 Sébastien Lavayssière
Sébastien Lavayssière
Le Service Registry illustré par Consul
Qu’est ce que c’est ? Consul est un “service registry” ainsi qu’un stockage de dictionnaire (key/value) qui permet de mettre en place un service de...
Mettre en oeuvre une infrastructure scalable, résiliente et tout automatisée est devenu depuis quelques années le Graal de l’informatique moderne. Mais si la quête du Graal n'est pas une sinécure, cette infrastructure est maintenant très simple à mettre en place.
Dans un précédent article je vous ai parlé de Service Registry, qui permet de maintenir à jour la liste de vos services/microservices au fil des déploiements.
J'ai pour objectif d'arriver à implémenter le schéma suivant:
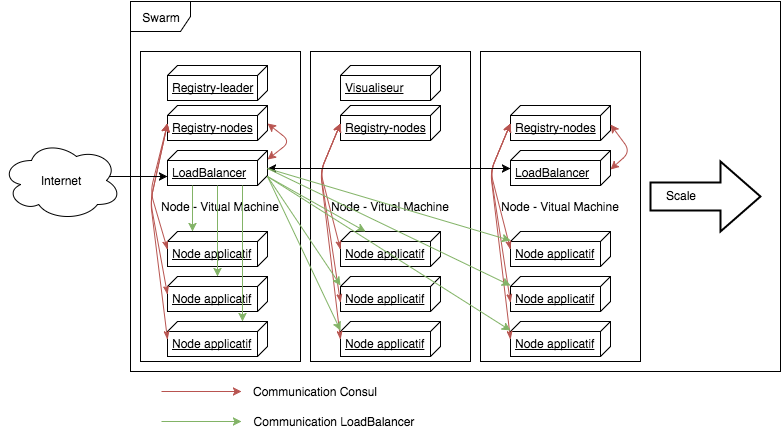
J’ai voulu mettre en place un système “simple” : un service web composé d’un ou plusieurs microservices qui puisse être disponible à l’extérieur du système, via internet par exemple.
J’ai donc besoin:
J’ai choisi Swarm, parce qu’il est facile à configurer sur mon poste et que je voulais essayer de pousser ses possibilités.
La première étape est de mettre en place 3 machines pour un “manager” et deux “workers”.
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox \
leader1
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox \
worker1
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox \
worker2
Ensuite on initialise le cluster Swarm :
ip_leader1=$(docker-machine ip leader1)
eval "$(docker-machine env leader1)"
docker swarm init \
--listen-addr $ip_leader1 \
--advertise-addr $ip_leader1
token=$(docker swarm join-token worker -q)
eval "$(docker-machine env worker1)"
docker swarm join \
--token $token \
$ip_leader1:2377
eval "$(docker-machine env worker2)"
docker swarm join \
--token $token \
$ip_leader1:2377
Je vais ensuite créer un réseau pour associer toutes mes instances dedans.
eval "$(docker-machine env leader1)"
docker network create \
-d overlay --subnet 10.1.9.0/24 \
multi-host-net
J’ajoute un service Docker qui me permet de visualiser mon cluster.
eval "$(docker-machine env leader1)"
docker service create \
--name=viz \
--publish=5050:8080/tcp \
--constraint=node.role==manager \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
manomarks/visualizer
J’utilise à nouveau Consul, mais j’ai adapté ma manière de le mettre en place aux outils Swarm.
docker service create --replicas 1 \
--name consul-leader \
--publish 8501:8500 \
--network multi-host-net \
--constraint=node.hostname=='leader1' \
progrium/consul -server -bootstrap-expect 1 -ui-dir /ui
Je crée un service Swarm, avec la contrainte qu’il ne doit s’exécuter que sur ma machine “leader1”, de manière à garantir son unicité. Mais pourquoi me direz-vous ? Pour que le container ait accès au réseau “multi-host-net”.
docker service create \
--name consul-nodes \
--publish 8500:8500 \
--network multi-host-net \
--mode global \
progrium/consul -server -join $ip_consul_leader -ui-dir /ui
Un deuxième service permet de créer le cluster. Il est sur le même réseau et est créé en mode “global”, qui est un mode Swarm qui permet d’avoir une instance de Consul par node.
À chaque action de scalabilité de mon Swarm, si j’ajoute un nœud, j’aurais automatiquement un Consul sur ce nœud. Très pratique pour m’assurer du bon nombre de serveurs Consul par rapport à mon nombre de nœuds Swarm.
J’ai utilisé Spring Cloud pour créer mon application.
Dans ma configuration je rends possible la configuration de mon backend Consul via une variable d’environnement “CONSUL_HOST” :
spring:
profiles: default
application:
name: democonsul
cloud:
inetutils:
preferred-networks:
- ${NETWORK}
consul:
host: ${CONSUL_HOST}
port: 8500
discovery:
preferIpAddress: true
healthCheckPath: /health
healthCheckInterval: 15s
tags: foo=bar, baz
instanceId: ${spring.application.name}:instance_${random.value}
La variable “NETWORK” permet de définir l’interface réseau de l’IP que Spring Boot envoie à Consul. Sans cet élément j’avais régulièrement un problème lié à l’envoi d’une IP avec laquelle Consul ne pouvait pas joindre le client. Le client était donc bien enregistré, mais en erreur.
À noter également un profil “test” dans le fichier de configuration, je vous invite à regarder le github en annexe, qui me permet de désactiver la connexion à Consul lors des tests unitaires.
Cette application va renvoyer un “Hello world” avec le nom de son instance dans Consul. Par exemple:
“Hello Docker World on democonsul:instance_a13954caee7c5769296b593806b7de73”.
Pour la répartition de charge, mon choix s’est porté sur Traefik qui a l’avantage de fournir un load balancer/reverse proxy capable de se connecter à Consul et à Swarm manager.
La connexion à Consul est double en réalité. Elle permet d'une part de récupérer les services dont la charge doit être répartie mais également de gérer la clusterisation de Traefik.
La première chose à créer est un fichier “toml” de configuration de Traefik.
defaultEntryPoints = ["http"]
[entryPoints]
[entryPoints.http]
address = ":80"
[consul]
watch = true
prefix = "traefik"
[consulCatalog]
domain = "localhost"
prefix = "traefik-consul"
[web]
address = ":8080"
Le bloc “consul” permet de gérer les configurations de Traefik en tant que stockage clef/valeur alors que le bloc “consulCatalog” indique la configuration des services à récupérer.
Ensuite on peut lancer notre service Traefik.
docker service create \
--name traefik \
--constraint=node.role==manager \
--publish 80:80 \
--publish 8080:8080 \
--mount type=bind,source=$PWD/traefik.toml,target=/etc/traefik/traefik.toml \
--network multi-host-net \
--mode global \
traefik \
--consulCatalog.endpoint=consul-nodes.multi-host-net:8500 \
--consul.endpoint=consul-nodes.multi-host-net:8500 \
--web
La configuration permet:
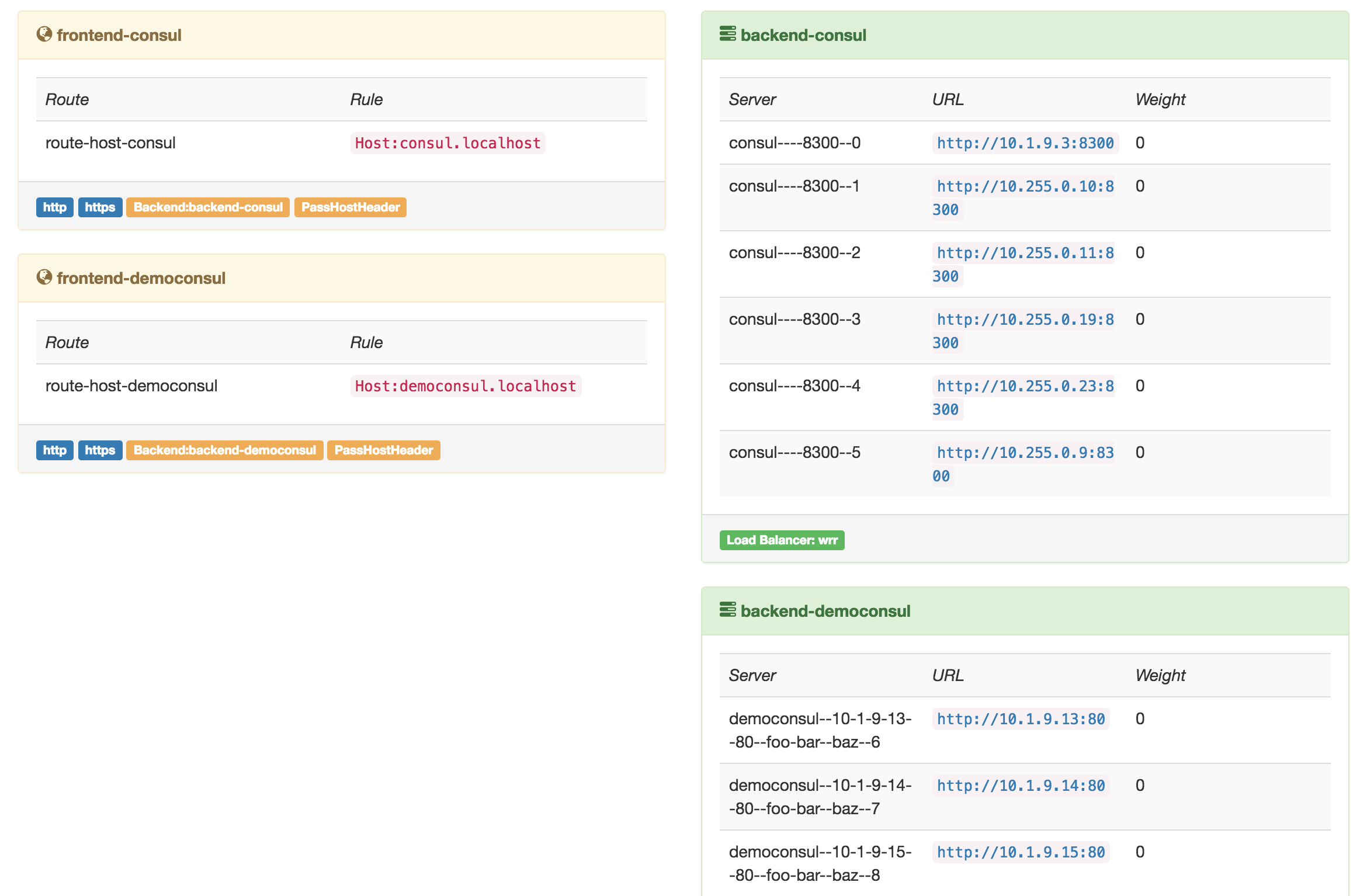
Mon service est fonctionnel :
curl -H Host:democonsul.localhost http://192.168.99.100
“Hello Docker World on democonsul:instance_a13954caee7c5769296b593806b7de73”
Commençons par tester la scalabilité, pour cela j’ajoute deux nœuds Swarm, un manager et un worker.
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox \
leader2
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox \
worker3
eval "$(docker-machine env leader1)"
token_leader=$(docker swarm join-token manager -q)
token=$(docker swarm join-token worker -q)
eval "$(docker-machine env worker3)"
docker swarm join \
--token $token \
$ip_leader1:2377
eval "$(docker-machine env leader2)"
docker swarm join \
--token $token_leader \
$ip_leader1:2377
Ce que je constate c’est l’instanciation de “traefik” et de “consul-nodes” automatiquement grâce au mode “global”.
L’augmentation des instances applicatives sera donc bien liée à l’augmentation du nombre de nœuds Swarm, qui induira l’augmentation des clusters de Load balancers et de Service Registry permettant la HA et la résilience de mes applications.
Je vais maintenant scaler manuellement mon application :
docker service scale web=10

Parfait !
Je vais maintenant tenter de supprimer des éléments de mon cluster.
docker-machine rm worker3 --force
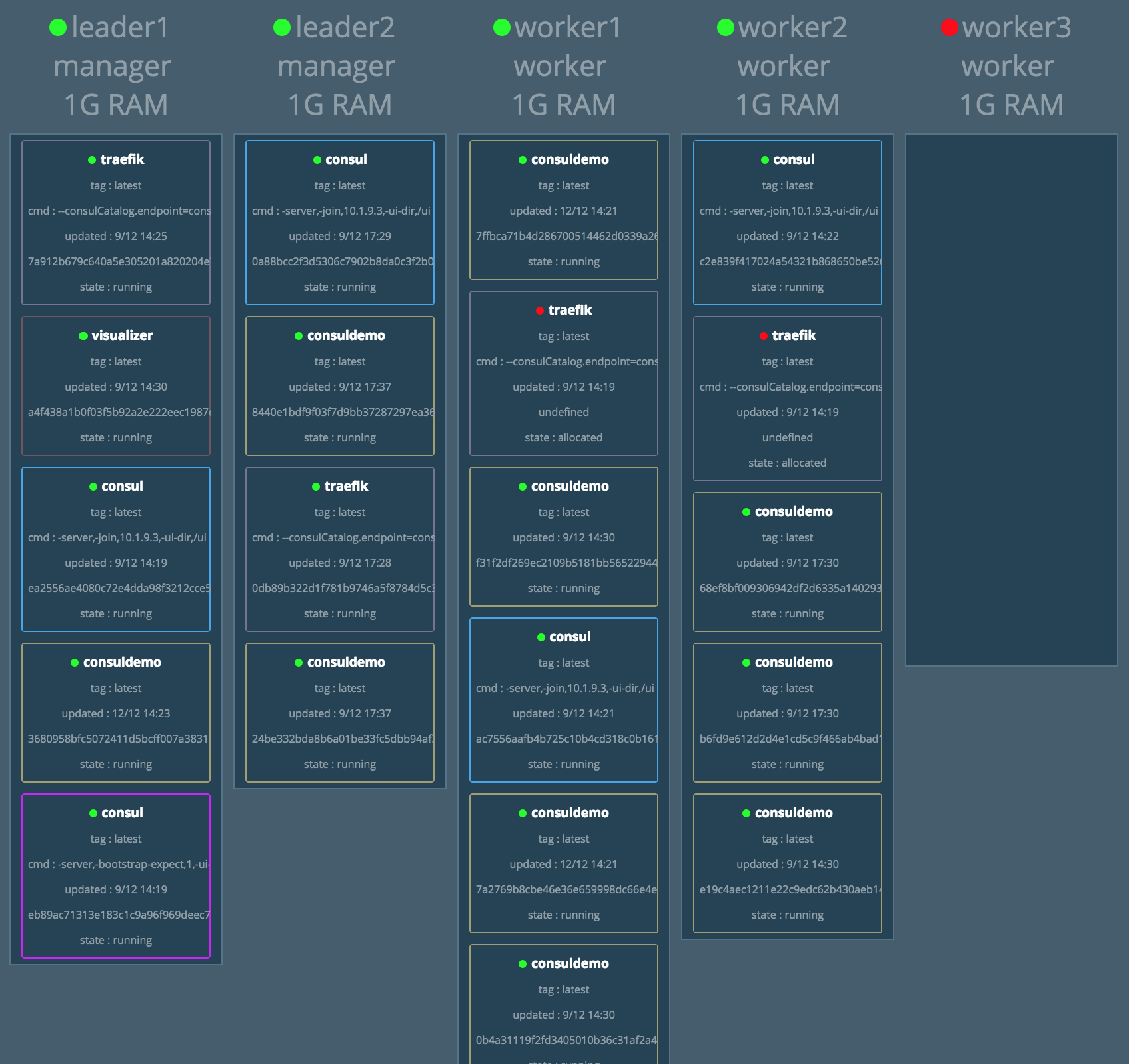
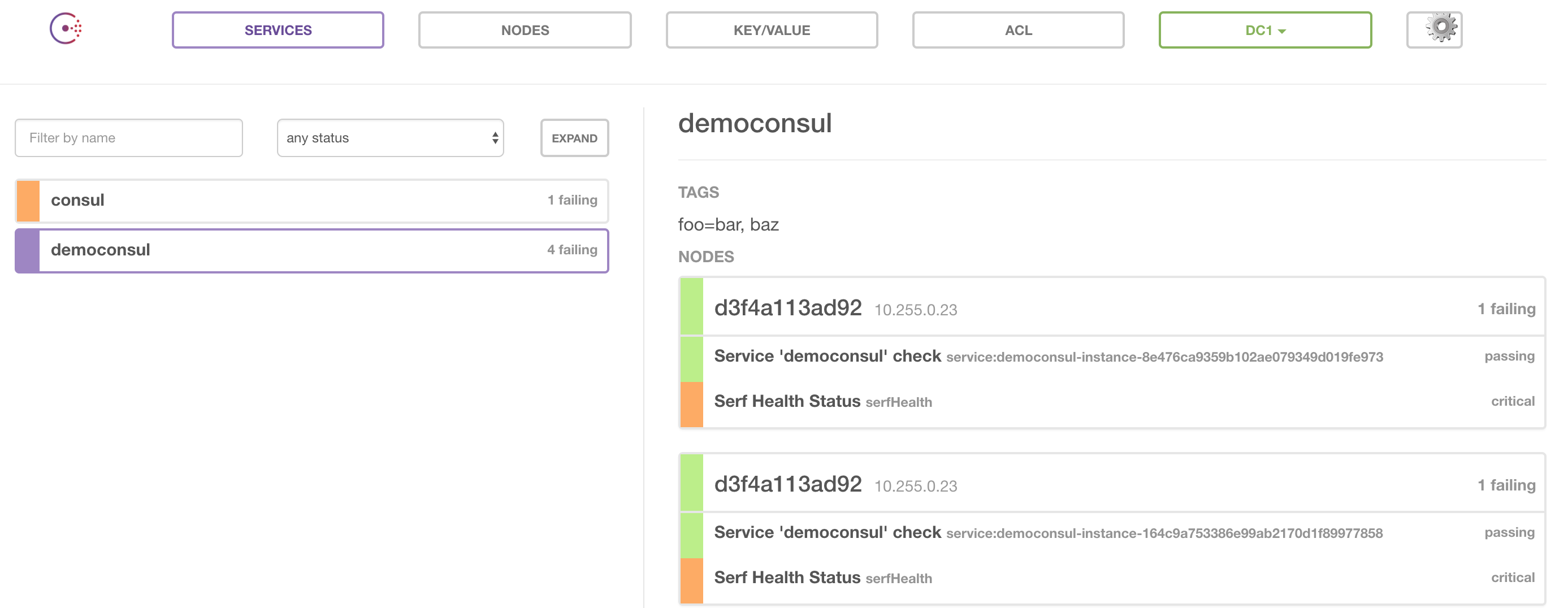
Swarm a automatiquement réparti mes containers applicatifs sur les quatre instances restantes.
Dans l’interfaces de Consul il reste des instances en “failing”, en effet les instances ne se sont pas “deregister” puisqu’elles ont été supprimées, les nouvelles instances créées par Swarm ont bien été enregistrées dans le Consul.
Bien sûr mon service est toujours fonctionnel même si j’ai eu une erreur “502” le temps de détecter les erreurs. Cette erreur ne se répète plus au bout de quelques secondes, elle apparaît dans l’onglet “health” de Traefik.
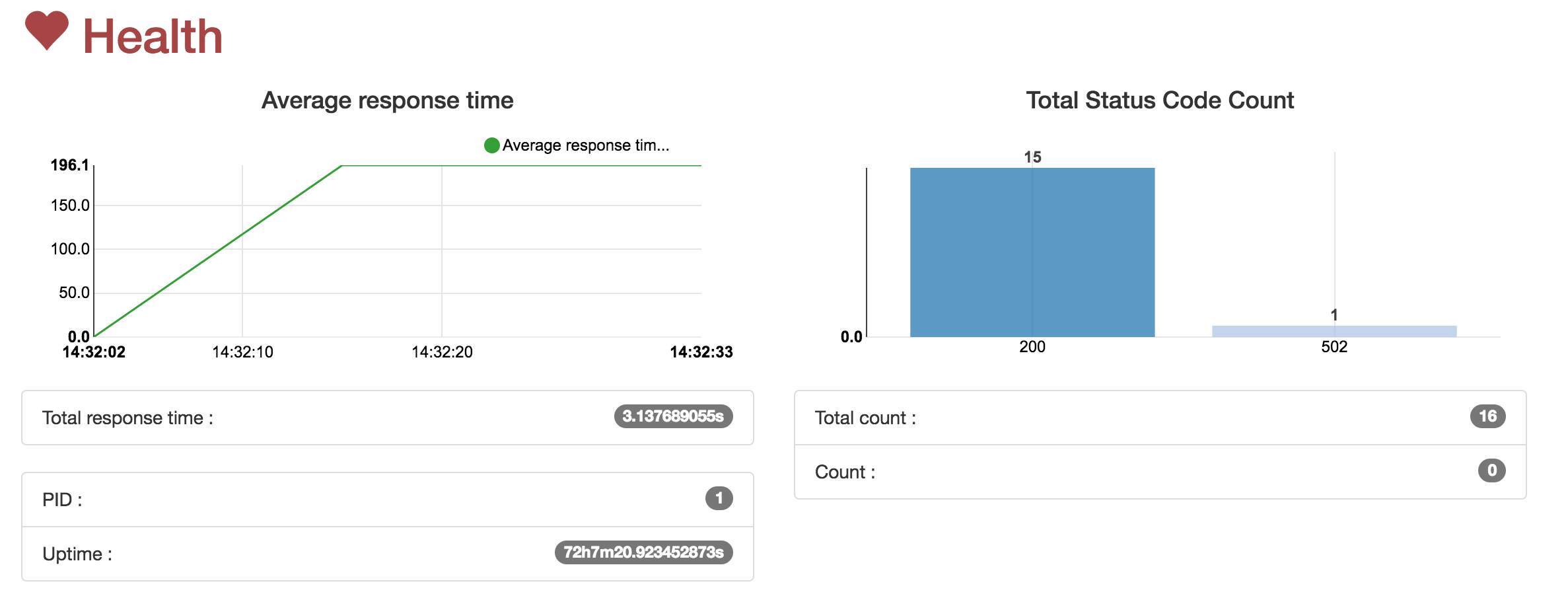
Le test suivant consiste à supprimer “leader2”. Même résultat que la suppression de “worker3”.
Mon cluster Consul nécessite deux services :
Mais ce que j’aimerais, c’est pouvoir supprimer “consul-leader” pour éliminer ce Single Point Of Failure.
Si je le supprime dans un premier temps tout fonctionne bien. Les autres instances prennent le choix d’un nouveau “leader” et Consul gère bien ce point. Mais si je rajoute un nœud, alors s’appliquent à nouveau les paramètres posés lors de la création du service : “-join $ip_leader1”.
Forcément la nouvelle instance Consul ne peut pas se connecter...
Cela ne concerne que les instances Consul puisque les instances applicatives se connectent sur "consul-nodes".
Il faudrait si cela se produit recréer un nouveau service "consul-leader" qui se connecterait à "consul-nodes".
Puis mettre à jour le service "consul-nodes" via un "service update".
Je n'ai pas trouvé à ce jour une solution simple pour résoudre ce point dans cet environnement.
Une des hypothèses de travail pourrait être de faire un "service update" sur "consul-nodes" et de remplacer le “-join $ip_leader1” par “-join consul-nodes.multi-host-net”.
De plus un noeud Consul par noeud Swarm est très largement exagéré, dans le cas de cluster Swarm important on doit utiliser les contraintes des services pour le limiter aux seuls "leaders Swarm" ou créer une nomenclature porteuse de l'information.
Qu’est ce que c’est ? Consul est un “service registry” ainsi qu’un stockage de dictionnaire (key/value) qui permet de mettre en place un service de...

Docker Machine est un outil de la famille Docker qui se charge de créer et configurer des machines pour exécuter le daemon Docker. Avec Kitematic,...
