
Saga Multi-Cloud E04 Stockage et réplication des données en mode multi-cloud
Cet article fait partie d’une série d’articles autour du thème "Construire des applications résilientes en multi-cloud".

Sommaire
Dans nos précédents articles, nous avons vu comment construire une infrastructure multi-cloud en reliant AWS et GCP via un VPN, puis nous avons préparé un annuaire de service ainsi que des répartiteurs de charge, et enfin nous avons déployé un orchestrateur de conteneurs pour pouvoir instancier nos applications. Nous conservons l’objectif suivant : permettre à nos applications d’exister entre plusieurs fournisseurs de cloud.
Nous verrons ici comment gérer le stockage mis à disposition de nos différentes applications.
Cette nouvelle étape va s’appuyer sur les précédentes, donc n’hésitez pas à vous faire une piqûre de rappel en relisant les autres articles :
- E01 Construction d’une infrastructure multi-cloud.
- E02 Découverte de service et répartition de charge multi-cloud.
- E03 Mon orchestrateur de conteneurs.
La création de l’infrastructure est assistée par Terraform, mais peut aussi être réalisée manuellement.
Le code utilisé est publié au fur et à mesure des articles sur : https://github.com/bcadiot/multi-cloud.
Pour information, afin de simplifier l'article, certains éléments n'apparaissent pas (comme les security group et les variables Terraform) mais peuvent être récupérés depuis les sources publiées sur github.
TL;DR
Plusieurs types de stockages existent ; qu'ils soient structurés, non structurés, répliqués synchrones ou asynchrones, chacun apporte des avantages et des inconvénients.
Un des éléments les plus importants à prendre en compte lors de la construction d'un stockage répliqué multi-cloud est l'état du réseau reliant les deux clouds. Des tests de latence et de débit sont effectués et permettent d'orienter le choix d'une solution de stockage.
Enfin, un exemple de déploiement d'un cluster Minio multi-cloud assure que l'offre de service stockage est accessible, fonctionnelle et résistante aux pannes.
Quel est l’objectif ?
En nous appuyant sur notre infrastructure, nous allons réfléchir aux moyens de mettre en place un stockage accessible aux différentes briques de notre infrastructure. Beaucoup de solutions existent, nous allons en étudier plusieurs, et finir par tester l'installation de l'une d'entre elles : Minio.
Le schéma ci-dessous représente notre architecture cible :
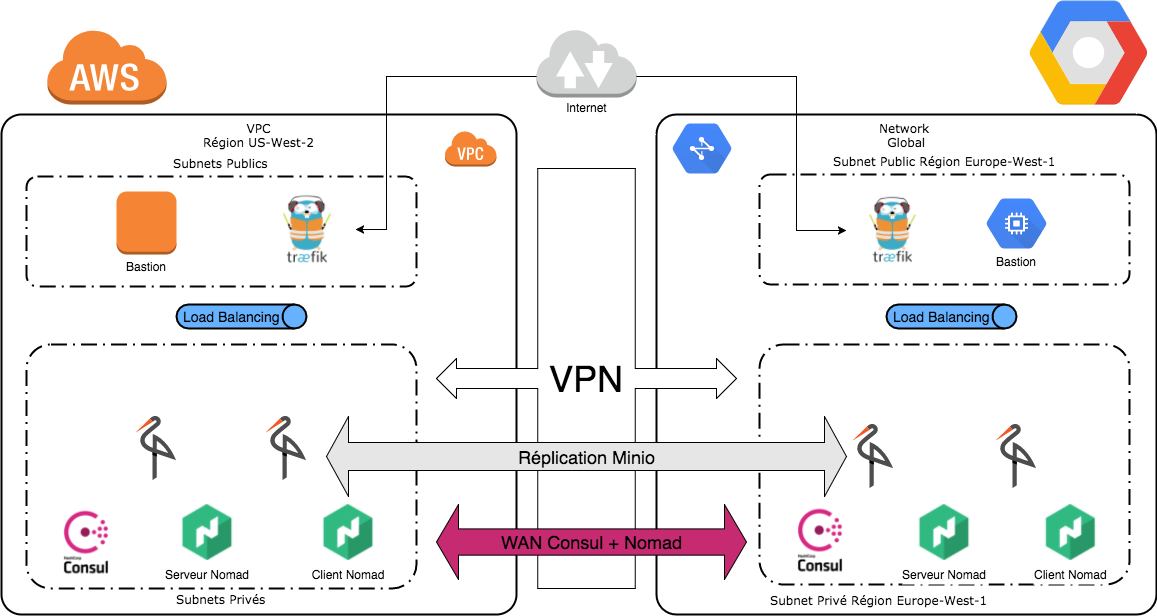
Types de stockage
Contrairement à ce que l'on pourrait penser, il y a plusieurs types de stockage et plusieurs mécanismes pour parvenir à nos fins.
Structure du stockage
Les mécaniques de stockage vont s'articuler autour de deux principales logiques : les stockages dits "structurés" et ceux "non structurés".
Dans un stockage structuré, la cohérence est gérée globalement et cela permet des traitements directement sur le stockage. Ce type de stockage nécessite l'utilisation de transactions et de verrous afin de garantir la cohérence de l'ensemble. La présence de ces verrous complexifie les déploiements distribués et/ou répliqués. En tant qu'exemple de stockage on peut citer :
- La plupart des bases de données (MySQL, Mariadb, PostgreSQL, OracleDB, SQL Server, etc...)
- Les systèmes de fichiers (ext4, ext3, ntfs, xfs, etc...)
À l'opposé, on trouve le système non structuré où la cohérence s'applique au niveau des métadonnées du stockage. Chaque élement est un objet et est indépendant des autres, cela permet d'augmenter drastiquement la concurrence des accès. Ce type de stockage est souvent très performant mais les capacités de traitements directs sont beaucoup plus limitées. On citera quelques-uns :
- Les bases de données distribuées (Cassandra, Scylla, HBase, etc...)
- Les systèmes de fichiers distribués (GlusterFS, BeeGFS, HDFS, IPFS, etc...)
- Les stockages objets distribués (Ceph, Infinit, Minio, etc...)
Réplication synchrone et asynchrone
Chaque service va écrire et lire les données sur le stockage mis à disposition au sein de son fournisseur de cloud, néanmoins pour être complètement multi-cloud il s'agit de trouver un mécanisme pour répliquer les données sur l'autre fournisseur de cloud.
La réplication peut se faire de manière synchrone ou asynchrone, cela a des conséquences sur les capacités offertes par le stockage mais également sur les contraintes qui pèsent dessus.
Lors d'une réplication synchrone, chaque noeud de stockage doit acquiescer les écritures avant que la transaction soit réellement réalisée. Ce mode permet de garantir la cohérence du stockage et une bascule vers n'importe quel noeud du stockage, s'ils ne sont pas déjà tous actifs. Néanmoins, ce type de réplication a des contraintes importantes notamment quant aux performances réseaux et disques.
La réplication asynchrone permet un peu plus de souplesse car les données sont d'abord écrites localement au noeud de stockage, et sont ensuite répliquées plus tard suivant une politique définie. Cette politique peut être de type streaming, ce qui implique une réplication au fur et à mesure, ou de type batch, ce qui signifie que les données seront envoyées selon une intervalle.
Solutions possibles
Les possibilités étant très diversifiées nous n'allons pas toutes les étudier, mais d'abord regarder ce qui est possible pour répondre à chaque besoin.
Choix d'un composant de stockage
Afin de choisir notre stockage il faut étudier ce dont aura besoin notre application. Certaines nécessiteront une base de données relationnelle pour stocker et structurer leurs données, alors que d'autres se contenteront d'un simple stockage objet non structuré.
Si l'on développe sa propre application, alors nous sommes relativement libres de nos choix. En revanche si nous utilisons un framework, nous serons le plus souvent limités par une liste de technologies.
Par exemple si nous déployons un serveur Wordpress, alors un serveur MySQL ou MariaDB est exigé. Alors qu'un site statique type Jekyll pourra se servir uniquement d'un stockage uniquement.
Cependant, beaucoup d'applications demandent un panaché afin de séparer la base de données relationnelle et le stockage des données brutes.
Si on veut être pleinement compatible multi-cloud il faut prendre en compte la particularité de notre infrastructure lors du choix de notre stockage et la conception de notre application. Le but étant de s'assurer une disponibilité maximale même en perdant l'un des fournisseurs de cloud.
Et le stockage géré ?
Une autre possibilité est de profiter des services offerts par nos fournisseurs de cloud. Chacun dispose d'une offre de service stockage, qu'elle soit structurée ou non structurée.
Pour le stockage chez AWS on trouvera notamment RDS, DynamoDB, Redshift, EFS, S3, etc...
Quant à Google Cloud, nous pouvons utiliser SQL, Datastore, Bigtable, Spanner, GCS, etc...
Chacun de ces services peut être utilisé très facilement, en revanche la difficulté se situe dans la réplication entre les deux fournisseurs de cloud. Celle-ci est la plupart du temps possible, mais peu simple et peu mise en avant :
- Pour le stockage non structuré il y a un mécanisme chez Google qui permet de rapatrier le contenu de S3 à intervalles réguliers. Cette solution est entièrement gérée mais est unidirectionnelle, et n'est pas synchrone. Cela est adapté pour un déploiement actif / passif avec AWS en zone principale et GCP en secondaire.
- Pour le stockage structuré, nous pouvons utiliser AWS RDS et GCP SQL. Ces services gérés embarquent un moteur de base de données classique (MySQL, MariaDB, PostgreSQL), et il est possible d'activer la réplication entre les instances de chaque cloud. Néanmoins, ce type de déploiement est assez complexe à mettre en oeuvre et nécessite une finesse de configuration pour être complètement fiable, robuste, et Prod-Ready.
La réplication du stockage conditionnée par l'état du réseau
Peu importe la solution choisie il reste un élément fondamental à prendre en compte avant d'envisager un déploiement multi-cloud : les capacités du réseau.
Dans un déploiement classique, les noeuds de stockage à répliquer sont situés à proximité immédiate ou relative, donc le débit est important et surtout la latence est faible. En multi-cloud, les noeuds de stockage sont bien plus éloignés, que ce soit géographiquement (potentiellement sur des continents différents), et en matière de bonds réseaux (il peut y avoir plusieurs dizaines de routeurs entre les points d'entrée des datacenters).
Toutes les solutions de stockage ne réagissent pas de la même manière suivant la latence du cluster, et le débit maximal qui peut être atteint. De la même manière, il faut réfléchir attentivement à ces contraintes quand on conçoit son application.
En effet dans un système synchrone, notre écriture ne sera pas validée tant que les autres noeuds n'auront pas acquiescé, ce qui peut ralentir considérablement votre application si la latence est importante. De la même manière, si la quantité de données écrites est importante, alors il faudra être vigilant au débit maximal supporté.
Pour s'assurer de ce qui est possible, faisons quelques tests sur notre infra multi-cloud pour en déterminer la latence et le débit suivant les chemins empruntés.
Tests de latence multi-cloud
Pour tester la latence, nous pouvons utiliser simplement l'outil ping, mais également la fonctionnalité rtt de Consul. Cette fonctionnalité est présente via la CLI Consul mais aussi depuis l’interface graphique Consul UI (uniquement pour les noeuds LAN)
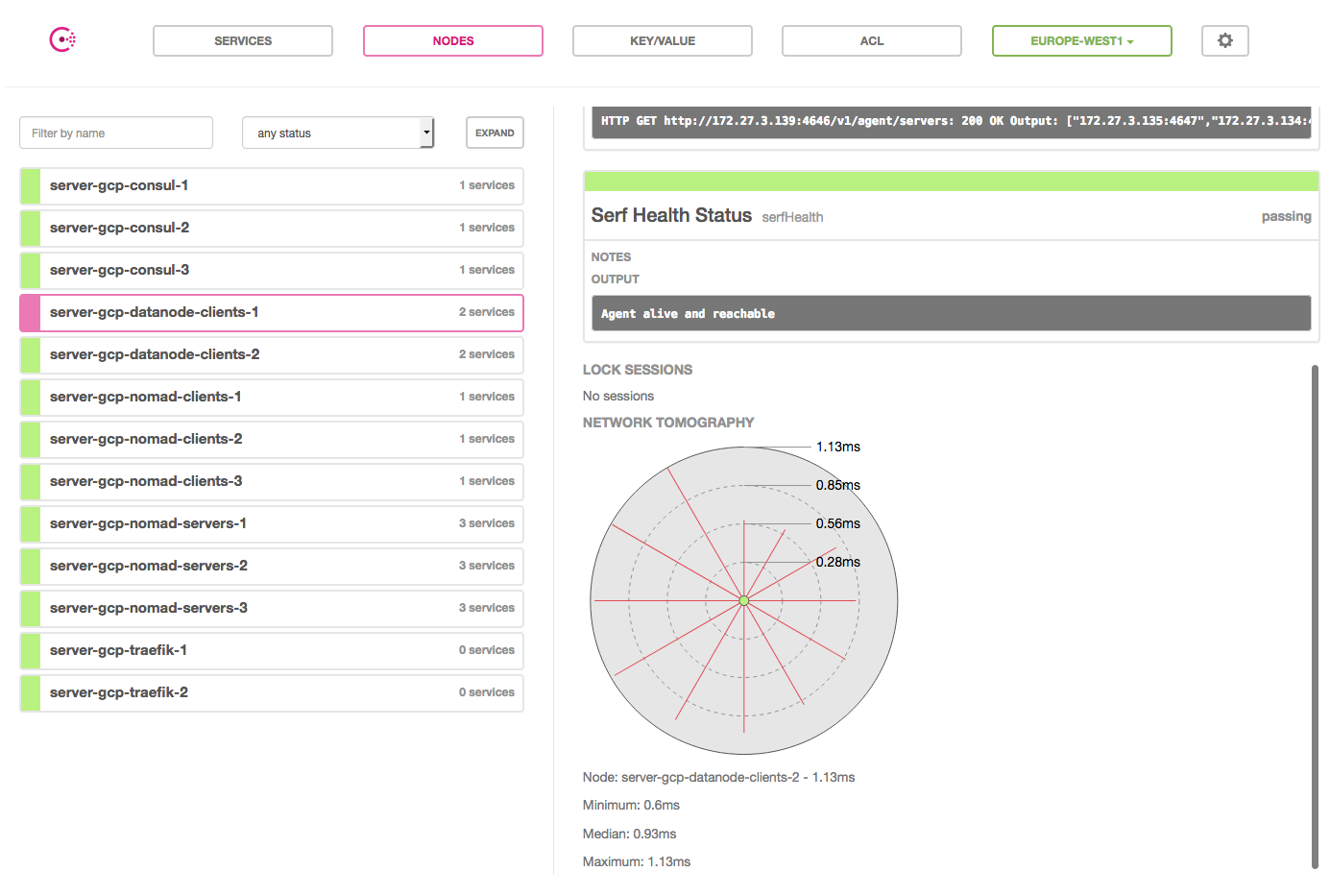
Latence entre deux noeuds de stockage dans le même cloud
Les métriques sont presque identiques au sein de chaque fournisseur de cloud.
GCP :
$ consul rtt server-gcp-datanode-clients-1 server-gcp-datanode-clients-2
Estimated server-gcp-datanode-clients-1 <-> server-gcp-datanode-clients-2 rtt: 1.388 ms (using LAN coordinates)
AWS :
$ consul rtt ip-172-30-3-132 ip-172-30-3-180
Estimated ip-172-30-3-132 <-> ip-172-30-3-180 rtt: 1.390 ms (using LAN coordinates)
On peut observer que la latence est très faible, quel que soit le cloud même en étant distribué sur plusieurs zones de disponibilité. Chez AWS et GCP la latence inter-noeuds est de moins 1,5 millisecondes.
Latence entre deux clouds via un VPN
Entre les serveurs Consul distants :
consul rtt -wan server-gcp-consul-1.europe-west1 ip-172-30-3-152.us-west-2
Estimated server-gcp-consul-1.europe-west1 <-> ip-172-30-3-152.us-west-2 rtt: 163.524 ms (using WAN coordinates)
Entre deux serveurs de stockage distants :
PING 172.30.3.132 (172.30.3.132) 56(84) bytes of data.
64 bytes from 172.30.3.132: icmp_seq=1 ttl=64 time=163 ms
64 bytes from 172.30.3.132: icmp_seq=2 ttl=64 time=162 ms
64 bytes from 172.30.3.132: icmp_seq=3 ttl=64 time=162 ms
--- 172.30.3.132 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 162.720/163.108/163.716/0.435 ms
On peut observer que la latence augmente de manière importante car elle est multipliée par 100 pour atteindre en moyenne 163 millisecondes. Même si au niveau routage un seul saut nous sépare entre les deux infras, nous ressentons les effets de la traversée de l'océan atlantique !
Latence entre deux clouds via Internet
Entre les serveurs Bastion distants :
PING 35.195.185.134 (35.195.185.134) 56(84) bytes of data.
64 bytes from 35.195.185.134: icmp_seq=1 ttl=45 time=165 ms
64 bytes from 35.195.185.134: icmp_seq=2 ttl=45 time=164 ms
64 bytes from 35.195.185.134: icmp_seq=3 ttl=45 time=164 ms
^C
--- 35.195.185.134 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 164.550/164.849/165.376/0.599 ms
La latence est assez proche de celle via le VPN, elle augmente tout de même de quelques millisecondes pour atteindre le 165 millisecondes de moyenne.
Que ce soit via le VPN ou via Internet directement, nous empruntons quasiment la même route, et donc la latence est presque identique. Pour l'abaisser il faudrait rapprocher nos fournisseurs de cloud en choisissant deux régions proches, voir en utilisant les technologies de DirectConnect (AWS) / Interconnect (GCP) afin de se brancher sur le backbone réseau directement. Néanmoins, ces options ont un coût important et ne sont pas toujours justifiées.
Tests de débit multi-cloud
Pour tester le débit, nous allons utiliser l'outil iperf. Tous les tests ont été faits de manière bidirectionnelle, un flux après l'autre. Ainsi, chaque ligne représente une connexion unique.
Débit entre deux noeuds de stockage dans le même cloud
Ce test est fait entre les deux noeuds de stockage sur GCP, les débits sont également très élevés chez AWS et permettent des réplications efficaces et rapides.
iperf -c 172.27.3.139 -p 40005 -r -t 30
------------------------------------------------------------
Server listening on TCP port 40005
TCP window size: 85.3 KByte (default)
------------------------------------------------------------
------------------------------------------------------------
Client connecting to 172.27.3.139, TCP port 40005
TCP window size: 999 KByte (default)
------------------------------------------------------------
[ 4] local 172.27.3.140 port 53084 connected with 172.27.3.139 port 40005
[ ID] Interval Transfer Bandwidth
[ 4] 0.0-30.0 sec 3.42 GBytes 979 Mbits/sec
[ 4] local 172.27.3.140 port 40005 connected with 172.27.3.139 port 36514
[ 4] 0.0-30.0 sec 3.41 GBytes 976 Mbits/sec
Il est logique d'atteindre ces performances car nous utilisons un réseau entièrement sous le contrôle de notre fournisseur de cloud.
Débit entre deux noeuds de stockage via VPN
Chacun des noeuds de stockage est situé sur un cloud différent. Ce test permet d’être représentatif du débit maximal qui pourra être utilisé par notre cluster de stockage multi-cloud.
iperf -c 172.27.3.139 -p 40005 -r -t 30
------------------------------------------------------------
Server listening on TCP port 40005
TCP window size: 85.3 KByte (default)
------------------------------------------------------------
------------------------------------------------------------
Client connecting to 172.27.3.139, TCP port 40005
TCP window size: 45.0 KByte (default)
------------------------------------------------------------
[ 4] local 172.30.3.132 port 56408 connected with 172.27.3.139 port 40005
[ ID] Interval Transfer Bandwidth
[ 4] 0.0-30.3 sec 130 MBytes 35.9 Mbits/sec
[ 4] local 172.30.3.132 port 40005 connected with 172.27.3.139 port 56572
[ 4] 0.0-31.3 sec 129 MBytes 34.5 Mbits/sec
Le débit est nettement inférieur à ce qu'on peut trouver en restant limité à une seule région d'un seul cloud. On peut déduire que le VPN agit comme un goulot d'étranglement en limitant le débit qui lui est envoyé.
Débit entre deux Bastions via Internet
Chaque Bastion est sur un cloud différent, ce test met en évidence le débit maximal atteignable en passant hors du VPN.
iperf -c 35.195.185.134 -p 80 -r -t 30
------------------------------------------------------------
Server listening on TCP port 80
TCP window size: 85.3 KByte (default)
------------------------------------------------------------
------------------------------------------------------------
Client connecting to 35.195.185.134, TCP port 80
TCP window size: 45.0 KByte (default)
------------------------------------------------------------
[ 3] local 172.30.3.4 port 46596 connected with 35.195.185.134 port 80
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-30.0 sec 388 MBytes 108 Mbits/sec
[ 3] local 172.30.3.4 port 80 connected with 35.195.185.134 port 35696
[ 3] 0.0-30.3 sec 213 MBytes 58.9 Mbits/sec
Sur le test, le premier flux est dans le sens AWS vers GCP, et le second est l'inverse. On note un élément intéressant, le débit entrant sur Google est deux fois plus élevé que celui entrant sur AWS. La raison de cette différence de débit peut s’expliquer par le passage par Internet et par des différences de charge sur les différents datacenters.
On observe également que, quoiqu'il arrive, le débit est au moins doublé, si ce n'est triplé par rapport à la connexion VPN. Néanmoins, il faut garder à l'esprit que répliquer des données est une opération sensible, et que la faire transiter par internet n'est pas la première option à considérer.
Déploiement des noeuds de données
Maintenant que nous avons une idée assez précise des capacités réseau, nous pouvons choisir la solution de stockage que nous allons déployer. Bien entendu cela dépend toujours de ce qui est demandé pour l'application, et pour notre test nous avons retenu Minio.
Minio est une solution offrant du stockage de type objet non structuré répliquée en synchrone. Lorsque Minio dispose de suffisamment de disques de stockage il active automatiquement la réplication avec support du Erasure Coding. Chaque écriture ne sera acquiescée que lorsque l'algorithme aura été exécuté sur un nombre suffisant de disques.
Minio a également l'avantage de supporter la perte N/2 disques pour la lecture des données et N/2+1 pour l'écriture. Cela est intéressant pour nous car nous pouvons perdre un fournisseur de cloud entier et continuer à pouvoir lire les données.
Son API est compatible AWS S3, ce qui signifie que la plupart des outils communiquant avec S3 peuvent être reconfigurés pour discuter avec Minio.
Enfin, un dernier point particulièrement intéressant est lié à la latence supportée : le cluster Minio supporte jusqu'a 3 secondes entre chaque noeud ! Comme nous sommes dans un contexte de Géo-réplication et que nous avons vu que la latence montait à 160 millisecondes, c'est un aspect à ne pas négliger.
Création des serveurs de stockage
Lors des précédentes étapes, nous avons instancié un cluster Nomad pour gérer nos applications, nous allons l'utiliser pour déployer notre solution de stockage.
Il aurait été possible d'utiliser les serveurs existants, néanmoins nous allons en ajouter des nouveaux et les lier à une classe spécifique étiquetée data. Par ailleurs, nous allons configurer Docker pour utiliser les volumes persistants de leur fournisseur de cloud (EBS chez AWS, et Disks chez GCP).
Le dépôt Github expose la configuration matérielle des machines virtuelles.
La configuration de chaque job Nomad est la suivante :
job "storage" {
region = "europe"
datacenters = ["europe-west1"]
[...]
group "object" {
count = 2
[...]
constraint {
attribute = "${node.class}"
value = "data"
}
task "minio" {
driver = "docker"
config {
image = "minio/minio:RELEASE.2017-08-05T00-00-53Z"
args = [
"server",
"http://minio-gcp-0.storage-object-minio.service.europe-west1.consul/data",
"http://minio-gcp-1.storage-object-minio.service.europe-west1.consul/data",
"http://minio-aws-0.storage-object-minio.service.us-west-2.consul/data",
"http://minio-aws-1.storage-object-minio.service.us-west-2.consul/data"
]
network_mode = "host"
port_map = {
minio = 9000
}
}
template {
data = <<EOH
MINIO_ACCESS_KEY="AKIAIOSFODNN7EXAMPLE"
MINIO_SECRET_KEY="wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"
EOH
destination = "secrets/file.env"
env = true
}
service {
port = "minio"
tags = [
"minio",
"minio-gcp-${NOMAD_ALLOC_INDEX}"
]
}
resources {
[...]
network {
port "minio" {
static = 9000
}
}
}
}
}
}
Déploiement du service Storage
Le job AWS est identique en tous points sauf sur les champs region et datacenters. Le même service est déployé, il s'agit du service storage. Nous utilisons le DNS Consul pour résoudre les adresses des services déployés.
Pour le déployer, il suffit de spécifier l'adresse de l'un des serveurs Nomad dans la CLI. Comme les deux régions Nomad communiquent, il est possible de soumettre les deux jobs au même serveur qui se chargera de transmettre celui qui ne le concerne pas à l'autre région :
$ export NOMAD_ADDR=http://${NOMAD_1_GCP_ADDR}:4646
$ nomad run minio-aws.nomad
$ nomad run minio-gcp.nomad
Si on regarde le status du déploiement, on observe assez vite que le service est actif et en status running:
$ nomad status storage
ID = storage
Name = storage
Submit Date = 10/09/17 08:36:50 UTC
Type = service
Priority = 50
Datacenters = europe-west1
Status = running
Periodic = false
Parameterized = false
Summary
Task Group Queued Starting Running Failed Complete Lost
object 0 0 2 0 0 0
Latest Deployment
ID = fd8cdf32
Status = successful
Description = Deployment completed successfully
Deployed
Task Group Desired Placed Healthy Unhealthy
object 2 2 2 0
Allocations
ID Node ID Task Group Version Desired Status Created At
a4c6e2f6 c87fbd05 object 0 run running 10/09/17 08:36:50 UTC
dd07ce45 b988319f object 0 run running 10/09/17 08:36:50 UTC
Par ailleurs, il est possible d'observer les logs de l'une des allocations pour s'assurer que le serveur Minio ait bien démarré.
$ nomad logs a4c6
Initializing data volume.
[01/04] http://minio-aws-0.storage-object-minio.service.us-west-2.consul:9000/data - 10 GiB online
[02/04] http://minio-aws-1.storage-object-minio.service.us-west-2.consul:9000/data - 10 GiB online
[03/04] http://minio-gcp-0.storage-object-minio.service.europe-west1.consul:9000/data - 10 GiB online
[04/04] http://minio-gcp-1.storage-object-minio.service.europe-west1.consul:9000/data - 10 GiB online
Endpoint: http://172.27.3.139:9000 http://172.17.0.1:9000 http://127.0.0.1:9000
AccessKey: AKIAIOSFODNN7EXAMPLE
SecretKey: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Browser Access:
http://172.27.3.139:9000 http://172.17.0.1:9000 http://127.0.0.1:9000
Command-line Access: https://docs.minio.io/docs/minio-client-quickstart-guide
$ mc config host add myminio http://172.27.3.139:9000 AKIAIOSFODNN7EXAMPLE wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Object API (Amazon S3 compatible):
Go: https://docs.minio.io/docs/golang-client-quickstart-guide
Java: https://docs.minio.io/docs/java-client-quickstart-guide
Python: https://docs.minio.io/docs/python-client-quickstart-guide
JavaScript: https://docs.minio.io/docs/javascript-client-quickstart-guide
.NET: https://docs.minio.io/docs/dotnet-client-quickstart-guide
Drive Capacity: 20 GiB Free, 20 GiB Total
Status: 4 Online, 0 Offline. We can withstand [2] drive failure(s).
Le serveur Minio nous répond qu'il a bien pu contacter les 4 noeuds de stockage, qu'un total de 40GB de volumétrie est exposée et que seule 20GB est utilisable. Le cluster tolère la perte de 2 disques grâce au mécanisme d'Erasure Coding.
Tests des accès Minio
Maintenant que notre cluster fonctionne, nous allons tester les écritures et lectures. Le plus simple est d'utiliser l'utilitaire en ligne de commande fourni par Minio. Mais une interface graphique existe, pour cela il suffit de se connecter via un navigateur web sur le port exposé (9000 en l'occurrence) sur n’importe quel noeud de stockage :
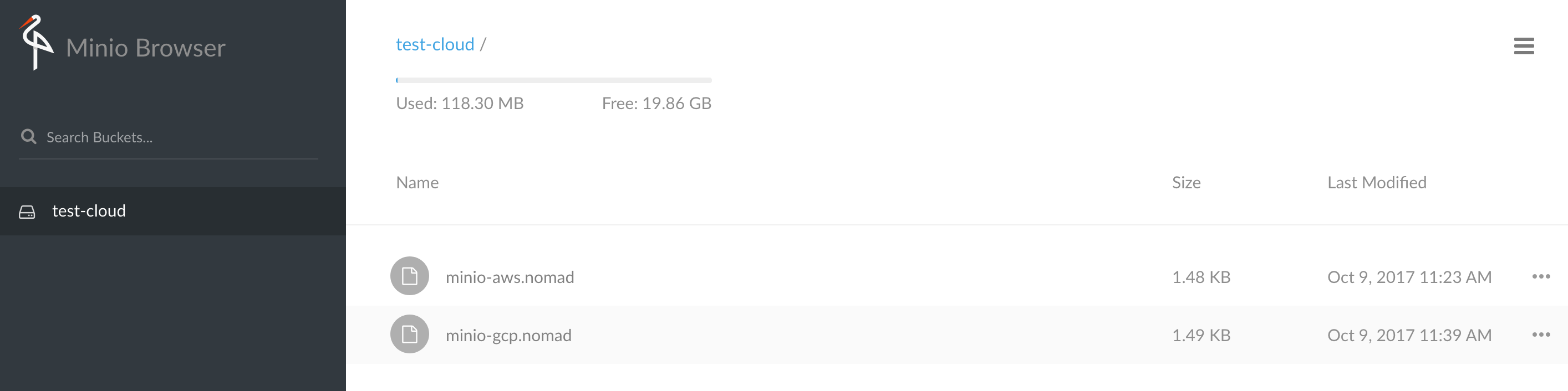
Pour les besoins du test, si vous êtes toujours connectés à l'un des serveurs Nomad, vous pouvez télécharger l'utilitaire mc (ci-après Linux x86_64):
wget https://dl.minio.io/client/mc/release/linux-amd64/mc
Et configurons le point d'entrée myminio avec les Access Key / Secret Key que nous avons préalablement définis. Vous noterez qu'en point d'entrée j'utilise l'IP d'une des instances Minio, il est néanmoins possible de s'adresser à n'importe laquelle sans problème. J'aurais pu utiliser le nom du service http://storage-object-minio.service.consul :
$ mc config host add myminio http://172.27.3.139:9000 AKIAIOSFODNN7EXAMPLE wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Added `myminio` successfully.
$ mc mb myminio/test-cloud
Bucket created successfully `myminio/test-cloud`.
$ mc cp *.nomad myminio/test-cloud/
minio-gcp.nomad: 2.97 KB / 2.97 KB ┃▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓┃ 100.00% 747 B/s 4s
$ mc ls myminio/test-cloud
[2017-10-09 09:23:46 UTC] 1.5KiB minio-aws.nomad
[2017-10-09 09:23:48 UTC] 1.5KiB minio-gcp.nomad
Après la connexion, j'ai créé un bucket test-cloud, puis j'ai copié les fichiers de définition des jobs Nomad. J'aurais pu utiliser n'importe quel fichier, mais puisqu'ils étaient présents, autant s'en servir !
Test de perte d'un Cloud
Pour compléter notre test, simulons la perte d'un Cloud entier et voyons comment se comporte notre cluster de stockage. Pour cela il s'agit simplement d'arrêter le job storage sur le cluster Nomad côté GCP :
$ nomad stop storage
==> Monitoring evaluation "5a1320cd"
Evaluation triggered by job "storage"
Evaluation within deployment: "fd8cdf32"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "5a1320cd" finished with status "complete"
Tant qu'aucune écriture n'est requise, la perte des disques ne sera pas détectée. Justement, connectons-nous au côté AWS et interrogeons le cluster à l'aide de mc :
$ mc ls myminio/test-cloud
[2017-10-09 09:23:46 UTC] 1.5KiB minio-aws.nomad
[2017-10-09 09:23:48 UTC] 1.5KiB minio-gcp.nomad
$ mc cat myminio/test-cloud/minio-gcp.nomad
job "storage" {
region = "europe"
datacenters = ["europe-west1"]
[...]
$ mc cp myminio/test-cloud/minio-gcp.nomad .
...ud/minio-gcp.nomad: 1.49 KB / 1.49 KB ┃▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓┃ 100.00% 1.68 KB/s 0s
On constate qu'on peut sans problème lister le contenu du bucket, lire le contenu d'un fichier, et même faire une copie de Minio vers notre stockage local. Ceci est normal car il s'agit d'opérations de lecture, et celles-ci sont possibles tant que l'on possède N/2 disques toujours disponibles.
Maintenant, testons la modification d'un de nos fichiers, puis l'envoi sur le cluster :
$ vi minio-gcp.nomad
$ mc cp minio-gcp.nomad myminio/test-cloud/minio-gcp.nomad
0 B / 1.49 KB ┃░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░┃ 0.00%
mc: <ERROR> Failed to copy `minio-gcp.nomad`. Multiple disks failures, unable to write data.
La tâche reste en suspend, puis au bout de quelques instants elle va sortir en erreur en indiquant clairement qu'il y a de multiples pertes de disques, ce qui interdit l'écriture sur le cluster. En effet, l'écriture nécessite N/2+1 disques, ceci afin de garantir la cohérence des données.
Si nous rallumons le service côté GCP, après un moment on s'aperçoit que même si le cluster est de nouveau réactivé, les données ne sont pas complètes. Minio ne s'autorépare pas, la mécanique de réplication est faite au moment de l'écriture des données, donc si l'on souhaite restaurer l'état du cluster il faut indiquer explicitement à Minio de s'autoréparer à l'aide de la commande heal.
La réparation peut mettre un peu de temps, les données vont réapparaître au fur et à mesure. Par exemple, les commandes ci-après sont passées sur l'un noeud de stockage côté GCP :
$ mc admin heal myminio
$ mc ls myminio/test-cloud
[2017-10-09 09:39:44 UTC] 1.5KiB minio-gcp.nomad
[...After a little...]
$ mc ls myminio/test-cloud
[2017-10-09 09:23:46 UTC] 1.5KiB minio-aws.nomad
[2017-10-09 09:39:44 UTC] 1.5KiB minio-gcp.nomad
$ mc cp minio-gcp.nomad myminio/test-cloud/minio-gcp.nomad
minio-gcp.nomad: 1.49 KB / 1.49 KB ┃▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓┃ 100.00% 699 B/s 2s
Enfin, après les opérations de restauration nous pouvons mettre à jour notre fichier modifié et le cluster autorise les écritures.
Conclusion
Après avoir étudié les problématiques réseau liées à la réplication, nous avons créé notre service de stockage sur nos deux fournisseurs de cloud et nous allons bientôt pouvoir terminer notre série en déployant effectivement une application sur notre infra multi-cloud.
Si tester le déploiement vous intéresse, le code utilisé est disponible sur https://github.com/bcadiot/multi-cloud.
Rendez-vous très bientôt pour le dernier article !



