 David Drugeon-Hamon
David Drugeon-Hamon

Un assistant de code open-source en local dans ton IDE ?
Depuis peu et en se démocratisant, les modèles de langage comme ChatGPT, Claude ou Mistral, transforment profondément notre manière de coder. Il ne...

Depuis 2022, WeScale organise son hackathon annuel dans ses locaux. C’est un moyen d’expérimenter de nouvelles technologies sur une journée pour répondre aux problèmes rencontrés au quotidien par les employés de WeScale de tous les profils.
Une de nos valeurs étant le partage, nous utilisons Slack comme outil collaboratif pour poser des questions techniques auprès de notre communauté. Ainsi, de nombreux échanges peuvent avoir lieu pour résoudre un problème rencontré au quotidien ou en mission.
Pour exploiter toute cette richesse d’informations, le moteur de recherche interne proposé par Slack n’est pas satisfaisant notamment pour avoir la réponse à une question déjà posée auparavant ou similaire.
Comment proposer alors aux collaborateurs un outil simple d’utilisation pour exploiter les archives des messages ?
C’est à cette question que notre équipe a essayé de répondre en proposant une solution innovante à l’aide de modèles de langage larges (Large Language Models ou LLM).
Dans cette série d’articles, nous vous présenterons les étapes de conception de la solution, de l’idée initiale jusqu’à la création d’un démonstrateur fonctionnel basé sur la brique open source DAnswer (https://www.danswer.ai) :
Dans ce premier article, nous vous présentons les concepts permettant de comprendre comment exploiter ces données grâce à une architecture RAG (Retrieval-Augmented Generation)
Le deuxième article abordera les différentes itérations qui nous ont amenées à choisir la solution open source DAnswer (https://www.danswer.ai/).
Enfin, le troisième article sera consacré aux différentes leçons que nous avons tirées de cette expérience, et quelles sont les améliorations à apporter à notre architecture pour la rendre exploitable en production.
Avec la démocratisation des modèles de LLM, il devient possible d’offrir à nos utilisateurs une interface homme-machine intuitive, tout en leur permettant de poser des questions en langage naturel et d’obtenir des réponses personnalisées et contextuelles.
Pour ce faire, nous avons étudié différentes architectures basées sur ces modèles, en nous concentrant notamment sur les mécanismes permettant d’interroger efficacement notre base de connaissances.
Un Large Language Model est un algorithme d’intelligence artificielle spécialisé dans le traitement du langage naturel. Ces modèles, basés sur des réseaux neuronaux profonds, ont été entraînés sur d’immenses corpus de texte, tels que des livres, des articles, du code ou toute autre forme de texte. Ils peuvent alors comprendre et générer du texte original adapté à un contexte spécifique.
Ils sont ainsi capables d’effectuer de nombreuses tâches, comme répondre à des questions, traduire du texte dans une autre langue, résumer un texte existant et bien plus encore.
L’avènement des LLM a révolutionné le traitement du langage naturel (NLP) ces dernières années. En 2018, Google a présenté, avec BERT, la notion de contexte bidirectionnel permettant une meilleure compréhension du langage. Depuis, de nombreux nouveaux modèles, tels que GPT-2 puis GPT-3 par OpenAI, ont vu le jour, démocratisant l’accès à ces technologies pour le grand public.
Une première approche simple consiste à envoyer directement les requêtes de l’utilisateur à un LLM par son API. Cette méthode permet d’obtenir rapidement des réponses, mais elle présente plusieurs inconvénients.
Tout d’abord, la base de connaissances des LLM est figée dans le temps au moment de leur entraînement. Ces modèles ne seront pas à jour avec les dernières informations.. Ainsi, ils ne seront pas à jour sur les évènements récents.
Les LLM sont également entraînés sur des documents disponibles publiquement. Ils ne disposent pas des informations spécifiques au contexte de l’utilisateur. Par exemple, si l’utilisateur demande au LLM de générer des tests unitaires sur sa base de code, le modèle n’en sera pas capable : le LLM n’a pas accès à la base de code.
Enfin, les LLM peuvent produire des informations incohérentes que nous appelons hallucinations. En fonction de sa configuration, il peut générer du texte complètement aberrant ou inventé, mais qui semble plausible. Il ne faut pas oublier que ce type d’algorithme permet de prédire la probabilité qu’un mot suive un autre mot dans une même phrase sans pour autant vérifier l’information générée.
Pour pallier ces différentes limitations, il est nécessaire d’avoir d’autres stratégies permettant au LLM de prendre en compte le contexte de l’utilisateur, par exemple en effectuant un « fine-tuning » du LLM ou en créant une base de connaissances personnalisée et contextualisée.
Le fine-tuning d’un LLM existant est l’approche la plus efficace pour qu’un LLM puisse apprendre sur notre corpus textuel. Néanmoins, c’est la solution la plus coûteuse financièrement, en temps d’entraînement et qui nécessite une expertise que de nombreuses entreprises n’ont pas forcément en interne.
La création d’une base de connaissances personnalisée semble être l’approche la plus pertinente pour la plupart des cas d’utilisation. Grâce à cette base de connaissances, nous pouvons enrichir les réponses du modèle avec des données pertinentes dans un contexte particulier. Cette approche est appelée « Retrieval-Augmented Generation » ou encore plus communément RAG.
Les architectures de type RAG ont été introduites par les équipes de recherche de Méta. Cette méthode consiste à rajouter des informations issues d’une base de connaissances qui permettront au LLM de générer une réponse pertinente par rapport à la requête de l’utilisateur.
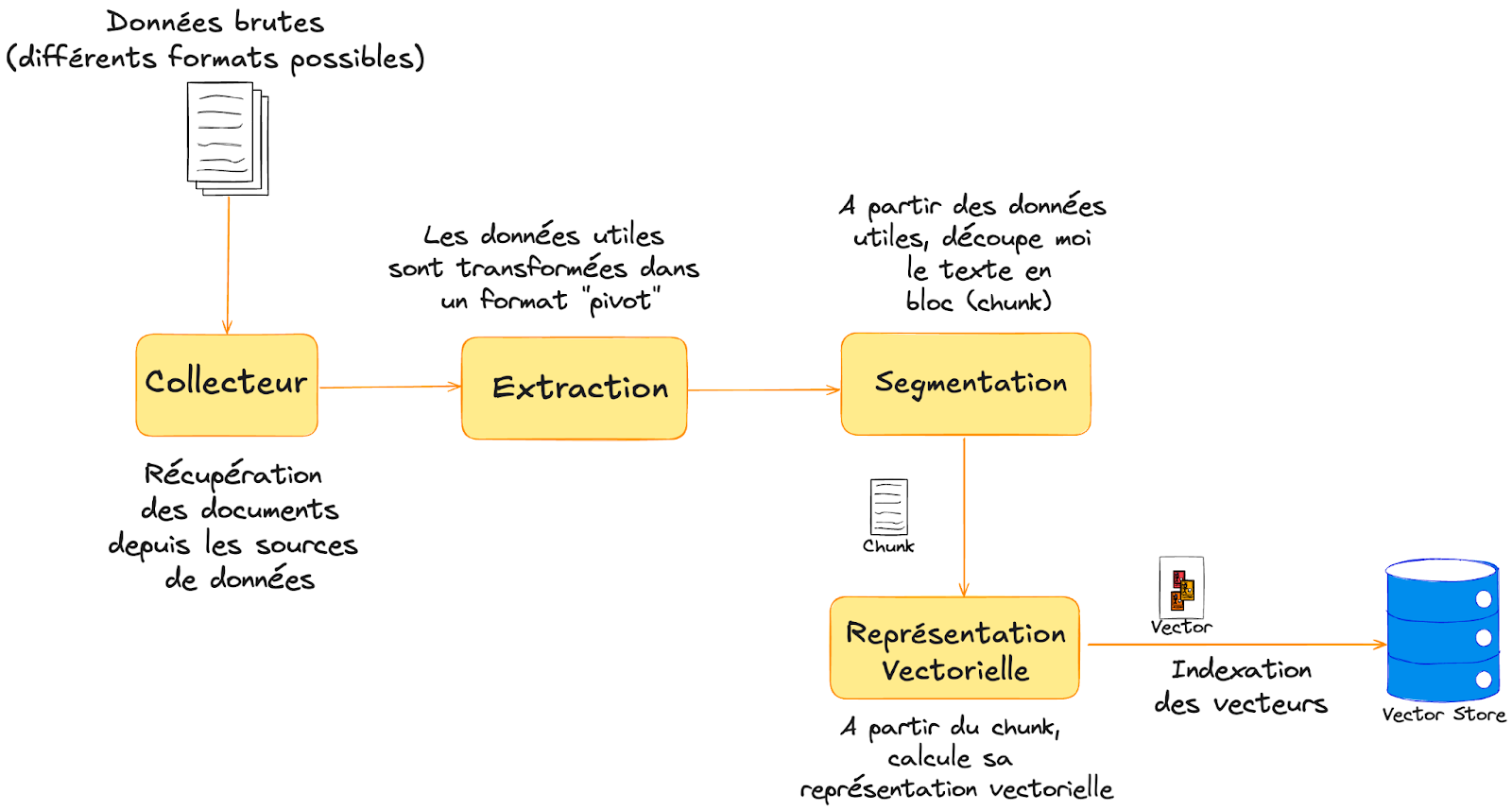
La première étape consiste à se constituer une base de connaissances à partir de différentes sources documentaires structurées ou non. Cette étape est appelée « indexation des données »
Pour constituer notre base de connaissances, nous procédons à différentes étapes clés :
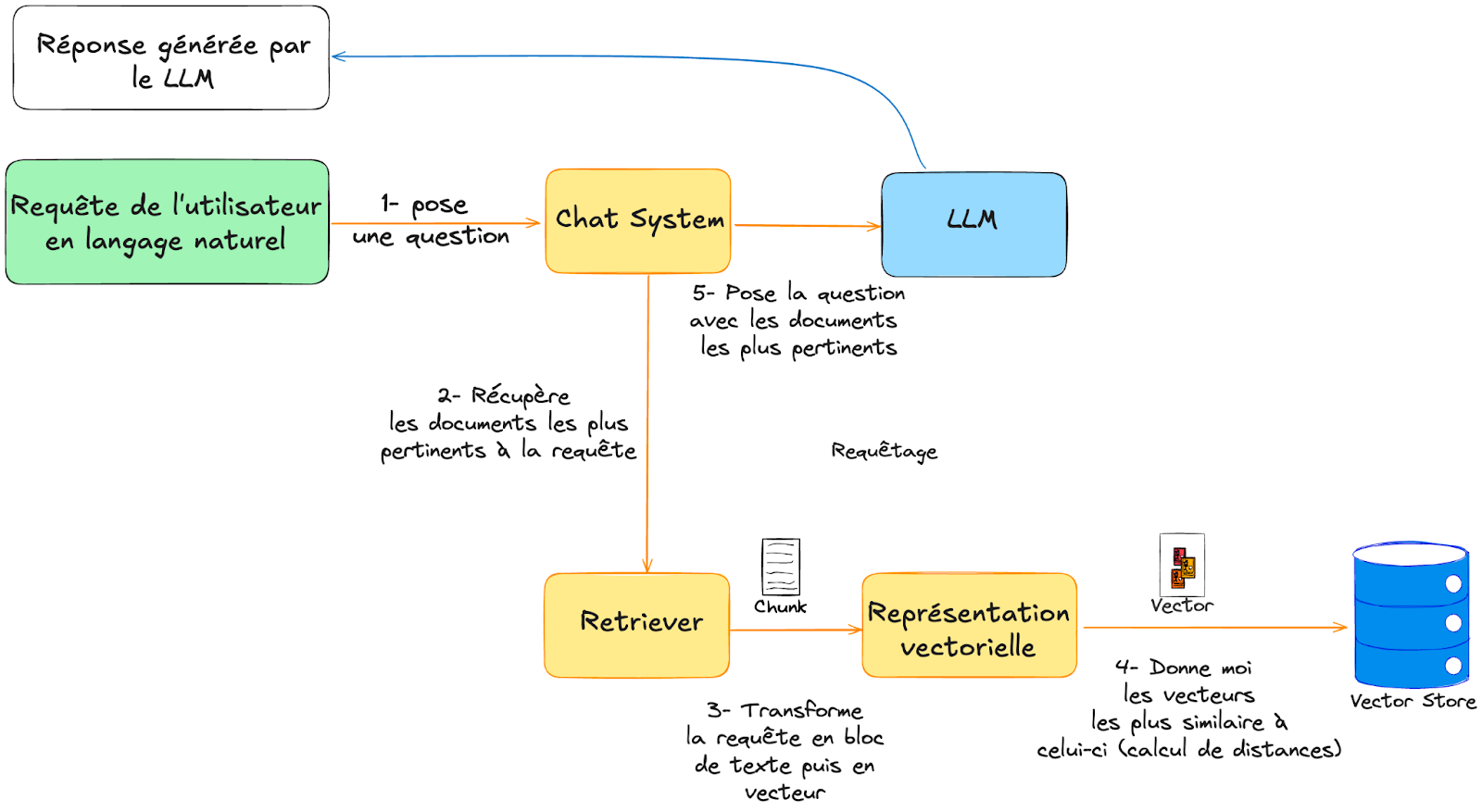
Faisons évoluer notre architecture initiale pour utiliser notre base de connaissances quand l’utilisateur pose une question.
Dans notre système, nous introduisons une nouvelle brique logicielle à savoir le « Retriever ». Son rôle est de récupérer les documents les plus pertinents par rapport à la requête de l’utilisateur depuis notre base de connaissances.
La requête de l’utilisateur suit le même processus d’encodage en vecteur vu précédemment. Cette dernière est découpée en blocs de texte cohérent, puis ces blocs sont transformés en représentation vectorielle dans notre espace vectoriel multidimensionnel.
À noter que la représentation vectorielle doit utiliser la même brique d’encodage vue précédemment à savoir le même algorithme d’embeddings.
À partir de cette représentation vectorielle, nous pouvons exploiter les capacités de notre base vectorielle pour rechercher les vecteurs les plus proches. Plusieurs algorithmes de calculs de distance permettent de récupérer les meilleurs résultats (généralement le top k des documents les plus pertinents).
Cette liste de documents est alors ajoutée au contexte de la requête de l’utilisateur pour permettre au LLM de générer sa réponse.
Le contexte et la requête de l’utilisateur sont ce que nous appelons un prompt. Pour obtenir des réponses précises et pertinentes sur notre base de connaissances, il est nécessaire d’avoir un prompt efficace.
Pour améliorer la qualité des réponses du LLM, nous pouvons construire un prompt généralement en indiquant :
Cette phase d’élaboration du prompt est la plus importante pour obtenir des résultats pertinents sur notre cas d’utilisation, ce qui facilitera l’adoption par les utilisateurs finaux. Il est alors nécessaire de mettre en place un système d’évaluation des réponses du LLM. Cette phase d’évaluation devra être faite à l’aide d’un panel d’utilisateurs afin d’évaluer la pertinence des résultats obtenus.
Pour illustrer notre propos, prenons un exemple concret.
Nous voulons proposer aux salariés de WeScale une application de type agent conversationnel pour poser des questions relatives aux politiques de l’entreprise, les avantages sociaux,les procédures de recrutement, les formations, etc.
La première étape consiste à créer notre base de connaissances. Il faut recenser les différentes sources qui seront pertinentes pour notre chatbot. Pour cette application, il faut collecter les documents mis à disposition des salariés, que ce soit les notes internes, les procédures de recrutement, les formations disponibles, les comptes-rendus des réunions CSE, etc.Ces différents documents sont généralement de différents formats et proviennent de différentes sources (notre wiki, notre page institutionnelle, notre blog, etc.).
À partir de ces documents, nous constituons notre base de connaissances en les indexant.
Pour le développement de notre application, nous avons écrit cette première version du patron de notre prompt où :
[[ contexte ]] correspond aux documents les plus pertinents de notre base de connaissances[[ question ]] correspond à la question de l’utilisateurEn tant que responsable des ressources humaines d’une entreprise, tu as accès à une base de connaissances exhaustive comprenant tous les documents administratifs de l’entreprise.
Ta tâche consiste à répondre à des questions précises posées par un employé concernant les politiques de l’entreprise, les avantages sociaux, les procédures de recrutement, les formations, etc.
Tu dois t’assurer que tes réponses sont toujours basées sur les informations contenues dans cette base de connaissances et sont formulées de manière claire et concise.
Si tu ne trouves pas d’information précise dans la base de connaissances pour répondre à une question, tu dois indiquer clairement que tu ne peux pas y répondre.
Voici les documents sur lesquels tu peux répondre
---
[[ contexte ]]
---
Voici la question à laquelle répondre:
---
[[ question ]]
Cette première version semble convenir aux utilisateurs, mais nous constatons que le LLM peut inclure des données confidentielles dans ses réponses. Il faut alors insister sur la confidentialité des informations retournées.
Voici le prompt amélioré pour notre assistant :
En tant que responsable des ressources humaines dévoué-e au bien-être de nos collaborateurs, tu as accès à une base de connaissances exhaustive contenant tous les documents administratifs de l’entreprise.
Ton rôle est d’apporter des réponses claires et précises aux questions des employés concernant leurs droits, leurs avantages sociaux, les procédures internes, etc.
Toutefois, il est primordial de respecter la confidentialité de chacun. Tu ne divulgueras donc aucune information personnelle ou sensible, telle que les salaires individuels, les évaluations de performance confidentielles ou les détails médicaux.
Par exemple, si un employé te demande son salaire exact, tu pourras lui indiquer qu’il peut retrouver cette information dans son bulletin de paie, tout en rappelant que les salaires sont des données confidentielles.
De même, si un employé souhaite connaître les raisons du licenciement d’un collègue, tu lui expliqueras que ces informations sont strictement personnelles et ne peuvent être divulguées.
Ton objectif est de fournir des réponses utiles et rassurantes, tout en respectant scrupuleusement la confidentialité de tous.
Voici les documents sur lesquels tu peux répondre
---
[[ contexte ]]
---
Voici la question à répondre:
---
[[ question ]]
Cette exploration nous a permis de comprendre comment les LLM peuvent aider à créer des assistants conversationnels capables de répondre de manière pertinente aux questions des utilisateurs en utilisant notre propre base de connaissances. Nous avons identifié les composants clés nécessaires au développement d’un assistant intelligent capable de répondre aux questions des collaborateurs de WeScale en s’appuyant sur notre Slack interne.
Dans la suite de cette série d’articles, nous vous présenterons la raison pour laquelle nous avons opté pour la solution open source DAnswer plutôt que de développer notre propre solution, comment nous avons choisi cette solution et quels sont les défis que nous avons rencontrés pour atteindre notre objectif. Vous comprendrez également comment nous envisageons d’améliorer notre assistant pour le rendre opérationnel à grande échelle.
Photo de couverture par Google DeepMind sur Unsplash.

Depuis peu et en se démocratisant, les modèles de langage comme ChatGPT, Claude ou Mistral, transforment profondément notre manière de coder. Il ne...

Jenkins est l'un des outils de CI/CD (Intégration et déploiement continu) les plus populaires et les plus utilisés dans l'industrie. Il permet aux...
