 Jérôme Masson
Jérôme Masson


Keda pourrait bouleverser l'écosystème Kubernetes avec ses fonctionnalités d'autoscaling étendues se basant sur des événements qu'ils soient internes ou externes à votre cluster.
Edito
Kubernetes est une plateforme où nos applications se retrouvent confrontées de plus en plus à des enjeux de temps de réponse, de support de charges applicatives et de besoins FinOps. Quoi de mieux que de gérer ces enjeux via l'autoscaling, qu’il soit horizontal (augmentation/diminution du nombre d'instances) ou vertical (augmentation/diminution des ressources).
Dans Kubernetes, il existe “nativement” l’autoscaling horizontal avec HPA qui ne se base que sur le CPU et la RAM et surtout ne cible que deux objets : Deployment et StatefulSet. Voyons comment Keda traite ce sujet de l'autoscaling et quels sont les objets Kubernetes scalables par Keda.
Entrons dans la machine : Keda
Keda est un Event Driven Autoscaler. Vous pouvez donc déterminer le scaling des objets cibles basés sur la valeur du nombre d’événements que vous aurez configurés en amont. Keda étend les outils natifs de Kubernetes pour gérer le scaling sans créer de doublons.
Keda est composé de plusieurs briques :
- L’agent (l’opérateur), qui est responsable de l’action sur le scaling (déploiement, etc.).
- Les Metrics, dont le but premier est de servir l’opérateur, exposent des informations et des métriques enrichies en comparaison de ce que fait Kubernetes Metric Server.
- L'admission webhook permet de contrôler les erreurs de configuration ainsi que les doublons de configuration sur une même cible.
Dans l’architecture ci-dessous, on peut voir que Keda est le point central se situant entre HPA permettant l’autoscaling, les événements externes (External Trigger) et les informations d’état de l’objet cible (ScaledObject).
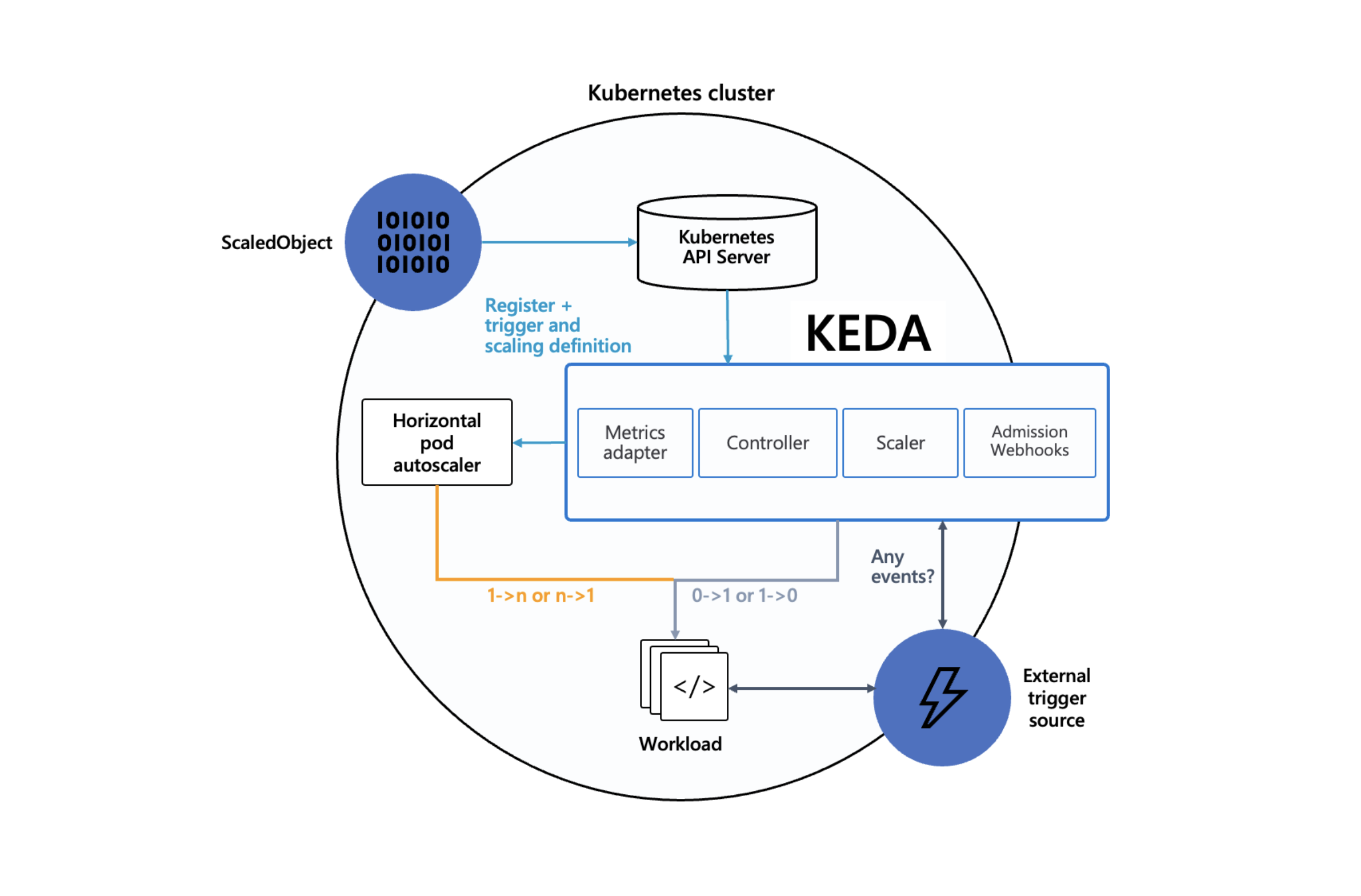
Figure : Architecture Keda - source: https://keda.sh/docs/2.11/concepts/#architecture
Keda étend l’API de Kubernetes et le fait grâce à l’introduction de 4 nouvelles CRDs dont nous parlerons plus loin :
- scaledobjects.keda.sh - cible de type workload
- scaledjobs.keda.sh - cible de type job
- triggerauthentications.keda.sh - authentification scope namespace
- clustertriggerauthentications.keda.sh - authentification scope cluster
En résumé, Keda est capable de définir des valeurs d’événements (External Triggers) l’autoscaling 1 à N (ou N à 1) via HPA mais aussi le cas aux limites 0 à 1 (ou 1 à 0).
Entrons dans la machine 2 : les scalers
Les valeurs sont extraites via des triggers (internes ou externes) qui sont nommés scalers. Ces scalers sont variés, et peuvent s’appuyer sur :
- des produits de Cloud Provider :
- AWS Cloudwatch,
- AWS SQS,
- Azure Log Analytics
- etc.,
- des produits tiers :
- Datadog,
- Redis,
- Kafka
- etc.,
- des métriques internes :
- CPU
- Memory
- Kubernetes Workload
- des métriques propres à votre API : Metrics API.
Chacun de ces scalers, il en existe environ 60 au moment de l’écriture de cet article, a sa propre configuration. Celle-ci permet d’accéder à de l’information (métriques, valeurs ou autres) spécifique à chacun, et ce via authentification ou non.
Keda nous permet d’avoir une authentification par Namespace ou par Cluster, que l’on peut partager ou non entre la déclaration pour un même type de scaler (les objets cibles devant être obligatoirement différents).
Exemple de trigger CPU :
triggers:
- type: cpu
metricType: Utilization # Allowed types are 'Utilization' or 'AverageValue'
metadata:
type: Utilization # Deprecated in favor of trigger.metricType; allowed types are 'Utilization' or 'AverageValue'
value: "60"
containerName: "" # Optional. You can use this to target a specific container in a pod
Exemple de trigger Memory :
triggers:
- type: memory
metricType: Utilization # Allowed types are 'Utilization' or 'AverageValue'
metadata:
type: Utilization # Deprecated in favor of trigger.metricType; allowed types are 'Utilization' or 'AverageValue'
value: "60"
containerName: "" # Optional. You can use this to target a specific container in a pod
Exemple de scaler Datadog :
triggers:
- type: datadog
metricType: Value
metadata:
query: "sum:trace.redis.command.hits{env:none,service:redis}.as_count()"
queryValue: "7.75"
activationQueryValue: "1.1"
queryAggregator: "max"
type: "global" # Deprecated in favor of trigger.metricType
age: "120"
timeWindowOffset: "30"
lastAvailablePointOffset: "1"
metricUnavailableValue: "1.5"
Double dragon : Objets scalables
Keda ne gère que 2 types de cibles :
- ScaledObject - Déploiement, StatefulSet ou toutes Custom Resource définissant la sous-resource /scale
- ScaledJob - Job Kubernetes
Le ScaledObject est orienté sur un scaling défini et vivant, ayant un cycle de vie relativement court. Le ScaledJob est orienté sur un scaling de Job et donc de tâches ayant un cycle de vie qui peut être relativement long.
Ils permettent surtout de définir la façon dont doit se comporter votre scaling, avant même de définir quand il aura lieu, et ses conditions. Cela vous permet de gérer assez spécifiquement chacune des phases de l’autoscaling (upscaling et downscaling) ainsi que le comportement par défaut (qui peut s’avérer très utile en cas de perte de données depuis le trigger externe).
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true" # Optional. Use to transfer an existing HPA ownership to this ScaledObject
autoscaling.keda.sh/paused-replicas: "0" # Optional. Use to pause autoscaling of objects
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
idleReplicaCount: 0 # Optional. Default: ignored, must be less than minReplicaCount
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
fallback: # Optional. Section to specify fallback options
failureThreshold: 3 # Mandatory if fallback section is included
replicas: 6 # Mandatory if fallback section is included
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Par exemple, voici un tableau des configurations et de leurs effets de bord potentiels :
| Configuration | Effet de bord |
| pollingInterval | L’API distante ayant une limitation du nombre de métriques/connexion/seconde va créer de la perte d’informations, voire la disparition pure et simple de métriques |
| cooldownPeriod | Un temps trop court fera que votre application va downscale en cas de perte de métriques ou d’absence de métriques dûes à l’erreur ci-dessus |
| envSourceContainerName | Ce paramètre optionnel, permet d'indiquer à Keda ou récupérer les propriétés (secret / variables d’environnements par exemple) |
ScaledJob: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
labels:
my-label: my-label-value # labels on the ScaledJob will be copied to each Job
annotations:
autoscaling.keda.sh/paused: true # Optional. Use to pause autoscaling of Jobs
my-annotation: my-annotation-value # annotations on the ScaledJob will be copied to each Job
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
minReplicaCount: 10 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
rolloutStrategy: gradual # Deprecated: Use rollout.strategy instead (see below).
rollout:
strategy: gradual # Optional. Default: default. Which Rollout Strategy KEDA will use.
propagationPolicy: foreground # Optional. Default: background. Kubernetes propagation policy for cleaning up existing jobs during rollout.
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
pendingPodConditions: # Optional. A parameter to calculate pending job count per the specified pod conditions
- "Ready"
- "PodScheduled"
- "AnyOtherCustomPodCondition"
Alex Kidd’s scaling : Scalabilité native ?
Keda nous permet d’avoir une scalabilité que l’on pourrait considérer comme native, car il s’appuie sur HPA. Or, HPA ne permet pas de gérer le cas du 0 à 1 ou de 1 à 0 et c’est bien là que Keda nous offre une fonctionnalité qui nous faisait défaut avec la scalabilité native de Kubernetes.
Nous allons donc pouvoir avec Keda configurer un scaledObject basé sur le CPU/RAM comme HPA ce qui nous permet de stopper totalement notre environnement au besoin.Le nombre de pod étant à zéro, il ne faut pas oublier le temps de redémarrage de votre application :
Temps d’attente = le temps du démarrage de votre Pod + le temps de la boucle de remédiation de Keda.
Ce temps d’attente peut engendrer une erreur d’accès à votre API selon les cas et donc de desservir les besoins de vos utilisateurs.
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
annotations:
scaledobject.keda.sh/transfer-hpa-ownership: "true"
autoscaling.keda.sh/paused-replicas: "0"
spec:
scaleTargetRef:
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
triggers:
...
Nativement, il n’est pas possible de faire cohabiter VPA (VerticalPodAutoscaling) et HPA (HorizontalPodAutoscaling) car les deux se mettent en concurrence pour gérer la même ressource (moyenne de consommation CPU vs pourcentage d’utilisation). Or, si votre scaling avec Keda ne touche ni au CPU ni à la mémoire, il vous sera possible de coupler votre définition avec une configuration VPA pour gérer vos scaling verticaux tout en offrant les conditions de scaling horizontal.
Shinobi’s Bonus stage
Considérant maintenant que nous sommes en capacité de scaler notre application comme bon nous semble, il reste à prendre en compte un autre atout de Keda, c'est la possibilité d'avoir plusieurs triggers pour la même application. Il ne peut pas y avoir plusieurs scaledObject pour la même cible, mais vous pouvez mettre plusieurs triggers dans le même scaleObject.
Cas avec VPA
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: myapp
namespace: myns
spec:
cooldownPeriod: 300
maxReplicaCount: 3
minReplicaCount: 1
pollingInterval: 30
scaleTargetRef:
name: myapp
triggers:
- authenticationRef:
kind: ClusterTriggerAuthentication
name: datadog
metadata:
activationQueryValue: '10'
age: '600'
metricUnavailableValue: '20'
query: >-
sum:aws.applicationelb.request_count{env:dev* AND
(ingress.k8s.aws/resource:myns/myapplb-internet-facing-myapp:80*
OR
ingress.k8s.aws/resource:myns/myapplb-myapp:80*)}.as_count()
queryValue: '30'
timeWindowOffset: '120'
metricType: AverageValue
type: datadog
- metadata:
activationValue: '1.1'
podSelector: app.kubernetes.io/name=myfront
value: '1'
type: kubernetes-workload
Cas sans VPA
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: myapp
namespace: myns
spec:
cooldownPeriod: 300
maxReplicaCount: 3
minReplicaCount: 1
pollingInterval: 30
scaleTargetRef:
name: myapp
triggers:
- metadata:
activationValue: '1.1'
podSelector: app.kubernetes.io/name=myfront
value: '1'
type: kubernetes-workload
- type: cpu
metricType: Utilization
metadata:
type: Utilization
value: "70"
containerName: "" # entire pod
- type: memory
metricType: Utilization
metadata:
type: Utilization
value: "80"
containerName: "" # entire pod
Rex: Castle of Illusion ?
Pour ma part, j’ai eu l’occasion d’utiliser Keda dans diverses conditions et intégrations. Mais je voudrais m’attarder sur les dernières qui m’ont marqué et partager avec vous un petit retour d’expérience.
Intégration avec le scaler Datadog :
L’idée de cette intégration paraissait la plus évidente dans les conditions qui étaient les miennes pour scaler mon application. Seul Datadog avait les métriques nécessaires pour scaler avec cohérence et simplicité. Ce faisant, il m’a fallu configurer mon scaledObject, son authentification avec le clustertriggerauthentications (nous avions plusieurs applications devant se connecter à Datadog), puis définir sa valeur.
- Première configuration et premier échec, la métrique mettant trop de temps à arriver sur Datadog, je ne peux laisser la même configuration que dans la documentation.
Tips: une métrique extraite depuis CloudWatch peut mettre un temps relativement long à arriver dans Datadog - Deuxième essai, c’est la bonne ! mon application se déploie et scale correctement
Tips: il faut profiter de l’interface de Datadog pour tester vos métriques (requêtes) et surtout prendre en compte les potentiels moments où vous aurez une zone sans métrique (plus d’utilisation ou informations qui arrivent avec une latence) - Troisième essai, oui (on part enfin en prod), mon application ne scale pas correctement et pas aussi vite que ce que je le pensais …
Tips: plus haut, je vous disais qu’il fallait prendre en compte les limitations des systèmes externes. Datadog a des limitations sur ces API et selon comment vous attaquez celles-ci vous vous retrouverez avec une erreur vous indiquant que vous allez devoir patienter car vous avez atteint votre quota de scraping de métriques - il n’y aura pas de quatrième essai car cela ne nous a finalement pas gênés, la configuration précédente était la bonne. Ci-dessous notre configuration qui prend en compte une fenêtre de temps un peu plus large pour prévenir les effets de bords observés.
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: myapp
namespace: myns
spec:
cooldownPeriod: 300
maxReplicaCount: 3
minReplicaCount: 1
pollingInterval: 30
scaleTargetRef:
name: myapp
triggers:
- authenticationRef:
kind: ClusterTriggerAuthentication
name: datadog
metadata:
activationQueryValue: '10'
age: '600'
metricUnavailableValue: '20'
query: >-
sum:aws.applicationelb.request_count{env:dev* AND
(ingress.k8s.aws/resource:myns/myapplb-internet-facing-myapp:80*
OR
ingress.k8s.aws/resource:myns/myapplb-myapp:80*)}.as_count()
queryValue: '30'
timeWindowOffset: '120'
metricType: AverageValue
type: datadog
Utilisation du scaler Kubernetes Workload :
Même lorsque vous développez en microservices mais que vous avez des API qui sont interconnectées, pourquoi attendre une charge certaine sur l’ensemble de votre système avant de réagir. Surtout si la brique avant la vôtre se met à scaler, impliquant ainsi une augmentation du trafic pouvant être multiplié par 10 en quelques minutes. C’est avec ce constat que j’ai abordé ce trigger et, mes APIs étant très étroitement liées, j’ai pris l’option d’ajouter un autre trigger permettant à mon application de scaler en fonction du nombre d'instances d’une autre application. Cela m’offre une réactivité que je n’aurais pas forcément pu obtenir avec un autre trigger car avant même que mon pod distant n’ait démarré, je détecte sa présence et mon déploiement actuel se scale.
ScaledObject: (yaml)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: myapp
namespace: myns
spec:
cooldownPeriod: 300
maxReplicaCount: 3
minReplicaCount: 1
pollingInterval: 30
scaleTargetRef:
name: myapp
triggers:
- metadata:
activationValue: '1.1'
podSelector: app.kubernetes.io/name=myfront
value: '1'
type: kubernetes-workload
Ces deux cas d’usage sont des cas relativement intéressants qui auraient pu être traités différemment dans d’autres conditions. Mais ici, je n’avais pas de métrique interne au cluster (même avec Prometheus) me permettant de scaler aussi rapidement. Au vu de la charge matinale de mon API, elle passe de 10 requêtes / seconde à 2000 requêtes / seconde en moins de 15 minutes.
L’objectif ici est de faire cohabiter les limitations de nos APIs avec la capacité de gérer le trafic, le tout pour optimiser les coûts d’infrastructure de la plateforme Kubernetes qui supporte ces déploiements.
Land of Illusion ? Keda - HTTP Add-ons (bêta)
Une initiative intéressante est le Keda HTTP Add-ons. Son principal objectif est de permettre d’intégrer dans votre cluster le scaling / nombre de requêtes tout en offrant la capacité à votre application de scale depuis 0 sans avoir d’erreur côté utilisateur. L’interceptor permet de traiter votre requête tout en offrant un délai à votre API pour répondre. Ainsi, celle-ci peut démarrer avant de servir vos utilisateurs.
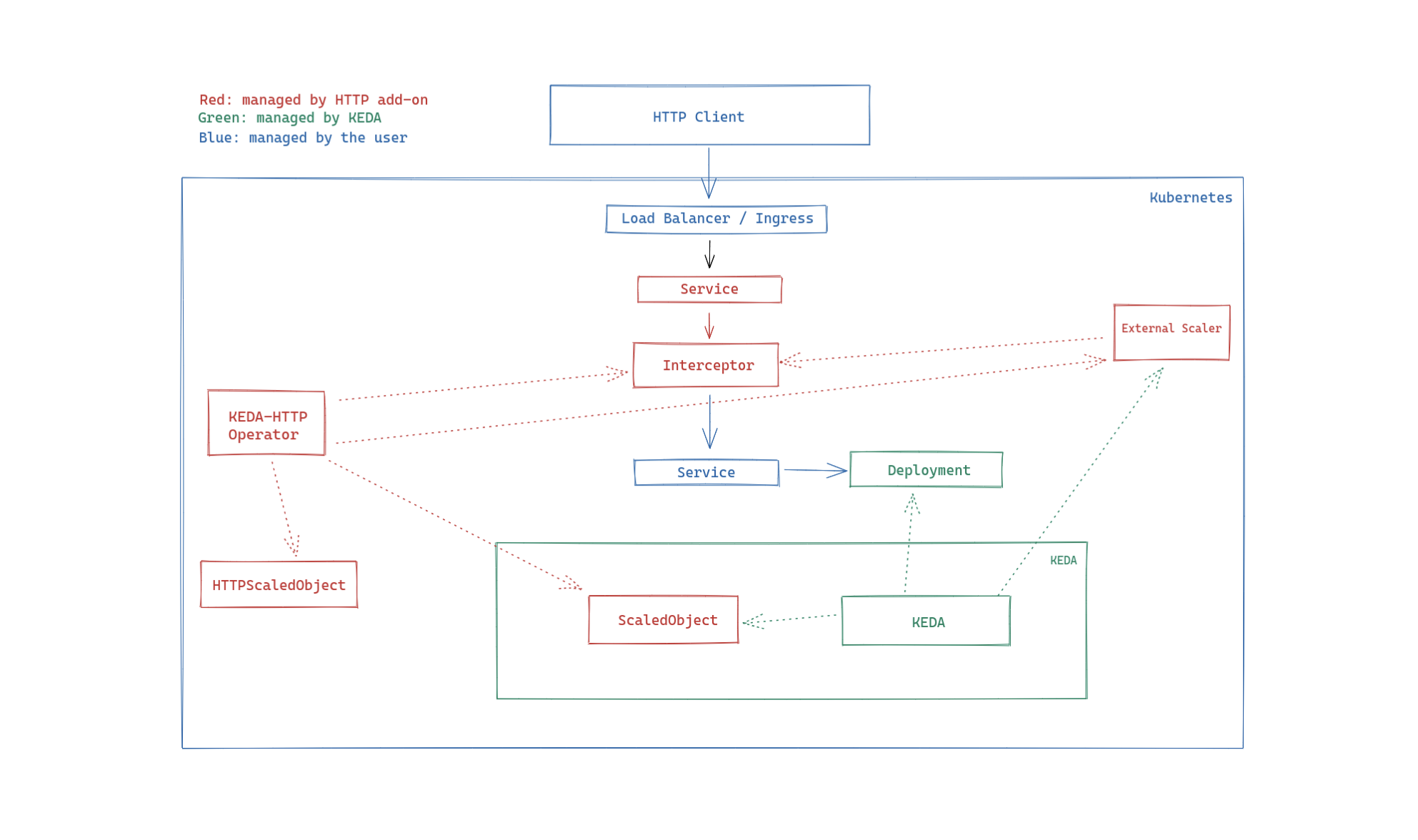
L’initiative de Keda est vraiment intéressante mais pour le moment ce n’est qu’une bêta car il manque pas mal de configurations à ScaleObject ou HPA qui sont automatiquement créées via la CRD HTTPScaledObject. De plus, il n’est pas possible de coupler l’opérateur avec un trigger externe et donc cela limite l'autoscaling aux paramètres disponibles.
Dernier point négatif, si votre application engendre un délai dans le temps de réponse, le scaler considère que votre application doit scaler au risque d’avoir des pods complètement inutiles. Il vous faudra redoubler de vigilance dans la configuration de cet opérateur.
Néanmoins, il faut saluer l’initiative qui pourrait rapidement devenir un must have dans les cas les plus simples de gestion de vos configurations d’autoscaling répondant aux nombres de requêtes / seconde.
Conclusion
Keda est définitivement un outil que vous devriez prendre en considération si vous souhaitez avoir une élasticité qui se base sur plusieurs métriques, si celles-ci ne se limitent pas aux ressources adressables avec HPA.
Il vous permet en plus de pouvoir prendre en compte les sujets de scaling tout en laissant la main à VPA pour optimiser les ressources matérielles de votre environnement.
Dans le cas d’un couplage avec un outil d’Infrastructure as Code ou d’une approche GitOps, il faudra bien prendre conscience que Keda agit sur le nombre de replica / job de votre déploiement / job et que cette donnée n’est plus une donnée statique gérée par votre outil de déploiement continu.
Sur une approche FinOps et/ou Green IT, Keda permettra de limiter vos consommations aux stricts besoins que vous allez pouvoir définir en accord avec vos équipes métiers. Tout en laissant le soin à des outils complémentaires comme VPA de travailler la taille de vos Pods optimisant encore les ressources utilisées.
| Avantages | Inconvénients |
| Les ressources de votre environnement étant généralement finies, l’optimisation du nombre d’instances permet de traiter des sujets FinOps et Green IT en plus des traditionnels besoin de gestion de partage de ressources. | Il existe une forte dépendance avec votre système sous-jacent dans l’optimisation des ressources Selon votre Cloud Provider et les limitations de ce dernier du nombre de pods par node, il vous faudra aussi tailler au mieux vos nodes applicatifs afin de ne pas surconsommer. (avec un bon autoscaler sur vos noeuds, vous pourriez réduire au maximum l’infrastructure sous-jacente) |
| La gestion du scaling basée sur de multiples critères offre une gestion fine des instances nécessaires aux services que doit rendre votre application. Il faut bien prendre en compte les limites de votre application et de vos scalers. | Les limitations de vos triggers peuvent, dans des environnements très denses en termes d’applications, vous obliger à les prendre en compte avant de définir l’utilisation de tel ou tel trigger. |
| Prendre connaissance et conscience des outils à sa disposition est un plus avec Keda qui est simple à déployer et tout aussi simple à configurer sans demander de très grosses notions des systèmes locaux ni distants. | En cas d’incident avec Keda vous perdez votre scaling et donc votre application retourne à son minimum configuré… Ce qui peut avoir une incidence forte. Keda devient de facto un point critique de votre environnement sans pour autant être une brique nativement incluse dans le control plane de Kubernetes. |

K8S : Gestion de ressources
La Scalabilité horizontale que permet Kubernetes est l’une de ses fonctionnalités les plus intéressantes mais scaler horizontalement implique plus de...