Valider statiquement son code Terraform
Préambule Dans notre métier, il est une bonne pratique d’utiliser de l’Infrastructure as Code et il n’est pas rare de faire le choix d’utiliser ...
3 minutes de lecture
La première partie de l’article sur AWX se concentrait sur les différentes fonctionnalités présentes dans l’outil et son installation, faisons maintenant place à la pratique.
Pour rappel, AWX pourrait être résumé à une interface graphique et une API permettant de piloter des playbooks Ansible.
Dans cette partie, nous partons d’un AWX déjà installé (voir l’article précédent pour les instructions) et nous suivrons pas à pas un cas d’utilisation d’AWX en partant d’un playbook Ansible existant. Je vous propose le déroulé suivant :
Ci-joint un schéma qui récapitule les étapes ainsi que les informations que nous avons besoin tout au long de ce cas d’utilisation :
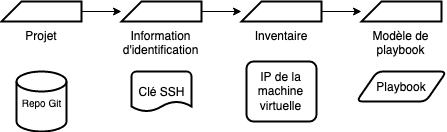
Nous utiliserons tout au long de cette démonstration un playbook qui vient installer un serveur apache2.
Maintenant, allons-y !
La première étape est de configurer notre projet qui est en fait une source de code en langage Ansible. Pour cela rendez-vous dans le menu “projet” :
Nous arrivons donc sur une page regroupant l’ensemble de nos projets (aucun pour l’instant).
Ajoutons maintenant notre projet, pour cela, il suffit de cliquer sur le petit “+” en vert.
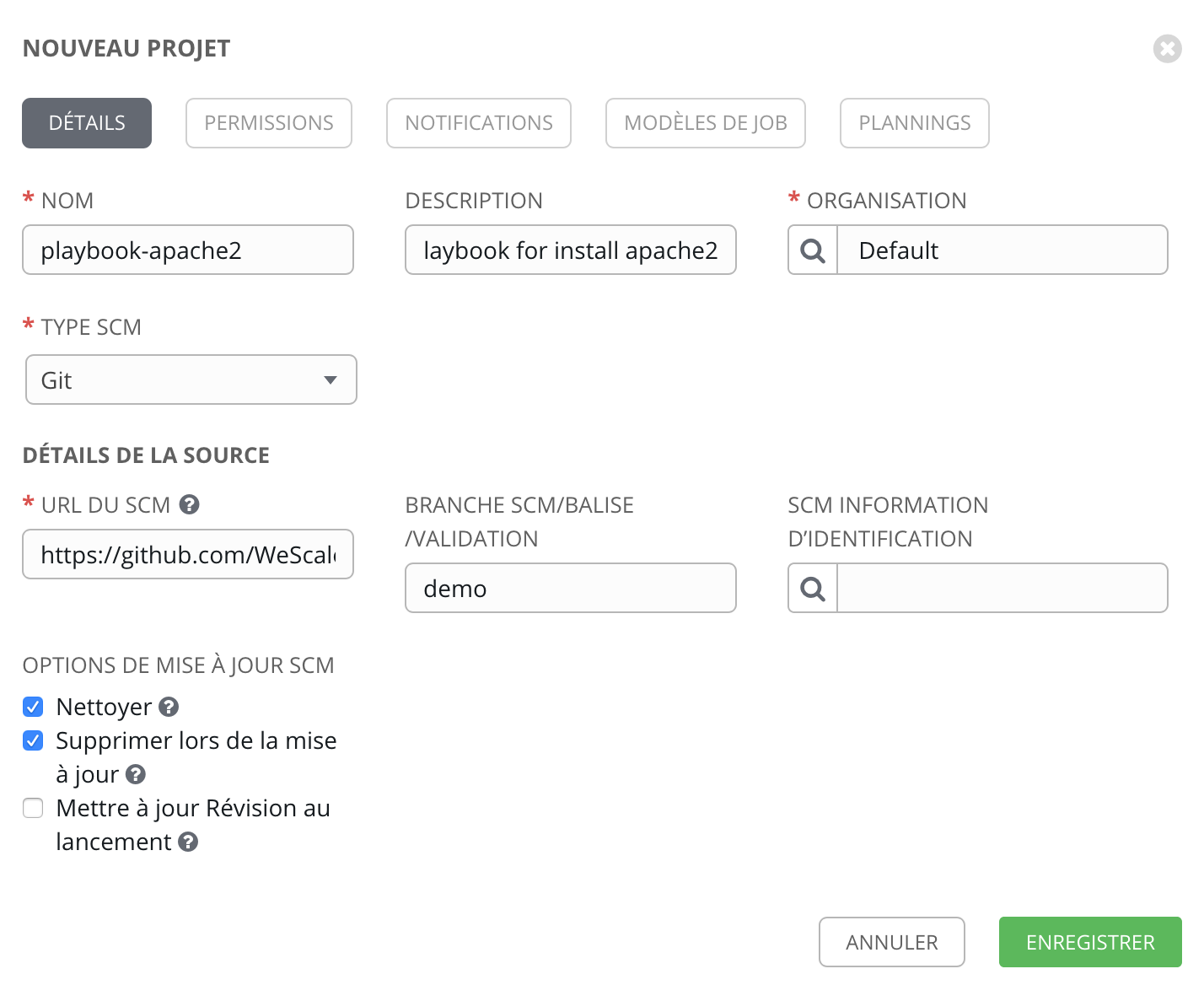
Nous initialisons notre projet avec les différentes informations ci-dessus, le but étant de donner un nom explicite, car nous allons devoir le retrouver lors de l’instanciation de notre playbook.
Ici, on doit définir l’endroit d’où provient le code source, dans notre cas, ce sera github donc “Git”. On peut venir choisir la branche que l’on veut récupérer et pourquoi pas configurer des informations d’identification si notre repository est privé.
Plusieurs options sont intéressantes ici, on peut supprimer les modifications locales via le “nettoyer”, supprimer le cache d’AWX de notre projet avec le “supprimer lors de la mise à jour” (cela évite notamment les conflits entre les commit), ou encore mettre à jour le projet à sa dernière version dès qu’on lance un playbook associé à ce projet.
Nous avons préparé notre projet, maintenant, il va falloir accéder à la machine sur laquelle on veut exécuter notre playbook, c’est pourquoi nous allons configurer les informations d’identification.
Une information d’identification peut avoir plusieurs formes : clé privée pour accéder à une machine, mot de passe Vault (Ansible), information pour se connecter à un compte cloud, etc.
Une fois que l’on accède à cette catégorie, on arrive sur cette page :

Dans notre cas, nous voulons configurer une clé privée pour accéder à la machine virtuelle sur laquelle nous allons exécuter notre playbook Ansible. Dans mon cas, j’ai lancé une machine virtuelle à l’aide de Vagrant.
Comme dit précédemment, on retrouve l’ensemble des types d’informations d’identification, ici ça sera “Machine” pour venir renseigner notre clé privée et l’utilisateur à laquelle elle appartient.
La dernière étape avant d’instancier notre playbook est la définition de l’inventaire pour déclarer sur quelle machine nous allons jouer notre script.
Encore une fois, nous arrivons sur une page qui liste l’ensemble de nos inventaires déclarés et qui permet de les gérer, dans notre cas, nous allons en ajouter un :

Nous prendrons un inventaire “classique” :
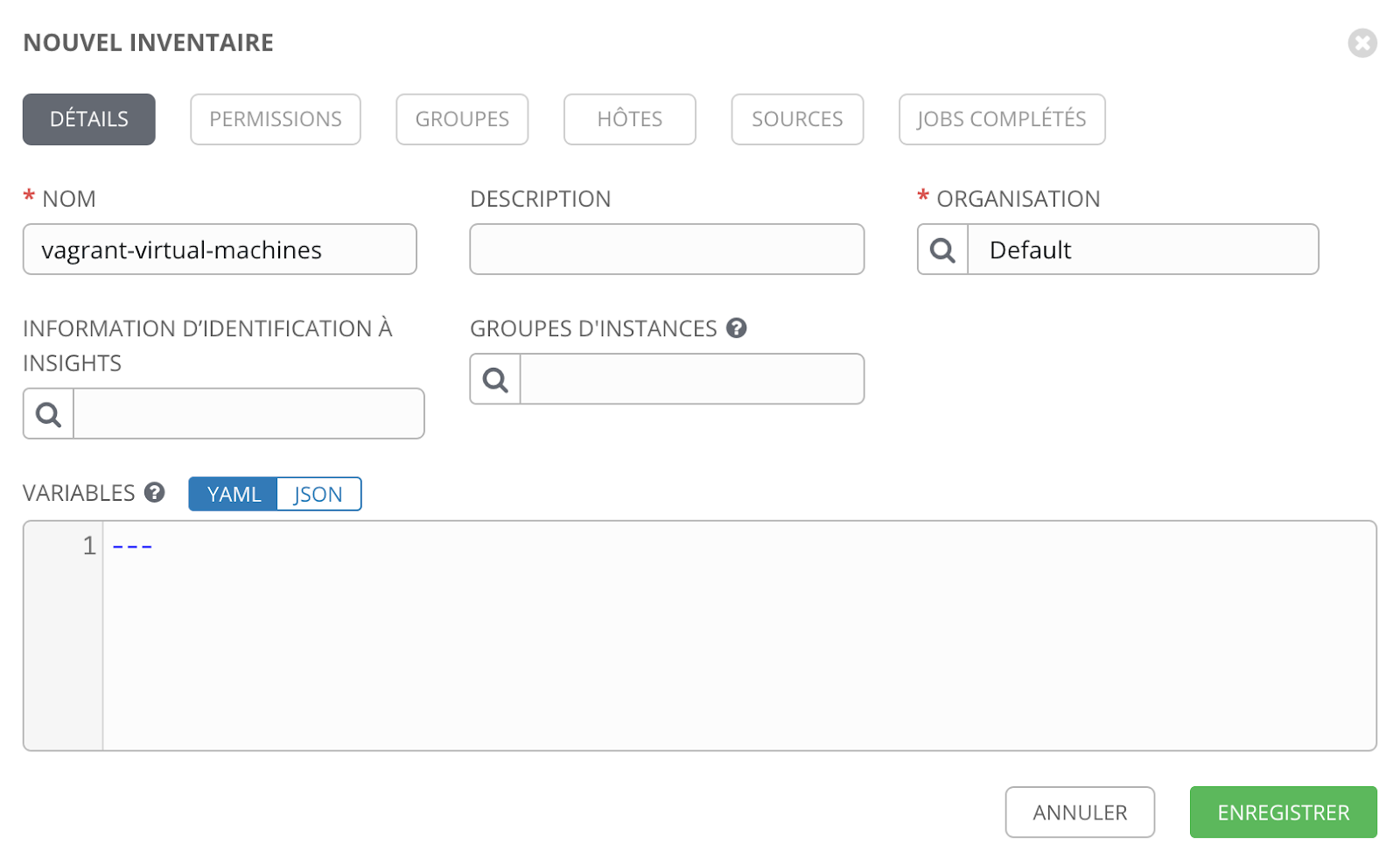
Une fois l’inventaire enregistré, nous allons pouvoir définir nos groupes et hôtes, ici, nous allons définir un groupe “web” qui contient l’IP de notre machine virtuelle.
Récapitulons ! Nous avons notre projet sourcé avec le bon lien vers notre repository Github, nous sommes capables de nous connecter à notre machine virtuelle, nous avons notre inventaire qui pointe vers celle-ci, il ne reste alors qu’une seule chose, mettre en place notre playbook.
Pour cela, nous allons devoir créer un modèle où nous sélectionnons notre playbook.
Nous arrivons sur ce genre de formulaire :
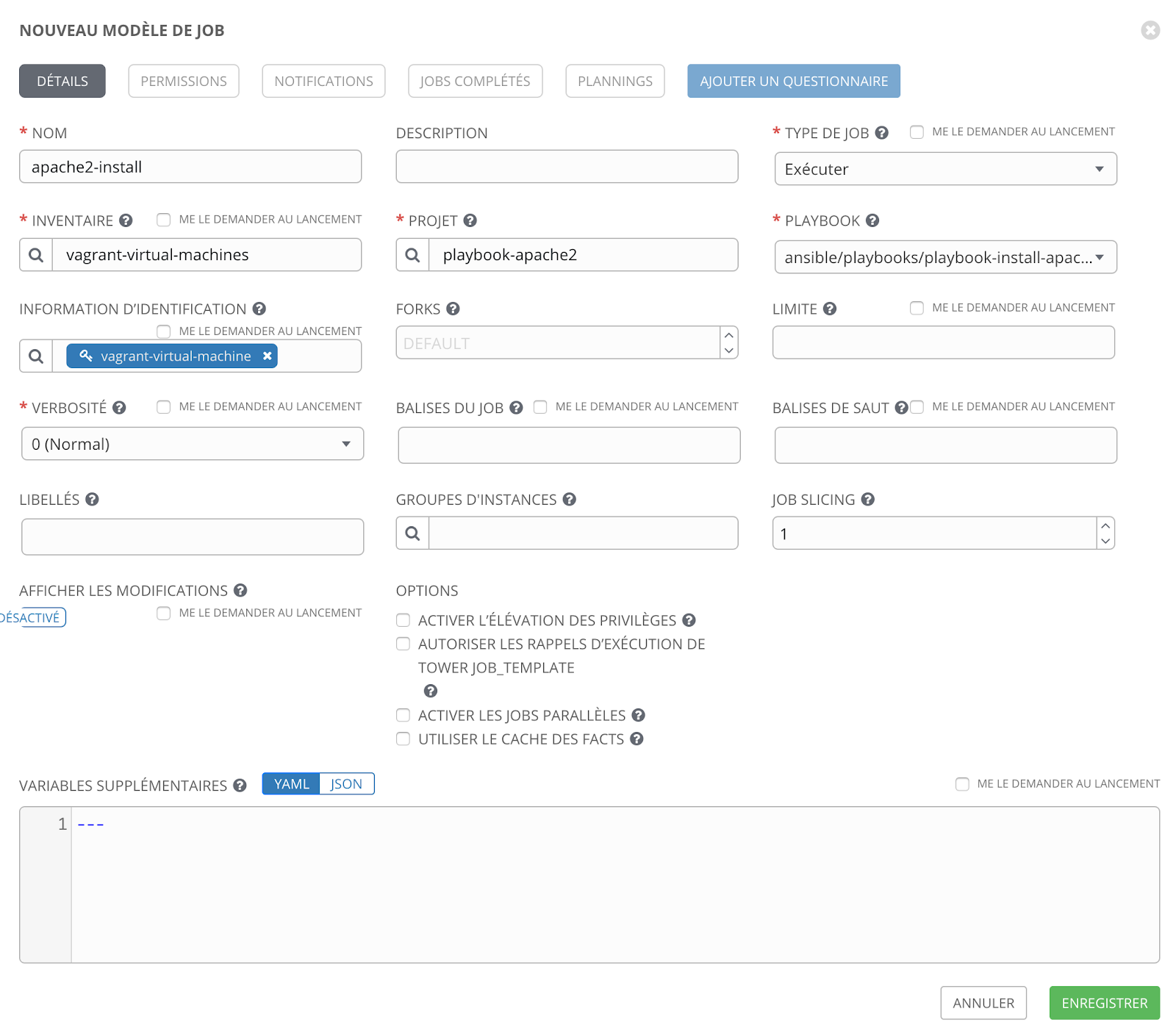
Tout ce que nous avons créé précédemment est ici sélectionné. Nous retrouvons notre inventaire (vagrant-virtual-machines), le ou les machines sur lesquelles nous allons dérouler notre playbook, le projet (playbook-apache2) qui permet de sélectionner notre playbook (playbook-install-apache2), et enfin, les informations d’identification (vagrant-virtual-machine) qui permettent de nous connecter à notre instance à configurer.
D’autres informations et options peuvent être complétées ici ainsi que des variables supplémentaires qui correspondent aux “extra_vars” d’Ansible. Vous pouvez également configurer la verbosité qui permet d’afficher différents niveaux de logs ou encore les balises de jobs qui permettent d’exécuter tout ou partie d’un playbook en fonction des tags associés.
Une fois cela fait, nous pouvons enregistrer notre modèle de job !
Nous avons configuré le minimum pour jouer un playbook via AWX, toujours dans le menu “modèle”, nous avons notre modèle configuré et nous sommes capables de le lancer à travers la petite “fusée” située à droite.
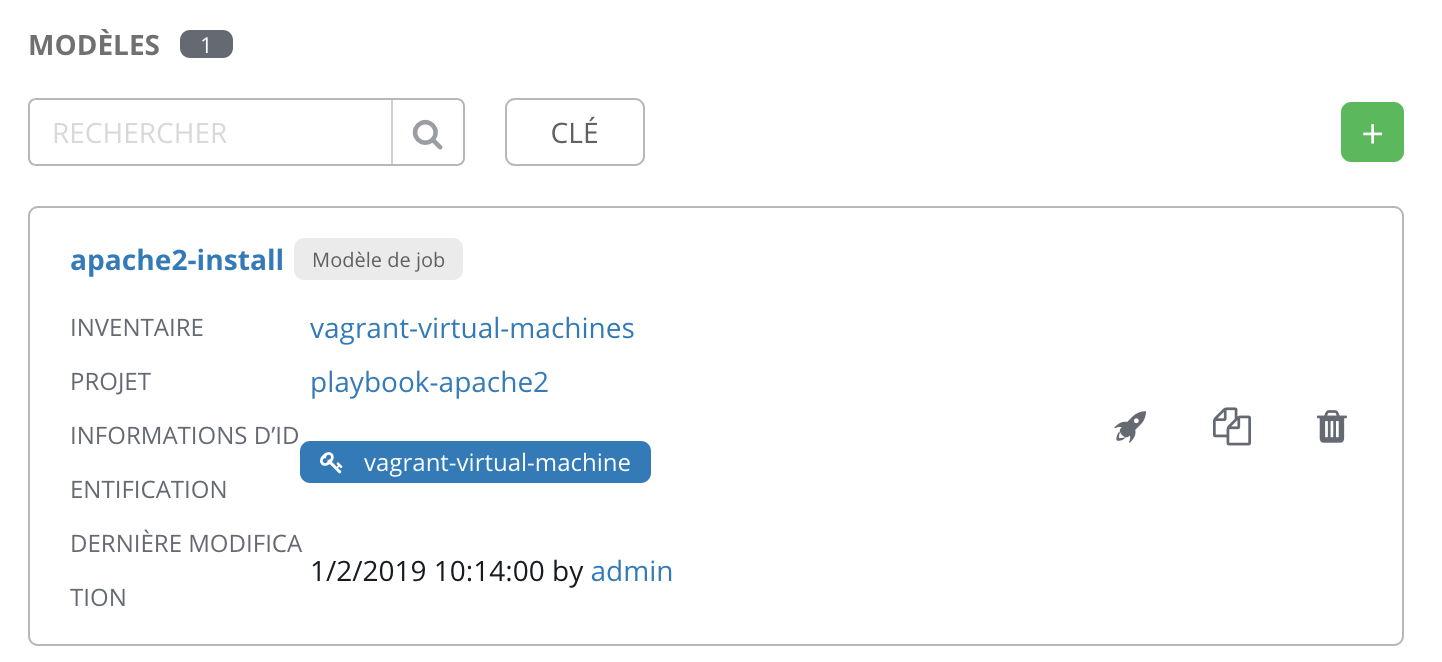
AWX va d’abord venir récupérer les sources du projet, importer les rôles s’il y en a via ansible-galaxy puis exécuter le playbook avec la configuration donnée.
Voici un aperçu après le lancement :
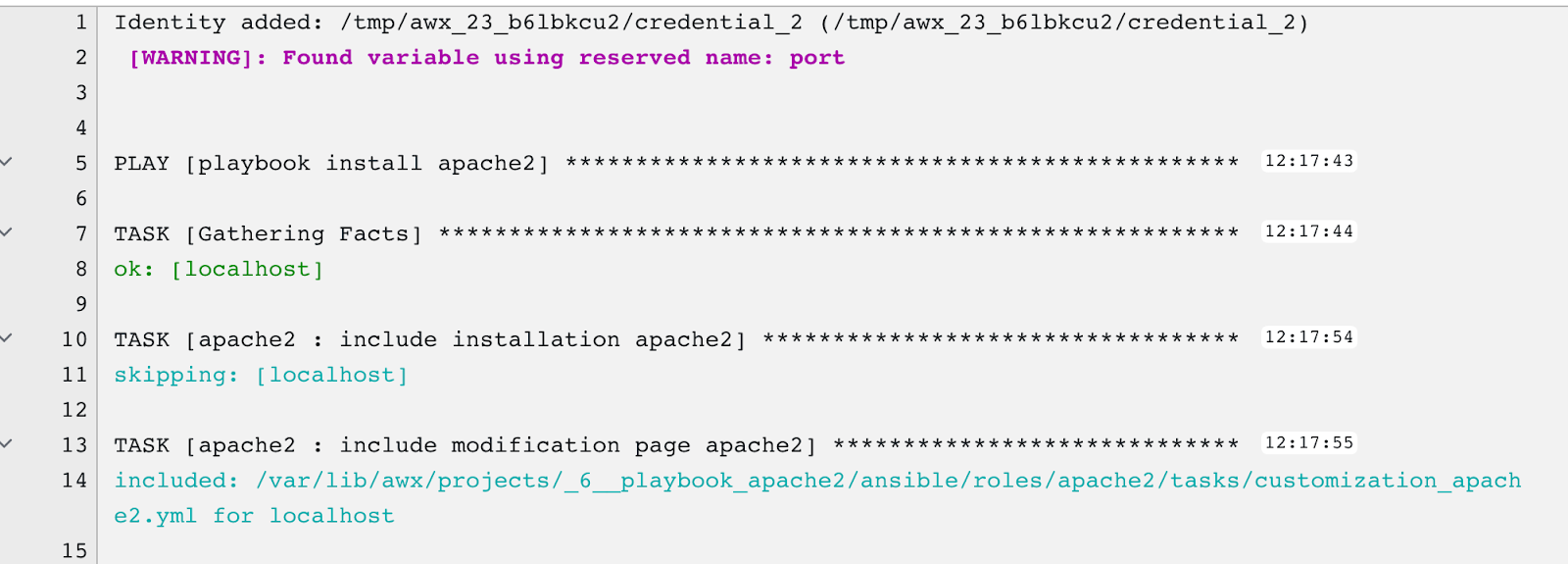
Et voilà ! Vous savez maintenant exécuter un playbook Ansible via AWX. :-)
Nous avons vu à travers cette démonstration le fonctionnement classique d’AWX qui consiste à exécuter à un playbook simple sur une machine distante. En réalité, cet outil permet de faire de choses beaucoup plus complexes comme par exemple, des workflows de playbooks ou encore créer une hiérarchie d’utilisateurs et leur donner des droits différents (ségrégation des rôles), et d’autres fonctionnalités qui ont été présentées dans l’article précédent.
Vous pouvez voir AWX comme une tour de contrôle qui peut piloter l’ensemble des vos déploiements sur vos environnements (dev, pré-prod, production) tout en gardant l’ensemble des traces d’exécution de vos playbooks.
Pour en savoir plus, je vous donne le lien vers la documentation officielle d’AWX/Ansible Tower.

Préambule Dans notre métier, il est une bonne pratique d’utiliser de l’Infrastructure as Code et il n’est pas rare de faire le choix d’utiliser ...

C’est quoi le cloud ? L’idée derrière le cloud est de mettre à disposition sous forme de service à la demande les ressources informatiques (calcul,...

J’exposais dans mon précédent article les contraintes liées à l’automatisation du déploiement de réseaux privés en datacenter et évoquais, sans m’y...