 Stephane TEYSSIER
Stephane TEYSSIER
Revue de Presse d'Avril 2019
Anthos : une plateforme pour les contrôler tous (ou plus simplement pour faciliter les déploiements multi-cloud) La conférence Cloud Next c’est...
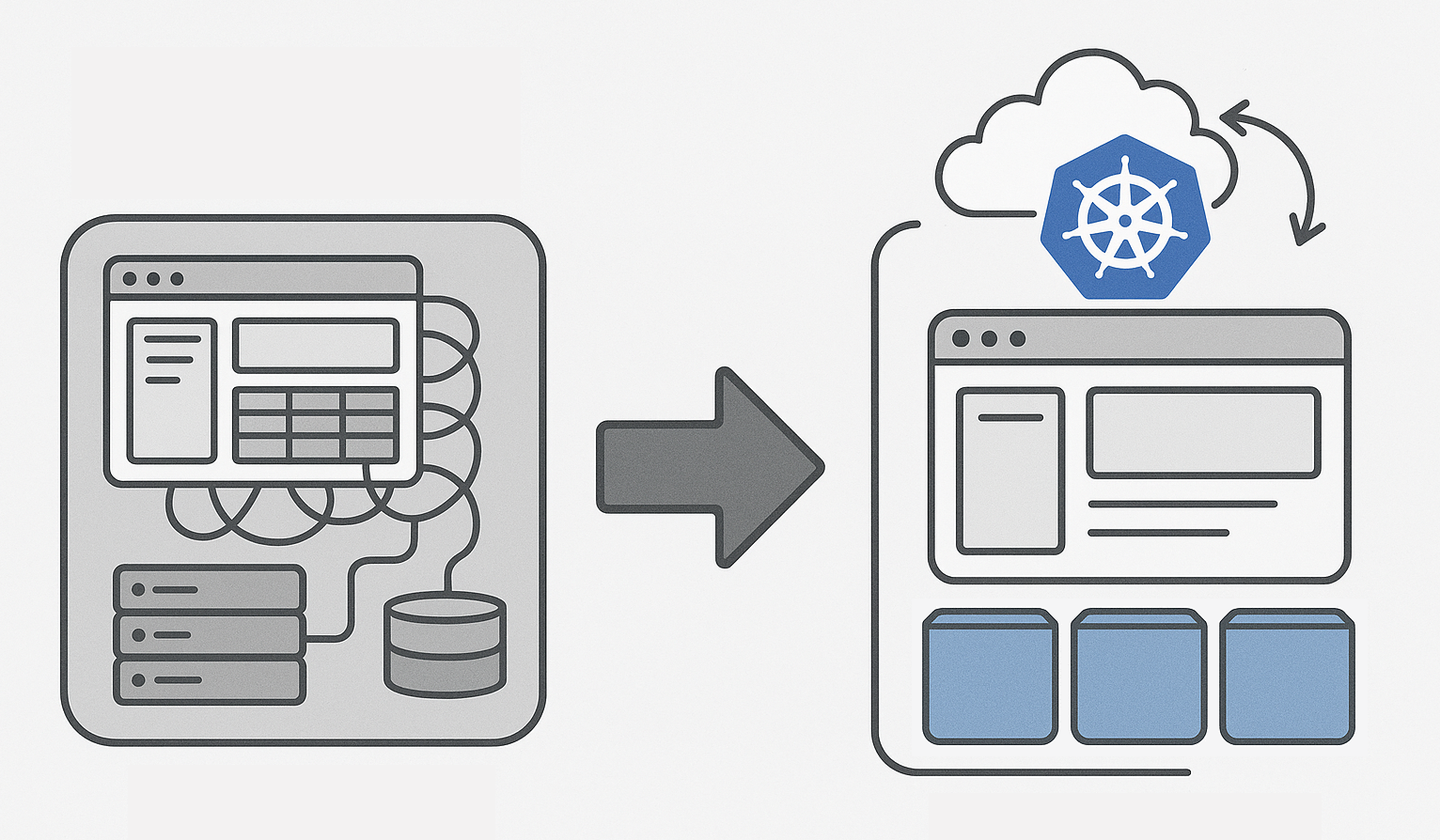

Anthos : une plateforme pour les contrôler tous (ou plus simplement pour faciliter les déploiements multi-cloud) La conférence Cloud Next c’est...

Introduction Sécuriser son système d’information demeure une préoccupation majeure. Et avec l’adoption des conteneurs et Kubernetes, de nouvelles...

L'Essor de Kubernetes Kubernetes est aujourd’hui la plateforme d’orchestration de conteneurs la plus utilisée dans le monde. Dans son rapport The...