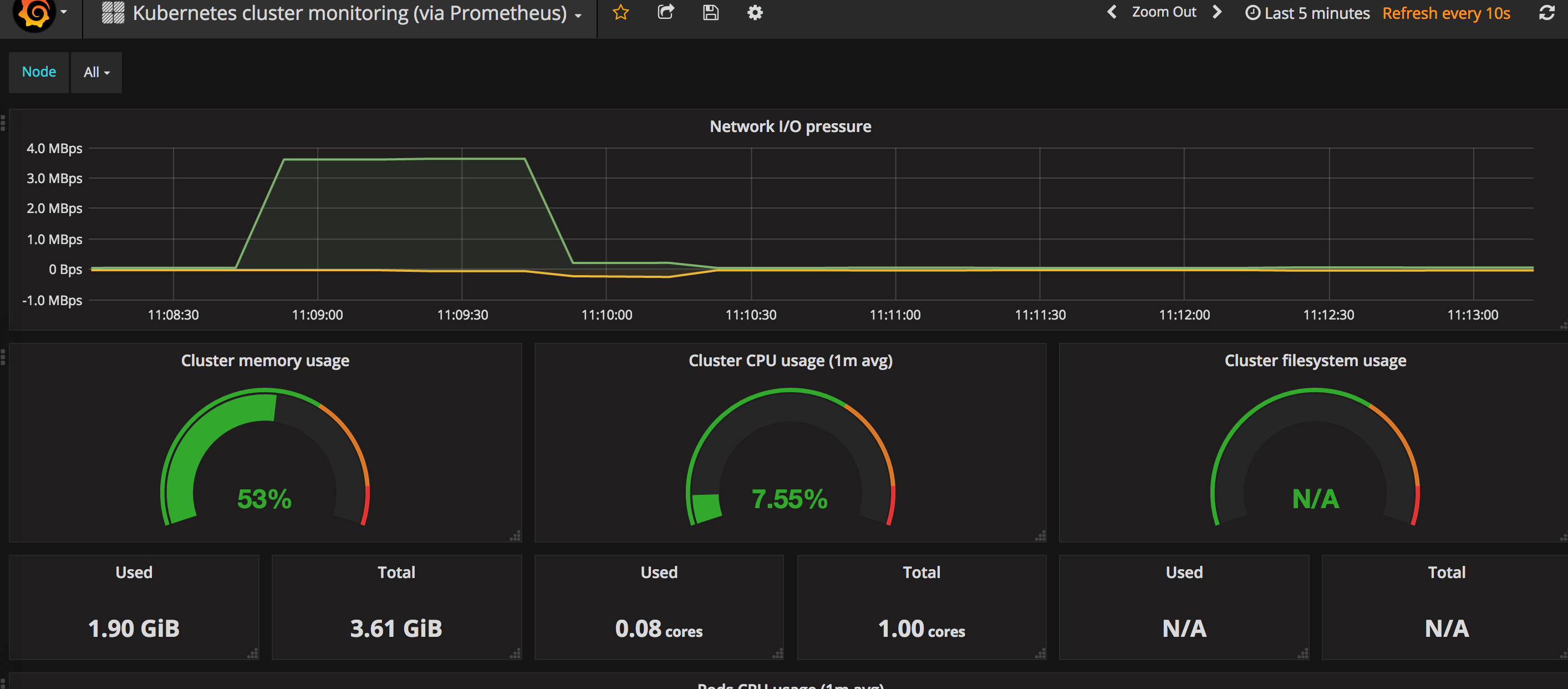
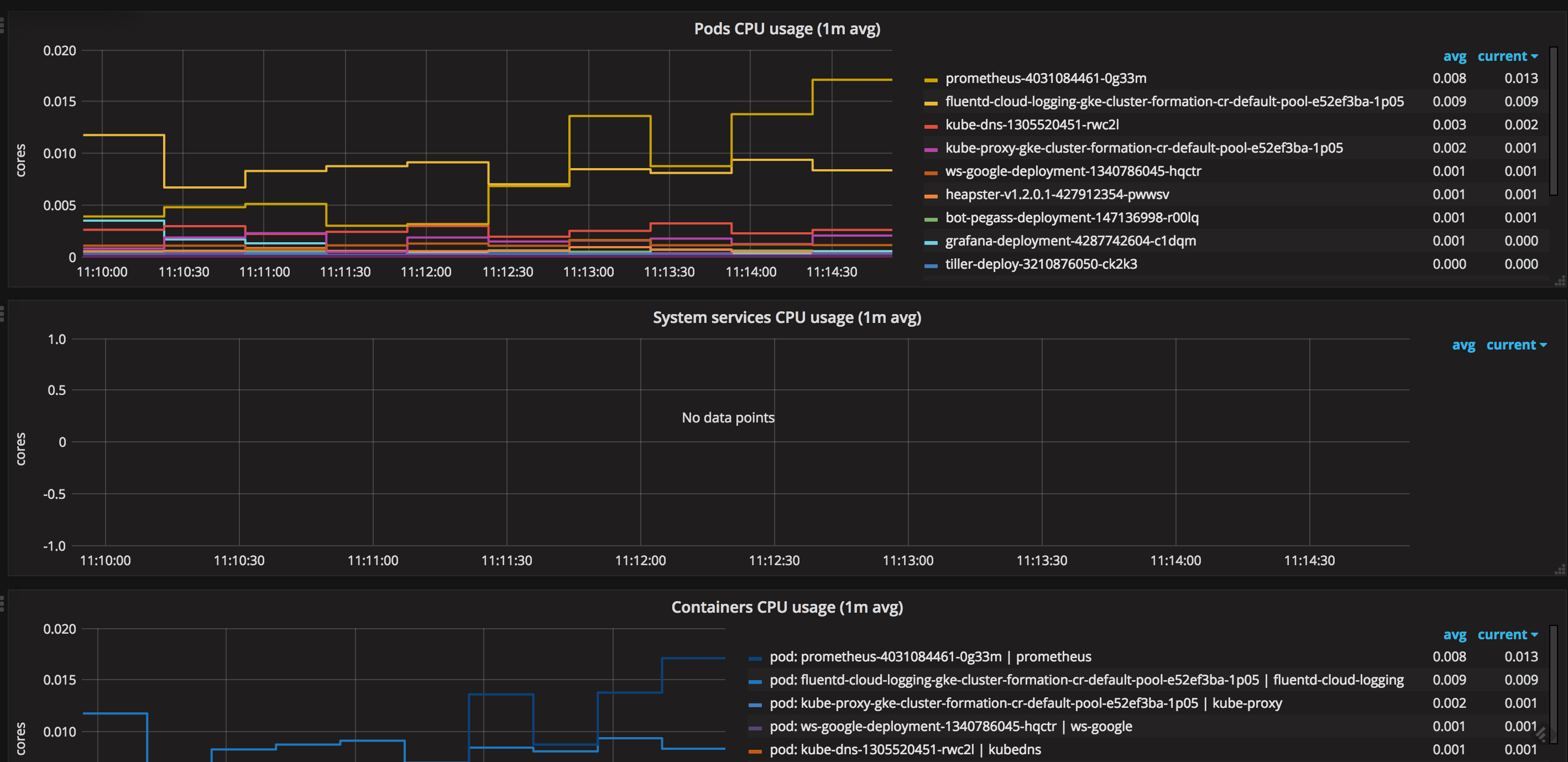
Grafana permet de lever ses propres alertes mais ne récupère pas les alertes levées par Prometheus. L’alerting de Grafana a l’avantage de pouvoir être configuré directement dans l’interface et non dans un fichier. Il est donc plus souple à l’usage.
Stockage de mes données
Le stockage des données est toujours un problème. Prometheus nous recommande de ne pas stocker les données dans leur système plus de 15 jours, c’est d’ailleurs le “Time To Live” des données configuré par défaut dans leur système.
Si lors de vos discussions, vous en déduisez que vous devez stocker vos données plus de temps, voire beaucoup plus de temps, alors vous devez prévoir un mécanisme pour envoyer les données de Prometheus vers une autre base de données.
Un type de base de données pour cet usage serait une base de données de type “time series”. Grafana accepte en source de données InfluxDB, OpenTSDB et encore Graphite ce qui vous permettrait d’avoir des dashboards compatibles.
Conclusion
L’ensemble des problématiques de monitoring peuvent être traitées par cette suite de logiciels. L’installation et la configuration sont plus simples qu’il n’y paraît, il ne faut qu’une ou deux heures pour lire la documentation et monter le système sur un environnement.
L’utilisation des alarmes vous permettra de ne pas passer trop de temps sur les outils de visualisation pour savoir si tout se passe bien en production et pourra servir de blocage lors de vos tests de performance ou d’intégration.
Un soucis avec tout cela : si votre cluster Kubernetes a des problèmes, votre monitoring de celui-ci risque de ne plus fonctionner.
Mais cela n’arrive jamais, n’est ce pas ? ;-)
NB : depuis la parution de cette article la version 2.0 de Prometheus est sortie, améliorant les capacités du stockage à court terme.



