 Akram BLOUZA
Akram BLOUZA


OpenShift permet de construire votre application, la déployer et l'exécuter.
Dans mon précédent article, j’ai abordé les différentes stratégies de build utilisables dans OpenShift.
Dans cette troisième et dernière partie, je vais parcourir l’ensemble des fonctionnalités les plus importantes qu’OpenShift peut traiter lors du déploiement de l’application.
Déploiement initial suite au Build
Je ne l’ai pas abordé dans le précédent article, mais vous l’avez sûrement remarqué, le build de votre application dans OpenShift lance sytématiquement un déploiement. Lors du build de l’application, le déploiement de l’application est effectué et un ensemble d’objets sont créés au niveau OpenShift.
Au niveau de la console, plusieurs informations utiles concernant votre application déployée sont affichées :
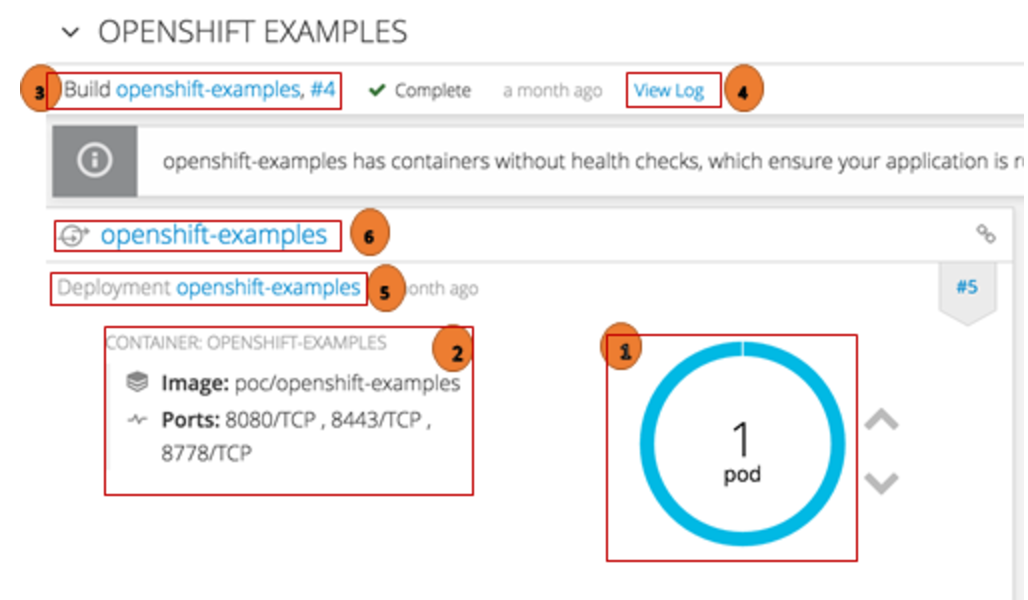
(1) Le Pod créé a une couleur bleue. Cette couleur indique que le Pod est bien déployé
(2) Ensemble des conteneurs déployés dans le Pod, ainsi que le détail de ces conteneurs.
(3) Lien pour afficher le détail de l’ensemble des builds de l’application et un autre lien pour afficher uniquement le détail du dernier build.
(4) Lien “view log” pour afficher le log du dernier build.
(5) Lien pour afficher le détail du déploiement de l’application.
(6) Lien pour afficher le détail du service exposé au Pod.
Détail du Pod
Avec la Console
Pour afficher les informations macro du Pod, il suffit de cliquer au niveau du Pod, et l’écran "détail du Pod" s’affiche. Dans mon exemple le Pod est en status Running :

Pour avoir plus de détails sur le Pod, un clic sur le nom du Pod suffit :
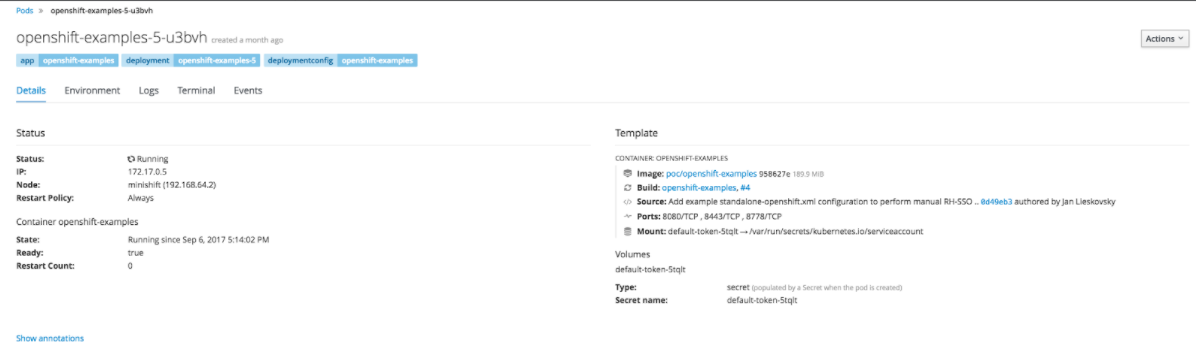
Parmi les informations intéressantes qui s’affichent, l’adresse IP du Pod et les différents volumes persistants utilisés.
Au niveau de cet écran, il est aussi possible d’accéder aux Logs Console de votre application, accéder au terminal pour vérifier par exemple les logs de votre application qui sont au niveau de fichiers logs.
Avec l’OC Cli
Pour afficher les informations du pod :
$ oc describe pod openshift-examples-5-u3bvh
Name: openshift-examples-5-u3bvh
Namespace: poc
Security Policy: restricted
Node: minishift/192.168.64.2
Start Time: Wed, 06 Sep 2017 17:14:01 +0200
Labels: app=openshift-examples
deployment=openshift-examples-5
deploymentconfig=openshift-examples
Status: Running
(...)
Volumes:
default-token-5tqlt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-5tqlt
Pour afficher les informations du pod :
$ oc logs openshift-examples-5-u3bvh
Pour accéder au Pod :
$ oc rsh openshift-examples-5-u3bvh
Détail du déploiement
Avec la Console
Pour afficher le détail du déploiement de votre application au niveau de la console, il suffit de cliquer sur le lien présent au niveau de de l’overview de votre application et détaillé plus haut :
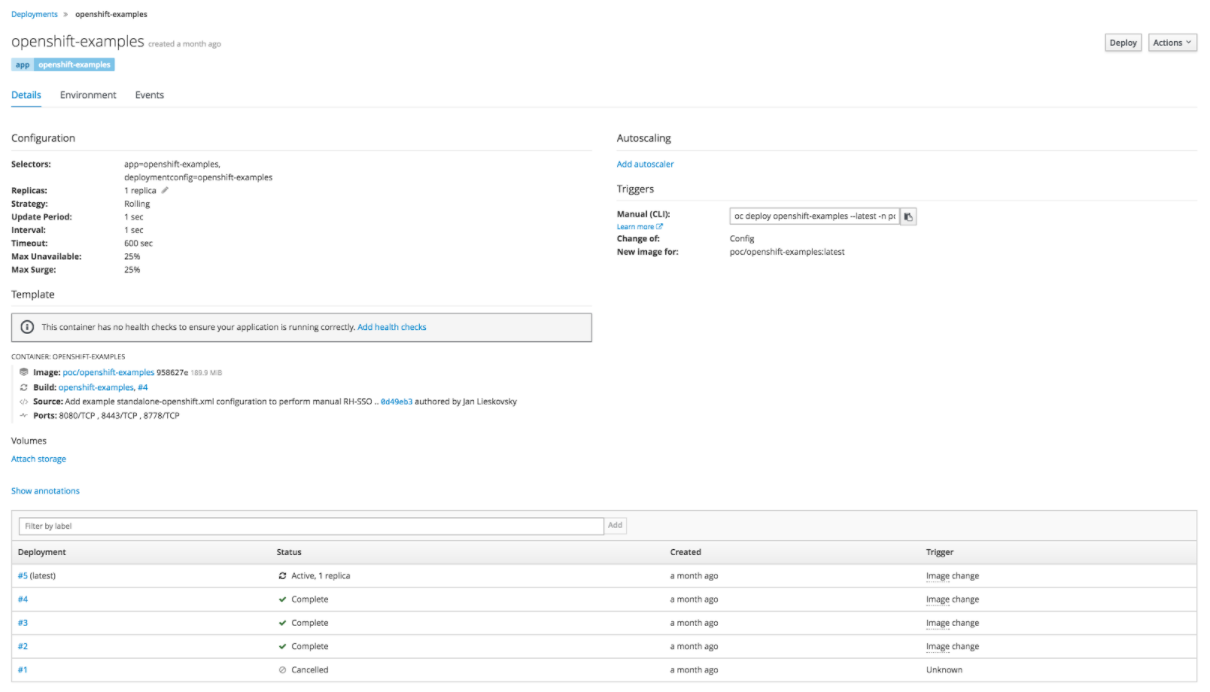
Parmi les informations intéressantes qui s’affichent, nous avons le nombre de réplicas de l’application (un par défaut), la stratégie de déploiement (rolling par défaut) et les détails des différents déploiements effectués.
Une fonctionnalité intéressante au niveau de l’écran du déploiement consiste à créer, modifier ou supprimer des variables d’environnement de votre application.
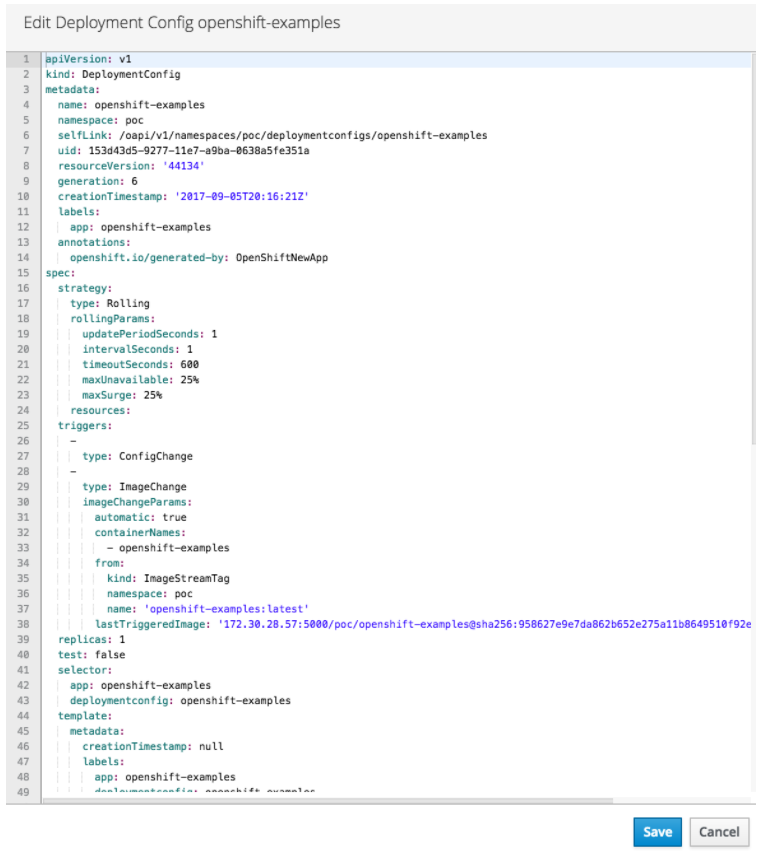
Il est aussi possible d’éditer directement le deployment Config de votre application avec Edit Yaml dans le menu déroulant Options :
Avec l’OC Cli
Pour afficher les informations du Deployment Config (DC) de votre application :
$ oc describe dc openshift-examples
Name: openshift-examples
Namespace: poc
Created: 5 weeks ago
Labels: app=openshift-examples
Annotations: openshift.io/generated-by=OpenShiftNewApp
(...)
Pour éditer le DC :
$ oc edit dc openshift-examples
Il est possible d’exporter le DC, le modifier avec votre outil préféré puis appliquer la modification :
$ oc export dc openshift-examples -o json > mon-appli.json
$ oc apply -f mon-appli.jsonFonctionnalités de déploiement et d'exécution dans OpenShift
Je reprends l’exemple d’architecture cité dans le premier article de la série.
Concernant la base de données, je choisis par exemple une base de données PostgresSQL.
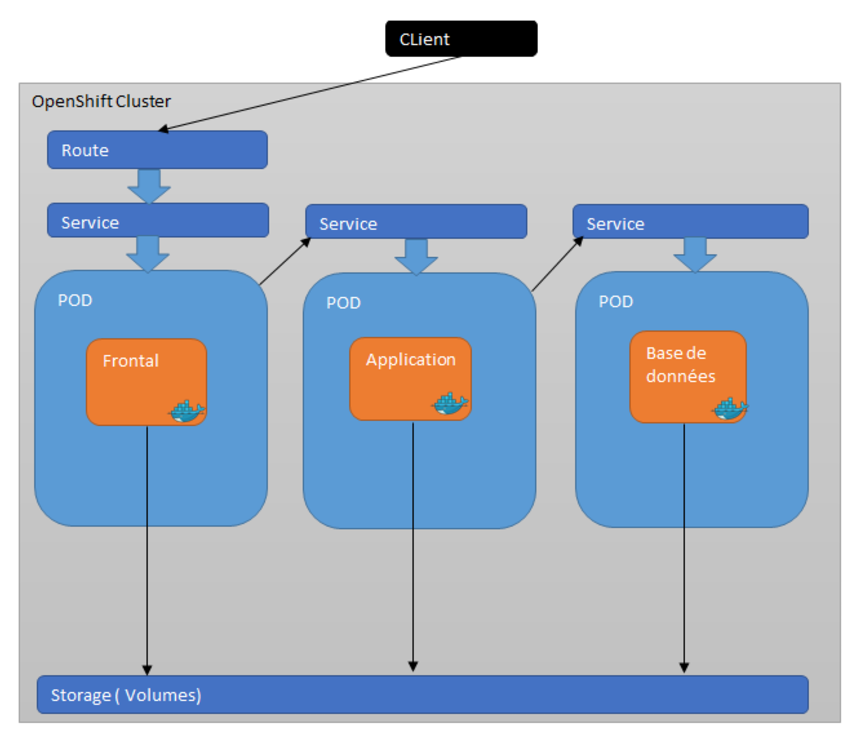
On suppose que le namespace que je nomme pococp a été créé et les déploiements sont faits suite au build des différents composants : Frontal, Application et Base de données.
Trois pods sont créés : frontal, application et postgres.
Il y a plusieurs points à considérer pour finir le déploiement de cette application dans OpenShift :
1- Ajustement du Quota nécessaire pour l’application
2- Création d’un secret pour le POD base de données (login, password).
3- Création des variables d’environnement. Ici dans notre exemple, nous avons plusieurs variables d'environnement à positionner :
- Pour le déploiement du POD frontal :
Variable d’environnement qui prend comme valeur l’adresse IP du service du Pod application. Si vous avez configuré un DNS, il est évidemment plus intéressant d’utiliser le DNS comme valeur à la variable d'environnement.
- Pour le déploiement du POD application :
Variable d’environnement qui prend comme valeur l’adresse IP du service du Pod postgres. Si vous avez configuré un DNS, il est évidemment plus intéressant d’utiliser le DNS comme valeur à la variable d'environnement.
- Variable d’environnement avec le login / password de la base de données.
4 - Variabiliser la configuration de l’application (Frontal, Application et Base de données) avec les variables d'environnement créées précédemment.
5 - Injecter ces fichiers de configuration dans des volumes persistants grâce aux configMap et les volumes.
6 - Création d’un persistent volume claim pour la base de données.
7 - Création d’une route pour le frontal.
8- Définir le mode de déploiement par POD.
9- Création du Liveness et Readiness probe.
Pour implémenter la majorité de ces points, il est possible d’utiliser la console. Toutefois, j’utiliserai l’OC Cli qui est le moyen la plus utilisée pour interagir avec OpenShift.
Définition du quota nécessaire pour l’application
Les pods sont déployés dans le cluster OpenShift et partagent les ressources des serveurs qui les hébergent. Pour éviter qu’un Pod ne consomme plus qu’il ne devrait sur les ressources de la machine sur laquelle il se trouve, il est important de définir le quota des ressources à utiliser pour cette application.
Le json à appliquer au niveau du namespace de notre application :
{
"apiVersion": "v1",
"kind": "ResourceQuota",
"metadata": {
"name": "quota"
},
"spec": {
"hard": {
"memory": "6Gi",
"cpu": "10",
"pods": "10",
"services": "3",
"replicationcontrollers":"5",
"resourcequotas":"1"
}
}
}
La commande OC :
$ oc apply -f ata-zqg-poc-compute-quota.json
Pour avoir la liste des quotas :
$ oc get quota -n pococp
NAME AGE
quota 34d
- Consulter l'état du quota qu'on veut modifier :
$ oc describe quota quota
Name: quota
Namespace: pococp
Resource Used Hard
------- - ---- ----
cpu 0 20
memory 0 1Gi
pods 0 10
replicationcontrollers 0 5
resourcequotas 1 1
services 0 5
- Export du json du quota :
$ oc export quota ata-zqg-poc-compute-quota -o json > ata-zqg-poc-compute-quota.json
Création du secret
Ici, je crée le secret qui sera utilisé par le pod base de données :
$ oc create secret generic db.pococp --from-literal=db.usr=test --from-literal=db.pwd=test
Il est toujours utile de créer un label pour tout objet OpenShift. Cela permet de le retrouver plus facilement :
$ oc label secret/db.pococp pococp=app
Vérifier si le secret a été créé :
$ oc get secret
NAME TYPE DATA AGE
db.pococp Opaque 2 34d
Avoir le détail du secret :
$ oc describe secret db.pococp
Name: db.pococp
Namespace: pococp
Labels: pococp=app
Annotations: <none>
Type: Opaque
Data
====
db.pwd: 4 bytes
db.usr: 4 bytes
Création des variables d’environnement pour le frontal et métier
Pour le DC du pod frontal, création d’une variable d’environnement qui prend comme valeur l’adresse IP du service du Pod application.
Pour le DC du pod métier, création d’une variable d’environnement qui prend comme valeur l’adresse IP du service du Pod postgres.
Pour retrouver les adresses IP des différents services présents :
$oc get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontal 172.30.195.65 <none> 8080/TCP,8443/TCP 36d
metier 172.30.126.98 <none> 8080/TCP,8443/TCP 37d
postgres 172.30.73.96 <none> 5432/TCP 37d
- Création des variables d’environnement :
$oc set env dc/frontal service_metier_ip=172.30.126.98
$oc set env dc/metier service_metier_ip=172.30.73.96
- Création d’une variable d’environnement qui prend comme valeur le secret db.pococp :
$oc set env --from=secret/db.pococp dc/postgres
configMap et les volumes : Injection de la configuration de l’application dans des volumes persistants
Positionnez-vous au niveau du dossier où se trouve la configuration de chaque composant de l’application pour créer la configMap. Chaque configMap possédera plusieurs clés dont la valeur est le nom du fichier et la valeur le contenu du fichier :
oc create cm pococp.frontal.conf --from-file=.
oc label cm/pococp.frontal.conf pococp=app
oc create cm pococp.application.conf --from-file=.
oc label cm/pococp.application.conf pococp=app
oc create cm pococp.postgres.conf --from-file=.
oc label cm/pococp.postgres.conf pococp=app
Modifiez le DC de chaque pod pour créer un volume persistant avec les fichiers de configuration :
oc set volume dc/frontal --add --name=conf --mount-path=/opt/webserver/conf --configmap-name=pococp.frontal.conf --overwrite
⇒ On crée un volume persistant au niveau du DC dc/frontal avec un point de montage /opt/webserver/conf. Les fichiers de configuration présents au niveau de la configMap pococp.frontal.conf sont copiés au niveau de ce point de montage.
Pareillement, je modifie les DC des pod application et postgres :
oc set volume dc/application --add --name=conf --mount-path=/app/conf --configmap-name=pococp.application.conf --overwrite
oc set volume dc/postgres --add --name=conf --mount-path=/app/conf --configmap-name=pococp.postgres.conf --overwrite
Demande d’un persistent volume Claim pour la base des données
Un PersistentVolume est une ressource de stockage OpenShift qui est provisionnée par le cluster admin depuis un stockage distribué (NFS, Ceph, EBS…) .
Pour demander du stockage persistant à votre application, il suffit d’utiliser un Objet PersistentVolumeClaim (PVC). Le Claim sera apparié avec un volume persistant.
Ici le postgres_pvc.json contient la définition d’un pvc :
apiVersion: "v1"
kind: "PersistentVolumeClaim"
metadata:
name: "postgres"
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "5Gi"
volumeName: "claimVolume0001"
La création d’un pvc se fait avec la commande suivante :
oc apply postgres_pvc.json
On vérifie que le pvc est pris en compte :
$ oc get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
postgres Pending 35d
Après un certain temps, le Claim est bien apparié avec un volume persistant :
$ oc get pvc
NAME LABELS STATUS VOLUME
postgres map[] Bound claimVolume0001
Un PersistentVolumeClaim est utilisé par un Pod comme un volume. Voici la commande permettant de créer le pvc au niveau d’un pod :
$ oc set volume dc/postgres --add --name=donnes -t pvc --claim-name=postgres --overwrite
Création du Health check : Liveness et Readiness Probe
Le liveness Probe permet de tester si l’application est encore en vie. Si le liveness probe échoue, le kubelet tue le pod. Le replication control (RC) vérifie et constate qu’on n’a pas le nombre de pods souhaités démarrés. Il applique ainsi la stratégie de déploiement pour démarrer un nouveau Pod.
Le readiness Probe permet de vérifier si l’application est ready pour accepter des requêtes. Au déploiement de l’application, il est souvent utile de savoir que l’application est bien déployée et surtout prête de ready à être ouverte vers l’extérieur.
Création d’un readiness Probe :
Dans cet exemple le readiness Probe fait appel au service healthz exposé par l’appli web du frontal :
$ oc set probe dc/frontal --readiness ----get-url=http://:8080/healthz
Routes
Pour donner accès au service frontal depuis l’extérieur du cluster OpenShift, il est nécessaire de créer une route. J’appelle cette route www.pococp.wescale.fr et la résolution DNS est gérée séparément :
$ oc expose svc/frontal -l pococp=app --hostname=www.pococp.wescale.fr
Pour vérifier que la route a été bien créée :
$ oc get routes
NAME HOST/PORT PATH SERVICES PORT
pococp www.pococp.wescale.fr openshift-examples 8080-tcp
Replicas
Le nombre de réplicas d’un pod est égale à un par défaut. Pour garantir une haute disponibilité de notre application, il est primordial de rajouter des réplicas au pod “frontal” et au pod “application”.
Voici les commandes à exécuter :
oc scale dc/frontal --replicas=2
deploymentconfig "frontal" scaled
oc scale dc/application --replicas=2
deploymentconfig "application" scaled
Le Replication Controller (RC) de Kubernetes a pour rôle de garantir que le nombre de réplicas définit par pod exacte.
Définition de la stratégie de déploiement
Pour les applications legacy, le serveurs qui les hébergent sont souvent arrêtées avant chaque déploiement. Cet arrêt du service est parfois inutile, et il est possible de redéployer la nouvelle version de l’application sans arrêter le service.
Les stratégies de déploiement qu’on peut application à notre application sont :
La stratégie Rolling
Cette stratégie garantit un non arrêt du service au déploiement d’une nouvelle version de l’application.
Prenons le cas du pod “frontal” qui possède d meux replicas. Un nouveau déploiement de ce composant avec la stratégie Rolling se fait au niveau de l’un des pods frontal. Un readiness probe est ensuite effectué sur ce pod.
L’autre pod reste disponible et aucun déploiement n’est effectué tant que le readiness probe n’est terminé.
Pour appliquer cette stratégie, il suffit de modifier le déploiement config du pod :
strategy: {
type: Rolling
rollingParams: {
updatePeriodSeconds: 1
intervalSeconds: 1
timeoutSeconds: 600
maxUnavailable: 25%
maxSurge: 25%
}
}
La stratégie Recreate
Avec cette stratégie de déploiement, le service est arrêté à chaque déploiement.
Pour un nouveau déploiement du frontal par exemple en appliquant ce mode de déploiement, un scale à 0 est fait sur le DC du frontal.
Ensuite, un nouveau déploiement est effectué avec un scale à 1, et enfin un deuxième déploiement sur le deuxième réplica.
Pour appliquer cette stratégie, il suffit de modifier le déploiement config du pod:
strategy: {
type: recreate
}
}
La stratégie Custom
Comme pour les stratégies de build, il est possible de développer votre stratégie de déploiement.
Cette stratégie de déploiement est à implémenter à partir d’une image Docker référencée au niveau du DC du pod :
"strategy": {
"type": "Custom",
"customParams": {
"image": "myimages/strategy",
"command": ["command", "arg1"],
"environment": [
{
"name": "ENV_1",
"value": "VALUE_1"
}
]
}
}
Et maintenant ?
Cette série d'articles sur le fonctionnement et l'utilisation de OpenShift est maintenant terminée.
Mais ne soyez pas tristes ! Il ne s’agit pas de la fin de l’histoire OpenShift dans notre blog, mais d’un début sur d’autres sujets tout aussi intéressants, importants et bien pointus.
À très vite

Ansibled - DNS, proxy et terminaison TLS pour vos applications
La rapidité et la simplicité qu’apportent les fournisseurs de cloud public en terme de déploiement applicatif n’est plus à démontrer. Il s’agit bien...