
K8S: Préemption et priorités de Pods
On a vu dans un précédent article l’influence des QoS sur l’utilisation des ressources du cluster ainsi que sur le cycle de vie des Pods. Dans cet article, on va parler d’un autre niveau pour définir la priorité qui intervient au niveau du scheduler, la préemption.
Sommaire
Préemption
Au moment du scheduling d’un Pod, le scheduler s’appuie sur plusieurs prédicats et métriques pour placer le pod dans un noeud (capacité des noeuds, les requests ..). La notion de préemption a été introduite en alpha à partir de la version 1.9 et passée en bêta à partir de la 1.11. Il s’agit d’un poid qu’on associe à un Pod au moment du scheduling :
- Les Pods seront déployés dans le cluster par ordre de priorité.
- Si de nouveaux Pods demandent à être déployés sur un cluster surchargé, le scheduler réévalue l’ordonnancement (scheduling) des Pods en enclenchant la préemption. Il s’agit de libérer de la place pour les Pods les plus prioritaires en terminant par les Pods les moins prioritaires qui repassent dans la file du scheduler qui va essayer de les ré-ordonnancer.
- Si le Pod est schedulable tout va bien sinon le scheduler enclenche la préemption.
- Si la préemption ne réussit pas (d’autres Pods plus prioritaires sont en train de tourner et il n’y a aucun Pod de moindre priorité qui peut être sorti, ou la capacité des noeuds ne permet pas de placer le Pod), dans ce cas-là, le Pod passe en statut “unschedulable”.
Interêt
Dans les versions antérieures à la 1.9 le scheduler traitait les demandes de scheduling en suivant une logique de premier arrivé premier servi (FIFO). Cela voudrait dire que des charges de travail moins prioritaires pouvaient bloquer le traitement d’autres plus importantes qui arriveraient après.
On peut imaginer par exemple le cas où la taille du cluster est fixée que ce soit parce qu’on est sur une infrastructure on-premise ou parce qu’on est chez un cloud provider mais pour des raisons de coût ou parce qu'on veut scaler rapidement notre application lors d’un pic de charge par exemple.
Assigner un poids élevé à ces Pods au moment du scheduling garantit la fiabilité du service en les priorisant par rapport à d’autres Pods moins critiques qui leur laisseront la place.
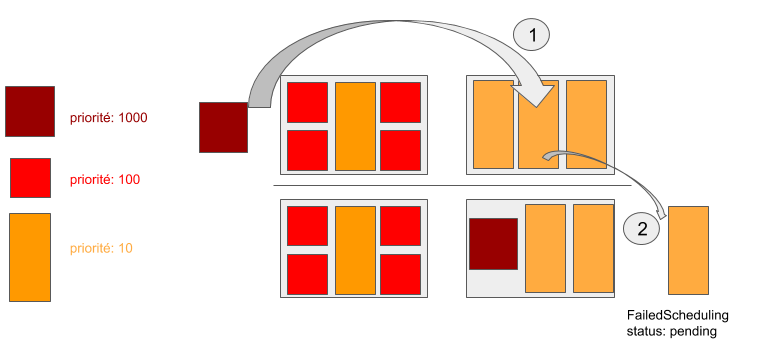
Pod Priority vs Qos (Préemption vs Éviction)
Il s’agit de deux niveaux de SLA différents, l'Éviction est déclenchée en cas de pression sur les ressources du cluster (CPU, Mémoire), ainsi le kubelet intervient pour terminer les Pods les moins prioritaires du point de vue QoS (BestEffort < Burstable < Guaranteed). Quant à la préemption elle intervient au moment du scheduling.
Se baser uniquement sur les QoS ne garantit pas la stabilité désirée d’un service critique lors d’un pic de charge par exemple, en effet, même si on ne déploie que des Pods Burstable et Guaranteed, on n’a pas la garantie que c’est le service le plus critique (par exemple un service destiné à servir des clients en temps réel ) qui aura la priorité de scaler et de poper de nouveaux Pods. En effet, du point de vue fonctionnel, tous les services Guaranteed et Burstable n’auront pas forcément le même SLA.
Ceci n’empêche que ces deux concepts peuvent se croiser au moment de l'éviction causée par une surcharge de ressources, le kubelet classe les Pods candidats à l’éviction en évaluant dans l’ordre ces conditions :
- Est-ce que le Pod dépasse ses requests ?
- Le niveau de Pod Priority
- Le dépassement de ressources consommées par rapport aux requests définis.
Mise en oeuvre
Créer un cluster avec 3 noeuds disposant d’une unité de cpu.
Créer une classe de priorité pour des services critiques :
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000
#pour que cette classe de priorité ne soit pas assignéé par défaut aux pods sans priorité
globalDefault: false
Créer un premier déploiement sans aucune priorité définie :
apiVersion: apps/v1
kind: Deployment
metadata:
name: no-priority
spec:
replicas: 3
selector:
matchLabels:
app: no-priority
template:
metadata:
labels:
app: no-priority
spec:
containers:
- name: no-priority
image: nginxdemos/hello
resources:
requests:
cpu: 1
memory: 128Mi
limits:
cpu: 1
memory: 128Mi
Observer que les Pods sont bien créés :
kubectl get pods
NAME READY STATUS RESTARTS AGE
no-priority-6b69478db5-8rkk7 1/1 Running 0 9s
no-priority-6b69478db5-kdznn 1/1 Running 0 9s
no-priority-6b69478db5-nh6fj 1/1 Running 0 9s
Déployer un Pod associé à la classe de priorité déjà définie :
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: nginxdemos/hello
resources:
requests:
cpu:1
memory: 128Mi
limits:
cpu: 1
memory: 128Mi
priorityClassName: high-priority
Le Pod sans priorité a été terminé ensuite passé en statut pending (en attente dans la file du scheduler) :
kubectl get pods
NAME READY STATUS RESTARTS AGE
high-priority 0/1 Pending 0 2s
no-priority-6b69478db5-65wcg 0/1 Pending 0 2s
no-priority-6b69478db5-8rkk7 1/1 Running 0 2m
no-priority-6b69478db5-kdznn 0/1 Terminating 0 2m
no-priority-6b69478db5-nh6fj 1/1 Running 0 2m
Observer que comme le total des requests a atteint la capacité maximale du cluster, le premier Pod est passé en statut pending et que le Pod le plus prioritaire a bien été schedulé et déployé dans le noeud :
kubectl get pods
NAME READY STATUS RESTARTS AGE
high-priority 0/1 ContainerCreating 0 11s
no-priority-6b69478db5-65wcg 0/1 Pending 0 11s
no-priority-6b69478db5-8rkk7 1/1 Running 0 2m
no-priority-6b69478db5-nh6fj 1/1 Running 0 2m
kubectl get pods
NAME READY STATUS RESTARTS AGE
high-priority 1/1 Running 0 14s
no-priority-6b69478db5-65wcg 0/1 Pending 0 14s
no-priority-6b69478db5-8rkk7 1/1 Running 0 2m
no-priority-6b69478db5-nh6fj 1/1 Running 0 2m
Conclusion
On a bien vu que les priorités des Pods permettent d’influencer la décision du scheduler et ainsi de garantir que les charges de travail les plus critiques puissent toujours être exécutées par rapport aux charges moins critiques, quand les limites de ressources du cluster sont atteintes, particulièrement quand la taille du cluster est fixe.
Combinés avec les QoS, on a une meilleure maîtrise sur les SLA de nos déploiements et sur le cycle de vie des Pods dans le cluster qui devient plus prédictible.



