

Saga de l'été : E03 Mon orchestrateur de conteneurs multi-cloud
Cet article fait partie d’une série d’articles autour du thème "Construire des applications résilientes en multi-cloud" qui sera publiée tout au long de l’été.

Sommaire
Dans nos précédents articles nous avons vu comment construire une infrastructure multi-cloud en reliant AWS et GCP via un VPN, puis nous avons préparé un annuaire de service ainsi que des répartiteurs de charge. Nous conservons l’objectif suivant : permettre à nos applications d’exister entre plusieurs fournisseurs de cloud.
Nous verrons ici comment mettre en place un orchestrateur de conteneurs afin de pouvoir instancier nos applications.
Cette nouvelle étape va s’appuyer sur les précédentes, donc n’hésitez pas à vous faire une piqûre de rappel en relisant les autres articles :
- E01 Construction d’une infrastructure multi-cloud.
- E02 Découverte de service et répartition de charge multi-cloud.
La création de l’infrastructure est assistée par Terraform, mais peut aussi être réalisée manuellement.
Le code utilisé est publié au fur et à mesure des articles sur : https://github.com/bcadiot/multi-cloud.
Pour information, afin de simplifier l'article, certains éléments n'apparaissent pas (comme les security group et les variables Terraform) mais peuvent être récupérés depuis les sources publiées sur github.
Quel est l’objectif ?
En nous appuyant sur notre infrastructure, nous allons maintenant construire le système de gestion de nos applications. Nous allons instancier nos applications sous forme de conteneurs Docker, et pour y parvenir nous choisissons un nouveau produit de l'écosystème HashiCorp : Nomad.
Ce produit Nomad va se connecter au cluster Consul et bénéficier de l'intégration aux services existants, notamment Traefik et la distribution multi-cloud.
Enfin nous lancerons une application de test au sein de ce cluster pour vérifier que tout fonctionne correctement.
Le schéma ci-dessous représente notre architecture cible :
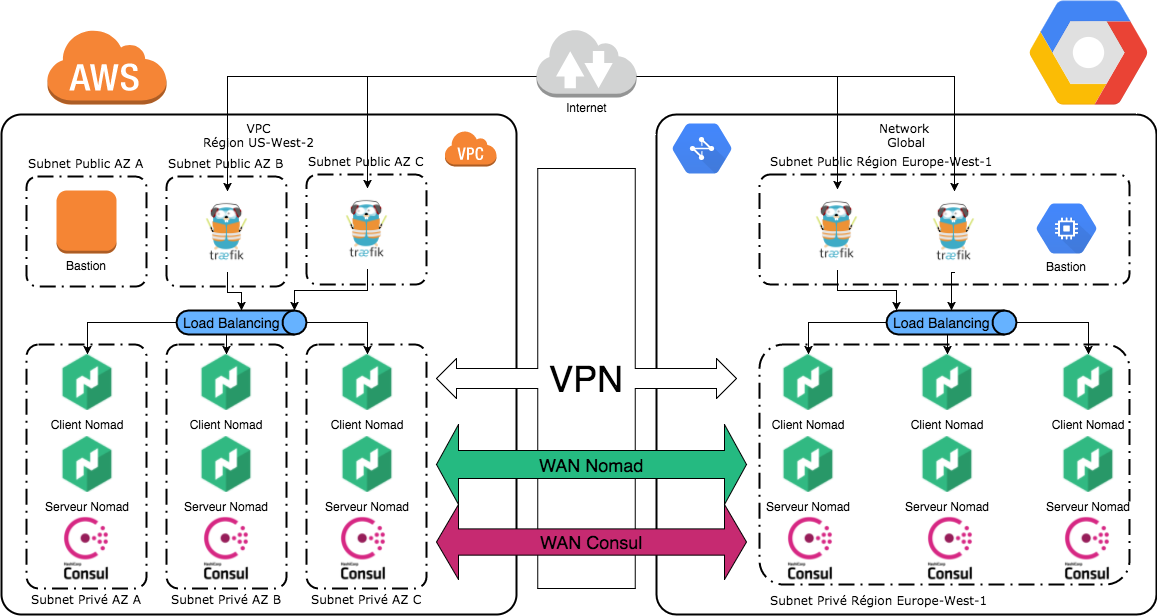
Installation du cluster Nomad
Sur chaque cloud, nous allons instancier un cluster Nomad de trois noeuds de type Server et trois noeuds de type Client. Chacune de ces instances embarquera un client Consul, et utilisera les mécanismes d'auto-détection des autres pairs Consul. Enfin, pour terminer, le moteur d'exécution de nos applications utilisera Docker qui sera préinstallé sur chaque client Nomad.
Par exemple sur GCP pour instancier nos serveurs Nomad :
resource "google_compute_instance" "nomad_servers" {
count = 3
name = "server-gcp-nomad-servers-${count.index + 1}"
machine_type = "${var.gcp_instance_type}"
zone = "${var.gcp_region}-${element(var.az_gcp, count.index)}"
boot_disk {
initialize_params {
image = "${var.gcp_image}"
}
}
scheduling {
automatic_restart = true
on_host_maintenance = "MIGRATE"
}
tags = ["nomad-servers", "consul-clients"]
network_interface {
subnetwork = "${data.terraform_remote_state.network.gcp_priv_subnet}"
}
service_account {
scopes = [
"https://www.googleapis.com/auth/compute.readonly"
]
}
metadata_startup_script = "${data.template_file.gcp_bootstrap_nomad_server.rendered}"
}
Comme lors de la création de nos instances Consul, nous déclarons une ressource template afin de mutualiser le script de bootstrap entre AWS et GCP :
data "template_file" "gcp_bootstrap_nomad_server" {
template = "${file("bootstrap_nomad.tpl")}"
vars {
zone = "$(curl http://metadata.google.internal/computeMetadata/v1/instance/zone -H \"Metadata-Flavor: Google\" | cut -d\"/\" -f4)"
region = "$(echo $${ZONE} | cut -d\"-\" -f1)"
datacenter = "$(echo $${ZONE} | cut -d\"-\" -f1)-$(echo $${ZONE} | cut -d\"-\" -f2)"
output_ip = "$(curl http://metadata.google.internal/computeMetadata/v1/instance/network-interfaces/0/ip -H \"Metadata-Flavor: Google\")"
nomad_version = "0.6.2"
consul_version = "0.9.2"
node_type = "server"
join = "\"retry_join\": [\"provider=gce tag_value=consul-servers\"]"
}
}
Configuration des agents Nomad
La configuration des agents Nomad est faite automatiquement lors du bootstrap, néanmoins il est intéressant de regarder la configuration déployée.
Par exemple pour la partie serveur :
region = "${REGION}"
datacenter = "${DATACENTER}"
data_dir = "/var/nomad"
bind_addr = "${OUTPUT_IP}"
server {
enabled = true
bootstrap_expect = 3
}
consul {
address = "127.0.0.1:8500"
}
La configuration est minimaliste, nous indiquons cependant la région gérée par notre cluster Nomad. Ainsi qu'une connexion vers le cluster Consul. Cet ajout vers Consul permet à Nomad de lire sa configuration et découvrir automatiquement les autres agents Nomad.
A noter que ce bloc est optionnel car par défaut si Nomad trouve un agent Consul localement il ira tenter de s'y connecter.
Si on s'attache maintenant à la configuration cliente de Nomad :
region = "${REGION}"
datacenter = "${DATACENTER}"
data_dir = "/var/nomad"
bind_addr = "${OUTPUT_IP}"
client {
enabled = true
}
Le bloc est encore plus simple que pour la partie serveur, car il s'agit simplement d'activer la fonction client. Il ira de lui même se configurer et notamment découvrir si Docker est installé, et s’il y a accès. Dans notre script de bootstrap nous avons installé Docker, et ajouté l'utilisateur Nomad dans le groupe Docker afin d’autoriser la communication.
Création de l'application de test
Maintenant que notre cluster Nomad est opérationnel nous pouvons tenter de déployer une application. Il s'agit d'une simple application lançant un serveur web et s'enregistrant sur Consul et sur Traefik.
Note importante : Afin de simplifier la démonstration nous allons enregistrer le job directement depuis la CLI d'un serveur Nomad. Cet accès externe n'existe pas et nous supposerons que vous pouvez agir depuis l'intérieur, plusieurs possibilités existent néanmoins :
- Se connecter en SSH sur l'un des serveurs Nomad, copier le fichier du job, et enregistrer le job en CLI.
- Se connecter en SSH sur le bastion, copier le fichier du job, et enregistrer le job via l'API HTTP.
- Ouvrir l'API Nomad dans Traefik en ajoutant dans un fichier service
nomadle tag traefikexposed, puis enregistrer le job à distance via l'API HTTP (cette méthode représente une faille de sécurité car elle ouvre un accès anonyme en écriture depuis tout internet vers notre cluster Nomad).
job "demoapp" {
region = "europe"
datacenters = ["europe-west1"]
type = "service"
update {
canary = 1
max_parallel = 1
}
group "webs" {
count = 2
restart {
attempts = 3
delay = "30s"
interval = "2m"
mode = "delay"
}
task "frontend" {
driver = "docker"
config {
image = "httpd"
port_map = {
http = 80
}
}
service {
port = "http"
tags = [
"traefik.frontend.rule=Host:demo.exemple.com",
"traefik.tags=exposed"
]
}
resources {
cpu = 200
memory = 64
network {
mbits = 10
port "http" {
}
}
}
}
}
}
Quand on observe ce job, on note quelques éléments intéressants :
- Localisation : Nous fixons la région
europeet le datacentereurope-west1. Ce qui signifie qu'il faut déclarer un job pour chaque région. - Update : Ce bloc permet de définir la stratégie de mise à jour de notre job. Nous choisissons une politique de type Canary afin de ne déployer en production qu'après nous être assurés que tout était correct. Nous verrons plus tard comment cela fonctionne.
- Docker : Pour des questions de simplicité, nous utilisons une image Docker minimale et déclarons qu'elle utilise le port 80.
- Service : Dans cette partie nous créons la configuration de définition de notre service, et notamment l'intégration dans Traefik. On observe qu'on souhaite exposer le service sur l'url
demo.exemple.com. - Resources : Enfin les ressources qui seront utilisées par notre job sont indiquées ici. Cette partie est utilisée par l'ordonnanceur Nomad, et c'est grâce à cela qu'il va décider où et comment lancer le job.
Nous pouvons maintenant lancer le job :
$ nomad run -address=http://172.27.3.133:4646 app-gcp-step1.nomad
==> Monitoring evaluation "1d7b9a95"
Evaluation triggered by job "demoapp"
Evaluation within deployment: "e839ee3d"
Allocation "e29e87d9" created: node "bdd7c860", group "webs"
Allocation "98bf6555" created: node "546f06e7", group "webs"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "1d7b9a95" finished with status "complete"
Si nous observons le statut du job :
$ nomad status -address=http://172.27.3.133:4646 demoapp
ID = demoapp
Name = demoapp
Submit Date = 09/04/17 12:36:41 UTC
Type = service
Priority = 50
Datacenters = europe-west1
Status = running
Periodic = false
Parameterized = false
Summary
Task Group Queued Starting Running Failed Complete Lost
webs 0 0 2 0 0 0
Latest Deployment
ID = e839ee3d
Status = successful
Description = Deployment completed successfully
Deployed
Task Group Desired Placed Healthy Unhealthy
webs 2 2 2 0
Allocations
ID Node ID Task Group Version Desired Status Created At
98bf6555 546f06e7 webs 0 run running 09/04/17 12:36:41 UTC
e29e87d9 bdd7c860 webs 0 run running 09/04/17 12:36:41 UTC
N'hésitez pas à accéder à l'URL définie dans la configuration frontend de votre job (ici : demo.exemple.com). Si vous ne souhaitez pas définir un vrai domaine vous pouvez utiliser la méthode proposée à la fin de l'article E02 Découverte de service et répartition de charge multi-cloud.
Pour rappel la même action est à réaliser sur la région US gérée par AWS car une seule région peut être ciblée par job.
Mise à jour de l'application en mode Canary
Pour terminer, nous allons tester l'option de mise à jour des jobs apportée par la dernière version de Nomad 0.6.
Le mode de mise à jour Canary permet d’instancier un certain nombre de nouveaux serveurs contenant la nouvelle version de notre applicatif sans jamais toucher à nos serveurs actuellement en production. Puis, une fois que nous aurons validé que cette nouvelle version est conforme, nous décidons de déclencher la mise à jour globale.
Dans notre précédente configuration du job, nous avons défini une politique de mise à jour de type Canary. Imaginons que nous souhaitions mettre à jour le job en augmentant les ressources allouées à chaque instance :
job "demoapp" {
[...]
resources {
cpu = 300
memory = 128
[...]
}
}
}
}
}
Nous gardons strictement le même job mais nous augmentons la quantité de ressources allouées. Essayons de vérifier le plan d'exécution avant de lancer la mise à jour :
$ nomad plan -address=http://172.27.3.133:4646 app-gcp-step2.nomad
+/- Job: "demoapp"
+/- Task Group: "webs" (1 canary, 2 ignore)
+/- Task: "frontend" (forces create/destroy update)
+/- Resources {
+/- CPU: "200" => "300"
DiskMB: "0"
IOPS: "0"
+/- MemoryMB: "64" => "128"
}
Scheduler dry-run:
- All tasks successfully allocated.
Job Modify Index: 16
To submit the job with version verification run:
nomad run -check-index 16 app-gcp-step2.nomad
When running the job with the check-index flag, the job will only be run if the
server side version matches the job modify index returned. If the index has
changed, another user has modified the job and the plan's results are
potentially invalid.
Nomad nous décrit les changements et propose la mise à jour en créant un canary et ignorant le reste du job. C'est bien le comportement attendu, et il nous propose même de faire la mise à jour sur un index afin de s'assurer que celle-ci sera bien conforme au plan affiché. C'est ce que nous allons faire :
$ nomad run -check-index 16 -address=http://172.27.3.133:4646 app-gcp-step2.nomad
==> Monitoring evaluation "8a1ea68e"
Evaluation triggered by job "demoapp"
Evaluation within deployment: "b78e97cc"
Allocation "2db75cbe" created: node "93864b30", group "webs"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "8a1ea68e" finished with status "complete"
Le résultat d'exécution indique bien la création d'une Allocation mais pas de suppression, continuons l'investigation en regardant le statut du job pour s'assurer que le canary est bien actif :
$ nomad status -address=http://172.27.3.133:4646 demoapp
ID = demoapp
Name = demoapp
Submit Date = 09/04/17 13:04:14 UTC
Type = service
Priority = 50
Datacenters = europe-west1
Status = running
Periodic = false
Parameterized = false
Summary
Task Group Queued Starting Running Failed Complete Lost
webs 0 0 3 0 0 0
Latest Deployment
ID = b78e97cc
Status = running
Description = Deployment is running but requires promotion
Deployed
Task Group Promoted Desired Canaries Placed Healthy Unhealthy
webs false 2 1 1 1 0
Allocations
ID Node ID Task Group Version Desired Status Created At
2db75cbe 93864b30 webs 1 run running 09/04/17 13:04:14 UTC
98bf6555 546f06e7 webs 0 run running 09/04/17 12:36:41 UTC
e29e87d9 bdd7c860 webs 0 run running 09/04/17 12:36:41 UTC
Notre souhait est bien pris en compte, et il est clairement indiqué que notre déploiement est en état running et attend d'être validé de notre côté.
Après avoir vérifié que notre applicatif fonctionne correctement sur le canary il est maintenant possible de promouvoir cette nouvelle version afin que le rolling update se déclenche.
$ nomad deployment list -address=http://172.27.3.133:4646
ID Job ID Job Version Status Description
b78e97cc demoapp 1 running Deployment is running but requires promotion
e839ee3d demoapp 0 successful Deployment completed successfully
$ nomad deployment promote -address=http://172.27.3.133:4646 b78e97cc
==> Monitoring evaluation "c7c47996"
Evaluation triggered by job "demoapp"
Evaluation within deployment: "b78e97cc"
Allocation "aeb0481e" created: node "546f06e7", group "webs"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "c7c47996" finished with status "complete"
Avec ces commandes nous avons promu la nouvelle version de notre applicatif et donné notre accord à Nomad pour procéder à la mise à jour en ajoutant les instances manquantes et en supprimant les anciennes.
Au bout de quelques dizaines de secondes, nous pouvons vérifier le statut de notre application :
$ nomad status -address=http://172.27.3.133:4646 demoapp
ID = demoapp
Name = demoapp
Submit Date = 09/04/17 13:04:14 UTC
Type = service
Priority = 50
Datacenters = europe-west1
Status = running
Periodic = false
Parameterized = false
Summary
Task Group Queued Starting Running Failed Complete Lost
webs 0 0 2 0 2 0
Latest Deployment
ID = b78e97cc
Status = successful
Description = Deployment completed successfully
Deployed
Task Group Promoted Desired Canaries Placed Healthy Unhealthy
webs true 2 1 2 2 0
Allocations
ID Node ID Task Group Version Desired Status Created At
aeb0481e 546f06e7 webs 1 run running 09/04/17 13:12:40 UTC
2db75cbe 93864b30 webs 1 run running 09/04/17 13:04:14 UTC
98bf6555 546f06e7 webs 0 stop complete 09/04/17 12:36:41 UTC
e29e87d9 bdd7c860 webs 0 stop complete 09/04/17 12:36:41 UTC
Nous voyons clairement que l'ancienne version a été arrêtée et que la nouvelle est dorénavant en production.
Nous sommes maintenant en mesure de déployer des applications sur notre infrastructure multi-cloud et de gérer leur cycle de vie.
Conclusion
Nous avons créé nos orchestrateurs de conteneurs et environnements applicatifs sur nos deux fournisseurs de cloud et il est maintenant possible de continuer notre série sur l'aspect stockage répliqué de notre infra multi-cloud.
Si tester le déploiement vous intéresse, le code utilisé est disponible sur https://github.com/bcadiot/multi-cloud.
Rendez-vous très bientôt pour le prochain article !



