 Stéphane Trébel
Stéphane Trébel
Migrer des applications legacy vers Kubernetes : défis et bonnes pratiques
Votre organisation a décidé d’adopter une plateforme Cloud ?C’est l’occasion rêvée pour envisager un move to cloud global du système d’information....

Cet article est le deuxième d’une série qui consiste à plonger en profondeur dans Cilium, l’outil novateur de gestion de réseau d’un cluster Kubernetes. La dernière fois, nous avions introduit le sujet en analysant l’installation de Cilium et ce qui en fait sa spécificité. Aujourd’hui, nous allons pouvoir rentrer dans le vif du sujet en abordant concrètement et techniquement certains aspects techniques de Cilium, à commencer par :
Le dernier article sera, lui, dédié à ces exigences non fonctionnelles fondamentales qui balisent notre métier : la Sécurité et l’Observabilité.
Cilium est capable de prendre en charge l’équilibrage de charge des services. Ce processus natif de l’API Kubernetes consiste en deux étapes :
Il n’y a qu’une seule condition pour « activer » la possibilité de faire de l’équilibrage de charge dans Cilium, c’est de créer une Custom Resource de type CiliumLoadBalancerIPPool qui va contenir, tout simplement, un CIDR.
Pour rappel : Un CIDR (Classless Inter-Domain Routing) est la représentation d’un sous-réseau par une adresse IP et son masque de sous réseau (par exemple "172.19.0.0/16") du pool d’adresses utilisables pour l’attribution à un service Kubernetes de type LoadBalancer.
Un exemple :
apiVersion: "cilium.io/v2alpha1"
kind: CiliumLoadBalancerIPPool
metadata:
namespace: kube-system
name: "my-pool"
spec:
cidrs:
- cidr: "172.19.255.0/24"
Dès que la CiliumLoadBalancerIPPool (nom raccourci : ippool) est créée, les services de type LoadBalancer qui étaient en statut <Pending> (faute de configuration activant l’équilibrage de charge) se voient automatiquement attribuer une adresse IP.
Mais, avoir une adresse IP externe, c'est bien, faire en sorte que le reste du monde soit au courant, c’est mieux !
Une fois qu’un service dispose d’une adresse IP externe prête à être utilisée de manière publique (soit directement, soit au travers d’un nom de domaine) il faut pouvoir faire en sorte que les réseaux soient au courant de son existence. C’est un mécanisme dédié, appelé Announcement, qui remplit cette tâche.
Il y a deux grandes méthodes (entre autres) d’annonce qui peuvent s’appliquer ici :
Celles et ceux qui ont utilisé MetalLB dans sa configuration par défaut seront en terrain familier : c’est exactement de ça dont il s’agit.
En résumé rapide :
Si un autre nœud reçoit une requête ARP concernant l’adresse IP du service exposé, il répond avec l’adresse du nœud qui porte le service exposé et une redirection sNAT (Source Network Address Translation, un mode de redirection de trafic qui change l’adresse IP de la source) est appliquée, ce qui permet de rediriger le trafic au sein du cluster :

Redirection layer2/ARP classique
Cela a donc toutes les caractéristiques d’un équilibrage de charge, même s’il y a la possibilité que le trafic arrive initialement sur un nœud occupé, voire hors service, avant d’être redirigé vers le nœud qui expose effectivement le service. Ceci étant dit, il y a de toute façon un problème de fond : on ne veut pas que les nœuds passent leur temps à se demander lequel d’entre eux porte le service exposé, on veut que le trafic soit correctement routé dès le départ.
C’est pour ça que Cilium ne se repose pas sur la méthode ARP, mais sur la seconde méthode, basée sur BGP.
La méthode BGP est extrêmement puissante, car c’est elle qui gère la quasi-totalité des annonces d’adresses IP sur Internet. Elle repose sur une logique finalement assez simple :
Dans Cilium, la fonctionnalité pérenne pour gérer le BGP par Cilium se fait en mettant la valeur --set bgpControlPlane.enabled=true dans le Chart Helm, ou en installant Cilium par la CLI en y ajoutant l’option --enable-bgp-control-plane=true. Un ancien mode de fonctionnement de BGP est disponible dans Cilium mais déprécié en 1.13 donc inutile de s’y attarder ici.
Cilium permet de créer une Custom Resource de type CiliumBGPPeeringPolicy qui va indiquer :
Par exemple, si on veut une politique qui :
Schématisé, ça donnerait ça :
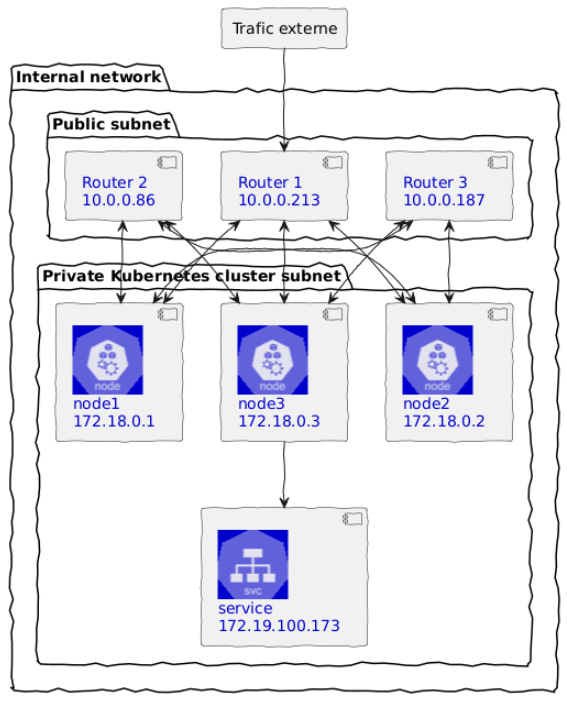
Exemple de maillage entre des nœuds et des routeurs avec BGP
On peut alors écrire le manifeste suivant :
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: 01-bgp-peering-policy
spec: # CiliumBGPPeeringPolicySpec
nodeSelector:
matchLabels:
bgp-policy: a
virtualRouters: # []CiliumBGPVirtualRouter
- localASN: 65000
exportPodCIDR: true
serviceSelector:
matchExpressions:
# Force broadcasting all services to upstream router
- {key: somekey, operator: NotIn, values: ['never-used-value']}
neighbors: # []CiliumBGPNeighbor
- peerAddress: 10.0.0.0/16
peerASN: 65000
Il suffit alors de correctement labelliser un nœud pour que la politique s’applique :
$ kubectl label nodes my-node bgp-policy=a
node/my-node labeled
Maintenant se pose la question : « Comment valider que la politique BGP s’applique correctement ? »
C’est là qu’intervient un outil comme BIRD (The « BIRD Internet Routing Daemon ») qui permet de gérer automatiquement le routage des systèmes UNIX-like en s’appuyant sur un certain nombre de règles et de protocoles dont BGP. On peut donc utiliser BIRD pour simuler le comportement qu’aurait un routeur qui gère nativement le BGP.
Sans rentrer dans la configuration fine de BIRDv2, la partie importante à configurer est celle-ci :
protocol bgp router1 {
local 172.18.0.213 as 65000;
neighbor 172.18.0.4 as 65000;
ipv4 {
import all;
export all;
};
}
Cette entrée permet, de manière bilatérale, d’échanger les informations de routage IPv4 entre deux AS (ici local et neighbor au sein d’un AS virtuel ayant pour ASN 65000). Naturellement, vous pouvez configurer BIRD pour ne faire en sorte que de recevoir, que de donner, etc. De plus, si vos AS nécessitent une authentification, une gestion sécurisée est possible pour éviter de donner ou de recevoir n’importe quoi à n’importe qui sur le même réseau.
Une fois la configuration effectuée, un birdc show protocols all permet de valider que la connexion est bien établie avec le(s) nœud(s) et que les adresses IP publiques sont bien annoncées :
vm1 BGP --- up 09:02:04.293 Established
BGP state: Established
Neighbor address: 10.17.31.50
Neighbor AS: 65000
Local AS: 65000
Neighbor ID: 198.20.0.4
Local capabilities
<...snip...>
Routes: 5 imported, 3 exported, 1 preferred
Route change stats: received rejected filtered ignored accepted
Import updates: 5 0 0 0 5
Import withdraws: 0 0 --- 0 0
Export updates: 10 7 0 --- 3
Export withdraws: 0 --- --- --- 0
BGP Next hop: 10.17.31.1
IGP IPv4 table: master4
Par exemple, ici, nous avons un service exposé en 172.18.255.107, et il apparaît comme tel dans un ip route (l’entrée mentionne d’ailleurs qu’elle provient de bird). Si on essaie d'accéder au service exposé à l’aide de curl, tout fonctionne comme prévu, car notre système a bien une route définie pour atteindre l’IP du service exposé :
$ ip route | grep 172.18.255.107
172.18.255.107 via 172.18.0.2 dev br-3b9d79dd2b15 proto bird metric 32
$ curl 172.18.255.107
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
Dans Cilium toutes les politiques de routage se font à l’aide d’une Custom Resource de type CiliumNetworkPolicy. Tous les détails d’application de la politique (et donc indirectement sa couche OSI de fonctionnement) se retrouvent dans la définition d’une ressource de ce type.
Ceci est naturellement dû au fait que l’eBPF permet à Cilium d’avoir un niveau de compréhension total du modèle, car étant présent dans le noyau Linux qui sous-tend tout le cluster.
La différence principale entre une CiliumNetworkPolicy et la NetworkPolicy du standard Kubernetes est qu’elle va utiliser les sélecteurs pour déterminer les entités au sens Cilium (des pods, services, le réseau hôte du cluster, le monde extérieur, etc.) sur lesquelles s’applique la politique réseau, là où la NetworkPolicy va uniquement chercher à déterminer les pods sur lesquels vont s’appliquer la politique réseau.
L’autre différence est la finesse de la politique : là où une NetworkPolicy traite des sujets sur les couches L3 et L4 du modèle OSI, une CiliumNetworkPolicy permet d’aborder les sujets de politique réseau sur la couche L7 en plus des deux autres. De plus, comme on va le voir, elle permet de mélanger les différentes caractéristiques des couches si c’est là notre besoin.
La couche L3 du modèle OSI est celle qui traite de la couche « réseau » du modèle (soit tout ce qui a trait aux adresses IP, à IPSec, ICMP, etc.). Elle se situe entre la couche L2 (celle des adresses MAC, des paquets ARP, etc.) et la couche L4 (TCP, UDP, etc.) qu’on verra plus loin.
Créer une politique de routage sur la couche L3 consiste à définir des règles qui vont concerner plus ou moins directement les adresses IP. On y retrouve le désormais fameux CIDR, mais aussi tout ce qui peut trivialement se convertir en adresse IP, comme les noms de domaines ou même les services Kubernetes (qui ne sont finalement qu’une IP devant d’autres IP). Et comme en plus dans Kubernetes, on peut adresser plusieurs services avec des étiquettes (« Labels »), il est également possible de définir une politique L3 en n’utilisant que les labels.
De fait, les manifestes suivants sont des manifestes traitant de la couche L3 :
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "front-to-backends"
spec:
endpointSelector:
matchLabels:
role: backend
ingress:
- fromEndpoints:
- matchLabels:
role: frontend
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "dev-to-host"
spec:
endpointSelector:
matchLabels:
env: dev
egress:
- toEntities:
- host
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "cidr-rule"
spec:
endpointSelector:
matchLabels:
app: myService
egress:
- toCIDR:
- 20.1.1.1/32
- toCIDRSet:
- cidr: 10.0.0.0/8
except:
- 10.96.0.0/12
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "to-fqdn"
spec:
endpointSelector:
matchLabels:
app: test-app
egress:
- toFQDNs:
- matchName: "my-remote-service.com"
Attention : Il est à noter que tant qu’un endpoint (au sens de Cilium) n’est concerné par aucune politique de routage d’entrée (respectivement sortie) de trafic, il est en Default Allow pour l’entrée (resp. sortie) de trafic. Par contre, dès qu’un endpoint est concerné par une seule règle d’entrée (resp. sortie) de trafic, il passe automatiquement en Default Deny sur l’entrée (resp. la sortie) de trafic. Il faut alors s’assurer que la/les politiques qui l’incluent sont correctement configurées. Cela peut surprendre les plus novices, mais la commande cilium endpoint list permet de voir le mode de fonctionnement qui s’applique à chaque ingress sur l’entrée (resp. la sortie) de trafic :
ENDPOINT POLICY (ingress) POLICY (egress) IDENTITY
ENFORCEMENT ENFORCEMENT
123 Enabled Disabled 34512
Comme on peut le constater, la définition d’une politique réseau L3 est très souple dans Cilium.
La couche L4 du modèle OSI est celle qui traite de la couche « transport » du modèle (soit tout ce qui a trait aux protocoles qui s'appuient sur le réseau, comme TCP et UDP par exemple). Elle se situe entre la couche L3 (celle des adresses IP) et la couche L5 (SOCKS, NetBIOS, PPTP, RTP, etc.).
Créer une politique de routage sur la couche L4 permet d’aller un peu plus loin qu’avec la L3. En effet, la L4 va permettre d’adresser les spécificités de transport, à savoir les ports ainsi que les protocoles, là où une L3 va autoriser ou interdire le trafic vers une adresse IP dans sa globalité.
Ce sont donc les politiques réseaux d’une plus grande finesse qui sont gérées de cette manière :
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "l4-rule"
spec:
endpointSelector:
matchLabels:
app: myService
egress:
- toPorts:
- ports:
- port: "80"
protocol: TCP
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "cidr-l4-rule"
spec:
endpointSelector:
matchLabels:
role: crawler
egress:
- toCIDR:
- 192.0.2.0/24
toPorts:
- ports:
- port: "80"
protocol: TCP
On voit là la souplesse et la granularité fine que permet l’inspection des données sur de multiples couches du modèle OSI.
La couche L7 du modèle OSI, peut-être la plus connue, est celle qui traite de la couche « application » du modèle (soit tout ce qui a trait au plus haut niveau comme les protocoles HTTP, FTP, SMTP, etc.). Elle se situe au-dessus de la couche L6 (celle sur laquelle sont basés les protocoles de haut niveau, et qui comprend MIME, ASCII, et PGP).
Étant la plus haute des couches, c’est également celle qui va permettre de renvoyer des informations plus précises sur les violations de politiques réseau : typiquement, une violation de type HTTP va permettre de renvoyer une erreur 403 plutôt que de simplement empêcher le trafic de passer.
Voici une liste d’exemples de politiques réseaux concernant la couche L7 :
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "Allow HTTP GET /public from env=prod to app=service"
endpointSelector:
matchLabels:
app: service
ingress:
- fromEndpoints:
- matchLabels:
env: prod
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: "GET"
path: "/public"
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "l7-rule"
spec:
endpointSelector:
matchLabels:
app: service
ingress:
- toPorts:
- ports:
- port: '80'
protocol: TCP
rules:
http:
- method: PUT
path: "/public"
headers:
- 'X-My-Header: true'
Cilium est d’ailleurs en train d’aller encore plus loin dans le traitement des politiques, car une implémentation expérimentale d’un méta-protocole Kafka est en cours d’implémentation. Si elle advient, elle pourra permettre de définir des règles de trafic en se basant sur des informations propres à Kafka, comme les roles et les topics:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "enable empire-hq to produce to empire-announce and deathstar-plans"
endpointSelector:
matchLabels:
app: kafka
ingress:
- fromEndpoints:
- matchLabels:
app: empire-hq
toPorts:
- ports:
- port: "9092"
protocol: TCP
rules:
kafka:
- role: "produce"
topic: "deathstar-plans"
- role: "produce"
topic: "empire-announce"
Nul doute que d’autres méta-protocoles (qu’on pourrait considérer comme étant un hypothétique niveau L8 dans le modèle OSI) pourraient apparaître dans le futur !
Rentrer dans le cœur de Cilium nous a permis de constater à la fois la flexibilité et la puissance de sa configuration, pour une application à de multiples cas d’usage.
Le prochain article nous permettra d’en apprendre encore davantage sur Cilium, en passant des politiques réseaux au maillage de services, à l’inspection TLS, et à l’observabilité détaillée de Cilium lui-même !
Votre organisation a décidé d’adopter une plateforme Cloud ?C’est l’occasion rêvée pour envisager un move to cloud global du système d’information....

Google Cloud Platform cherche son public & dictature ou démocratie pour les choix techniques

Quoi de plus stressant qu’un serveur tournant comme une horloge depuis un long moment, et qui a subit plusieurs upgrade système et une quantité...