 Henri Gomez
Henri Gomez



Supply Chain Attack : Proxies, gestionnaires d’artefacts et cartographie
Nous avons vu précédemment que l’usine logicielle devait être isolée des autres environnements comme ceux de développement ou de production.

Dans les articles précédents, nous avons vu comment protéger l’usine logicielle de contenus malicieux provenant de l’extérieur.
Il est temps de regarder comment produire des contenus de confiance.
Commençons par définir les critères de confiance :
Il est difficile de faire confiance à des processus opaques et non compris. Il est donc capital d’expliquer la chaîne de fabrication aux utilisateurs, à commencer par les développeurs.
La confiance passe par la compréhension des règles de vie, il ne faut donc pas passer à côté d’une formation minimale des utilisateurs..
Nous pouvons commencer par présenter les services présents dans l’usine. Des outils standards comme Jenkins, GitLab, GitHub, Artifactory, Nexus, SonarQube ou Trivy sont largement connus et reconnus, vous pourrez faire un focus sur les règles et processus.
Prenons 2 exemples courants, la gestion des vulnérabilités et les montées de versions des dépendances.
Pour chaque règle, une documentation décrit le processus et l’outillage qui participe au processus, par exemple Trivy sur les vulnérabilités et Renovate sur les montées de versions.
Des règles et processus simples et partagés sont des éléments clés pour comprendre le processus de fabrication et les interventions à prévoir.
Depuis plusieurs années, les étapes de construction d’un livrable, appelées Pipelines, se font via des fichiers qui sont déployés au sein même du projet.
Ces fichiers de construction sont ensuite interprétés et exécutés par les moteurs de CI/CD greffés au projet, comme Jenkins ou CircleCI, ou directement même directement dans le gestionnaire de source, comme GitLab, GitHub Actions, Forgejo ou Woodpecker CI pour ne citer que ceux là,
Prenons l’exemple des images Docker produites par Quarkus
Nous avons le détail de l’ensemble des étapes et le contexte technique, tout est là visible, en totale transparence. Comme tout fichier d’un projet, tout changement est visible, potentiellement sous approbation via la mécanique des Pull/Merge Requests. Nous pouvons discuter des impacts avant même que cela soit utilisé.
Cette transparence est capitale pour la compréhension du processus de fabrication, une clé de plus pour la confiance.
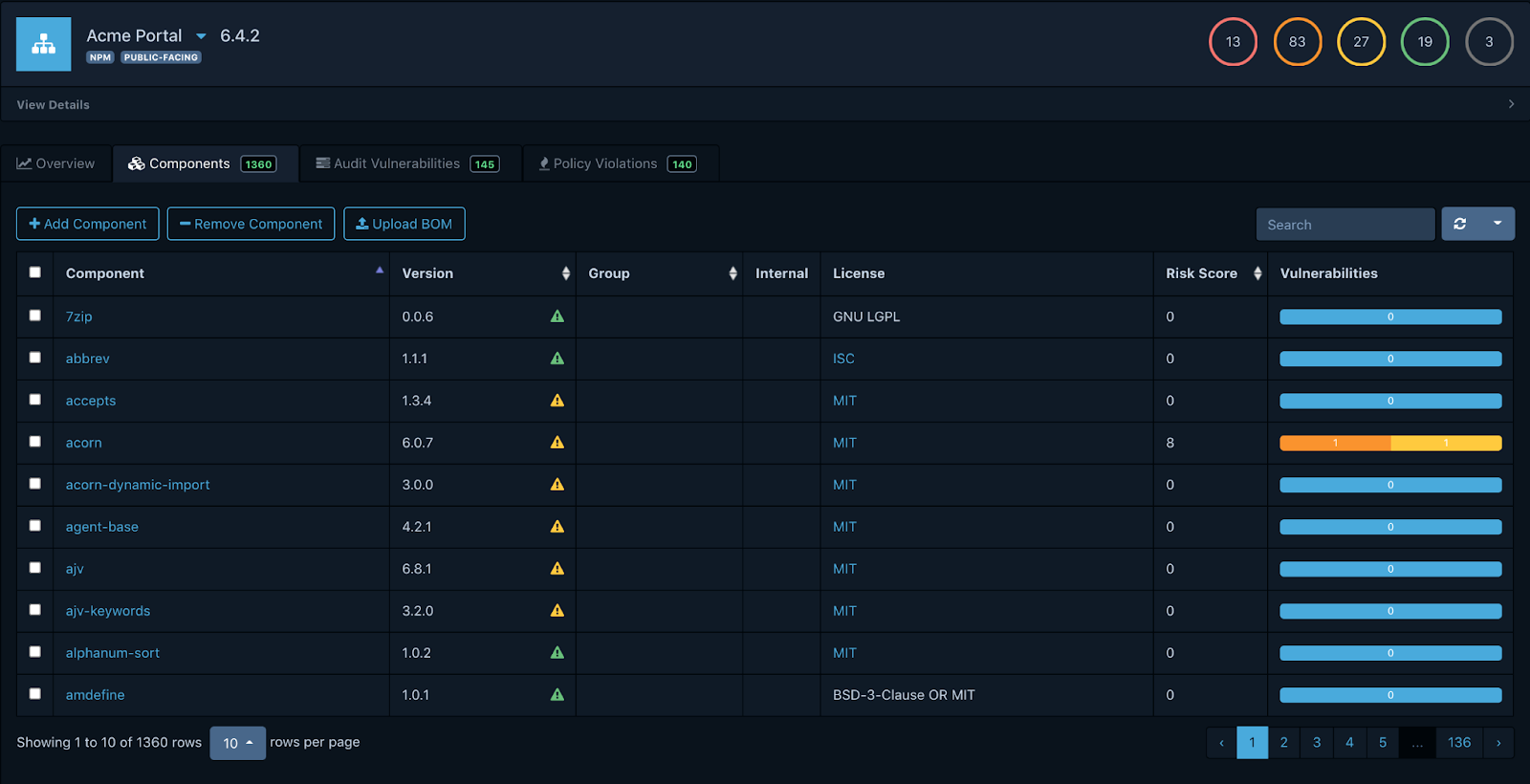
Qui dit contenu, dit livrables, mais aussi des composants qu’ils embarquent, souvent appelés artefacts. Il est capital de savoir de quoi est composé un livrable et pourquoi tel ou tel composant a été embarqué.
Ceci permet d’avoir une trace d’audit qui va de la demande initiale jusqu’au déploiement en passant par toutes les étapes de développements et livraisons.
Nous devons pouvoir à tout moment aller d’une version des sources aux artefacts produits et réciproquement.
Pendant longtemps, nous faisions une relation stricte entre le numéro de version du source et de l’artefact, ce n’est plus le cas depuis l’avènement du Continuous Delivery où nous trouverons souvent en plus un index de construction.
Quelle que soit la mécanique retenue, il est capital de garder trace de cette relation sur le long terme, tant que le binaire est en production en interne ou chez ses clients.
Cette réversibilité est indispensable pour être à même de faire des analyses sur des problèmes de performances, des bugs ou des levées de doute de vulnérabilités.
Pour aller plus loin, nous pouvons même lier la version de l’artefact ou du produit au workflow de version, par exemple, Jira, pour avoir un scope complet et réversible, qui va de la demande à l’implémentation.
Cette liaison peut se faire simplement, lors d’un Merge/Pull Request, en mettant en commentaire la référence du ticket. L’opération Merge/Pull Request portant l’ensemble des informations sur la prise de décision de livraison, les acteurs et leurs échanges, nous aurons tout le matériel nécessaire pour des investigations précises à posteriori.
Un produit se composant de nombreux artefacts, ceux produits en interne et les dépendances externes, souvent Open Source. Il faut avoir un inventaire précis de ce qui a été livré dans un produit final, que ce soit une application que nous allons opérer ou un logiciel que nous vendons à des clients.
En Mai 2021, l’Executive Order de la Maison Blanche a mis le focus sur une fonctionnalité qui était trop peu utilisée et qui est amenée à devenir obligatoire, la Nomenclature du Logiciel plus connue sous son nom anglais Software Bill Of Materials (SBOM).
Les éditeurs doivent être en mesure de fournir la liste de l’ensemble des artefacts présents dans les logiciels produits.
Il est plus que recommandé d’introduire la production de ce SBOM dans les processus de livraison, de nombreuses solutions existent pour la majorité des langages et notamment CycloneDX, l’offre Open Source de l’OWASP (Open Web Application Security Project), acteur majeur dans la sécurité du Web.
CycloneDX propose des modules qui produiront l’inventaire pour la plupart des technologies de développement, et notamment Java (Maven/Gradle), Node, Golang, Rust, Python, .Net.
Les acteurs traditionnels des usines logicielles fournissent une production SBOM, JFrog avec XRay Security ou Sonatype avec Nexus.
Les inventaires de vos produits, majoritairement des dépendances, peuvent être stockés dans un gestionnaire comme Dependency Track qui vous donnera une vision précise et temporelle, de ce que vous consommez et permettra donc d’identifier rapidement quelles versions de vos produits embarquent telle ou telle vulnérabilité.
Avec l’adoption progressive du support SBOM par les éditeurs, vous pourrez en plus avoir la même finesse d’information pour les produits tiers.
Outre le contenu, il faut savoir qui l’a produit, avec la granularité la plus fine possible, permettant ainsi d’identifier rapidement et sans ambiguïté la personne ou l’équipe qui sera à même de donner toutes les informations sur le contenu.
Il existe différentes techniques pour faciliter l’identification des sources, en voici quelques unes possibles et cumulables
Avec cette ségrégation de la production logicielle, par dépôt et/ou signature, il est facile d’identifier qui a produit quoi, permettant de bloquer plus simplement la diffusion de tout ou partie de contenus suspects.
Depuis longtemps, nous utilisons des mécaniques de chiffrement et signatures, utilisant GPG/PGP et notamment dans l'Open Source.
Ceci permet de s’assurer que le contenu n’a pas été altéré entre la production et votre consommation. C’est même un mécanisme natif dans les systèmes de packaging Linux comme DEB/RPM.
Ce mécanisme GPG/PGP utilise une clé qui correspond à une organisation, un éditeur ou une communauté typiquement et fonctionne bien dans une approche où nous faisons totalement confiance dans l’organisation productrice.
Au sein de votre entreprise, vous devrez peut-être aller plus loin et utiliser des clés qui correspondent à un développeur ou une équipe. Dans ce cas, il faut utiliser d’autres solutions, plus souple, pour notamment gérer la révocation de certificats, lors des départs d’équipiers ou en cas de doute sur la production de contenus.
Des solutions comme Sigstore permettent de traiter ces problématiques, avec un contrôle précis de la production jusqu’à l’utilisation.
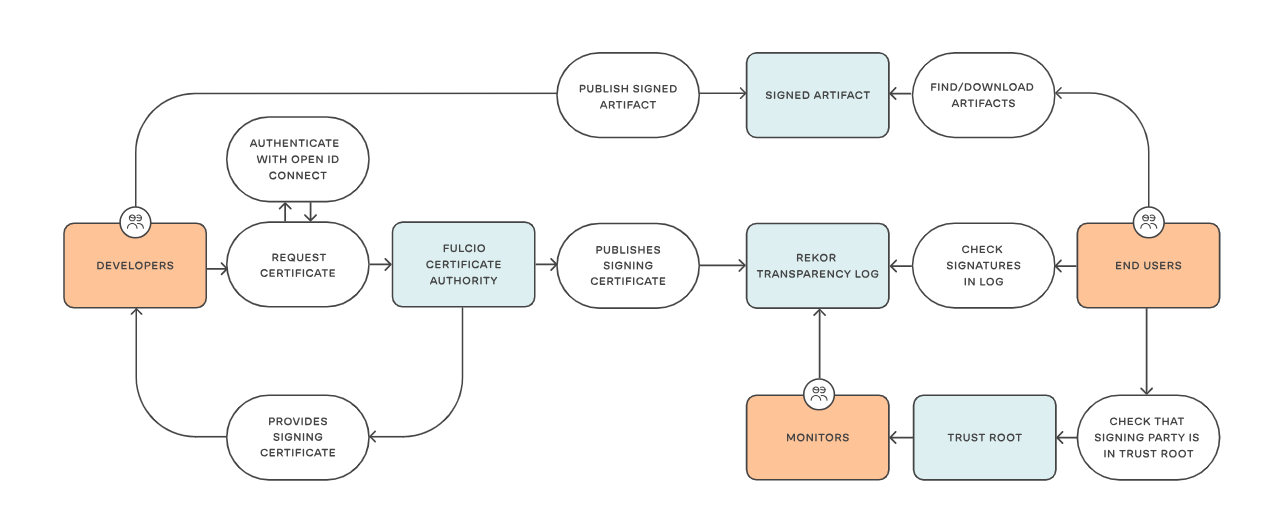
Il est important de pouvoir rapidement isoler des contenus douteux et notamment s’assurer qu’ils ne peuvent plus être utilisés en développement ou production.
Les gestionnaires d’artefacts modernes peuvent être complétés par des systèmes de contrôle de contenus comme Artifactory Curation et Nexus Firewall qui utilisent des bases de vulnérabilités permettant de bloquer sur demande ou automatiquement la diffusion des artefacts douteux.
Dès lors, ces contenus identifiés comme dangereux ne sont plus utilisables dans les développements et la remédiation, souvent la montée de version, devient obligatoire dans le cycle de développement.
Il faut être en capacité d’interdire ou détecter des processus non autorisés sur l’environnement de l’usine logicielle, afin de s’assurer que la production de livrables se fasse avec des outils connus et sous contrôle.
Si vous êtes en environnement Kubernetes, des contrôleurs d'admission comme Kyverno ou Open Policy Agent peuvent être utilisés en place pour interdire l’utilisation de contenus non conformes, défaut de signature ou signature non reconnue.
En environnement traditionnel, bare metal ou VM, il faudra utiliser les mécaniques de l’OS, en systématisant l’utilisation de packages natifs (DEB/RPM) signés par des éditeurs ou par votre propre chaîne de fabrication.
Il est possible d’utiliser des outils comme Falco, qui utilisant la technologie eBPF peuvent détecter le démarrage de processus n’utilisant les binaires autorisés, sur un scope large, bare metal, VM ou containers.
Les Pipeline CI peuvent évoluer très vite, en fonction des technologies employées, contraintes métiers ou réglementaires.
Pendant longtemps la gestion des Pipeline était dans le scope unique des équipes CI, cette responsabilité est maintenant partagée avec les développeurs pour des questions d’agilité.
Une Pipeline manipulant le contenu de vos livrables, il faut donc s’assurer que certaines règles soient respectées, comme l’utilisation d’images de confiance.
Dans certains contextes critiques, nous devrons démontrer d’un suivi de conformité des Pipelines CI aux règles d’entreprise. C’est une activité qui peut vite devenir chronophage avec le nombre de projets et Pipeline. Certains outils comme R2Devops permettent d’automatiser une partie de la charge.
Avec des outils simples, il est possible de protéger efficacement et simplement son usine logicielle des contenus dangereux.
Dès lors que les contenus sources et artefacts ne sont plus consommés directement depuis Internet mais passent via des proxy et gestionnaire d’artefacts, nous auront la possibilité de faire des analyses, interdire les contenus à risque et avertir sur des contenus nouvellement à risque.
Ne pas oublier une cartographie complète de l’ensemble de vos composants logiciels tiers, nous ne pouvons que suggérer d'introduire la fourniture de SBOM dans vos processus CI/CD.

Nous avons vu précédemment que l’usine logicielle devait être isolée des autres environnements comme ceux de développement ou de production.

La mesure de la consommation énergétique des applications est un sujet d’actualité, d’une part pour en prendre conscience et d’autre part pour...

La sécurité, le stockage et le contrôle des secrets s’imposent aux DSI qui doivent être sur tous les fronts ! Sécuriser les applications et services,...