10 plugins Krew incontournables pour Kubernetes
Introduction Krew est le gestionnaire de packages pour les plugins de kubectl. Il vous permettra de rechercher, d’installer et de mettre à jour...
4 minutes de lecture
Artillery est un outil permettant de réaliser des tests de montée en charge de sites web, il est open source. Le projet est disponible sur Github (https://github.com/artilleryio/artillery).
Artillery permet de mettre en place des scénarios ayant pour but de décrire le comportement d’un utilisateur sur l’application à tester. Il existe de nombreux projets équivalents : JMeter, Gatling, Locust, etc ...
Lors d’un atelier de tests de charge pour un client, j’ai choisi Artillery.io pour sa facilité d’écriture des scripts en YAML. La simplicité de manipulation des headers HTTP pour l’authentification par exemple, et l’extraction de contenus sous forme de variables pour les ré-utiliser dans les appels HTTP suivants.
Les deux éléments essentiels d’Artillery sont les “scénarios” et les “phases”.
D’autres fonctionnalités très pratiques sont également disponibles :
Le Flow est l'enchaînement des appels HTTP à réaliser sur la cible.
Chaque élément du Flow peut-être un verbe HTTP (GET / POST / PUT / PATCH / DELETE),
et les arguments spécifiques à chacun.
Dans les Flows , il y a des facilitateurs pour manipuler les cookies, les forms (urlencode et multipart), Basic Auth HTTP, le suivi ou non des redirections, le support des réponses GZIP.
Exemple d’appel HTTP avec Basic Authen :
.../...
- get:
url: "/protected/resource"
auth:
user: myusername
pass: mypassword
.../...Suite à une réponse d'un appel HTTP, il est possible de vérifier et extraire des infos sur les données retournées par l'appel HTTP, pour extraire des tokens, ou toute autre information des headers ou du body.
Pour cela, nous avons plusieurs solutions pour procéder à l’extraction du body : soit avec des expressions régulières, soit en manipulant directement la structure json retournée si le body est en json. Il est possible d’extraire des données dans une variable pour les réutiliser dans la suite du script.
Il est possible de conditionner la bonne exécution du Flow via l’attente de résultats : Expectations and Assertions.
Exemple de capture et d’expectation :
.../...
scenarios:
- name: Get pets
flow:
- get:
url: "/pets"
capture:
- json: "$.name"
as: name
expect:
- statusCode: 200
- contentType: json
- hasProperty: results
- equals:
- "Tiki"
- "Tests de charge avec Artillery.io"
.../...Il faut que la réponse HTTP soit code 200 http, que le content type retourné soit json, que la propriété “results” soit présente, et que le contenu de la variable “name” soit égal à “Tiki”.
Un scénario permet de définir un ou plusieurs Flows (enchaînement d’appels HTTP).
On peut ensuite jouer l’ensemble des scénarios en même temps, en appliquant une pondération par scénario pour contrôler le nombre d’exécutions.
On pourrait imaginer 3 types de scénarios sur un site de e-commerce : les anonymes qui se baladent de produit en produit, ceux qui créent un compte, et ceux qui passent commande ; et définir un poids pour chacun de ces scénarios
Automatiquement, Artillery.io va respecter les ratios demandés en terme de nombre d'exécutions de scénarios. Si on ne spécifie pas de poids, il fera à parts égales l’ensemble des scénarios écrits.
Il n’y a pas de limite sur le nombre de scénarios par exécution de charge.
Comme vu plus haut, une fonctionnalité très sympathique d’Artillery.io est la possibilité de définir des phases. Elles permettent de définir la charge souhaitée sur la cible. Chaque phase peut avoir des caractéristiques différentes pour varier l’intensité de la charge durant l’exécution du test de charge.
Artillery.io raisonne en terme d’utilisateurs virtuels. Il va créer durant toute la durée de la charge des nouveaux utilisateurs qui vont exécuter le Flow d’un des scénarios.
Exemple de phase possible, mais vous pouvez imaginer toutes sortes de variantes :
phase 1 : 1 utilisateur pendant 10 secondes
phase 2 : 40 utilisateurs pendant 10 secondes avec une rampe de 10 utilisateurs par seconde
phase 3 : 80 utilisateurs pendant 20 secondes
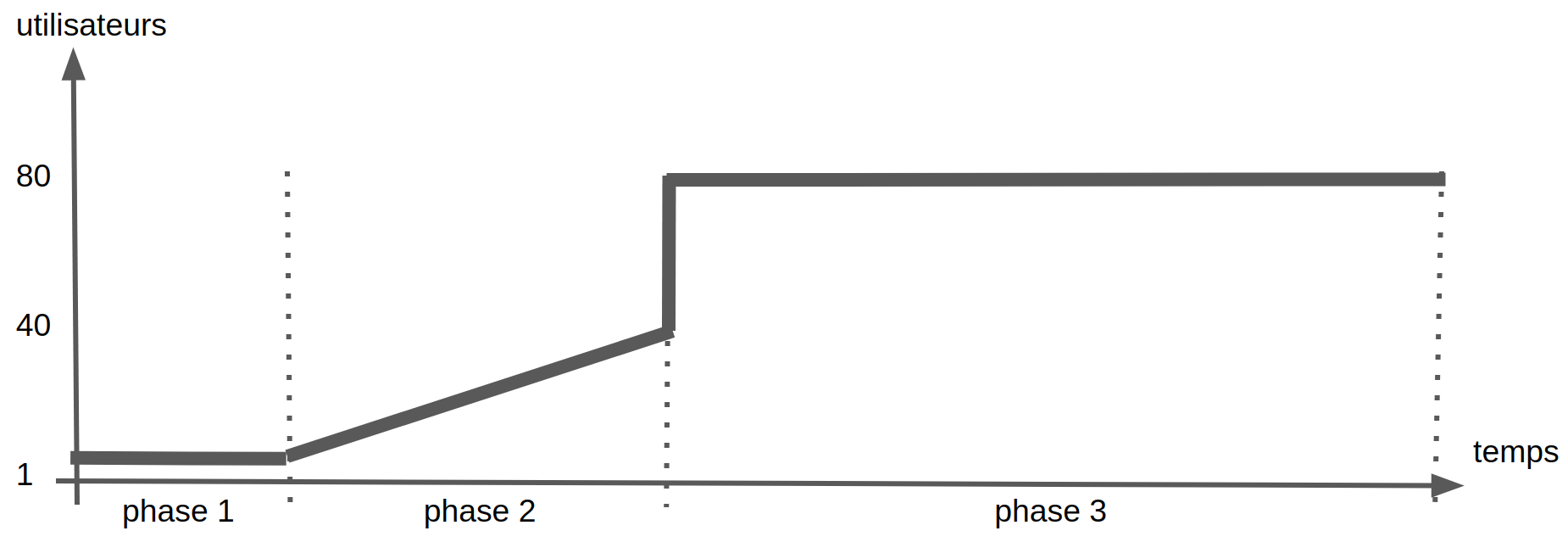
config:
phases:
- duration: 10
arrivalRate: 1
name: "phase1"
- duration: 10
arrivalRate: 40
rampTo: 10
name: "Phase2"
- duration: 20
arrivalRate: 80
name: "Phase3"$ npm install -g artillery
$ artillery run mon_test.yml
$Il existe aussi un dockerfile :https://github.com/artilleryio/artillery-docker.
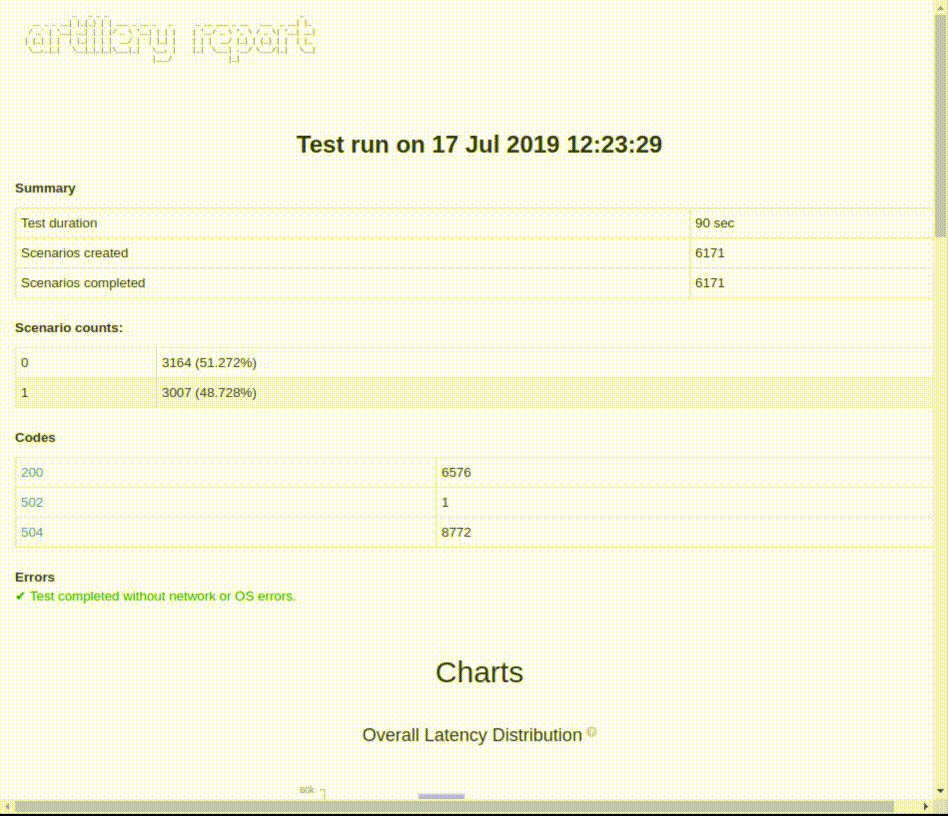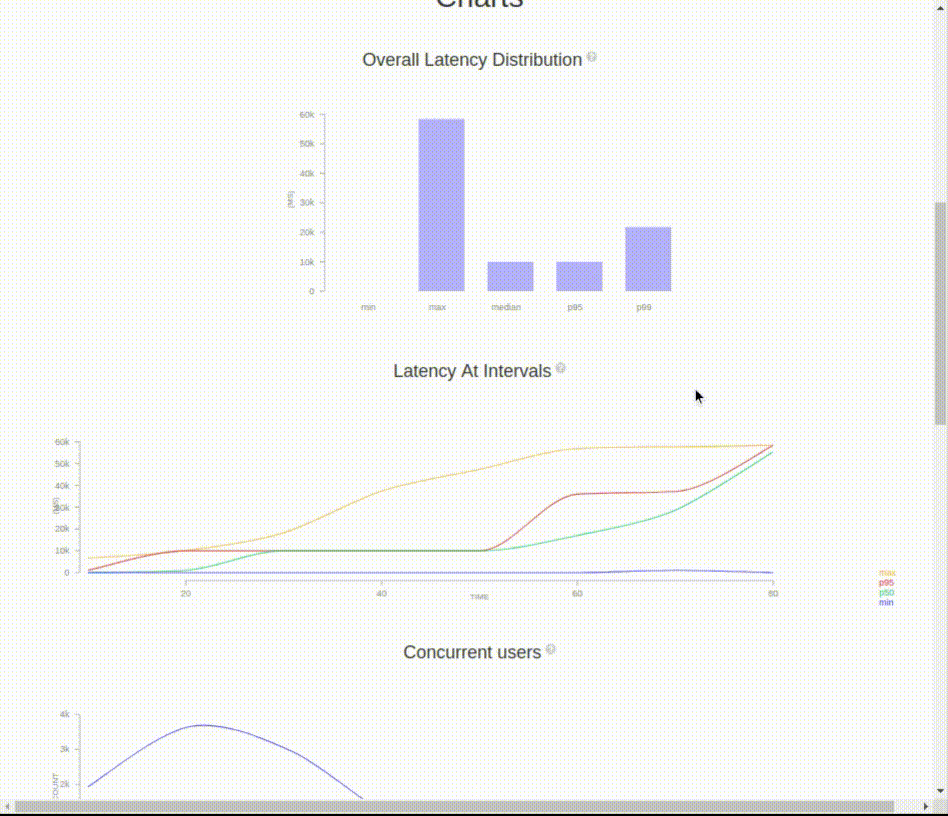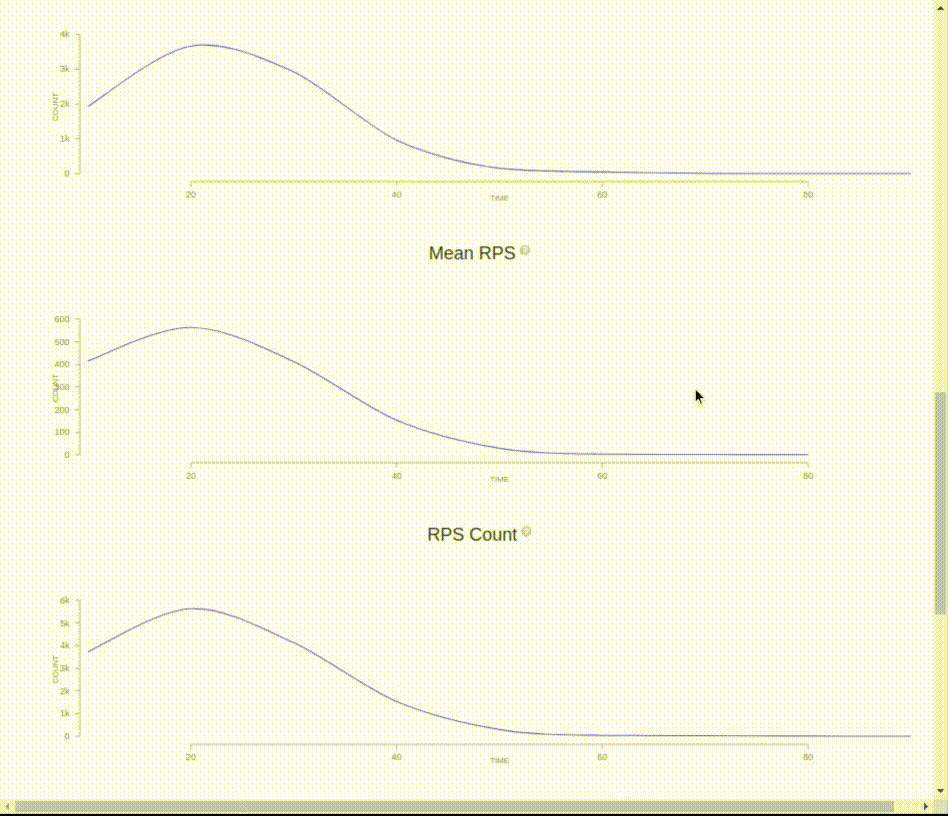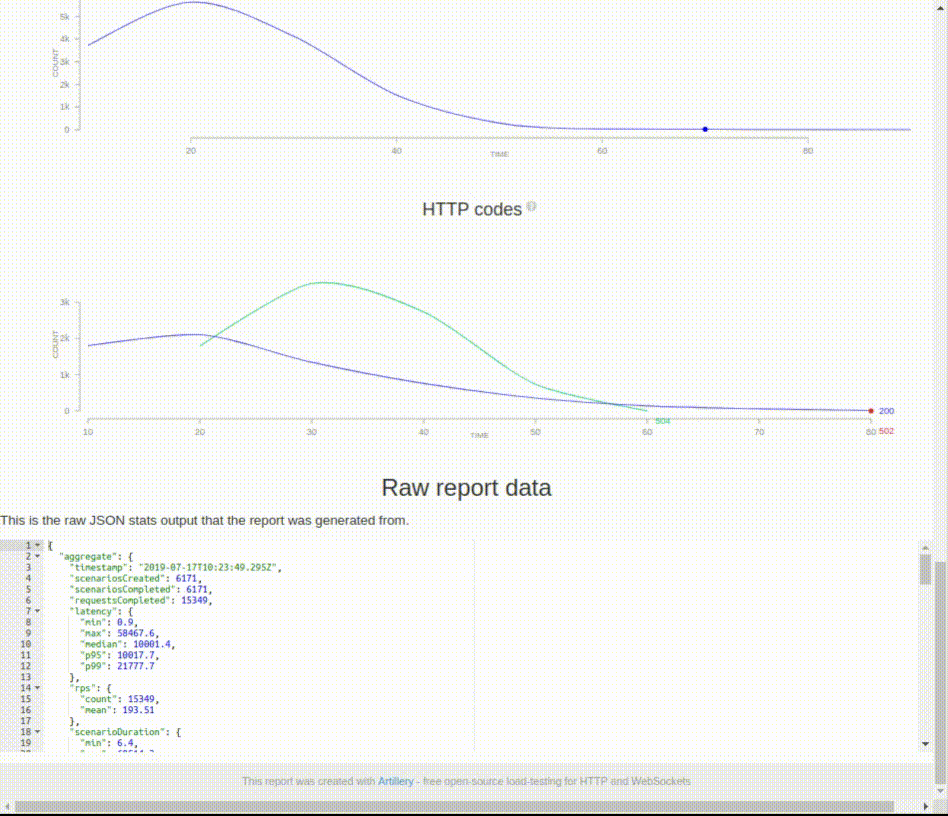
## Résultats et Rapports :
À la fin de l’exécution, Artillery.io propose un récapitulatif des résultats obtenus sous forme de compteurs.
Complete report @ 2019-07-19T08:50:27.966Z
Scenarios launched: 300
Scenarios completed: 300
Requests completed: 600
RPS sent: 18.86
Request latency:
min: 52.1
max: 11005.7
median: 408.2
p95: 1727.4
p99: 3144
Scenario counts:
0: 300 (100%)
Codes:
200: 300
302: 300Cette synthèse est également disponible dans le fichier .json associé au “run”. Ce fichier contient aussi des informations durant le “run”.
Il est possible de générer un rapport détaillé html humainement lisible, avec la commande :
$ artillery report mon_test.yml.jsonVous pouvez afficher le rapport dans un navigateur le fichier mon_test.yml.json.html :
Naturellement, il est prévu d'écrire des Flows qui chargent un seul site web. Dans certains cas, il peut être intéressant de passer sur plusieurs cibles durant le script, pour cela vous pouvez écrire l’url complète dans votre Flow et cela remplace la “target”, par exemple :
# exemple de multiple cibles dans le même flowconfig:
target: http://www.cible.com
phases:
../..
scenarios:
- flow:
- get:
url: "/list"
- get:
url: "http://www.cible1.com/pets"
- get:
url: "http://www.cible2.com/cattle"
- get:
url: "http://www.cible1.com/pets-infos"
- get:
url: "http://www.cible2.com/cattle-infos"
../..
j’ai bien aimé :
j’ai moins aimé :

Introduction Krew est le gestionnaire de packages pour les plugins de kubectl. Il vous permettra de rechercher, d’installer et de mettre à jour...
Introduction Nous avons vu dans la première partie du guide du Chaos Engineering (CE) que le CE ne peut pas avoir lieu sans expérimentations.

ShiftLeft avec TFSec Le ShiftLeft ou “décalage à gauche” dans la langue de Zizou est un concept qui veut que l’on apporte la sécurité au plus tôt...