Infrastructure immuable
Quoi de plus stressant qu’un serveur tournant comme une horloge depuis un long moment, et qui a subit plusieurs upgrade système et une quantité...
4 minutes de lecture

Cette gestion de l’état des ressources est indispensable, car elle empêche la divergence entre le code et l’état réel de l’infrastructure. Le problème est que de nombreuses modifications de code entraînent la re-création des ressources, et ont donc un impact important sur les environnements.
Dans cet article, nous chercherons à identifier les situations problématiques, ainsi que les outils dont nous disposons pour re-synchroniser l’état sans impact sur l'infrastructure déployée.
Bien que difficile, le refactoring de code d’infrastructure est nécessaire pour répondre aux nouveaux besoins qui arrivent, et pour garantir la maintenabilité au fil du temps et des changements d’architecture.
Souvent, c’est l’évolution des besoins qui provoque le refactoring. Certaines ressources doivent être renommées, ou déplacées dans des modules pour être ré-utilisées. On peut également avoir besoin de revoir le découpage des stacks lorsque celui-ci n’est plus pertinent.
Parfois, les besoins de refactoring sont amenés par l’outillage. Comme avec l’arrivée de l’expression for_each avec Terraform 0.12, ou des boucles sur les modules avec Terraform 0.13.
Bien que nécessaires, ces changements sont souvent négligés car ils provoquent une re-création des ressources et donc un impact utilisateur fort. Pourtant, comme nous allons le voir, il existe des solutions pour déployer ces changements en toute transparence.
Pour cela, prenons l’exemple d’un “Application Load Balancer” que nous devons renommer dans le code suite au changement du nom de notre application. Nous avons deux solutions à notre disposition.

On ajoute un nouvel ALB dans le code (avec le nouveau nom), et on met à jour la configuration DNS pour qu’il reçoive le trafic. Le déploiement de cette configuration donne le résultat suivant :
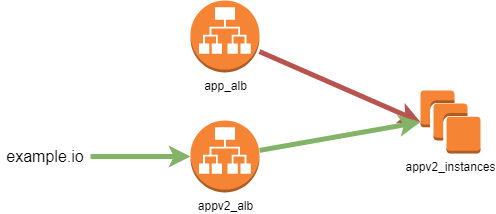
Quand l’ancien ALB ne reçoit plus de trafic (après l’expiration du cache DNS des clients), nous pouvons le supprimer du code et déployer sa suppression.
Cette procédure est simple à mettre en place et fonctionne de manière identique avec les deux outils. En revanche, elle n’est pas utilisable pour les ressources stateful (ex: bases de données) ou pour celles qui ont des contraintes d’unicité (ex: noms de domaines).
L’idée ici est de mettre à jour l’état géré par l’outil d’IaC, pour qu’il corresponde au nouveau code. Cette fois, la façon de faire va dépendre de l’outil utilisé.
Avec Terraform, l’opération se fait grâce à la commande terraform state mv :
Avec CloudFormation c’est plus compliqué, il faut supprimer la ressource de l’état et la réimporter :
L’avantage de cette méthode est qu’elle permet de gérer tous les cas vus plus haut. Par contre, elle sera plus ou moins facile à mettre en place en fonction de l’outil utilisé.

Ce second cas de figure est issu d’une situation rencontrée lors d’une de mes missions. Lors de son démarrage sur AWS, le client avait fait le choix de déployer son infrastructure avec CloudFormation pour gagner du temps. Avec l’évolution de ses besoins, et pour gérer la complexité croissante du code, le client a décidé de passer à Terraform.
Mais comment faire pour gérer les ressources initialement créées avec CloudFormation, sans avoir à recréer la totalité de l’infrastructure?
Dans un premier temps, il faut réécrire le code CloudFormation en Terraform. C’est une étape manuelle, car il n’existe pas d’outil de conversion de code pour le faire pour nous.
Ensuite, nous devons supprimer les ressources de la stack CloudFormation, puis les importer dans le tfstate Terraform, sans supprimer les ressources réelles :
Il est également possible de faire des migrations Terraform vers CloudFormation car ce dernier fournit également des fonctions d’import. Dans les deux cas, on pourra utiliser des tags sur les ressources pour gérer leur stack d’appartenance, et ne pas en perdre en route.

On parle de divergence de configuration lorsque des changements sont faits sur l’infrastructure en dehors de l’outil d’IaC. Il y a alors une désynchronisation entre l’état stocké et la réalité. En fonction de la situation et de l’outil utilisé, une synchronisation manuelle pourra être nécessaire.
De manière générale, les modifications manuelles sont à proscrire lorsqu'on utilise un outil d’IaC. Néanmoins, elles peuvent être nécessaires pour corriger un problème de production en urgence, ou pour tester rapidement un nouveau réglage.
Dans ce cas, on utilisera les fonctions de visualisation des outils (terraform plan, aws cloudformation detect-stack-drift) pour identifier les divergences. La correction à appliquer dépendra de la situation :
Certaines opérations complexes ne peuvent être réalisées avec les outils d’IaC. C’est le cas par exemple des procédures de récupération des systèmes distribués, pour lesquels il faut implémenter une logique de réconciliation souvent complexe.
Il arrive également que des opérations ne soient pas prises en charge par l’outil. Par exemple, Terraform gère la restauration d’une base de données RDS à partir d’un snapshot, mais pas le Point In Time Restore.
Pour gérer ces cas, on automatise le processus de récupération à l’aide d’un script dans notre langage préféré, puis on utilise les fonctions de manipulation de l’état vues précédemment pour le réconcilier.
Si l’on prend l’exemple de restauration Point In Time d’une base de données RDS, les étapes sont les suivantes :
Après la lecture de cet article, j’espère que les contraintes d’utilisation d’un outil d’IaC avec gestion d’état ne seront plus un frein pour vous. Plus d’excuses pour remettre à plus tard un refactoring important, ou pour faire certaines opérations manuellement “parce que c’est plus simple”.
En revanche, lors des opérations de manipulation de l’état, il est primordial de suivre certaines bonnes pratiques pour ne pas avoir de mauvaises surprises :


Quoi de plus stressant qu’un serveur tournant comme une horloge depuis un long moment, et qui a subit plusieurs upgrade système et une quantité...

Nos infrastructures peuvent être construites, déployées, répliquées grâce à ces API. Des outils dits d’Infrastructure as Code (IaC) comme AWS Cloud...
