 David Drugeon-Hamon
David Drugeon-Hamon
HashiCorp Vault : le cookbook
Si vous découvrez Vault, HashiCorp nous fournit une superbe documentation. En témoigne la prolifique section Learn du site, tenue à jour au fil des...
.jpg)
Lorsqu’il s’agit de gérer les droits d’un utilisateur dans un système informatique, il est essentiel de comprendre trois concepts fondamentaux : l’identification, l’authentification et l’autorisation. Ces trois aspects jouent un rôle crucial dans la sécurisation des ressources et des données, ainsi que dans l’organisation globale de leurs accès.
Tout d’abord, l’identification concerne la première étape, où un utilisateur prétend être une entité particulière, généralement au moyen d’un nom, d’une adresse e-mail ou tout autre identifiant. Cependant, à cette étape, il n’est pas possible de déterminer si les informations saisies correspondent bien à l’identité de la personne.
L’authentification est la phase qui permet de vérifier son identité réelle. Cela peut se faire en demandant un mot de passe, une empreinte digitale, un code PIN ou tout autre mécanisme de vérification. L’envoi d’un code sur le téléphone mobile de la personne peut renforcer (ou pas) cette phase. Celle-ci garantit que l’utilisateur est bien celui qu’il prétend être, en se basant sur quelque chose qu’il sait, qu’il a, ou qu’il est.
Enfin, l’autorisation se rapporte à l’accès effectif aux systèmes ou aux données une fois qu’il a été identifié et authentifié. C’est ici que les privilèges et les permissions entrent en jeu. Cela détermine ce que l’utilisateur peut accéder, modifier ou exécuter.
Dans la suite de cet article, nous nous concentrerons uniquement sur l’étape d’autorisation d’accès à une ressource.
Il y a encore quelques temps, nos applications étaient développées sous forme d’un monolithe, ce qui facilitait la gestion des droits d’un utilisateur sur l’application et ses données.
De nos jours, nous découpons nos applications cloud native en microservices. Ainsi, elles peuvent être utilisées par un plus grand nombre d’utilisateurs. La mise à l’échelle devient plus aisée : nous pouvons augmenter le nombre de services en fonction de la charge sur une partie de l’application. En outre, l’intégration de services tiers pour ajouter de nouvelles fonctionnalités telles que la facturation, un système de paiement, etc ou pour répondre à des besoins réglementaires, ce qui ajoute de la complexité dans la gestion de droits d’accès à ces ressources.
Une mauvaise conception de cette gestion de droits peut en effet avoir des conséquences dramatiques comme la fuite de données ou l’intrusion dans notre système.
Dans ce contexte, construire un système d’autorisation efficace et non centralisé devient un véritable challenge technique.
Par exemple, AWS a développé IAM (Identity and Access Management) pour faciliter l’accès à ses différents services. D’ailleurs, AWS propose depuis quelques mois ce moteur décisionnel en open source : AWS Cedar (https://www.cedarpolicy.com/en). Il est écrit en Rust et semble prometteur. Malheureusement, il n’est actuellement disponible que sous forme d’un SDK en Rust.
D’autres solutions au sein de la Cloud Native Computing Foundation (CNCF - https://www.cncf.io) existent pour s’assurer de la mise en application de politiques de sécurité comme Kyverno ou encore Open Policy Agent.
Concentrons-nous sur Open Policy Agent aussi appelé OPA.
Open Policy Agent (ou OPA) est un projet open source créé et développé par Styra (https://www.styra.com/) et est maintenant hébergé au sein de la Cloud Native Computing Foundation (CNCF - https://www.cncf.io/projects/open-policy-agent-opa/) avec le niveau “graduated”.
Ce projet est une alternative plus souple et moderne que XACML pour gérer ses autorisations. Il est adapté aux architectures modernes et évolutives : OPA peut être intégré pour gérer les autorisations au niveau des microservices, des conteneurs ou d'autres composants distribués.
Il est versatile : il peut être aussi bien utilisé comme moteur de décision pour un système de gestion de droits que pour s’assurer de la conformité du code d’infrastructure par rapport à des contraintes réglementaires ou de sécurité. En effet, nous pouvons le déployer sur une chaîne de CICD ou bien sur un cluster Kubernetes pour vérifier des règles sur la soumission d’un artefact au control plane ou encore pour contrôler l’accès à un microservice métier.
En fonction de vos besoins projets, il peut être déployé :
Il définit un langage spécifique de haut niveau pour écrire aisément les règles sous forme de code exécutable : le Rego. Ce dernier est proche des langages de programmation logique tels que Prolog ou Datalog.
Rego propose un ensemble de librairies standards permettant, par exemple, d’extraire des informations d’une payload au format JSON. D’autres librairies sont présentes pour s’adapter aux différents besoins. De plus, un SDK est disponible pour étendre ses fonctionnalités pour traiter des cas spécifiques.
Sur le projet actuel sur lequel je contribue, nous avons développé une librairie permettant de s’assurer qu’une signature d’un JSON-LD est valide grâce au matériel cryptographique de l’émetteur du message.
La ligne de commande d’Open Policy Agent offre une manière de livrer ses règles Rego sous forme d’un package appelé Bundle. Pour faciliter la gouvernance, nous pouvons stocker ces règles Rego dans un dépôt GIT pour les versionner et pouvoir tracer les changements effectués. Une Chaîne de CICD peut alors être exécutée pour les tester, les revoir et les distribuer sous forme d’un bundle et les rendre disponibles grâce à un serveur HTTP. Les agents ont nativement un mécanisme qui permet de les télécharger automatiquement grâce à une détection de changement. Bien entendu, ce processus de téléchargement est configurable.
A noter
La gestion et le déploiement des règles se fait agent par agent. Cela peut être problématique si nous devons gérer plusieurs agents en parallèle avec des bundles de règles versionnées et déployées différemment.
Enfin, Open Policy Agent s’appuie sur des données au format JSON qui peuvent provenir de différentes sources de données (par exemple, un LDAP) pour prendre une décision. Ces données peuvent aussi être intégrées directement au sein de l’agent via l’interface REST de l’agent.
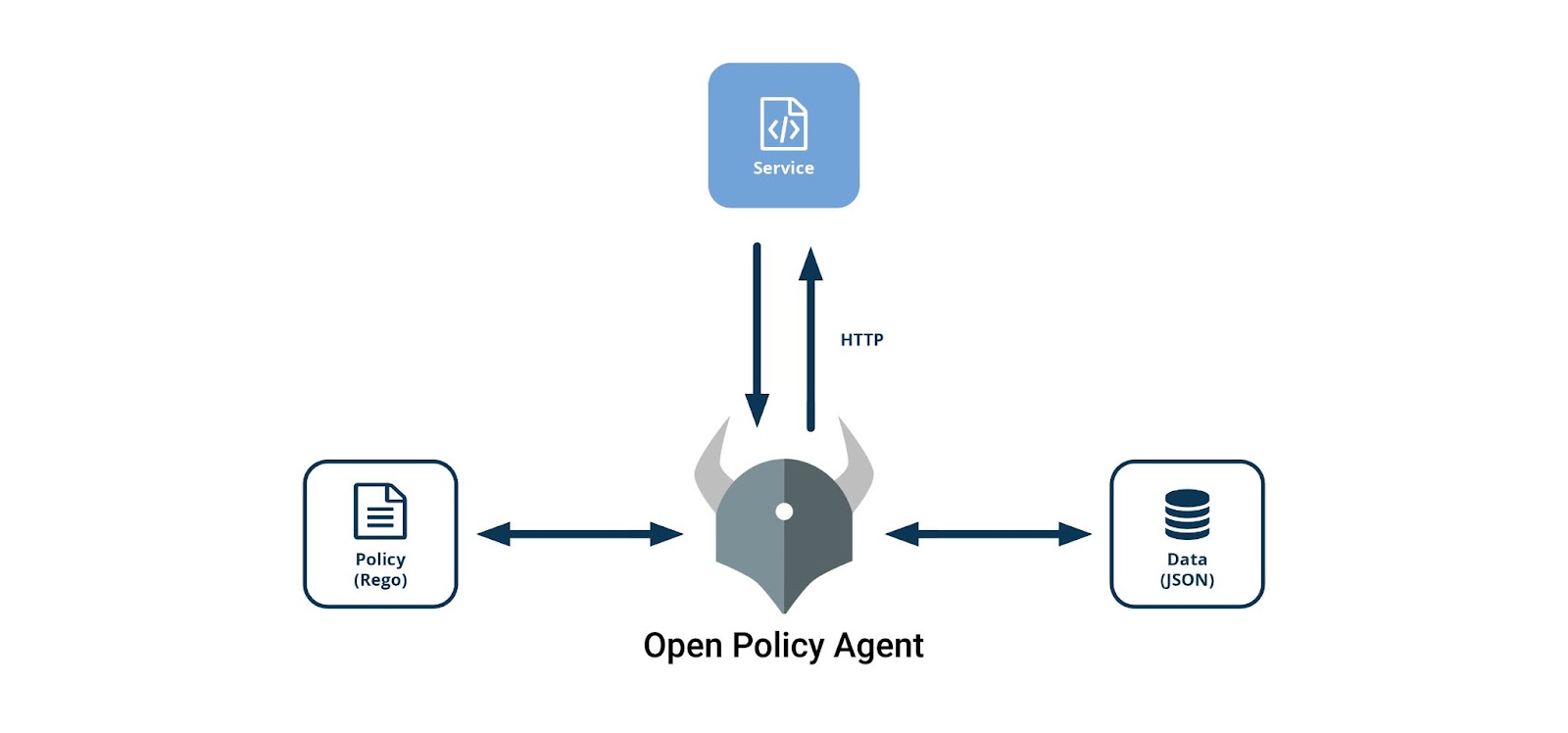
Nous pouvons synthétiser la prise de décision à l’aide du schéma suivant :
Le service envoie une requête HTTP à l’agent avec les données reçues de l’utilisateur pour savoir s'il est autorisé ou non à accéder à une ressource. L’agent en extrait les informations utiles et à l’aide des règles Rego et des données de son référentiel répond à la requête avec sa prise de décision.
Malgré tous ces avantages, Open Policy Agent présente également certains inconvénients potentiels :
La société permit.io a développé une brique essayant de combler les différents manques d’OPA. C’est le projet Open-Policy Administration Layer aussi connu sous le nom de OPAL. Les contributeurs à ce projet se sont fortement inspirés du talk de la KubeCon 2017 expliquant comment Netflix a conçu son système d’administration et de gouvernance de ses politiques d’accès : How Netflix Is Solving Authorization Across Their Cloud [I] - Manish Mehta & Torin Sandall, Netflix
A noter
Ils ont aussi développé un autre projet open source permettant de déployer et administrer un ensemble d'agents AWS Cedar.
Open Policy Administration Layer (OPAL) est donc un complément d’OPA conçue pour simplifier et améliorer la gestion des règles et des autorisations.
Pour faciliter la gouvernance des politiques de sécurité, elles doivent être stockées dans un dépôt GIT. Elles pourront ainsi être revues, validées et versionnées avant d’être déployées sur les différents agents OPA à l’aide d’une chaîne de CICD classique.
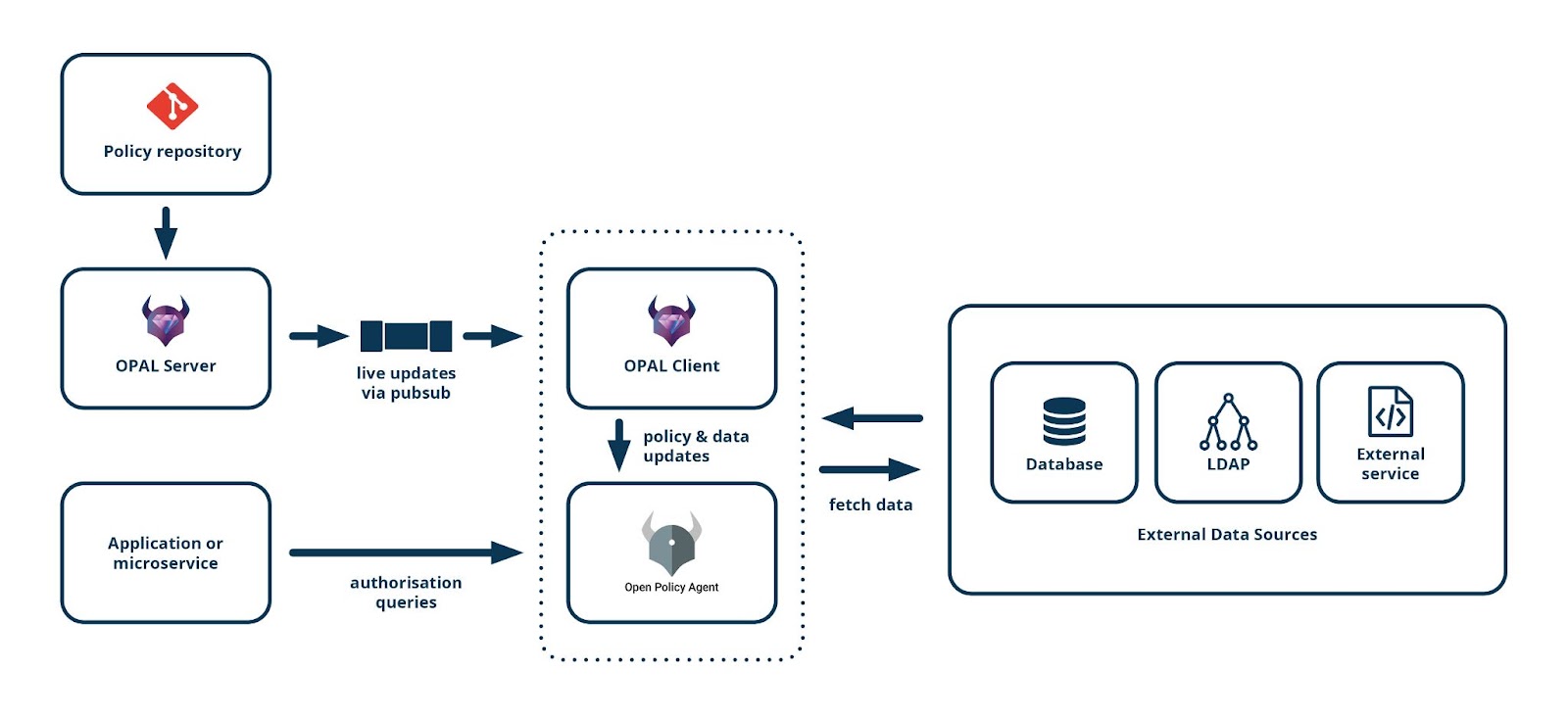
Architecture logicielle OPAL
Cette architecture de référence ajoute deux composants à une infrastructure basée sur Open Policy Agent : OPAL Server et OPAL Client.
OPAL Server est un coordinateur de mise à jour des règles Rego. Son rôle est de détecter les changements sur les règles Rego d’un ou plusieurs dépôts GIT pour ensuite les transmettre aux différents OPAL Clients.
Pour cela, il crée un mécanisme de publication de messages sur un ou plusieurs topics basé sur des websockets. Grâce à cette technologie, le serveur peut être déployé sur une infrastructure différente de celle des OPAL Clients. Les clients peuvent alors s’abonner à un ou plusieurs topics pour recevoir les mises à jour sur plusieurs dépôts GIT.
Pour détecter les changements, il peut être configuré pour exposer un webhook que le dépôt GIT pourra appeler à chaque changement. Par défaut, il l’interroge périodiquement pour récupérer les évolutions. Il ne publiera alors que les différences par rapport à la version précédente sur le topic concerné.
Il expose une API Rest pour administrer les sources de données sur lesquelles les données de décision peuvent être récupérées. Ainsi, nous pouvons donner l’URL, les clés d’authentification ou autres données nécessaires. Les clients pourront récupérer cette configuration via une API Rest dédiée.
OPAL server devient le point central d’administration de vos règles et données permettant la prise de décision. Il doit être déployé de manière hautement disponible et doit pouvoir être mis à l’échelle. Bien entendu, plusieurs serveurs peuvent être déployés pour répondre à ce besoin. Dans ce cas, les différents serveurs peuvent communiquer entre eux via un mécanisme de Pub/Sub basé sur un cluster Redis, un cluster Postgresql ou un cluster Kafka.
Un OPAL Client est déployé pour administrer un ou plusieurs Open Policy Agent. Son rôle principal est d'agréger les différentes sources de données et les mises à jour des règles Rego pour les injecter ensuite dans l’agent OPA via son interface d’administration.
A noter
OPAL Client inclut par défaut un Open Policy Agent ce qui facilite l’intégration. Néanmoins, il peut être configuré pour administrer un OPA distant.
À son démarrage, il récupère sa configuration depuis l’OPAL Server puis s’abonne au topic dédié exposé par le serveur. Le mécanisme de Pub/Sub s’appuyant sur des WebSockets permet de s’affranchir des pare-feux et permet de récupérer les événements depuis un serveur distant.
Régulièrement, il ira chercher les données de référence pour récupérer les changements afin de les soumettre à l’agent OPA. Il réagira aussi aux événements reçus depuis l’OPAL Server.
Les mise à jour sur les règles et ces données seront alors prises en compte par l’agent OPA afin de prendre ses décisions. Par exemple, si un utilisateur change de groupe, il pourra avoir accès à certaines ressources immédiatement.
Les différents composants sont écrits en Python et sont disponibles sous forme de container ce qui les rend facilement déployables sur différents types d’infrastructure.
Une charte Helm (https://permitio.github.io/opal-helm-chart et les sources de la charte sont disponibles sur GitHub - https://github.com/permitio/opal-helm-chart) est d’ailleurs disponible pour un déploiement facilité sur un ou plusieurs clusters Kubernetes.
A noter
Dans la partie tutoriel de la documentation, ils fournissent un docker-compose qui permet d’appréhender les différents concepts et de tester les différentes configurations.
Dans un environnement de développement, nous pouvons déployer un seul OPAL Server qui se basera sur un serveur Redis pour la synchronisation. Cet OPAL Server pourra être déployé sur le même cluster Kubernetes que celui où sont déployés les pods applicatifs.
Voici par exemple, le fichier values.yaml d’une configuration que j’ai mise en place sur l’environnement de développement du projet sur lequel je travaille dernièrement. Les agents OPAL server se synchronisent sur la branche main d’un dépôt Git où sont stockées nos règles Rego.
image:
server:
registry: docker.io
repository: permitio/opal-server:0.7.4
server:
port: 7002
policyRepoUrl: "https://gitlab.com/gaia-x/data-infrastructure-federation-services/deployment-scenario/abc-checker.git"
policyRepoMainBranch: main
pollingInterval: 900
dataConfigSources:
# No data sources
config:
entries: []
broadcastUri: 'redis://redis-server:6379/0'
broadcastPgsql: false
uvicornWorkers: 4
replicas: 1
extraEnv: {
“OPAL_BUNDLE_IGNORE”: “.idea,data,main_test.rego”
}
À noter que j’utilise directement les agents OPA inclus dans le container d’OPAL Client.
Dans une optique de déploiement dans un environnement de production, il est nécessaire de rendre le serveur OPAL hautement disponible et le mettre à l’échelle en fonction de la charge. Une solution de Pub/Sub résiliente comme une base de données Postgresql ou un cluster Kafka est à envisager pour la synchronisation entre les serveurs. Ces serveurs OPAL devraient être déployés sur un cluster Kubernetes dédié, ce qui faciliterait la gouvernance et les droits pour administrer les règles.
Bien entendu, il sera nécessaire d’observer la solution à l’aide de vos outils d’observabilité préférés. OPAL Server comme Client peuvent être configurés pour récupérer des statistiques d’utilisation des différents composants (je vous convie à lire le tutoriel suivant https://docs.opal.ac/tutorials/monitoring_opal).
Le projet OPAL se révèle être une solution essentielle pour simplifier et optimiser la gestion des politiques et des autorisations dans un environnement contenant un ensemble d'agents OPA (Open Policy Agent). Au fur et à mesure que les organisations évoluent et que la complexité des politiques d'autorisation augmente, OPAL offre une réponse efficace aux défis de gestion qui se posent.
Il permet de s’inscrire dans la mouvance GitOps pour faciliter le déploiement de politiques de sécurité. Il offre un moyen pour les équipes de sécurité, de conformité et de développement, de travailler de manière plus efficace ainsi qu’une agilité accrue pour assurer un contrôle plus granulaire sur l'accès aux ressources sensibles.
Article de blog comparant la solution OPA + OPAL versus XACML : https://www.permit.io/blog/opal-opa-vs-xacml

Si vous découvrez Vault, HashiCorp nous fournit une superbe documentation. En témoigne la prolifique section Learn du site, tenue à jour au fil des...

Contexte WeScale a tenu son “DevSecOps Summer Challenge”, un CTF orienté DevOps, de début juin à fin septembre 2023. Pour clore cet événement, nous...