 David Drugeon-Hamon
David Drugeon-Hamon
Mise en place d'un assistant avec l'IA : Implémentation
Dans notre premier article, nous avons exploré les défis de la création d’un assistant virtuel capable de communiquer avec les utilisateurs de...

Dans nos articles précédents, nous avons décrit la mise en place d’un agent conversationnel qui assiste nos collaborateurs dans leurs tâches quotidiennes en utilisant notre base de connaissances interne. Nous avons développé cet agent lors de notre hackathon annuel. Pour ce faire, nous nous sommes inspirés de l’architecture « Retrieval Augmented Generation » et avons adopté la solution open source DAnswer (https://www.danswer.ai).
Dans ce dernier article, nous ferons le bilan de nos apprentissages. Pour ce faire, nous nous appuierons sur le « Well-Architected Framework » d’AWS pour identifier les principaux axes d’amélioration.
Pour rappel, AWS définit dans son livre blanc « Well-Architected Framework » comment construire et déployer une application sur leur cloud public en s’appuyant sur six piliers :
Nous aborderons entre autres les défis liés à la scalabilité, à la sécurité et à la maintenance, afin de garantir une solution robuste et durable.
Cet hackathon a démontré l’importance de prendre le temps d’évaluer les différentes solutions possibles. Est-il préférable d’opter pour une solution clé en main ou de tout développer de A à Z ?
Bien que l’utilisation de frameworks comme Langchain (https://www.langchain.com) ou LiteLLM (https://litellm.vercel.app/) facilite grandement le développement de telles solutions, nous avons finalement opté pour une solution open source, comme DAnswer, afin de nous concentrer sur l’essentiel : la création d’un prototype fonctionnel pour démontrer les différents cas d’utilisation des IA génératives pour la recherche documentaire.
Ce choix nous a permis d’atteindre notre objectif dans les délais prévus et de créer un prototype fonctionnel. Il comprend des connecteurs qui permettent de récupérer des données de diverses sources (Slack, Confluence, notre blogue, etc.) et de les indexer dans sa base de connaissances. En outre, il offre une interface utilisateur intuitive. Ces éléments nous ont aidés à arrêter le développement spécifique.
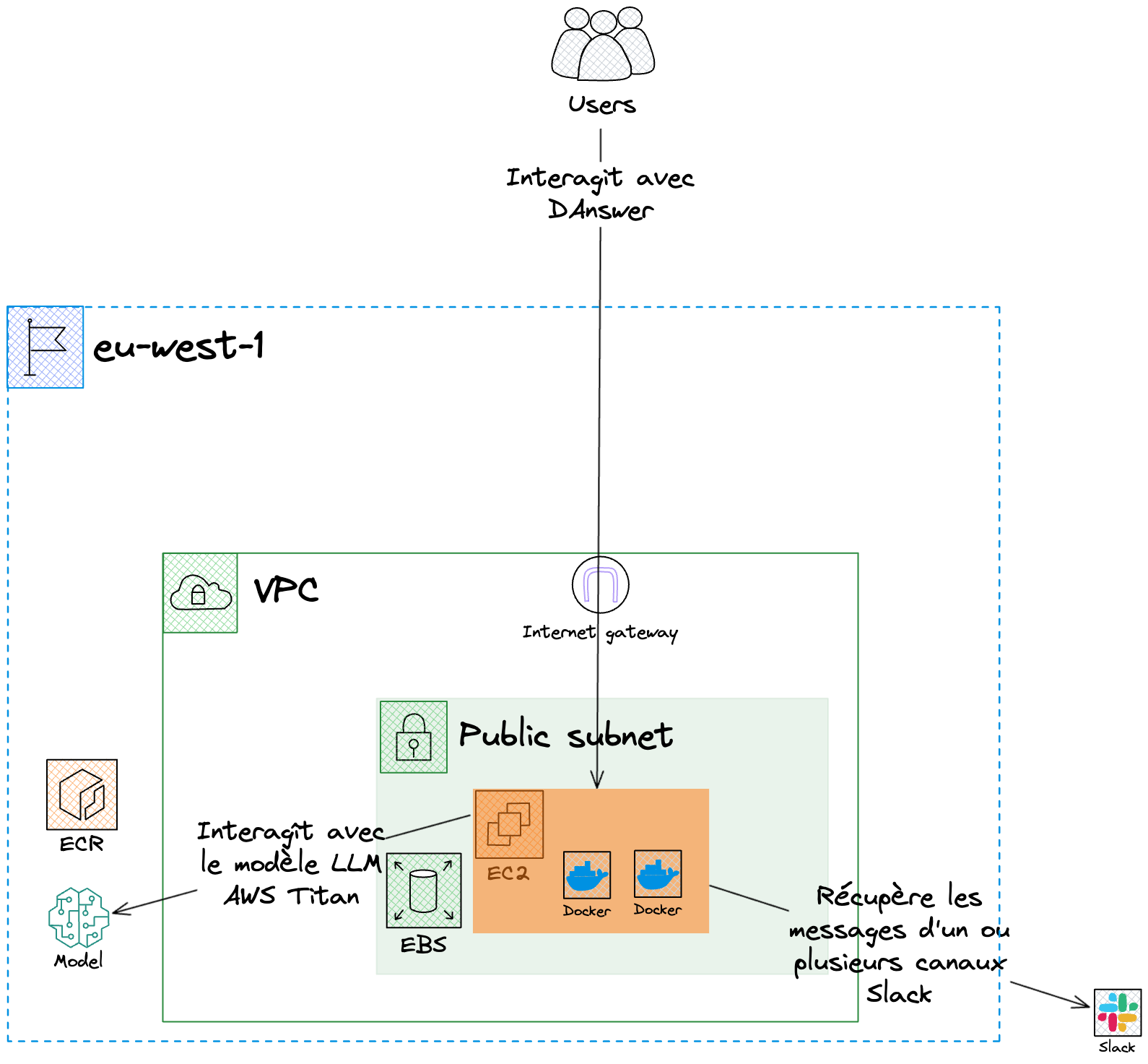
Notre prototype a été déployé sur une infrastructure simple, comme le recommande la documentation (https://docs.DAnswer.dev/production/aws/ec2). Tout y est donc déployé sur une seule instance EC2 dans une seule zone de disponibilité. Les données, elles, étaient stockées dans un volume EBS dédié pour pouvoir les récupérer en cas de défaillance de notre système.
La documentation du projet est claire et didactique. Nous avons pu facilement déployer la solution et la configurer. L’interface utilisateur de la solution est bien conçue : elle est simple et intuitive, que ce soit pour sa configuration ou pour la recherche d’informations.
Le fait que l’outil présente les résultats de la recherche sémantique dans la base de connaissances en même temps que la réponse générée par le LLM contribue à accroître la confiance des utilisateurs envers l’outil. Des solutions comme Streamlit (https://streamlit.io) pourraient nous aider à concevoir une interface utilisateur simple pour notre agent conversationnel. Mais, nous aurions eu de la difficulté à obtenir une interface aussi simple et intuitive en si peu de temps.
Cette infrastructure présente cependant des limites en termes de scalabilité et de résilience. En effet, le déploiement sur une seule instance EC2 nous expose au risque de panne. De plus, elle ne nous permet pas de faire face à une augmentation significative du trafic.
Nous envisageons donc de migrer vers une architecture plus robuste, basée sur orchestrateur de container comme AWS ECS ou un cluster Kubernetes. Cela nous permettrait de profiter d’une haute disponibilité ainsi que d’une scalabilité automatique.
En nous appuyant sur le Well-Architected Framework d’AWS, nous pourrons aussi optimiser les coûts, réduire l’empreinte carbone et garantir la sécurité de notre solution.
En mettant en place ce type d’application, nous avons réalisé qu’il est crucial de garantir la confidentialité des données. Nous ne pouvons pas la garantir si nous transmettons nos données d’entreprise à des services externes, comme OpenAI ou tout autre fournisseur de services d’IA générative. Des exemples l’ont déjà démontré, comme celui de Samsung, qui a vu des codes sources confidentiels fuiter après que leurs ingénieurs ont utilisé ChatGPT pour les aider à débugguer un probleme : https://www.bloomberg.com/news/articles/2023-05-02/samsung-bans-chatgpt-and-other-generative-ai-use-by-staff-after-leak.
Deux choix sont donc possibles pour pouvoir garantir la confidentialité de nos données.
Dans un premier temps, nous avons opté pour la première solution. DAnswer possède en effet une intégration à Ollama (https://docs.DAnswer.dev/gen_ai_configs/ollama). Malheureusement, l’expérience utilisateur n’était pas à la hauteur : les temps de latence pour obtenir une réponse étaient trop importants. Et cela occasionnait de la frustration lors de nos tests. L’utilisation d’une instance avec un GPU dédié permettrait d’obtenir de meilleures performances, mais son coût d’utilisation serait nettement plus élevé pour notre prototype.
Nous nous sommes donc rapidement orientés vers la deuxième solution en utilisant un modèle de langage proposé par Bedrock. Même si, initialement, DAnswer ne proposait pas cette intégration, elle a été vite prise en compte, après que la communauté en a fait la demande. Nous avons choisi le modèle proposé par Amazon au moment du développement, le modèle Titan. A noter qu’Amazon a déprécié ce modèle au profit de son nouveau modèle Nova.
À l’aide de ce service managé, nous avons pu retrouver une interface fluide et qui correspond aux attentes de nos utilisateurs.
Pour renforcer la sécurité des données en transit, nous avons utilisé un VPC endpoint pour accéder au service managé. Les communications réseau sont sécurisées et transitent par le réseau interne d’AWS entre notre instance et le service managé.
Pour protéger les données sensibles lors de l’utilisation de notre agent conversationnel, nous devons mettre en place une politique d’accès selon les droits du collaborateur.
A ce jour, nous n’avons pas encore indexé de documents confidentiels. Toutefois, si le besoin se présente, nous devons y remédier : DAnswer permet entre autres de cloisonner les sources et les bots en fonction du profil de l’utilisateur, mais cela nécessite de mettre en place une connexion à l’outil via un mécanisme de SSO.
Dans son offre, Bedrock propose notamment AWS Bedrock Guardrails. Ce dernier permet de définir des règles et des politiques pour contrôler l’utilisation des modèles de langage. Il garantit que les modèles ne produisent pas de contenu inapproprié, biaisé ou dangereux, en respectant les règlements en vigueur. Son utilisation permettrait d’ajouter des garde-fous sur l’utilisation de notre agent conversationnel.
Bien sûr, nous avons respecté le principe du « least privilege » dans notre stratégie IAM. Chaque utilisateur et chaque rôle possède un ensemble strictement nécessaire d’autorisations. Ainsi, seul l’utilisateur DAnswer peut accéder à AWS Bedrock (il n’est pas possible d’utiliser un rôle d’instance).
Toutefois, pour améliorer la sécurité, il est nécessaire d’auditer les politiques d’accès. Nous pouvons utiliser le service AWS IAM Access Analyzer pour identifier les autorisations excessives, ainsi que AWS Config pour vérifier la conformité de notre configuration IAM.
Comme nous l’avons vu, nous avons opté pour un déploiement « quick and dirty ». Notre infrastructure n’est absolument pas tolérante aux pannes, mais ce n’était pas l’objectif principal de ce prototype.
Pour obtenir une infrastructure plus résiliente, il faut utiliser une solution d’orchestration de conteneurs, comme ECS Fargate ou un cluster EKS Fargate. En cas de défaillance, les conteneurs pourraient alors être redémarrés automatiquement.
Pour le plan de reprise des activités, il faut établir une politique de sauvegarde des diverses sources de données, que ce soit la base de connaissances ou encore les données propres à la solution DAnswer. Il est aussi important de tester ces sauvegardes pour s’assurer qu’elles fonctionnent.
Enfin, nous pourrions utiliser une base de données vectorielle managée, comme le propose AWS avec OpenSearch Serverless ou Aurora Postgres. Cette solution permettrait de gérer efficacement les mises à jour, les sauvegardes et les restaurations. Actuellement, DAnswer ne le permet pas, mais cela pourrait être l’occasion de contribuer au projet en proposant cette fonctionnalité.
Concernant les Service Level Agreement, AWS en propose un de 99,9% pour le service Bedrock. Ce SLA est équivalent à environ 52 minutes d’indisponibilité sur une année pour notre service d’agent conversationnel. Vu la criticité de notre application, c’est largement acceptable.
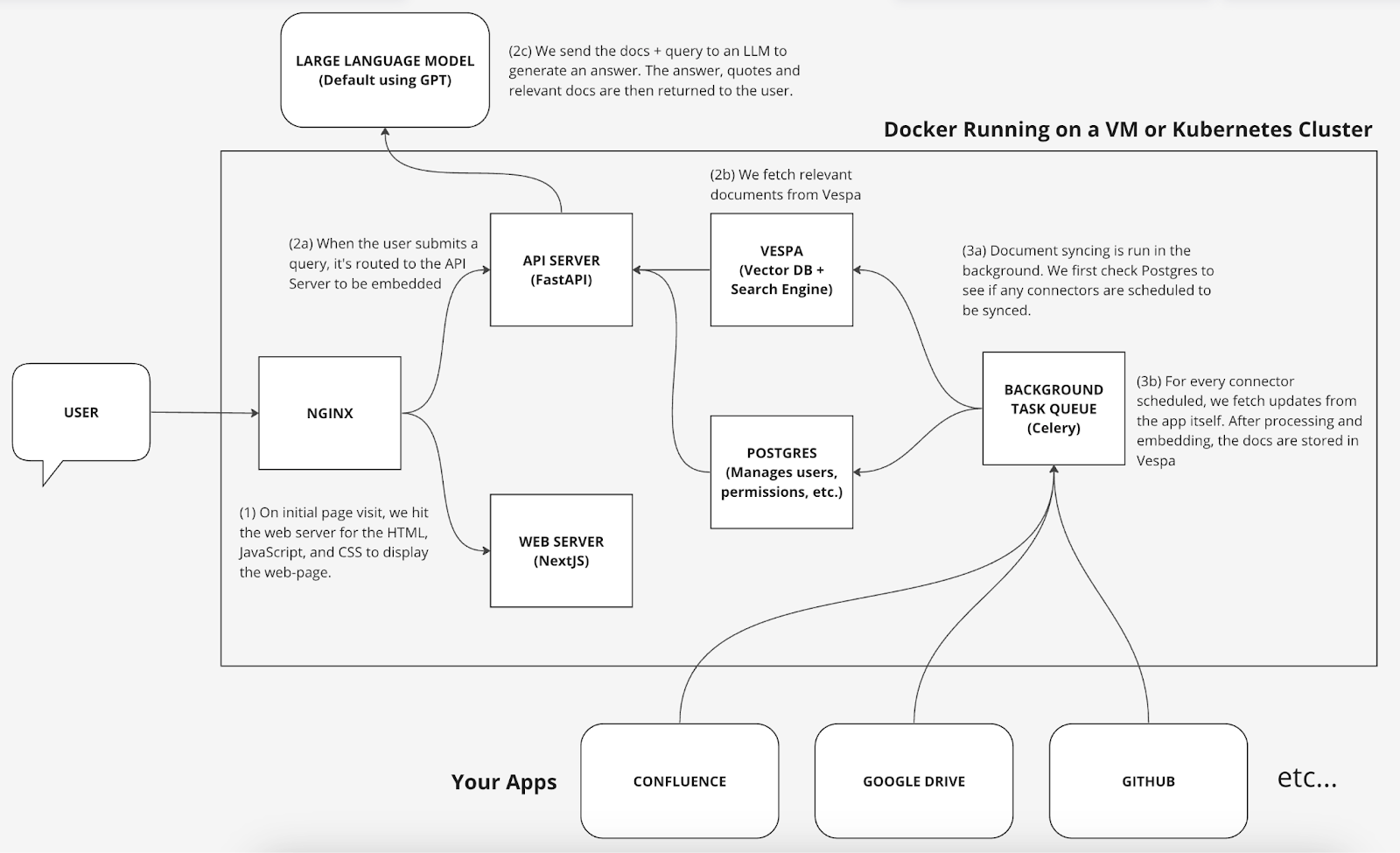
Nous avons opté pour la solution DAnswer pour sa simplicité d’installation et ses fonctionnalités adaptées à nos besoins. Sa structure logicielle est bien conçue : une partie est consacrée à l’indexation, tandis que l’autre concerne les utilisateurs.
Source : https://docs.DAnswer.dev/system_overview
DAnswer utilise déjà une approche asynchrone, ce qui permet d’ajuster la charge en fonction du nombre, par exemple, de sources de données. Pour être encore plus efficace, il faudrait pouvoir mettre en place une politique de scaling automatique en fonction de la charge et en fonction du nombre d’éléments dans la file de messages pour l’indexation.
Le déploiement sur un orchestrateur de conteneurs comme EKS faciliterait la possibilité de scaling automatique. De plus, l’utilisation de composants serverless améliorerait les performances sur certains composants, mais cela nécessiterait de repenser l’architecture du projet.
Comme nous l’avons vu dans notre article précédent, l’utilisation du service AWS Bedrock permet d’améliorer les performances en ce qui concerne la génération de texte, ce qui améliore l’expérience utilisateur.
Dès le début du projet, nous avons choisi d’utiliser Terraform et Packer pour déployer notre infrastructure. Cela nous a permis de tester rapidement notre solution dans différents environnements. Par conséquent, il faut prévoir un environnement dédié afin de tester les sauvegardes et les mises à niveau avant de les mettre en production.
L’automatisation des déploiements grâce à une chaîne de déploiement continu permettrait d’améliorer notre solution, par exemple en facilitant les mises à jour logicielles ou les mises à jour de sécurité.
L’observabilité a été volontairement omise, compte tenu du temps alloué. Il est nécessaire d’être réactif et de mesurer des indicateurs métiers sur les diverses composantes de l’architecture logicielle, que ce soit l’ingestion des données, l’indexation ou la recherche. AWS offre des métriques spécifiques à son utilisation d’AWS Bedrock. Des tableaux de bord sur AWS Cloudwatch nous permettraient d’être plus réactifs en cas de problème.
Comme nous l’avons vu dans la section « Fiabilité », il est également important d’établir une politique de sauvegarde efficace.
La mise en place d’une architecture d’IA générative est beaucoup plus énergivore qu’une architecture d’applications classiques. Il est donc nécessaire de mesurer et d’ajuster l’infrastructure pour minimiser les coûts, mais aussi l’empreinte environnementale.
Plusieurs stratégies ont déjà été mises en place. D’abord, nous avons opté pour une instance fonctionnant avec des processeurs ARM. Cette technologie permet d’être plus efficace et nettement moins dispendieuse. En comparaison avec une instance traditionnelle, nous pouvons réduire les dépenses d’environ 30 % pour la même période d’utilisation, et ce, sans que les performances soient affectées.
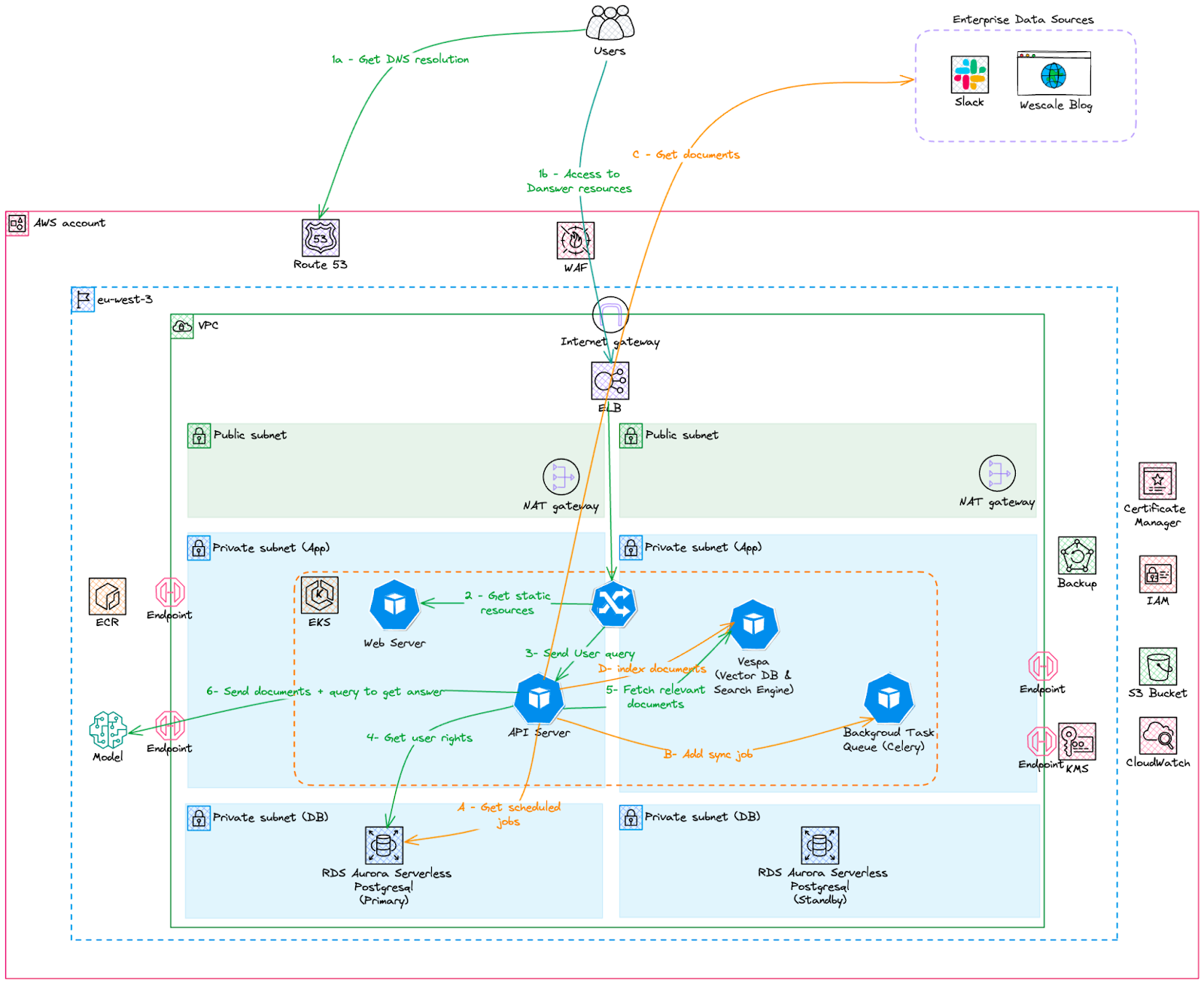
Pour réduire notre empreinte environnementale, il est judicieux de choisir une région dont la production électrique est la moins émettrice en CO2 mais aussi où la consommation en eau pour refroidir les datacenters est la plus basse (https://timspirit.fr/articles/etat-des-lieux-des-indicateurs-environnementaux-du-cloud/) . Des outils comme Electricty Maps (https://www.electricitymaps.com/) nous permettent de comprendre quelles sont les sources de production d’électricité d’un pays ou d’une région. Grâce à celui-ci, nous avons choisi de déployer notre service sur la région Paris (eu-west-3) vu que la France utilise principalement des centrales nucléaires ce qui émet le moins de CO2..
Pour une utilisation en production, notre architecture devrait, comme nous l’avons vu, utiliser des services d’orchestration de conteneurs sans serveur. EKS Fargate pourrait être un bon candidat.
Concernant les coûts d’utilisation d’IA génératives, il est important de surveiller leur utilisation. En fonction de la charge de notre agent, cela peut engendrer une croissance exponentielle de leurs coûts si leur utilisation n’est pas contrôlée. La tarification est complexe à appréhender. En effet, les coûts dépendent du modèle de fondation choisi, du nombre de requêtes et de la longueur des réponses. Il est donc nécessaire de pouvoir superviser efficacement l’utilisation de ce service afin de limiter, par exemple, la taille des réponses générées. Concernant notre prototype, nous sommes restés vigilants même si au final nous sommes restés dans le free tiers proposé par AWS.
Un hackathon est l’occasion pour les participants de travailler en équipe sur un sujet qui leur tient à cœur. C’est également l’occasion d’expérimenter de nouvelles technologies et de sortir de sa zone de confort. Enfin, c’est aussi une occasion de pouvoir collaborer avec des collègues avec qui nous n’avons pas l’habitude de travailler au quotidien.
Grâce à l’intelligence collective, nous avons pu mieux comprendre le concept d’agent conversationnel, et surtout celui des intelligences artificielles génératives. Même si elles sont de plus en plus accessibles et faciles à intégrer, il est important de bien comprendre leurs avantages et leurs limites. Nous avons aussi exploré des alternatives, telles que les architectures RAG (Retrieval-Augmented Generation), afin d’améliorer notre agent.
Les leçons tirées de cette expérience ont été nécessaires pour transformer notre prototype en une solution pérenne et fiable.
Depuis l’arrivée des IA génératives, comme ChatGPT d’OpenAI ou Gemini de Google, les entreprises ont revu comment les utiliser dans leurs applications actuellement déployées. De nouvelles initiatives émergent régulièrement, ce qui rend nécessaire de s’intéresser au sujet afin de pouvoir répondre efficacement aux besoins de notre clientèle.
Nous envisageons d’adopter une architecture basée sur AWS EKS Fargate. Cette solution nous permettra d’offrir la flexibilité et la scalabilité nécessaires pour gérer les charges de travail de manière dynamique, tout en assurant une gestion optimisée des coûts et une empreinte carbone réduite. Nous utiliserons le service AWS Bedrock pour gérer nos modèles de fondation LLM.
À noter qu’un certain nombre de solutions proposées par les « cloud providers » ont fait leur apparition depuis notre hackathon.
Par exemple, AWS propose différentes solutions pour mettre en place des applications basées sur des LLM comme Bedrock Knowledge Bases ou encore Amazon Q for business, qui permet d’agréger différentes sources de données afin de créer un chatbot basé sur les données de l’entreprise. Cette dernière solution pourrait être envisagée en raison de ses contraintes opérationnelles et de ses coûts.
Photo de couverture par Greg Rosenke sur Unsplash

Dans notre premier article, nous avons exploré les défis de la création d’un assistant virtuel capable de communiquer avec les utilisateurs de...

Introduction à Nomad et Consul par HashiCorp Nomad est un orchestrateur de conteneurs développé par HashiCorp. Allié à Consul, c’est une excellente...
