
Rook : Comment avoir du stockage distribué ?
Depuis quelques années, les conteneurs sont de plus en plus présents dans nos infrastructures, nous vous avons déjà parlé du monitoring d'un cluster Kubernetes.
Je vous propose de parler maintenant du stockage de vos données.

Sommaire
Une solution souvent exploitée consiste à utiliser les services de notre Cloud Provider directement intégré dans notre cluster Kubernetes. Mais comment faire quand on déploie un cluster on-premise ?
Rook est là pour vous permettre de déployer rapidement un système de stockage distribué (Ceph). Si cette solution est la seule que propose Rook aujourd’hui, il est prévu d’en ajouter d’autres, à terme.
Je vous propose maintenant de voir ensemble comment utiliser Rook :
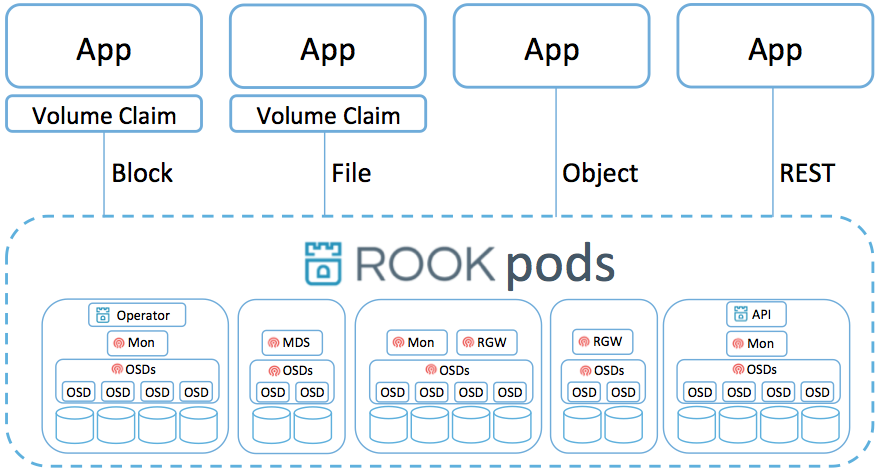
Prérequis
Vous devez installer quelques prérequis pour le bon fonctionnement de Rook sur vos serveurs :
# Debian / Ubuntu
apt-get install ceph-fs-common ceph-common
# Redhat / CentOS
yum install ceph
# Global
cd /bin
sudo curl -O https://raw.githubusercontent.com/ceph/ceph-docker/master/examples/kubernetes-coreos/rbd
sudo chmod +x /bin/rbd
rbd #Command to download ceph images.
Installation de rook-operator
Le rook-operator s’occupe d’automatiser la gestion du cluster Ceph, et celui-ci implémente pour nous les third party resources (TPR). Ainsi, nous le verrons un peu plus tard, nous pouvons gérer les ressources de rook via l’appel “apiVersion: rook.io/v1alpha1”.
Rook propose deux modes d'installation, via Helm ou via des fichiers de configuration plus classiques.
Personnellement, je préfère l'installer via Helm, mais vous propose ici les deux solutions.
Installation classique
Kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/rook-operator.yaml
Installation via Helm
helm repo add rook-alpha http://charts.rook.io/alpha
helm install --name rook --namespace rook rook-alpha/rook
Déploiement du cluster Ceph
Une fois le pod rook-operator déployé, nous pouvons demander la création du cluster Ceph. L'ensemble se fait via un fichier de configuration qu'on envoie à Kubernetes :
apiVersion: v1
kind: Namespace
metadata:
name: rook
---
apiVersion: rook.io/v1alpha1
kind: Cluster
metadata:
name: rook
namespace: rook
spec:
versionTag: 0.5.1
dataDirHostPath:
storage:
useAllNodes: true
useAllDevices: false
storeConfig:
storeType: filestore
databaseSizeMB: 1024
journalSizeMB: 1024
kubectl create -f mon-fichier-de-configuration.yaml
Quelques secondes / minutes plus tard, si vous regardez en même temps l’etat de vos pods via un kubectl get pod --all-namespaces, nous pouvons voir les différents services de Rook (api, mon, osd) se déployer.
Activation du service block dans Ceph
Votre cluster Ceph est maintenant opérationnel, cependant votre Kubernetes n'est pas encore configuré pour communiquer avec celui-ci. Pour cela, on lui envoie la configuration suivante :
apiVersion: rook.io/v1alpha1
kind: Pool
metadata:
name: replicapool
namespace: rook
spec:
replication:
size: 1
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-block
provisioner: rook.io/block
parameters:
pool: replicapool
kubectl apply -f mon-service-block.yaml
/!\ Si vous souhaitez créer des pods avec un persistent volume en dehors du namespace “default”, vous devez copier le secret qui contient la clée d’accès a rook dans les différents namespaces où vous souhaitez les utiliser.
Ceci devrait être corrigé dans les prochaines versions de Rook.
kubectl get secret rook-rook-user -o json | jq '.metadata.namespace = "kube-system"' | kubectl apply -f -
Interaction avec Rook
Vous pouvez interagir avec Rook soit via son API, soit via le rook-client.
L’installation est elle aussi très simple : Documentation d’installation.
Test
Vous pouvez à présent vérifier le bon fonctionnement de Rook dans votre cluster Kubernetes en lançant cette commande :
kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/mysql.yaml
Celle-ci va vous déployer un serveur MySQL avec un volume persistant dans Rook !
Conclusion
Rook est très facilement installable et vous permet d'utiliser des volumes persistants sans dépendre de votre Cloud Provider.
La solution est encore en Alpha, mais une version stable devrait arriver d'ici la fin de l'année (décembre 2017 dans la roadmap).
Je vous encourage fortement à lire la documentation de Rook, pour comprendre les différentes configurations et possibilités que celui-ci vous offre :)



