 Ismael HOMMANI
Ismael HOMMANI






Comment gérer les clusters GKE, EKS et AKS sur Lens en 4 étapes
Introduction Dans l’article Les outils incontournables pour accélérer votre utilisation de K8s !, nous avons découvert l’utilisation de K9s...

Le pattern GitOps a énormément gagné en popularité ces dernières années.
Plutôt discret à ses débuts, il devient sûrement un standard de-facto en tant que pattern de déploiement sur les plateformes Kubernetes.
Nous en parlions en détail dans de précédents articles dont nous vous conseillons la lecture pour bien comprendre l’esprit du GitOps.
Pour autant, il n’y a pas de consensus clair sur l’implémentation à adopter qui sont aujourd’hui représentées par les deux références de la CNCF et récemment graduated que sont Flux et ArgoCD.
Le choix est loin d’être anecdotique, car derrière un socle commun de “faire du GitOps”, il y a des philosophies et des architectures d’implémentation très différentes.
Choisir l’un par rapport à l’autre va conduire à devoir adapter sa structure de dépôt Git, la configuration de ses clusters et plus globalement son approche DevOps.
A travers la pratique de ces deux outils, il nous semble important de vous partager nos retours d’expérience pour permettre à chacun de comprendre vers quel outil aller en fonction de ses contraintes. Plutôt que d’approcher les outils par l'expérience opérationnelle ou les performances, nous préférons axer cet article sur les différences fondamentales entre leurs modèles. Ce niveau est suffisant pour se faire une idée de la viabilité de l’un ou l’autre dans votre contexte métier.
Précisons que l’objectif n’est pas d’opposer les deux outils, mais d’en extraire les points communs, leurs particularités et enfin leurs axes d’amélioration pour créer une argumentation claire selon l’outil considéré.
Indépendamment du contexte GitOps, nous parlons de modèle pour décrire les différentes entités manipulées ainsi que les relations et les règles qui les lient.
Dans le cadre d’une comparaison Flux/ArgoCD cela nous paraît intéressant à plus d’un titre.
De ce modèle découlent les capacités, l'expérience utilisateur et les performances des outils.
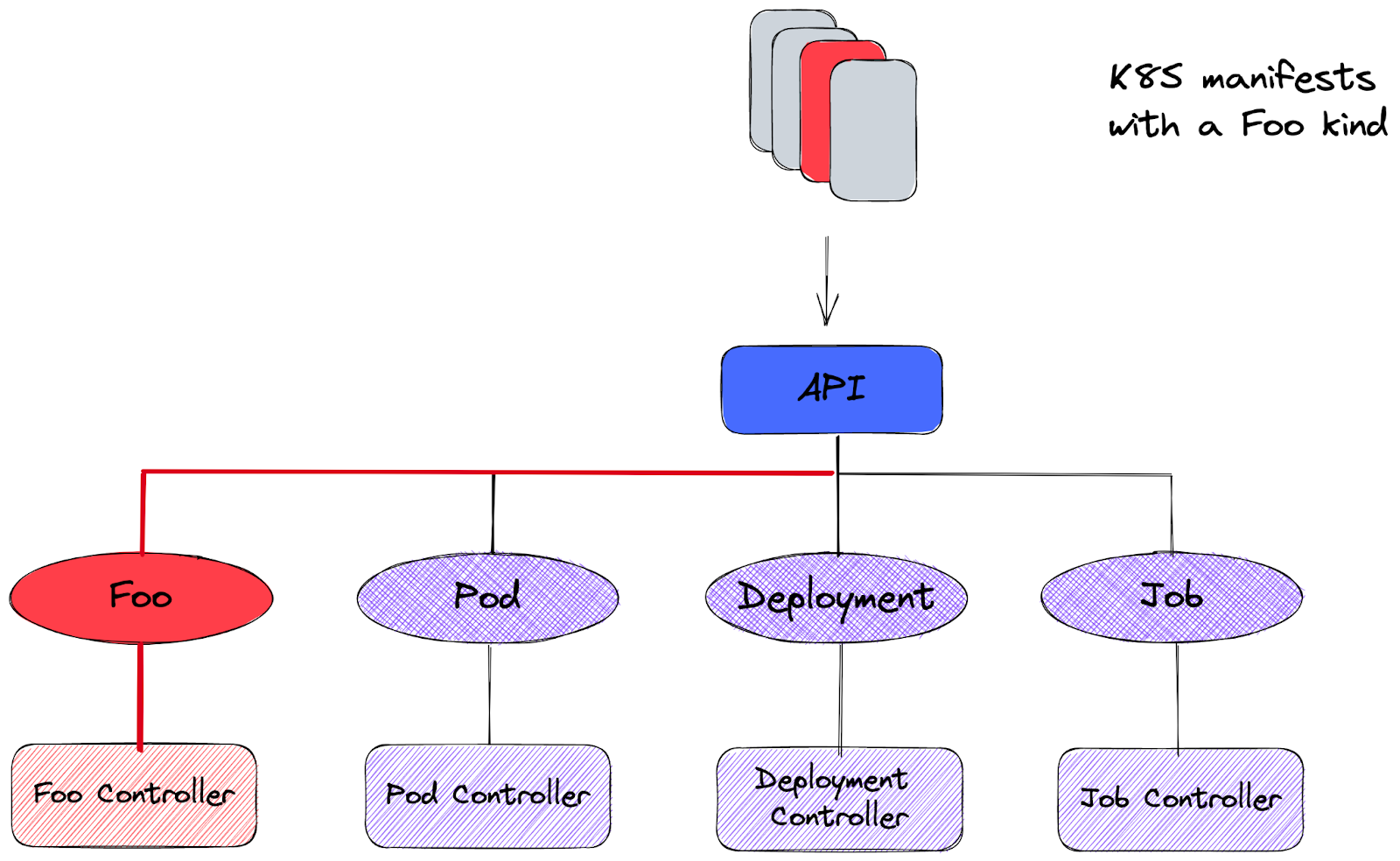
Que ce soit Flux ou ArgoCD, les deux outils se basent sur un même métamodèle: le pattern Operator de Kubernetes.
Par défaut, Kubernetes ne comprend qu’un seul métier : celui de déployer vos applicatifs et d’en spécifier les conditions d’accès.
Le pattern operator va enrichir cette compréhension avec une logique métier propre que vous définissez à travers une Custom Resource Definition et son Controller associé. Ce dernier est garant de la bonne manipulation des entités de base de K8S pour inculquer une nouvelle logique à Kubernetes. Par exemple, un operator Mysql automatise des tâches de DBA sur la présence d’une Custom Ressource ad-hoc. Tout type de logique est candidat à ce pattern, en particulier la logique GitOps.
Un controller Foo permet d’enrichir Kubernetes avec un métier “Foo”. Une CRD ad-hoc permet d’en paramétrer le comportement
Fort de ce rappel, observons comment Flux et ArgoCD prennent parti de cette capacité de Kubernetes.
Le modèle Flux appelé “GitOps toolkit” s’appuie sur des Custom Resources formant le graphe de dépendance fonctionnel suivant :
Les entités Flux liées par un graphes relationnel
Un point essentiel à saisir est la répartition des responsabilités de la synchronisation GitOps qui est portée par plusieurs ressources.
Le socle de la synchronisation est porté par le couple {Source, Kustomization}.
La Source représente votre point de vérité, le territoire, là où la Kustomization représente l’exploration de cette source, i.e la carte des entités à considérer pour la synchronisation.
Le lien entre la Source et la Kustomization étant porté par la Kustomization via une entrée sourceRef dans son manifeste.
apiVersion:
source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: podinfo
namespace: default
spec:
interval: 5m0s
url: https://github.com/stefanprodan/podinfo
ref:
branch: master
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: podinfo
namespace: default
spec:
interval: 10m
targetNamespace: default
sourceRef:
kind: GitRepository
name: podinfo
path: "./kustomize"
prune: true # remove stale resources from cluster
Bien qu’il existe plusieurs types de Source, la principale est le dépôt Git dans lequel une Kustomization “racine” prend en compte d'autres ressources Kubernetes.
Ces dernières pouvant elles-mêmes être de type Source et Kustomizations.
On comprend assez rapidement que le graphe précédent devient un directed graph, idéalement acyclique (DAG). En effet, les cycles ne vous seront remontés qu’au moment de la synchronisation des sources pointées par une Kustomization donnée. Si cette dernière crée un cycle en pointant vers une source “ancêtre”, la synchronisation échouera pour cette Kustomization et donc les ressources pointées.
Parmi les autres types de sources, citons HelmRepository, OCIRepository. Autant de sources supplémentaires pour la création des ressources Kubernetes pointées par les manifestes “sous” une Kustomization.
Bien sûr, Flux ne fait pas l’impasse sur Helm, le package manager de facto de Kubernetes. Une CRD HelmRelease est disponible et représente une release d’un chart Helm dont le repository se retrouvera parmi des sources au sens Flux, la plus évidente étant le kind HelmRepository.
Bien que cela ne soit pas nécessaire à la compréhension du modèle, le terme de Kustomization vient de l’outil Kustomize intégré à Kubernetes et sur lequel s’appuie Flux.
L’atout de Kustomize est de permettre la gestion de vos manifestes à travers une base et des fichiers “patch” sélectionnés selon l’environnement dans lequel vous considérez votre déploiement.
Le cloud native est un monde d’eventual consistency. Tout finit par “tomber en marche” mais au prix d’un certain nombre d'essais avant qu’une ressource requise par d’autres finisse par apparaître, débloquant ainsi les ressources et services dépendants.
Flux offre une capacité d’orchestration pour lier (plutôt que prioriser) la prise en compte de telle ou telle Kustomization ou HelmRelease. Ainsi, il est possible pour un consommateur de Flux de créer un graphe de dépendance logique entre entités Flux, la seule contrainte étant que ces entités soient du même type.
Flux permet de définir des dépendances “arrières” entre Kustomizations ou HelmReleases
À partir d’une installation unique de Flux peut-on gérer la synchronisation GitOps de plusieurs clusters Kubernetes ? La réponse est non.
Chaque cluster à considérer pour une réconciliation GitOps doit avoir Flux d’installé.
Pour autant, il est possible de mimer la gestion multi-clustering à travers un control plane unique avec l’approche suivante :
Flux a une approche extrêmement distribuée de la synchronisation GitOps
En faisant pointer l’ensemble des installations Flux sur un unique dépôt Git, nous contrôlons de facto le contenu des différents clusters via un unique point : le dépôt Git.
En allant plus loin, ce même dépôt peut aussi contenir les sources d’installation Flux d’un cluster donnée et sur lesquelles ce dernier est capable de se synchroniser.
À ce moment-là, nous contrôlons non seulement le contenu de tous les clusters sur un dépôt unique, mais aussi les différentes installations Flux.
En définissant le tenant comme l’entité de ségrégation atomique (selon votre contexte, équipe, organisation, environnement, …), le multi-tenant serait la capacité à garantir l’intégrité de cette frontière et donner l’illusion à chaque tenant d’être seul sur une plateforme donnée.
D’un point de vue Flux, comment garantir cette ségrégation sur une même organisation ?
Très souvent, Flux s’appuie sur les entités Kubernetes existantes pour définir ses propres capacités et il n’existe pas de notion de multi-tenancy by Flux . Flux préfère se reposer sur l’existant Kubernetes : les namespaces, les rôles, les comptes de services / identité et les rôles binding associés.
Se faisant, il n’y a pas une solution unique, mais plusieurs, dont la suivante tirée de la documentation officielle fait partie :
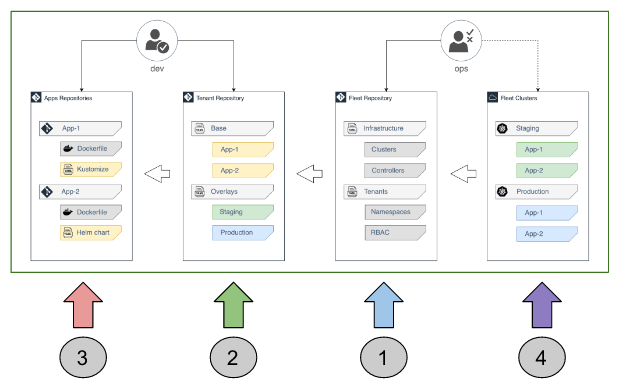
Flux, une vision de la multitenancy entre du Keep It Simple Stupid (KISS) et DIY
Sur l’entrée bleue, une installation Flux “admin” se synchronise sur des sources définissant les installations Flux ainsi que des tenants sous la forme de manifestes de type {Namespace, Role, Rolebinding, ServiceAccount}.
Toujours dans ces tenants, des synchronisations représentées par le couple {Source, Kustomization} pointent vers des sources Git illustrées par l’entrée verte : les tenants repositories.
Ces derniers contiennent les manifestes propres aux applications à déployer sur les clusters et pointent vers des artefacts produits à partir de dépôts de code applicatifs représentés par l’entrée rouge.
L’arbre de synchronisation issue de ces différentes entrées est calculé par l’instance de Flux installé sur un cluster et peut procéder à son implémentation : entrée violette.
Ajoutons à cela les permission d’accès et leur granularité de votre hébergeur de dépôt Git (GitLab, GitHub, etc.) et vous complétez la notion de multi tenancy par Flux tout en gardant bien en tête qu’il s’agit d’une approche possible parmis d’autres.
D’un point de vue logique, cela se traduit par l’arbre de synchronisation suivant :
Un arbre de synchronisation GitOps réparti sur plusieurs dépôts Git
ArgoCD centralise la philosophie GitOps à travers une unique ressource nommée Application. Ce modèle peut sembler plus simple comparé à celui de Flux qui repose sur un plus grand nombre de custom ressources. Toutefois, le modèle de configuration d’une Application ArgoCD est assez riche pour se conformer à différents contextes.
À sa base, l’Application regroupe la notion de source à synchroniser contenant des manifestes à déployer et de cible i.e le cluster k8s sur lequel déployer.
Le contenu d’une source Git peut être de différent type et comprend par défaut manifestes YAML et Kustomize ainsi que les langages de templating récurrents tels Helm, Jsonnet.
Un système de plugin permet d’enrichir cette liste de formats.
Point intéressant, un système configurable permet de “câbler” le cycle de vie de l’application à des hooks (des workloads) qui se déclenchent dès que l'Application entre dans une phase donnée de la synchronisation. Ce cycle de vie propre à l’Application ArgoCD donne la possibilité d’imaginer toute sorte de situation avec des actions associées.
Ce modèle GitOps tout-en-un tend à complexifier la prise en main de la ressource Application tout en simplifiant le modèle global et donc sa compréhension par l’utilisateur final. L’Application n’a en soi que très peu à voir avec la philosophie Kubernetes dans sa conception. Kubernetes n’est qu’un détail qui “transpire” que par la notion de cluster cible dans la configuration. Notons au passage que cette cible sera n’importe quel cluster auquel l’installation ArgoCD à accès.
Afin de fédérer ces différentes Applications, ArgoCD ajoute la notion d’AppProject pour définir les réponses possibles aux questions suivantes :
Toute Application appartient à un unique AppProject qui pourra contenir plusieurs Applications.
Un graphe de dépendances simple et non simpliste grâce à une configurabilité poussée
Tout comme Flux, il est possible d'ordonnancer l’ordre de prise en compte des ressources à synchroniser. Argo donne la possibilité de séparer une synchronisation en plusieurs waves que vous pourrez prioriser entre elles.
Ce n’est pas la même simplicité que Flux qui permet de définir des dépendances entre synchronisation (i.e Kustomization), mais cette approche permet des combinaisons plus fines.
Notons par ailleurs qu’ArgoCD ordonnance par défaut la synchronisation des entités Kubernetes en prenant par exemple en compte les Namespace avant les Deployment.
ArgoCD est par nature adapté à la gestion multicluster du fait d’une installation centrale sur un cluster pouvant accéder à d’autres clusters en fonction des credentials à sa disposition. Cette installation fait office de Control-Plane des différentes synchronisations.
Contrairement à Flux où chaque cluster “candidat” à une synchronisation doit avoir Flux d’installé.
ArgoCD, une approche plutôt centralisée de la synchronisation GitOps
On remarque que là où Flux est dans une approche systématique de pull depuis le cluster à synchroniser vers les dépôts Git source de vérité, ArgoCD mixe une approche pull et push depuis ce cluster “control plane”. Pull des informations à synchroniser, push vers les clusters où appliquer cette dernière.
La notion d’AppProject fait que la multi-tenant est déjà intégrée à ArgoCD. C’est par cette ressource que nous pouvons limiter les capacités de déploiement d’une Application.
Ajoutons à cela la présence d’une interface graphique avec son propre système de permission et l’intégration avec des solutions de SSO.
Tout comme dans le cas de Flux, nous pouvons invoquer la possibilité de considérer les permissions de son hébergeur de repo Git pour compléter ce paysage de multi-tenancy.
Contrairement à Flux, ArgoCD vient avec une interface graphique rendant compte de l’état de synchronisation de ses différents Applications ainsi que de leur fédération à travers les AppProjects.
La présence de cette interface est souvent invoquée comme argument sur la motivation du choix d’Argo plutôt que Flux.
Cependant, il ne faut pas voir cette absence d’UI chez Flux comme un élément manquant par rapport à ArgoCD. En réalité, tout ça est très cohérent avec leur façon de voir le GitOps comme nous le décrivons dans la partie qui suit.
La présence d’une UI chez ArgoCD qui témoigne plus d’une conception spécifique du GitOps que d’une disruption par rapport à Flux
En considérant la consigne suivante “Imaginez un outil pour implémenter le GitOps avec la possibilité de le déployer sur Kubernetes”, vous allez voir une équipe formée exclusivement d’experts Kubernetes, et une autre formée plutôt d'experts métiers avec un background technique.
Il est fort probable que la première équipe vous propose une solution proche de Flux là où la seconde aura une approche ressemblant à ArgoCD.
Flux propose un modèle GitOps fortement couplé aux capacités de Kubernetes. À bien y regarder, il ne propose que du liant pour des notions déjà existantes.
Kustomize, une release Helm, un repo Git ne sont rien de neuf. Les lier par des relations de dépendance ou en définir des fréquences de rafraîchissement sont ce que va apporter Flux à travers des CRD qui les encapsulent. L’esprit d’implémentation d’une feature est du point de vue Flux plus de se demander si :
ArgoCD offre a contrario un modèle GitOps autoportant. Comme si justement l’équipe qui en est à l’origine n’avait pas nécessairement Kubernetes en tête des plateformes cibles ou a minima comme une possibilité parmi d’autres. De nouvelles entités apparaissent et viennent enrichir le modèle Kubernetes dont le métier premier est de gérer des Deployments. L’Application devient une entité au-dessus du Deployment et qui capte la compréhension du GitOps du point de vue ArgoCD.
C’est dans cette optique qu’ArgoCD propose une interface graphique. C’est une manière d’expliciter clairement son modèle qui est indépendant de celui de Kubernetes.
Cette UI n’est pas un bonus, mais bien une nécessité causée par la manière même de fonctionner d'ArgoCD.
Un autre point différenciant entre les deux outils est la conception d'une synchronisation.
Du fait d’un rapport très proche à Kubernetes, Flux privilégie les synchronisations “transparentes” entre ce qui se trouve poussé sur un dépôt Git et l’état du cluster. Autrement dit, ce qui se trouve sur le repo et traqué par Flux est reproduit sans autre forme de procès sur votre cluster.
ArgoCD aura plus tendance à prévenir l’application automatique de synchronisation par un système de demande manuelle à travers l’interface graphique et il sera possible d’automatiser les synchronisations, mais cela doit être explicitement dit.
Une conséquence de ces observations est que dans le cas de Flux la connaissance de Kubernetes est un vrai plus pour son utilisateur (voire obligatoire) là où ArgoCD peut viser une population plus profane.
Ce que résume le tableau suivant :
|
Flux |
ArgoCD |
|
|
Complexité du modèle |
Distribué sur plusieurs entités |
Concentré sur une entité tout-en-un |
|
Gestion de la synchronisation GitOps |
Distribution extrême. Chaque plateforme à synchroniser doit avoir Flux d’installé |
Par défaut, centralisation de la logique de synchronisation sur un seul cluster |
|
Relation à k8s |
Colle au modèle k8s et son écosystème. Peut se voir comme une extension GitOps de Kubernetes. |
Modèle autonome à celui de Kubernetes |
|
Système d’extension |
Pattern Operator de Kubernetes |
Système de plugins propre à ArgoCD |
|
Orchestration des synchronisations |
Création de dépendances explicites entre entités Flux |
Système de priorisation de la prise en compte des synchronisations |
|
Actions complémentaires à la synchronisation |
Notion Kubernetes d’init container |
Système de Hooks à associer avec des phases du cycle de synchronisation |
|
Principales CRDs |
Sources + Kustomization |
AppProject + Application |
|
Besoin d’interface graphique ? |
K9S est suffisant |
La présence d’une UI par défaut est d’avantage le témoignage d’un besoin de l’outil que d’une feature |
Entre Flux et ArgoCD, il y a un choix fort loin d’être anecdotique.
D’un côté, Flux propose une approche plutôt KISS du GitOps en s’appuyant sur des notions de l’écosystème Kubernetes. Avoir une compréhension du fonctionnement de Kubernetes et de quelques outils gravitant autour (Kustomize, Helm) aidera sûrement dans la prise en main de Flux.
À l’opposé, ArgoCD part d’une feuille vierge pour définir le GitOps à travers son langage et ses entités. ArgoCD implémente ce modèle par des mécaniques propres à Kubernetes mais ne requiert pas pour autant la compréhension de cette plateforme. Kubernetes y est un détail d’implémentation.
Au-delà d’une question de performance ou d’aspect graphique, c’est bien la compréhension du modèle des deux outils et l’expérience utilisateur qui en découle qui doit servir de boussole quant au choix du bon outil GitOps selon le contexte dans lequel vous vous situez.

Introduction Dans l’article Les outils incontournables pour accélérer votre utilisation de K8s !, nous avons découvert l’utilisation de K9s...

WeScale était présent avec notamment nos quatre speakers Jean-Pascal Thiery, Guillaume Mathieu, Gérôme Egron et Ismaël Hommani ; sans oublier...
