
8 minutes de lecture

La sécurité applicative est un enjeu qui doit être pris en compte dès la conception du projet et chaperonné tout au long du cycle de développement.
S’assurer de la qualité et de la sécurité du code tout au long du cycle de développement applicatif peut représenter une tâche fastidieuse, complexe et chronophage. Cet article vous présentera un type d'outil technique aidant à répondre à ce challenge en exposant les failles de sécurité provenant des dépendances applicatives. Nous vous présenterons son fonctionnement, comment l'exploiter pour corriger les vulnérabilitiées détectées et les intérêts de son utilisation.
Nous avons fait en sorte que cet article soit accessible aux métiers de gouvernance et de direction. La totalité des termes techniques sont référencés dans le glossaire en fin d’article, n’hésitez pas à le consulter !
Technologies de sécurisation du code applicatif
Pour pallier les problèmes de sécurité liés au développement applicatif, différentes technologies ont vu le jour. Elles permettent d’analyser le code sous toutes les coutures (contenu, dépendance, exécution, etc.). Couplées à des outils d’intégration et de développement continus (CI/CD), il est possible d’automatiser le processus de sécurisation du code et de l’intégrer au cycle de développement de manière naturelle.
Sécurisation des dépendances
Contexte
Aujourd’hui l’open-source est partout. Ce mouvement qui rassemble ses valeurs autour du partage et de la transparence a su trouver sa voie auprès de nombreux projets de développement et des entreprises. L’utilisation de dépendances open-source permet de ne pas réinventer la roue à chaque projet, de gagner du temps et de facto, de l’argent. En termes de sécurité, l’avantage de l’open-source est que le code est auditable car visible par tous. Mais comme tout projet, il arrive que des failles soient détectées.
Lorsqu’une dépendance est ajoutée à un projet, les vulnérabilités qui lui sont associées ne sont pas forcément analysées, soit pour des raisons de manque de compétences ou soit d’organisation agnostique de la sécurité. On se contentera de prendre la dernière version de la dépendance qui répond à notre besoin.
Le problème est que cette dépendance peut contenir des vulnérabilités, qu’elles soient déjà connues ou découvertes plus tard. Il faut trouver une solution qui nous permette de connaître facilement si une dépendance de notre projet est vulnérable et si c’est le cas, comment la traiter. C’est exactement le travail que remplissent les analyseurs de dépendances :
- Les Software Composition Analysis (SCA), en français analyse de la composition du logiciel, sont des outils permettant de découvrir les vulnérabilités connues associées aux composants/librairies tierces d’un projet. Cela inclut bien entendu les librairies open-sources, mais aussi les composants développés en interne si une base de données de vulnérabilités est maintenue.
- Les Open Source Analysis (OSA) sont des SCA dont le focus est uniquement sur les composants/librairies open-source. Le terme ne prend pas en compte les dépendances “privées”. On préférera dans cet article parler de SCA plutôt que d’OSA.
Il existe de nombreuses solutions de SCA :
- DependencyTrack et DependencyCheck sont des SCA open source développés par l’OWASP
- Snyk est un SCA qui fonctionne en SaaS
- GitLab intègre, dans sa version entreprise, un scanner de dépendances directement
- Checkmarx, WhiteSource et Veracode offrent des solutions en SaaS
- Et d’autres encore …
Fonctionnement
Le comportement qui sera décrit ici est celui de Dependency-Track. D’autres solutions de SCA peuvent fonctionner différemment, bien que dans les grandes lignes cela reste similaire.
Un analyseur de dépendances a besoin de 2 ressources pour fonctionner :
- les dépendances de votre projet (l’objet d’étude)
- des bases de données de vulnérabilités (notre source de vérité).
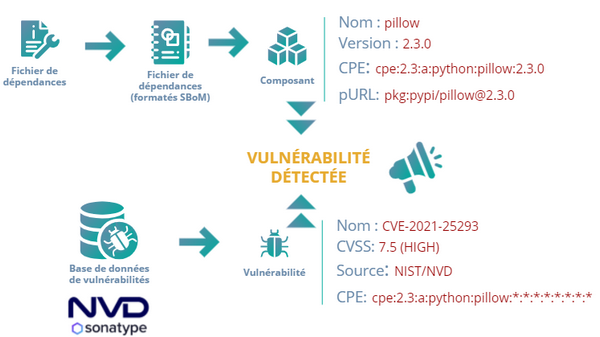
Énumérer les dépendances de votre projet dépendra du langage utilisé. Il existe différents outils et commandes pour cela. En Python, la convention veut que la liste des dépendances d’un projet soit stockée dans un fichier nommé requirements.txt. Une fois ce fichier de dépendance généré pour votre projet, il faut que celui-ci soit rendu “présentable” à l’analyseur de dépendances.
Dependency-Track ne travaille pas avec des fichiers de dépendances bruts, il travaille avec des BoM (Build of Material) ou plus précisément des SBoM (Software Build of Material).
Concrètement, ce sont des fichiers de dépendances nomenclaturés contenant des informations relatives aux dépendances, au format XML.
Exemple de SBoM avec un composant :
<?xml version="1.0" encoding="UTF-8"?>
<bom version="1" xmlns="http://cyclonedx.org/schema/bom/1.0">
<components>
<component type="library">
<publisher>Hynek Schlawack</publisher>
<name>attrs</name>
<version>19.3.0</version>
<description>Classes Without Boilerplate</description>
<hashes>
<hash alg="MD5">15c8ca1fd31e80e02b38064e835ddcd8</hash>
<hash alg="SHA-256">08a96c641c3a74e44eb59afb61a24f2cb9f4d7188748e76ba4bb5edfa3cb7d1c</hash>
</hashes>
<licenses>
<license>
<name>MIT</name>
</license>
</licenses>
<purl>pkg:pypi/attrs@19.3.0</purl>
<modified>false</modified>
</component>
</components>
</bom>
Ce format permet au SBoM d’identifier de manière unique chaque dépendance, mais aussi de mettre à disposition toutes ces métadonnées aux utilisateurs.
Comme nous l’avons précisé, un SCA a aussi besoin de bases de données de vulnérabilités. Celles-ci conservent l’ensemble des versions de composants open-source et leurs vulnérabilités associées. Il existe plusieurs bases de données de vulnérabilités (CVE) comme la NVD (National Vulnerability Database) maintenue par le NIST (agence du département du Commerce des USA) ou encore l’OSS Index, maintenu par la société Sonatype. Outre le fait de mettre à disposition des vulnérabilités, ces bases de données indiquent la criticité de celles-ci au travers d'un score (CVSS) et l’explicitent dans son fonctionnement.
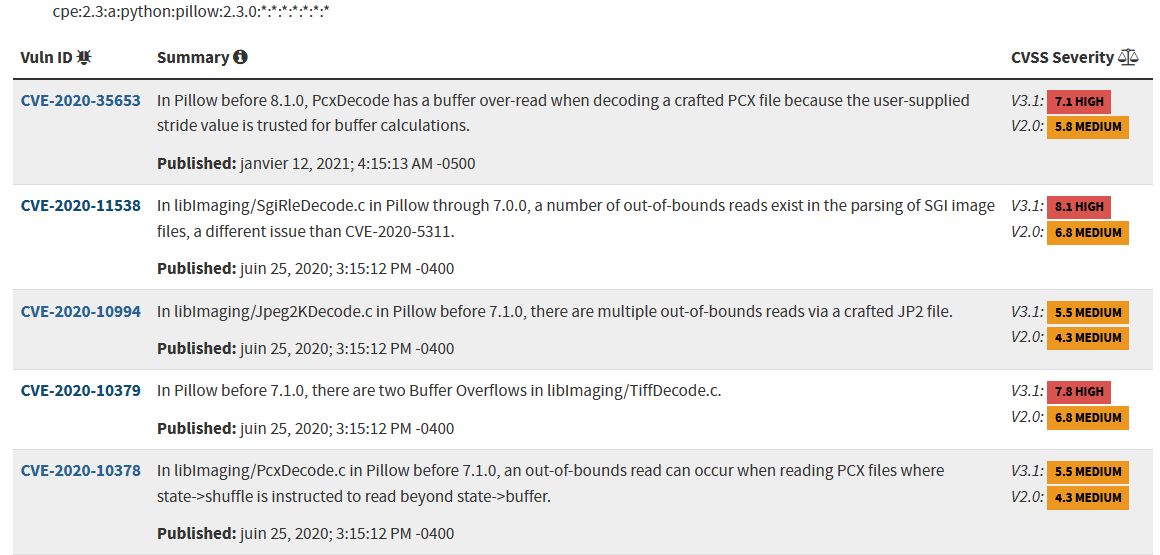
Le SCA a donc en sa possession un inventaire complet des composants et de leurs versions et peut communiquer avec des bases de données de vulnérabilités. Mais comment peut-il bien faire le lien entre un composant et une vulnérabilité ?
Il existe 2 standards pour identifier un couple composant-version(s) :
- pURL : pkg:pypi/pillow@2.3.0
- CPE (v2.2) : cpe:/a:python:pillow:2.3.0
- CPE (v2.3) : cpe:2.3:a:python:pillow:2.3.0:*:*:*:*:*:*:*
Dans l’exemple ci-dessus, on identifie le package Python Pillow en version 2.3.0 pour chacun des 2 formats. Attention, un CPE ou pURL représente toujours un seul composant mais peut référencer plusieurs versions ! À la surprise générale, une vulnérabilité peut être présente sur plusieurs versions :)
C’est ce lien qui permet à l’analyseur de dépendances de faire la relation entre le composant et une vulnérabilité.
Réaction
Grâce aux analyseurs de dépendances vous avez à diposition une liste de vulnérabilités qui impactent vos dépendances, il s'agit maintenant de les traiter. Reste à répondre au célèbre QQOQCCP (pour « Qui ? Quoi ? Où ? Quand ? Comment ? Combien ? Pourquoi ? »). Malheureusement avoir ce type d'outil en place ne suffit pas, cela ne permet que de détecter les vulnérabilitiés, pas de les corriger. Pour cela il vous faut définir des processus clairs et avoir à disposition les compétences adéquates au sein de vos équipes. Un rôle ou un pôle doit être désigné à la charge de ce sujet de sécurité voir les équipes directement (cela dépendant évidemment de votre contexte). Cela peut être un pôle sécurité, un security champion, un DevSecOps, etc. Cette entité/personne aura la charge de veiller à ce que les failles détectées soient priorisées et prises en charge rapidement en fonction de leur criticité et évidemment de déterminer la solution pour la corriger. Il y a plusieurs solutions pour traiter une vulnérabilité :
- Traiter : On corrige la vulnérabilité en mettant à jour la dépendance ou en corrigeant nous même si cela est possible.
- Tolérer : On accepte de ne pas corriger la vulnérabilité, soit car le risque de criticité est faible, soit car l'implémentation qui en est faite n'assujetie pas le projet à la faille (on parlera alors de faux-positif)
- Terminer : On change de dépendance, possible mais cela dépendra évidemment de l'adhérence du projet à sa dépendance.
Ce choix technique du traitement de la vulnérabilité incombera en général à la personne technique en charge du projet. Il est important qu'elle possède les compétences adéquates pour comprendre les tenants et aboutissants de la vulnérabilité ou du moins qu'elle soit accompagnée par une personne qui possède ces compétences.
Intérêt
Un analyseur de dépendances a pour objectif principal de mettre en exergue les dépendances vulnérables. En général, un SCA recèle d’autres fonctionnalités intrinsèques :
- Dresser un inventaire complet des dépendances de vos projets. Que ce soit en termes de librairie/framework, application, conteneur, système d’exploitation, etc. Et surtout d’en associer leurs versions, étant donné qu’une vulnérabilité n’est pas toujours associée à toutes les versions d’un composant (et heureusement). C’est indirectement ce couple nom+version qui va permettre au SCA d’identifier quel composant est vulnérable.
- Identifier les vulnérabilités associées à un composant : une version spécifique d’une librairie open-source peut être associée à plusieurs vulnérabilités. Un SCA permet de savoir lesquelles, leur nature et leur criticité.
- Savoir comment la vulnérabilité impacte le code. En fonction de la manière dont a été implémenté un composant dans le projet, celui-ci peut ne pas être vulnérable. Par exemple, si une fonction particulière est mise en cause alors qu’elle n’est pas utilisée dans le projet, elle n’impactera pas celui-ci.
- Savoir comment traiter la vulnérabilité. Les bases de données de vulnérabilité proposent parfois des moyens de remédiations pour traiter la faille ou la mitiger. Bien entendu, la mise à jour reste la solution à prioriser.
- Dans quels projets sont présentes les vulnérabilités. Un bon SCA sera à même de vous offrir une vue d’ensemble de vos projets, leurs composants et leurs vulnérabilités. Ainsi, vous pouvez détecter simplement et rapidement quels sont les projets atteints par la dernière vulnérabilité découverte.
- Réagir rapidement et efficacement. En fonction de sa configuration, un SCA scanne régulièrement vos projets pour y détecter des vulnérabilités. Vous pouvez y configurer des déclencheurs pour être alerté(s), vous ou vos équipes.
- Mettre en évidence des licences des composants tierces. Qui dit composant open-source dit licence ! En fonction de la licence, votre application peut être impactée légalement.
Cette technologie a de nombreux avantages et peu d’inconvénients. On peut la considérer comme relativement fiable étant donné qu’elle est peu assujettie aux faux-positifs. Concrètement, sa fiabilité dépendra de votre capacité à soumettre la totalité des dépendances de vos projets à l’analyseur de dépendances et des bases de données de vulnérabilités qui lui sont associées. Si elles sont mises à jour régulièrement et exhaustives, la majorité des vulnérabilités connues présentes dans vos projets seront détectées.
On peut aussi affirmer que ce type de solution est peu coûteux. Il existe de nombreux SCA, qu’ils soient open-source ou en SasS. Vous devriez pouvoir trouver la solution adaptée à votre besoin pour un investissement moindre. Quant à l’investissement humain, le SCA reste un outil facile à prendre en main. Pour en tirer le maximum de profit, l'automatisation de son utilisation au travers de compétences DevOps est indispensable. Tout comme le fait d’avoir des personnes à même d’interpréter les risques d’une vulnérabilité.
Conclusion
J’espère que cet article vous aura plu et qu’il vous a permis d’apprendre et de comprendre l’intérêt d'un analyseur de dépendances. La sécurité est au cœur des cybers-enjeux de demain. Il est important de l’adresser dès maintenant au travers de vos processus, outils et compétences. Les outils d’analyse de code permettent de répondre en partie au besoin de sécurisation de l’application. Nous verrons dans de futurs articles qu’il existe d’autres technologies qui pourront nous aider à relever le défi de la sécurité.
Glossaire
BoM (Build Of Material) / SBoM (Software Build of Material) : définit et décrit le contenu de ce qui est utilisé dans la fabrication et l'emballage du produit à livrer. Dans les chaînes d'approvisionnement en logiciels, cela fait référence au contenu de tous les composants fournis avec le logiciel, y compris les auteurs, les éditeurs, les noms, les versions, les licences et les droits d'auteur.
CI/CD (Continuous Integration / Continuous Deployment) : combinaison des pratiques d'intégration continue et de livraison continue ou de déploiement continu.
CPE (Common Platform Enumeration) : système de dénomination structuré pour les systèmes, les logiciels et les progiciels de technologie de l'information. Fondé sur la syntaxe générique des Uniform Resource Identifiers (URI), un CPE comprend généralement le fournisseur, le nom du produit et la version.
CVE (Common Vulnerabilities and Exposures) : dictionnaire des informations publiques relatives aux vulnérabilités de sécurité.
CVSS (Common Vulnerability Scoring System) : système d'évaluation standardisé de la criticité des vulnérabilités selon des critères objectifs et mesurables.
CWE (Common Weakness Enumeration) : liste de types de faiblesses logicielles et matérielles.
NIST (National Institute of Standards and Technology) : agence du département du Commerce des États-Unis. Son but est de promouvoir l'économie en développant des technologies, de la métrologie et des standards de concert avec l'industrie.
NVD (National Vulnerability Database) : base de données de vulnérabilités maintenue par le NIST.
OSA (Open Source Analysis) : outil d’analyse des dépendances open source d’une application.
OWASP : communauté en ligne travaillant sur la sécurité des applications Web. Sa philosophie est d'être à la fois libre et ouverte à tous.
PURL (Package URL) : chaîne URI utilisée pour identifier et localiser un paquet logiciel de manière pratiquement universelle et uniforme parmi les langages de programmation, les gestionnaires de paquets, les conventions d'emballage, les outils, les API et les bases de données.
SaaS (Software as a Service ou logiciel en tant que service) : modèle d'exploitation commerciale des logiciels dans lequel ceux-ci sont installés sur des serveurs distants plutôt que sur la machine de l'utilisateur.
SCA (Software Composition Analysis) : outil d’analyse des dépendances d’une application.
SQLi (injection SQL) : groupe de méthodes d'exploitation de failles de sécurité d'une application interagissant avec une base de données.
XSS (Cross Site Scripting) : type de faille de sécurité des sites web permettant d'injecter du contenu dans une page, provoquant ainsi des actions illégitimes sur les navigateurs web visitant la page.
Et la saga continue...
A lire et à relire, les articles de la saga "Sécurisation du cycle de développement applicatif".
-Episode 1 : "Analyse des dépendances"
-Episode 2 : "Analyse du code"

Comment appliquer de la conformité dans le Cloud avec Cloud Custodian ?
Introduction L’usage du cloud dans les entreprises ne fait plus débat. Bien utilisé, il devient moteur d’avantages concurrentiels et ouvre la voie à...

Revue de Presse de Mai 2018
Announcing Docker Enterprise Edition 2.0 - Docker Blog Après une longue attente suite à son annonce à la DockerCon de Copenhague en octobre dernier,...