

Sommaire
Découverte
Dans le monde DevOps, l’automatisation est un pilier essentiel. La CI/CD en est une expression sur laquelle l’approche GitOps a de plus en plus de succès.
Cette dernière n’est cependant pas comprise à sa juste valeur du fait d’une vulgarisation excessive. L'expression popularisée par Weaveworks en 2017 ne reflète pourtant rien de neuf et il est fort probable que vous ayez utilisé cette approche sans tout à fait le savoir.
La démocratisation de Kubernetes en a accéléré l’adoption et fait ressortir le besoin de cadrage autour de la notion de GitOps. Parmi les acteurs qui en proposent une implémentation, Weaveworks et Intuit avec respectivement Flux et Argo CD, sont ceux qui sortent du lot.
Flux en particulier nous offre une solution Kube Native élégante, prenant parti des fonctionnalités Kubernetes en tant que plateforme.
Cette solution repose sur quelques principes clés sans lesquels il est possible de passer à côté de la richesse et la puissance de cet outil.
Nous vous proposons de passer en revue ces points afin d’avoir une vision claire du GitOps et surtout pouvoir le penser dans un contexte Kube Native via Flux.
GitOps, pull over push
Une recherche du terme GitOps est susceptible de remonter plusieurs définitions qui ne sont pas équivalentes. Partons donc de celle fournit par Weaveworks, à l’origine de l’expression et qui remonte les points suivants. Nous les laisserons dans leur forme anglaise pour ne pas risquer de dénaturer le propos :
- The entire system is described declaratively
La description de l’état du système est le seul élément d’intérêt. La logique de sa mise en place est hors scope. - The canonical desired system state versioned in Git
L’état désiré de ce système est versionné. En général ça sera avec Git.
Git devient alors notre source unique de vérité vis-à-vis de l’état du système. - Approved changes that can be automatically applied to the system
L’état décrit et approuvé doit automatiquement être reflété sur notre plateforme cible. - Software agents to ensure correctness and alert on divergence
Un “agent” surveille la source de vérité et s’assure de la cohérence de cette dernière avec la ou les plateformes sous son contrôle.
Pour toute personne pratiquant la CI/CD les trois premiers points n’apportent rien de neuf. Certaines définitions du GitOps s’y arrête d’ailleurs et rendent le 4ème point optionnel.
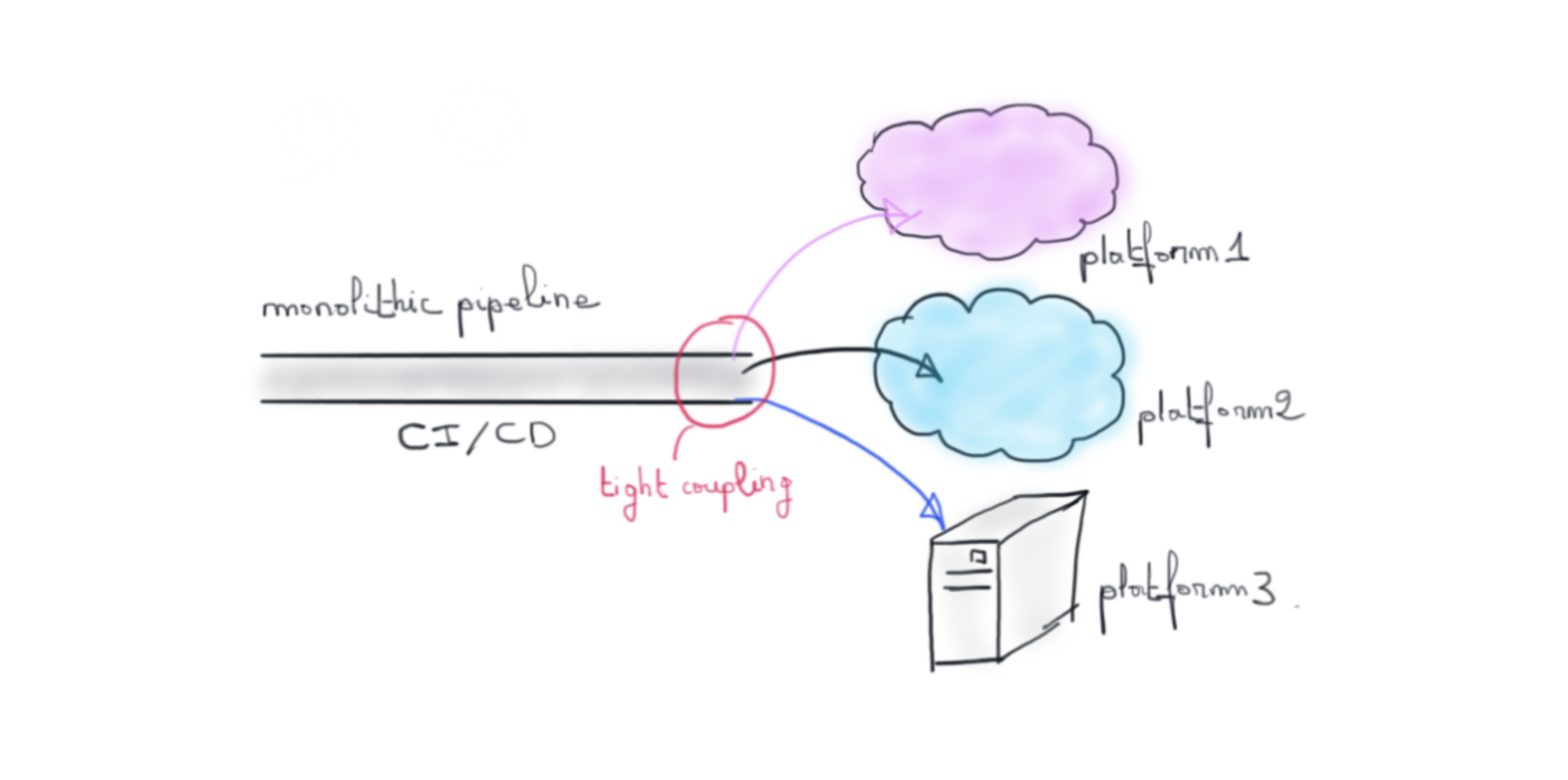
C’est pourtant le point essentiel qui va distinguer l’approche GitOps de l’approche CI/CD “classique” représentée par un pipeline monolithique s’occupant à la fois de l’intégration (CI) et du déploiement (CD).
Le problème qu’implique cette vision est que nous devons adapter le pipeline à la cible de déploiement. Nous couplons fortement notre point de vérité avec la plateforme sur laquelle on déploie. Une nouvelle cible de déploiement signifie une mise à jour du pipeline.

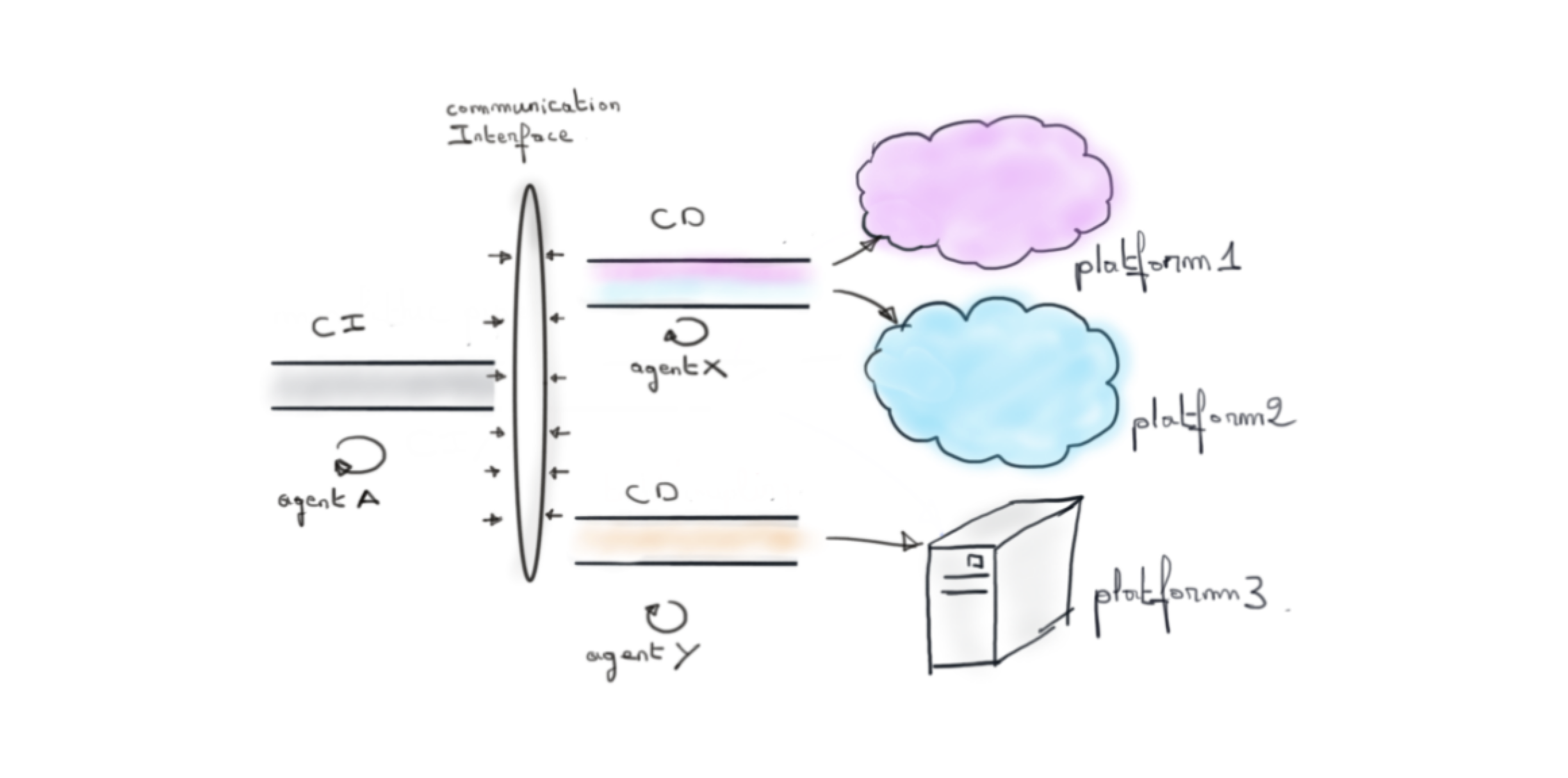
Dans une approche GitOps nous avons aussi un pipeline CI/CD mais modulaire. Il y a une CI et une CD qui vont être opérées par deux agents différents.
L’avantage offert par cette modularité est que désormais, notre pipeline initial de CI n’a plus à savoir où le code sera déployé. Il se contera de faire un travail agnostique à la plateforme de déploiement. Un ou des agents tiers, par un système de pull, iront chercher le “résultat” pour l’appliquer selon leur logique propre à des plateformes cibles.
Il est à noter que ce système de pull peut tout à fait devenir synchrone à la terminaison de la CI avec un système de webhook, comme proposé par GitHub ou GitLab.
Nous retiendrons donc du GitOps, que c’est une approche CI/CD où le “D” de déploiement est pris en charge par un agent externe, différent de celui en charge du “I” de l’intégration.
Pour faire un parallèle avec le monde de l’observabilité, c’est le push VS pull des agents de collectes de métriques.
Pour le développeur c’est un écho au principe d’inversion de dépendance qui voit notre CI s’appuyer sur une abstraction (l’agent de déploiement) plutôt qu’une implémentation concrète à sa charge.

Note: Jusqu’à présent et dans la suite de l’article, le “D” de CD se réfère à Deployment. Il peut aussi se référer à Delivery dans la littérature. Ce n’est pas notre positionnement sur cet article et nous considérerons que le delivery peut tout à fait faire partie de la partie CI dans un contexte GitOps. Le Delivery d’une image OCI (Open Container Initiative) dans un artifactory par exemple.
Flux, du GitOps dans un contexte Kube Native
Dans ce contexte GitOps, Flux se comprend comme l’agent en charge de la réconciliation d’un cluster Kubernetes avec l’infrastructure applicative décrite dans un repo Git sous forme de manifestes Kubernetes.
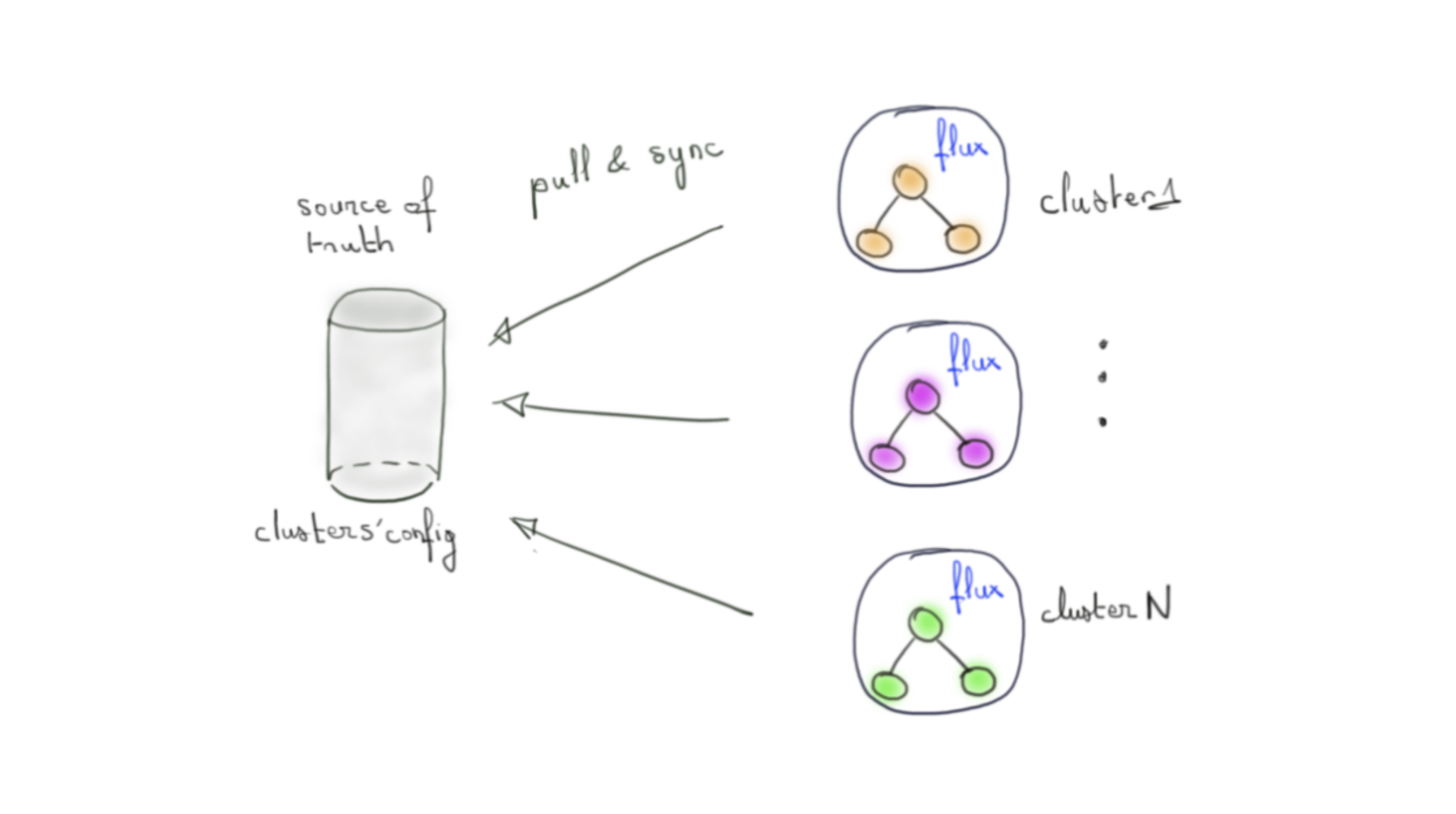
Une spécificité de l’implémentation GitOps de Flux est qu’il est installé sur la plateforme que l’on souhaite réconcilier. Autrement dit, l’agent en charge du pull de la source de vérité se trouve sur cette même plateforme à réconcilier.
Il en découle que si nous souhaitons réconcilier N clusters Kubernetes, il faudra installer Flux sur ces N clusters.
Pour autant cela ne veut pas dire que nous devons avoir N repo Git en tant que point de vérité car le modèle de Flux nous permettra d’exprimer simplement les différences entre cluster à partir d’un repo unique voire une arborescence de repo avec un repo racine. Nous abordons ce point plus loin.

Pour Flux il y aura a minima toujours une installation à réconcilier: lui même. Du point de vue de “l’agent” Flux, Flux est une application comme les autres et se doit d’être réconciliée de la même manière que les autres.

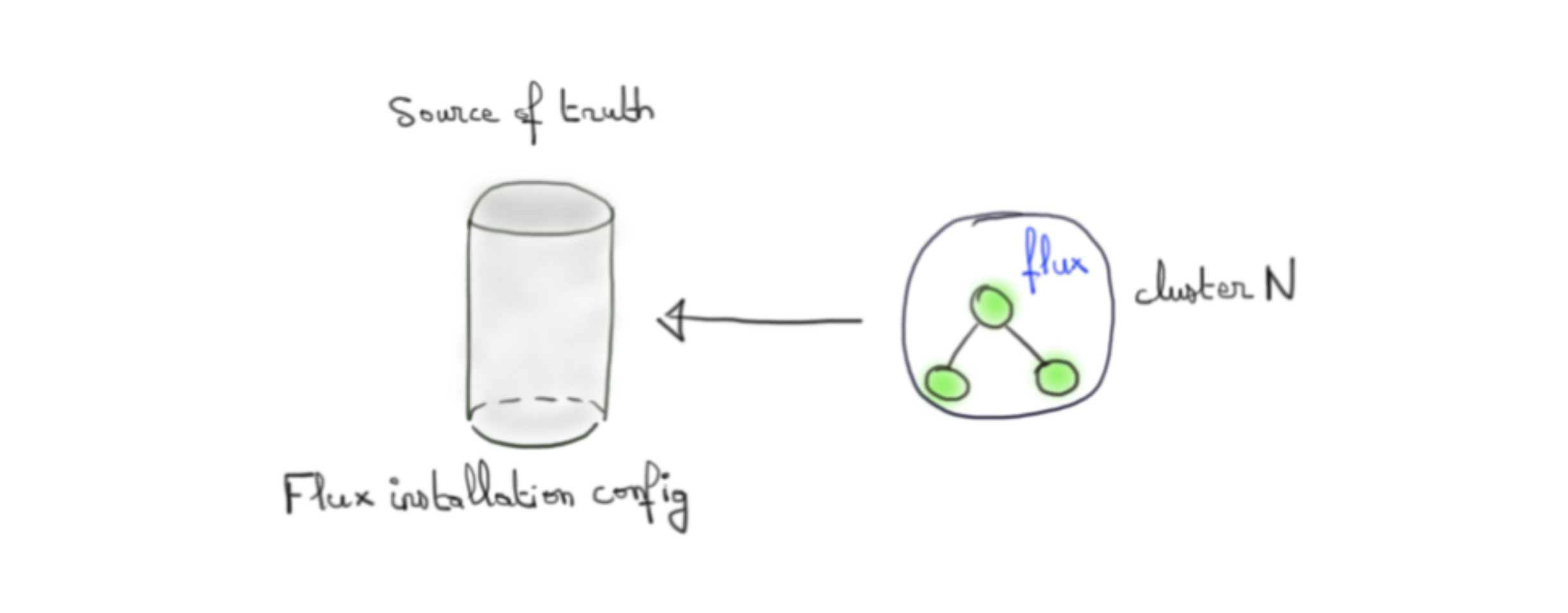
Cela pose évidemment un problème d'œuf et de la poule. Si pour que Flux soit installé sur le cluster il faut une réconciliation Flux, on ne va pas aller bien loin...
La notion de “bootstraping” fournie par la CLI Flux nous aide à casser ce paradoxe. C’est ce que nous illustrerons dans un second article et nous considérerons par la suite que l’installation initiale de Flux est donnée.
Flux et le pattern Operator de Kubernetes
Kubernetes est une plateforme qui offre un certain nombre d'entités à déclarer, sur lesquelles le moteur de K8S s’appuiera pour créer les entités adéquates à travers une boucle de réconciliation permanente. Ces déclarations passent par une API qui va “réagir” en notifiant de manière asynchrone des controllers chargés de leur traitement. Ces entités sont propres au domaine Kubernetes et nonpas à celui de votre métier.
Il est possible d’étendre l’API avec des Custom Resource Definitions (CRDs) associées à des controllers qui contiennent la logique de leur interprétation et invoqués lors de la boucle de réconciliation du moteur K8S.
Ce pattern très en vogue nommé Operator, permet de customiser Kubernetes avec vos différents domaines métiers et leurs logiques propres.
Plus généralement on nommera Operator un controller qui comprend deux domaines:
- Kubernetes
- Quelque chose d’autre
Ce quelque chose d’autre peut être une base de donnée, des agents, un serveur, ou de manière plus abstraite une logique globale de reconciliation avec des repo Git, i.e une logique GitOps.
C’est l’approche choisie par Flux qui utilise deux outils, Kustomize et Helm, pour définir et configurer cette logique.

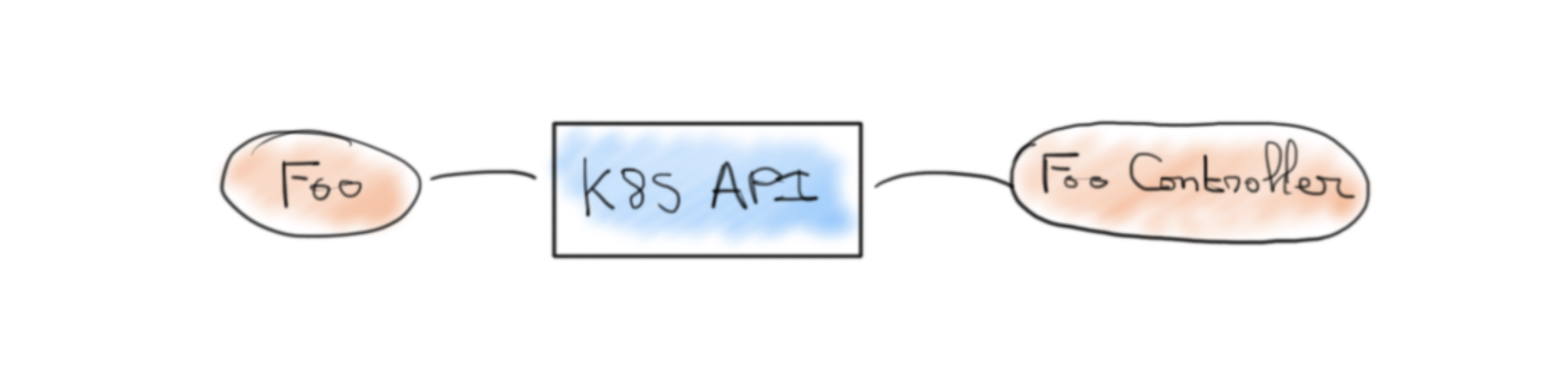
Kustomize et Helm au coeur du système Flux
Kustomize est un outil de gestion de configuration, au sens manifeste Kube, qui respecte les principes déclaratifs de Kubernetes. Pas de logique impérative de gestion. A partir d’une source YAML pure, on applique des transformations selon des fichiers de patch YAML versionnés pour sortir une nouvelle version de cette source.
Kustomize est très intéressant dans le cadre d’un mono repo Git car permet d’apporter une notion supplémentaire au système de branche Git sans parler du brut copié/collé de fichier. En partant d’une base, Kustomize va permettre d’exprimer un système de layering par dessus (avec des fichiers de patch et des stratégie de merge) pour en sortir une version différente de la base initiale en fonction des layers que nous décidons d’appliquer.
Un fichier YAML servant de base représente en réalité une infinité de fichiers différents.
Nous comprenons dès lors comment Flux peut gérer la configuration de plusieurs clusters sur un monorepo.

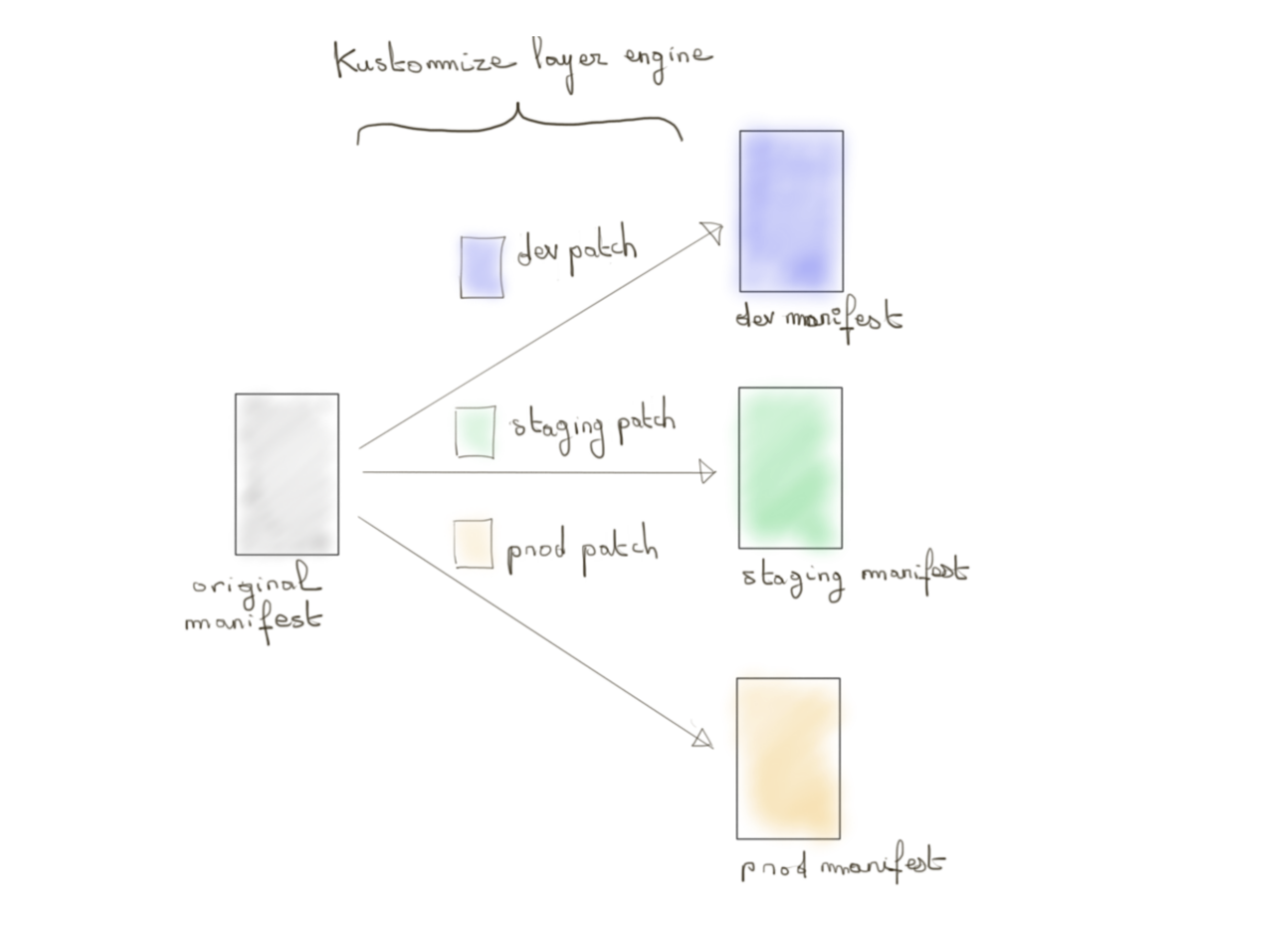
Cette approche fonctionnellement pure se veut plus accessible que le template qui nuit à la lisibilité et tend à mélanger différents concepts métier si utilisés à outrance.
Helm en est justement le parfait représentant mais a tout de même trouvé son public en s’imposant comme le “package manager” sur Kube.
Flux décide de prendre le meilleur des deux en introduisant deux CRDs:
- Kustomization
Gère l’infrastructure applicative Kube d’une manière native via Kustomize (et s’arrêter là si on le souhaite). Dans la pratique, c’est l’élément qui va nous permettre de pointer notre réconciliation vers des répertoires contenant des manifestes Kubernetes (job, deployment, namespace, …). - HelmRelease
Déploie des releases de Helm charts dans nos clusters managés par Flux.
La description de notre infrastructure applicative auprès de Flux passera donc par la déclaration d’entités de ces deux types et nous noterons donc qu’il n’est pas question d'opposition des deux mais de complémentarité.
Le GitOps toolkit
Le fonctionnement de Flux repose donc sur un ensemble de CRDs et de controllers associés qui forme le GitOps Toolkit.
Le tableau ci-dessous en répertorie les principaux éléments
| Controller |
CRD associée |
|---|---|
| SourceController |
GitRepository |
| HelmRepository |
|
| Bucket |
|
| KustomizeController |
Kustomization |
| HelmController |
HelmRelease |
Ces éléments sont liés par le flow suivant:
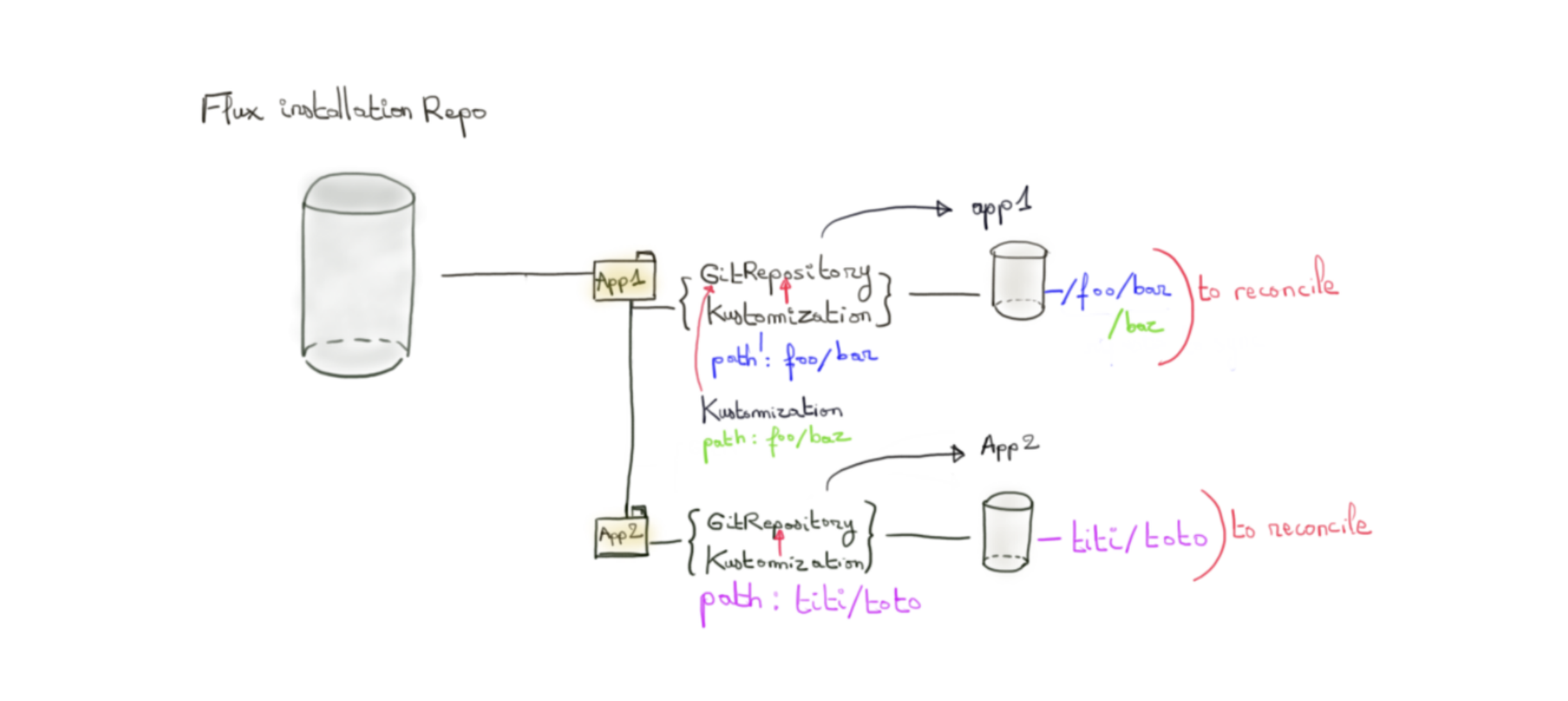
- Une entité GitRepository indique au source controller de cloner une branche donnée du repo au niveau du cluster d’installation Flux i.e celui où la réconciliation doit se faire.
Il s’agit seulement d’ une récupération des sources qui nous serviront pour la réconciliation. - La logique de réconciliation avec le contenu du repo est à la charge des controllers KustomizeController et HelmController.
En créant une Kustomization qui référence un path donné d’un précédent GitRepository, le KustomizeController va être en capacité d’explorer ce path dans lequel il trouvera un manifeste Kustomize (ou pas) lui indiquant les manifestes kube à considérer et les patchs à appliquer. Si aucun manifeste Kustomize n’est trouvé alors l’ensemble des manifestes Kube présent sous le path sera pris en compte de manière brute.
Il est possible d’orchestrer la prise en compte de Kustomization entre elles avec un mot clé dependsOn permettant de créer de graph de dépendance. - Parmi les manifestes se trouvera potentiellement un de type HelmRelease. Le HelmController entrera alors en jeu pour créer la release associée sur notre cluster.
Cette dernière doit référencer une entité HelmRepository accessible à Flux pour récupérer le chart référencé par la release.
Note:
Kustomize peut en particulier patcher le contenu d’une HelmRelease selon différentes considérations. L'environnement par exemple.
C’est un excellent exemple de complémentarité entre Kustomize et Helm que l’on a plutôt tendance à opposer. Même si pour Flux, il y a une préséance du Kustomize sur Helm qui ne vient qu’en second temps dans la réconciliation.
Du point de vue de la documentation officielle de Flux cela se résume à ce schéma abscons si l’on n’est pas introduit avec les précédentes notions.

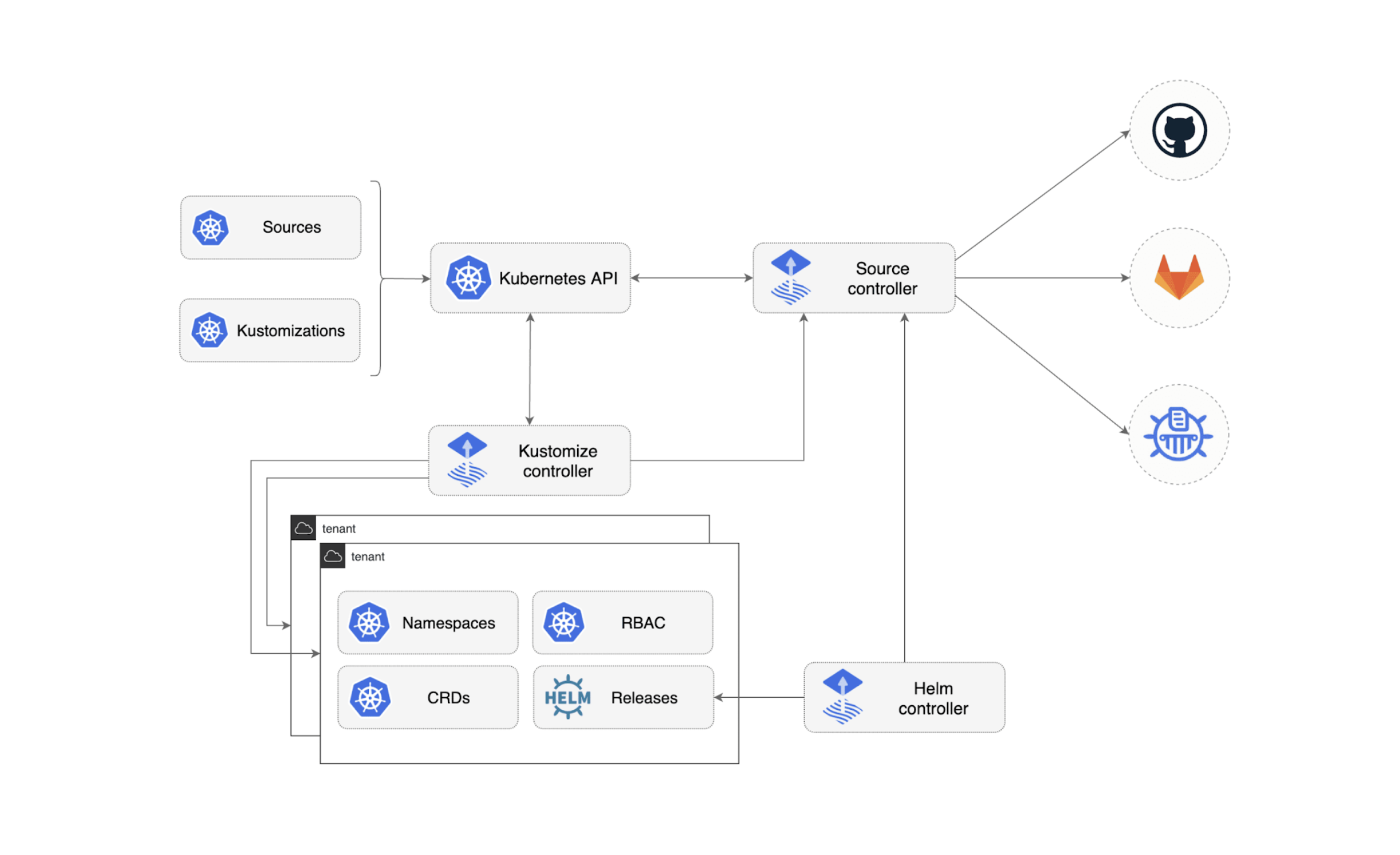
Il existe des controllers supplémentaires mais qui sont toutefois secondaires en matière d’importance dans la philosophie de Flux telle que présentée.
Réconciliation et temporalité
La boucle de réconciliation offerte par Flux dispose de plusieurs leviers de configuration:
- Les sources
Chaque entité de type sources, Gitrepository & HelmRepository, définissent leurs intervalles de synchronisation propres.
Cela permettra de lisser la charge sur le SourceController Flux par exemple. - Kustomization & Helmrelease
Exposent une configuration d’interval de réconciliations
On notera qu’il y a peu d’intérêt à définir un intervalle de réconciliation inférieur à celui de la synchronisation de la source référencée.
En parallèle de la temporalité se trouve aussi le scope de la réconciliation.
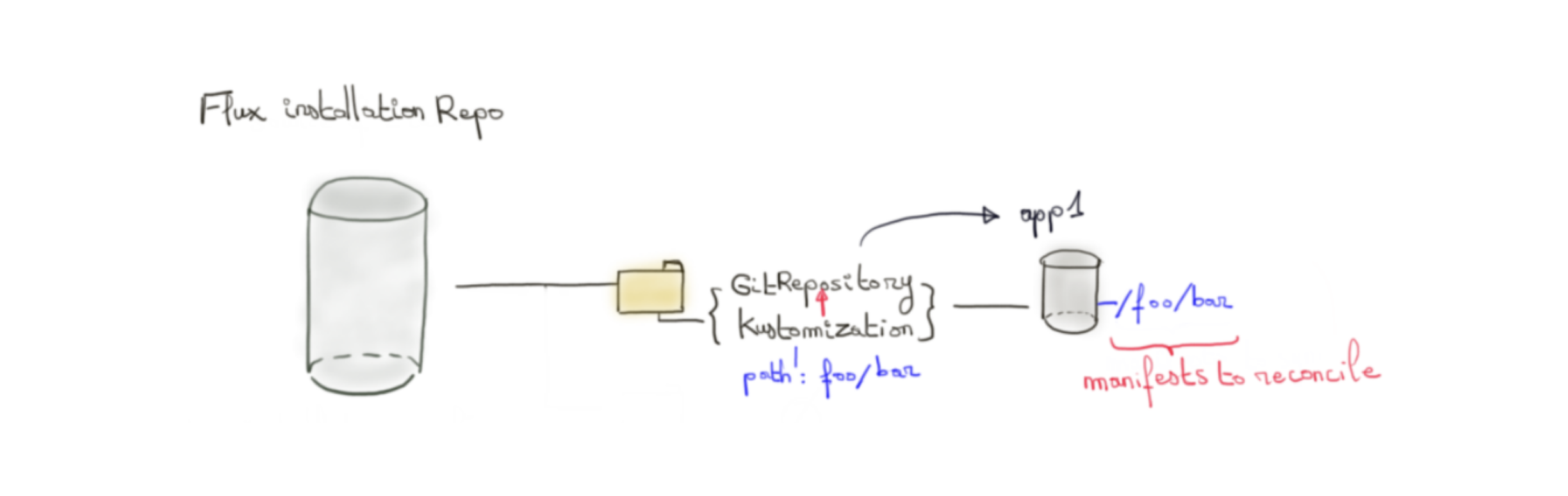
Il est possible de le contrôler au niveau d’une Kustomization par la définition du path du GitRepository référencé par cette dernière. Cela permet d’envisager différents scénarios de migration vers Flux plutôt que de s’imposer une migration bigbang vers du GitOps.
Côté Helm Release, la CRD comprend le semantic versionning (numéro de version sous le format MAJOR.MINOR.PATCH) et pourra ou non réconcilier une release selon les contraintes de versionning que l’on définit à son niveau.

La multi-tenancy avec Flux
La réconciliation offerte par Flux doit être au service d’équipes, de projets. En d’autres termes de tenants qui doivent cohabiter dans un même cluster Kubernetes.
Les controllers Flux en charge de cette réconciliation sont installés dans un namespace avec une identité par défaut.
C’est eux qui par la suite effectueront les créations de ressources Kubernetes avec cette identité dans un ou des namespaces cibles de la réconciliation.
On voit assez rapidement le problème que cela pose. Avec cette condition initiale il est possible de faire de l’escalade de droit en déclarant des ressources à créer dans un namespace qui nous serait interdit…mais pas aux controllers Flux.

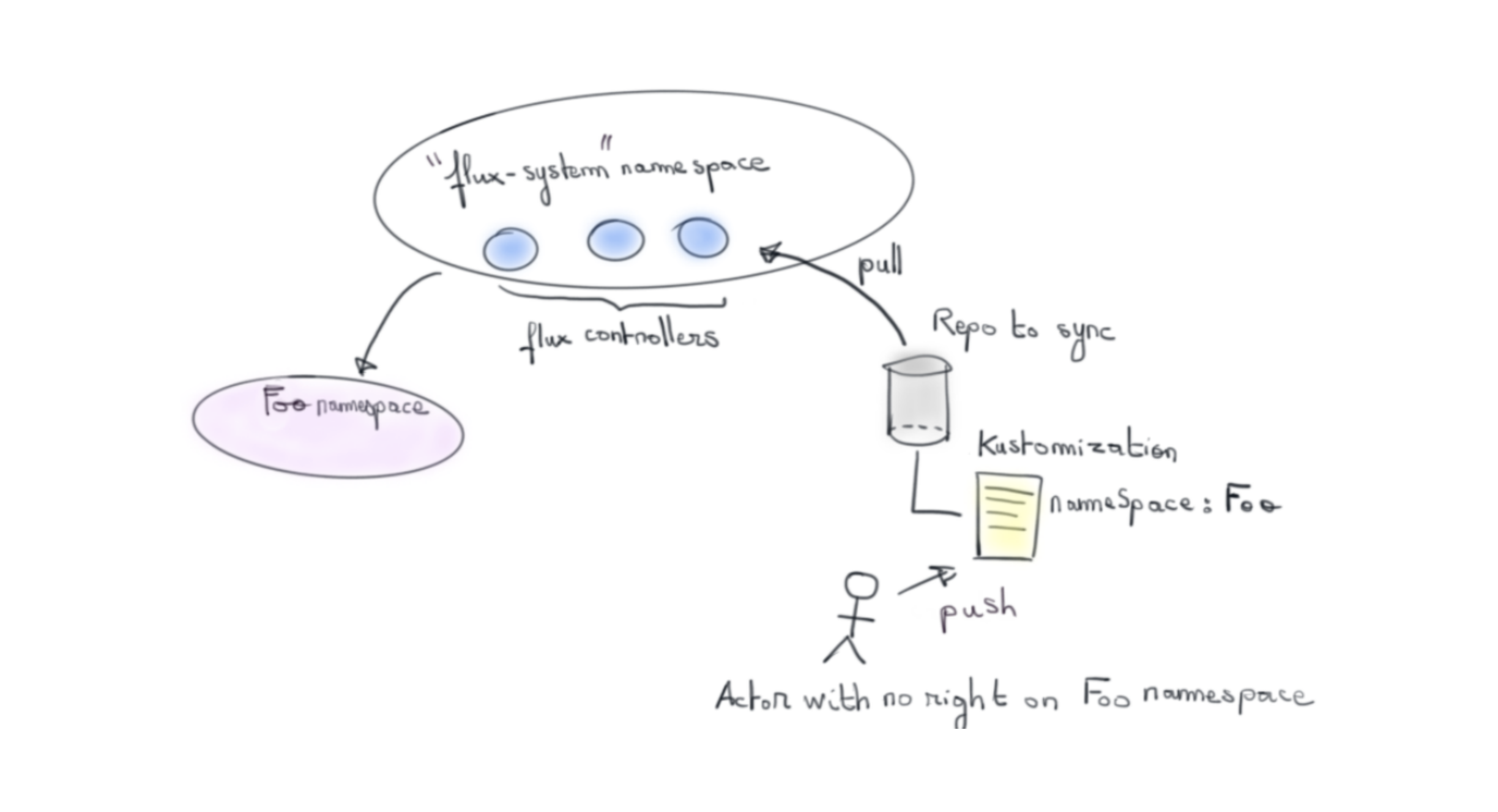
Pour se prémunir de cette faille, Flux introduit une notion de tenant par l'agrégation de concepts Kubernetes pour contraindre l’action des Controllers lors d’une réconciliation.
Simplement il s’agit d’un compte de service avec un rôle et un rôle binding associé. Lors de la définition des CRDs Flux nous impose la spécification d’un compte de service que chaque controller impersonifiera pour procéder à la synchronisation et de ce fait ne pas aller au-delà des droits associés à une équipe. On complètera l’approche en enlevant tous les droits du compte par défaut des controllers.
Cela dit, il sera difficile d’imposer que le service account spécifié est bien celui sur lequel on s’est mis d’accord avec l’équipe de développement…
La notion de tenant est donc intéressante mais insuffisante pour se prémunir d’une escalade des droits.
Flux dans l'écosystème GitOps
La place de leader GitOps sur K8S a l’air de s’orienter vers Argo CD. Pourtant, Flux a de vrais arguments à faire valoir mais il pâtit encore de décisions difficilement compréhensibles de la part de Weaveworks.
Au moment de l’écriture de cet article deux versions de Flux coexistent sans que l’on puisse parler de juste “Flux”. Il y a Flux V1 et Flux V2. La première, dépréciée, est issue d’une première approche qui s’est révélée problématique car monolithique et non optimisée pour suivre l’évolution de Kubernetes.
La décision a été prise d’en arrêter le développement pour passer à une V2 toujours en bêta que cet article décrit.
Du point de vue du consommateur il y a donc 2 versions: L’une dont le développement est au point mort mais toujours considérée comme “prod-ready” et une seconde qui est attrayante mais toujours en bêta. Comment prendre une décision dans ce cas là ?
La nomenclature est tout aussi problématique. Pourquoi parler de version dans l’intitulé du projet ? Une décision qui irait dans le bon sens serait de s’inspirer du projet Angular qui a eu une même situation mais a arrêté de parler de version pour se concentrer sur le nom de la technologie seulement. Flux V2 gagnerait à s’appeler juste Flux.
D’autres personnes invoquent l'existence d’une UI Argo CD pour justifier son succès mais rien n’en est moins sûr. Ces aspects là peuvent compter mais ne remplaceront pas l'ergonomie globale, point sur lequel Flux est assez avancé.
Il n’empêche que Flux a trouvé son public et il sera intéressant de voir si son approche Kube Native minimaliste lui permettra de le fidéliser voir de le faire grandir.
Conclusion
Faire du GitOps déclarativement, telle est la promesse de Flux.
C’est un outil conceptuellement simple mais puissant. Son approche Kube Native rend son usage assez naturel pour toute personne comprenant les bases de Kubernetes.
Cet outil doit cependant rattraper des choix de design initiaux qui complique son adoption en entreprise. Handicapé par un faux départ avec Flux V1, Flux V2 ne se définit toujours pas comme production ready du fait de la non parité de features avec sa précédente version. Beaucoup d'incompréhensions autour de l’outil ajoutent du poids à son concurrent Argo CD mais pour de mauvaises raisons, comme l’absence d’interface graphique par exemple.
Flux, n’en reste pas moins une solution solide, élégante, illustrant brillamment l’approche GitOps dans un contexte Kube Native.
C’est une fois les bases comprises que s’ouvre une richesse de scénarios possibles tant en matière d’organisation des dépôts Git d’infrastructure que d'application.
Il faudra en jauger la pertinence à la lumière d’un contexte projet, produit ou d’équipe.
C’est ce que nous illustrerons dans un prochain article avec quelques études de cas.



