 Bastien Cadiot
Bastien Cadiot


Dans nos précédents articles, nous avons vu comment construire une infrastructure multi-cloud en reliant AWS et GCP via un VPN, puis nous avons préparé un annuaire de service ainsi que des répartiteurs de charge, nous avons également déployé un orchestrateur de conteneurs pour pouvoir instancier nos applications, et enfin préparé une offre de service stockage distribuée. Nous conservons l’objectif suivant : permettre à nos applications d’exister entre plusieurs fournisseurs de cloud.
Cet article est le dernier de la série, nous verrons le déploiement final d'une application compatible multi-cloud et les points de vigilance à garder à l’esprit.
Cette nouvelle étape va s’appuyer sur les précédentes, donc n’hésitez pas à vous faire une piqûre de rappel en relisant les autres articles :
- E01 Construction d’une infrastructure multi-cloud.
- E02 Découverte de service et répartition de charge multi-cloud.
- E03 Mon orchestrateur de conteneurs.
- E04 - Stockage et réplication des données en mode multi-cloud
La création de l’infrastructure est assistée par Terraform, mais peut aussi être réalisée manuellement.
Le code utilisé est publié au fur et à mesure des articles sur : https://github.com/bcadiot/multi-cloud.
Pour information, afin de simplifier l'article, certains éléments n'apparaissent pas (comme les security groups et les variables Terraform) mais peuvent être récupérés depuis les sources publiées sur github.
TL;DR
Toute notre infrastructure multi-cloud est en place, et nous devons maintenant déterminer comment faire le lien des points d'entrées de notre application chez chaque fournisseur de cloud.
Après le choix d'un répartiteur de charge global multi-cloud, il devient vital de s'assurer que les tests de vie permettant la résilience de notre infrastructure sont bien opérationnels.
Enfin, un focus est fait sur l'importance d'adapter les applications pour les rendre pleinement compatibles avec toutes les spécificités et les avantages des déploiements multi-cloud.
La dernière partie consiste en une batterie de tests pour vérifier que chacun de nos composants est bien tolérant aux pannes, et vérifier leur comportement en cas d'erreur.
Quel est l’objectif ?
En nous appuyant sur notre infrastructure, nous allons déployer un exemple d'application et vérifier que tous les composants multi-cloud sont utilisés.
Le schéma ci-dessous représente notre architecture cible :
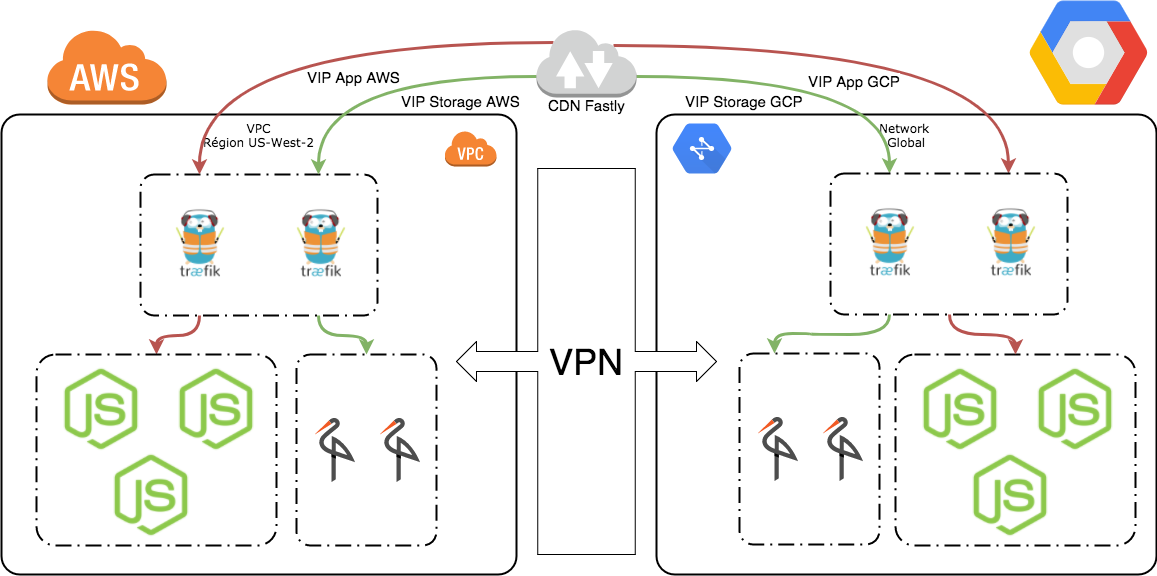
Agrégation des points d'entrée de chaque cloud
Ces dernières semaines, nous avons construit une infrastructure multi-cloud entre AWS et GCP. Cette infrastructure permet la communication entre les deux clouds, mais il reste un aspect qui n'a pas été encore adressé : le point d'entrée extérieur de notre infrastructure.
En effet, les réseaux publics des fournisseurs de cloud sont indépendants et il n'est pas possible dans notre scénario de faire en sorte qu'une seule adresse IP permette de contacter les deux entités. Comment résoudre ce problème afin de s'assurer que nos clients utilisent bien les deux côtés de notre infra multi-cloud ?
Répartition DNS (Round-robin DNS) : Cette technique consiste à s'appuyer sur les noms de domaine externes, et à renseigner les adresses IP de nos répartiteurs de charge internes comme autant d'alternatives.
- Avantages : La solution est la plus simple possible, on suppose que toutes nos applications hébergées sont contactées via leur nom DNS. On ne crée pas de nouvelles vulnérabilité car les enregistrements DNS sont propagés partout.
- Inconvénients : Aucun test de vie n'est réalisé, donc en cas de perte d'un répartiteur de charge, une partie de nos clients sont redirigés vers un équipement disparu. Le temps de propagation DNS peut être très long, donc tout changement peut provoquer des interruptions. En règle générale cette solution manque de souplesse.
Répartiteur de charge interne : Cette solution suppose que nos infras cloud ne sont pas exposées sur Internet. Elles sont connectées directement à notre infrastructure privée qui sert de passerelle pour les contacter.
- Avantages : Beaucoup d'entreprises utilisent cette méthode qui permet d'utiliser le cloud comme une extension de leurs propres datacenters. Le trafic entrant comme sortant est complètement contrôlé, et le seul point d'entrée est celui du ou des datacenters privés.
- Inconvénients : Cette méthode suppose de posséder déjà une infrastructure exposée sur internet, et les interconnexions directes avec les fournisseurs de cloud peuvent être relativement cher. De plus, cette solution crée un risque en faisant reposer la disponibilité de notre infra multi-cloud sur la disponibilité de notre infra interne.
CDN externe : La méthode fait appel à un tiers pour réaliser l'agrégation de nos points d'entrée. Ce tiers concentre tout notre trafic entrant puis le distribue aux différentes infra cloud selon des règles prédéfinies.
- Avantages : Faire confiance à un tiers nous permet de déléguer entièrement cet aspect vers une entité conçue spécifiquement pour gérer cette problématique. À condition de bien choisir son tiers de confiance, nous nous assurons d'une haute disponibilité, d'une distribution géographique homogène, ainsi que d'un service de cache permettant de monter en puissance aisément.
- Inconvénients : Le problème majeur de cette solution est qu'on ne résout pas le point d'unique de défaillance (SPOF). Ce tiers de confiance devient un SPOF car en cas de perturbations ou d'indisponibilités c'est toute notre infra multi-cloud qui s'en trouve affectée.
À noter que la plupart des fournisseurs de cloud proposent également un service de CDN interne, nous aurions pu l'utiliser mais dans ce cas, la conception d'une infra multi-cloud résiliente perd de son sens.
Nous ferons le choix de la solution un peu plus tard.
Les tests de vie au coeur de la résilience multi-cloud
La résilience de notre infrastructure provient de sa capacité à détecter les pannes et à adopter un comportement permettant au mieux l'autoréparation et au pire la prise de mesures conservatoires pour garantir la disponibilité.
Ces mesures interviennent tout au long de la chaîne de déploiement et concernent l'ensemble de nos composants. Au fil de nos articles nous en avons mis certaines en oeuvres, mais pas toutes :
Réseau interne : Notre réseau interne repose sur l'infra réseau de chaque fournisseur de cloud, et nous avons veillé à répartir nos serveurs sur les différentes zones de disponibilité afin de se prémunir d'une panne réseau d'une des zones. Nous faisons confiance à notre fournisseur de cloud pour maintenir une disponibilité sur son infrastructure réseau.
Réseau VPN : Nous avons relié nos deux clouds à l'aide d'un lien VPN contenant deux tunnels. Ce choix nous protège contre la perte d'un tunnel.
Réseau externe : Comme nous l'avons vu, les réseaux externes sont difficilement fédérables, néanmoins nous allons utiliser un CDN externe pour faire cette fédération. L'utilisation de ce composant nous prémunit contre la perte entière d'un fournisseur de cloud. Ce CDN externe réalise des tests de vie sur chacun des points d'entrée que nous lui fournissons et s'assure que le service est toujours disponible avant d'y envoyer notre trafic.
Serveurs virtuels : Nous avons pris le parti de multiplier le nombre d'instances présentes au sein de chaque fournisseur de cloud afin de garantir que la perte d'une machine n'interrompe pas le service. Pour aller plus loin, nous aurions pu utiliser des groupes d'instances (Instances Groups chez GCP, et AutoScalingGroups chez AWS) afin de s'assurer une remplacement automatique des instances en cas de coupure, ainsi qu'une adaptation du nombre d'instances suivant la charge réelle. Nous n'avons pas mis en place ce mécanisme pour simplifier les précédents articles.
Annuaire de services : Pour que notre infrastructure puisse évoluer sans nécessiter de reconfiguration constante de notre part, nous avons mis en oeuvre un annuaire de services. Son rôle est de découvrir les services hébergés et indiquer aux autres services où et comment contacter leurs clients. Cet annuaire de service est lui-même tolérant à la panne, et s'adapte automatiquement quand des services apparaissent ou disparaissent de l'infrastructure. Pour cela, il utilise entre autre les mécanismes des tests de vie pour n'indiquer que les services réellement disponibles. Nous aurions pu aller plus loin dans la construction de notre annuaire de service afin de définir des query. Cette définition permet d'indiquer qu'un service peut être secouru sur un autre datacenter et donc continuer à renvoyer le trafic sur l'autre datacenter.
Exécution des services : Afin de gérer la vie des services, nous avons également installé un orchestrateur. Ce dernier décide du placement des différents services, et s'assure également qu'ils fonctionnent correctement. Il dispose également de capacité de réparation de l'infrastructure, car en cas de panne il tentera de relancer les services interrompus.
Répartition de charge : La répartition de charge est gérée en interne par un répartiteur connecté à notre annuaire de service. Ainsi il n'enverra le trafic qu'aux services réellement étiquetés disponibles par l'annuaire. Quant à la répartition de charge externe, notre CDN externe s'appuie sur des tests de vie applicatifs pour déterminer si nos répartiteurs internes fournissent bien le service qu'il attend.
Stockage : Pour la mise en place du stockage, nous avons utilisé un moteur de stockage distribué qui réplique le trafic sur plusieurs noeuds. Cela nous garantit qu'en cas de perte d'un fournisseur de cloud, notre stockage reste accessible même si dégradé en terme de performances et de fonctionnalités.
Intégration des applications en mode multi-cloud
Beaucoup de choses peuvent être réalisées dans la définition de l'infrastructure, néanmoins pour être le plus efficace possible, il est fortement recommandé de modifier le code applicatif pour utiliser au mieux nos services.
Réaliser cette intégration permet une meilleure réactivité aux mutations de l'infrastructure et un usage plus complet de nos fonctionnalités.
Étape 1
Par exemple, imaginons une application web utilisant notre stockage objet pour le mettre à disposition sous forme d'une boutique en ligne.
Par défaut, il n'est pas nécessaire que l'application prenne conscience des spécificités de l'infrastructure, il est possible que l'application utilise un nom DNS pour joindre le stockage objet, et y récupérer ses informations. Ce nom DNS est fourni à l'aide de notre serveur reverse DNS devant l'annuaire de service.
Cependant supposons qu'un des noeuds de stockage tombe en panne, et qu'il s'agisse justement du noeud que notre application connaisse dans son entrée DNS. Dès lors, si notre application ne sait pas gérer un cache applicatif, il faudra attendre plusieurs secondes avant que le timeout ne survienne et que le cache DNS soit invalidé, cet intervalle va engendrer une perturbation d'une partie de notre application.
Étape 2
Réalisons maintenant des modifications pour que notre application ne se contente pas d'un nom DNS pour résoudre son service, mais aille directement interroger l'annuaire pour connaître l'adresse d'un noeud disponible. Ce mécanisme garantit une disponibilité bien meilleure car l'annuaire de service a une réactivité bien meilleure à la détection de panne. Dans ce scénario la perte d'un noeud de stockage engendre une légère perturbation le temps que l'annuaire de service détecte la panne et décide de sortir le noeud fautif du pool.
Étape 3
Dernier scénario, tous les noeuds de stockage d'un fournisseur de cloud tombent en panne, dès lors notre annuaire de service ne peut plus indiquer à notre application l'adresse d'un noeud valide. Afin de ne pas perdre la puissance d'un fournisseur de cloud entier, nous pouvons modifier les appels à notre annuaire de service pour qu'il ne se contente pas de lister les services disponibles qu'il connaît, mais pour qu'il nous renvoie également la liste des services disponibles sur les autres datacenters. Ce mécanisme appelé query rend l'ensemble de l'infrastructure un peu plus résiliente.
Déploiement des répartiteurs
Pour les accès externes nous allons utiliser la méthode du CDN externe. Puis nous allons aussi configurer Consul de manière à implémenter un mécanisme de Failover.
Notre répartiteur interne est déjà créé et fonctionnel, il n'y pas de reconfiguration à faire pour les serveurs Traefik.
Création du CDN externe
Pour notre CDN externe nous allons utiliser Fastly. Ce CDN est bien adapté en tant que Global Load Balancer et sa géodistribution massive nous permet de lui faire confiance quant à sa robustesse. À des fins de tests, il est possible de créer un compte offrant 50$ de crédits, ce qui est largement suffisant pour tester.
Terraform fournit un provider pour configurer aisément le service. Néanmoins, il faudra indiquer manuellement les adresses de tous nos load balancers locaux Traefik. Il n'est pas possible à l'heure actuelle de faire une boucle.
resource "fastly_service_v1" "minio" {
name = "minio-fastly"
domain {
name = "${var.minio-subdomain}.${var.domain}"
comment = "${var.minio-subdomain}"
}
backend {
address = "${data.terraform_remote_state.consul.gcp_traefik_public_ips.0}"
name = "GCP LB 1 hosting"
port = 80
error_threshold = 5
healthcheck = "miniohealth"
}
backend {
address = "${data.terraform_remote_state.consul.gcp_traefik_public_ips.1}"
name = "GCP LB 2 hosting"
port = 80
error_threshold = 5
healthcheck = "miniohealth"
}
backend {
address = "${data.terraform_remote_state.consul.aws_traefik_public_ips.0}"
name = "AWS LB 1 hosting"
port = 80
error_threshold = 5
healthcheck = "miniohealth"
}
backend {
address = "${data.terraform_remote_state.consul.aws_traefik_public_ips.1}"
name = "AWS LB 2 hosting"
port = 80
error_threshold = 5
healthcheck = "miniohealth"
}
healthcheck {
method = "GET"
host = "${var.minio-subdomain}.${var.domain}"
check_interval = "500"
path = "/minio/"
name = "miniohealth"
}
cache_setting {
name = "nocache"
action = "pass"
}
force_destroy = true
}
Ce service va créer le répartiteur pour Minio, il faudra également créer celui pour l'application.
Création de la query Consul pour le failover
Afin de rendre notre infrastructure résiliente en cas de panne des noeuds de stockage de tout un datacenter, nous allons créer une query Consul pour permettre le failover natif vers le second datacenter.
Commençons par créer l'objet pour la query storage-query.json depuis n'importe quel serveur membre du cluster Consul :
{
"Name": "storage-object-minio",
"Service": {
"Service": "storage-object-minio",
"Failover": {
"NearestN": 1
}
}
}
Maintenant, réalisons l'insertion de la query dans le Cluster et vérifions qu'elle fonctionne :
# curl --request POST --data @storage-query.json http://127.0.0.1:8500/v1/query
{"ID":"dd1f5589-a026-d8e6-92c7-544e49a66c95"}
# curl http://localhost:8500/v1/query?pretty
[
{
"ID": "dd1f5589-a026-d8e6-92c7-544e49a66c95",
"Name": "storage",
"Session": "",
"Token": "",
"Template": {
"Type": "",
"Regexp": "",
"RemoveEmptyTags": false
},
"Service": {
"Service": "storage",
"Failover": {
"NearestN": 1,
"Datacenters": null
},
"OnlyPassing": false,
"Near": "",
"NodeMeta": null
},
"DNS": {
"TTL": ""
},
"CreateIndex": 6803,
"ModifyIndex": 6803
}
]
Un ping sur l'adresse storage-object-minio.query.consul nous renverra l'un des nodes de notre datacenter, puis un des nodes de l'autre datacenter si nécessaire.
Déploiement de l'application de test
Pour notre application de test, j'ai choisi de réutiliser une application d'exemple de Minio. Il s'agit d'un magasin factice en NodeJS affichant des articles présents sur le stockage objet. Pour les besoins du test, j'y ai apporté quelques modifications pour la rendre pleinement résiliente et compatible multi-cloud.
Son code est disponible sur github dans le sous-dossier app du dossier e05_app_layer : https://github.com/bcadiot/multi-cloud/tree/master/e05_app_layer/app.
Code applicatif
Le code JS modifié concerne principalement la faculté de l'application à servir Minio sur une interface externe et une interface interne :
var minio_external_host = process.env.MINIO_EXTERNAL_HOST || 'localhost'
var minio_external_port = process.env.MINIO_EXTERNAL_PORT || 9000
// Instantiate a minioClient Object with an endPoint, port & keys.
var minioClient = new Minio.Client({
endPoint: process.env.MINIO_HOST || 'localhost',
port: parseInt(process.env.MINIO_PORT, 10) || 9000,
secure: false,
accessKey: process.env.MINIO_ACCESS_KEY || 'AKIAIOSFODNN7EXAMPLE',
secretKey: process.env.MINIO_SECRET_KEY || 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY'
});
Import de données dans le stockage
Dans le dossier files/bucket, sont mises à disposition des images qui peuvent être utilisées pour alimenter le stockage.
Pour plus de simplicité il est possible d'utiliser le MinioClient depuis l'un des serveurs de l'infra. On notera qu'on utilise le nom DNS de la query précédemment mise en place :
wget https://dl.minio.io/client/mc/release/linux-amd64/mc
chmod +x mc
mc config host add myminio http://storage-object-minio.query.consul:9000 AKIAIOSFODNN7EXAMPLE wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Une fois les accès configurés, il faut créer le bucket et y copier les fichiers.
mc mb myminio/minio-store
mc cp files/bucket/*.png myminio/minio-store/
Enfin, il faut changer la policy par défaut pour autoriser la consultation publique.
mc policy public myminio/minio-store
Job Nomad
Puis, dans la définition du job Nomad nous renseignons les variables d'environnement qui seront consommées par l'application, ainsi que la connexion au load balancer interne Traefik :
task "player" {
driver = "docker"
config {
image = "bcadiot/minio-js-store-app:1.1"
port_map = {
app = 3000
}
}
env {
MINIO_EXTERNAL_HOST = "minio-test.example.com"
MINIO_EXTERNAL_PORT = 80
MINIO_HOST = "storage-object-minio.query.consul"
MINIO_PORT = 9000
MINIO_ACCESS_KEY = "AKIAIOSFODNN7EXAMPLE"
MINIO_SECRET_KEY = "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"
}
service {
port = "app"
tags = [
"traefik.frontend.rule=Host:app-test.example.com",
"traefik.tags=exposed"
]
}
}
À présent, nous pouvons déployer notre application et voir qu'elle est disponible à l'URL que nous avons indiquée !
Tests de résilience multi-cloud
Notre série d'articles touche à sa fin, nous avons déployé une application multi-cloud fonctionnelle. Cependant, il reste un dernier aspect à vérifier, sa capacité de résilience et de tolérance aux pannes.
Le moment est venu de provoquer des pannes et de voir le comportement de notre infrastructure !
Pour rappel notre infrastructure était la suivante :
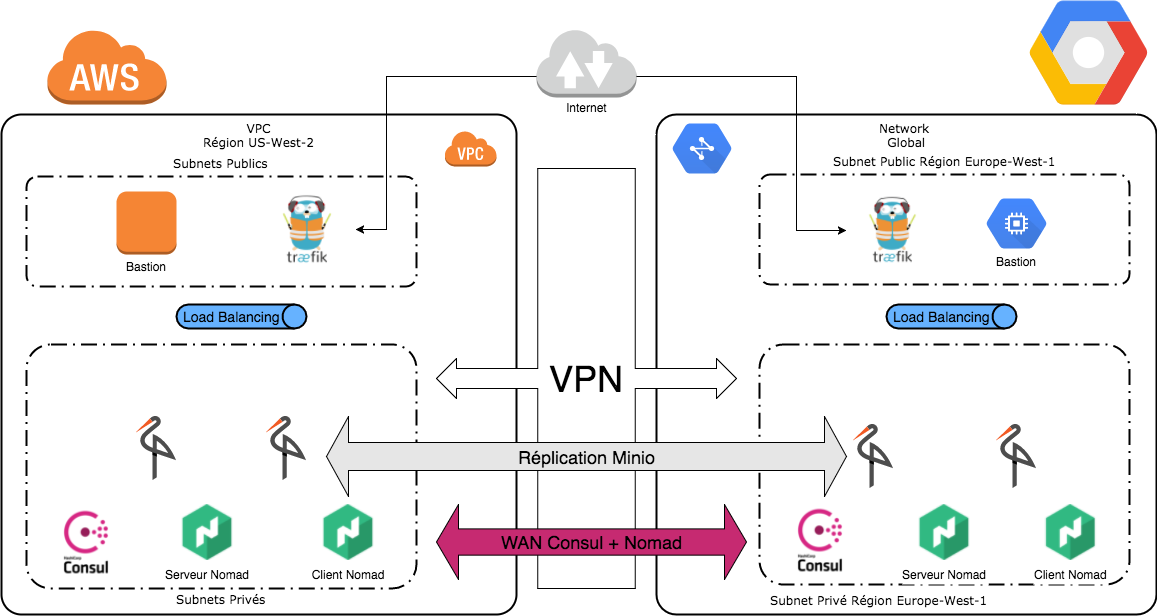
Panne des applications hébergées
Première étape, la panne tout en haut de la stack, la panne des applications hébergées. Pour nous, cela signifie la panne de notre application NodeJS et la panne du stockage distribué.
À noter que ces exemples supposent que les noeuds sont irrécupérables. S’il s'agit simplement d'un conteneur tué, alors l'orchestrateur de service tentera de le rallumer ou de le relocaliser ailleurs. Une fois le redéploiement effectué les données seront resynchronisées.
Erreur du stockage distribué
Il y a plusieurs scenarii à tester pour simuler la panne du stockage distribué Minio :
- Perte d'un noeud : Le nombre de noeuds passe de 4 à 3, cela n'impacte pas le service normal, il est toujours possible de lire et écrire sur le stockage.
- Perte de deux noeuds : Le nombre de noeuds passe de 4 à 2, cela n'impacte pas notre application car, par défaut, elle ne réalise que des lectures, en revanche il n'est plus possible de réaliser d'écritures.
- Perte de trois noeuds ou plus : Le nombre de noeuds passe de 4 à 1 voire 0, cela empêche les lectures également car le cluster n'est plus en capacité de garantir la cohérence.
Erreur applicative
En cas d'incident applicatif, il y a deux niveaux de protection, les répartiteurs locaux, et le répartiteur global :
- Perte d'une partie des conteneurs d'un cloud : Dans ce cas de figure l'annuaire de service via les tests de vie détecte la panne et se met à jour. Ce mécanisme permet aux répartiteurs locaux de modifier la liste des backends où adresser le service et de se reconfigurer à la volée. Cette étape est transparente et n'engendre pas de perturbations.
- Perte de la totalité des conteneurs d'un cloud : Si tous les conteneurs disparaissent, alors l'annuaire de service ne peut plus indiquer aux répartiteurs locaux une liste de services actifs. Dès lors, le répartiteur n'a plus la possibilité de rendre le service. Dans ce cas, le test de vie positionné au niveau répartiteur global renverra une erreur sur les répartiteurs locaux et cela provoquera la redirection du trafic sur l'autre cloud.
Panne du cluster de services
La seconde étape concerne les incidents au niveau du cluster de services, que ce soit pour le moteur d'exécution des conteneurs ou l'annuaire de services.
Perte des noeuds d'exécution Nomad
En cas de perte d'un des noeuds client Nomad, le cluster détectera que ce noeud ne répond plus aux tests de vie. Dès lors, le cluster Nomad va considérer que les services hébergés ne sont plus actifs et va prendre la décision de les relocaliser ailleurs si cela est possible.
Tant qu'il reste des noeuds d'exécution cela n'a pas d'impact sur le service, l'orchestrateur tentera toujours de relocaliser les services suivant les ressources matérielles disponibles.
En cas de perte de tous les noeuds, aucun conteneur ne pourra plus être démarré, et dans ce cas, les services ne seront plus actifs. L'ensemble du fournisseur de cloud sera désactivé au niveau répartiteur de charge global.
Perte des noeuds de gestion du cluster
Qu'il s'agisse des serveurs Consul ou des serveurs Nomad, le comportement sera strictement identique.
Perte d'un serveur du cluster : Les clusters sont formés à l'aide du protocole de consensus Raft. Grâce à ce protocole, le cluster reste actif tant qu'un quorum est toujours présent. Comme pour le cluster de stockage Minio, le quorum est de N/2+1, ce qui signifie que dans notre cas il est possible de tolérer la perte d'un serveur de chaque cluster. Cela n'a pas d'impact sur la vie de notre infrastructure car ces clusters sont des services commes les autres et l'annuaire de service sera mis à jour en conséquence.
Perte de plusieurs serveurs du cluster : En cas de perte de plusieurs, voire de la totalité des membres de chaque cluster, alors le service ne peut plus être rendu dans le datacenter, et cela se traduira par l'impossibilité d'exécuter la couche applicative, et donc la désactivation entière du fournisseur de cloud au niveau du répartiteur global.
Panne des composants d'infrastructure
La dernière partie à tester concerne les pannes pouvant survenir sur les éléments centraux de notre infrastructure.
Perte du lien intercloud
Le lien intercloud est composé de deux tunnels pour justement rester disponible en cas de panne de l'un d'eux. Si, malgré tout, les deux liens étaient coupés, cela aurait un impact relativement limité sur notre déploiement.
En effet, l'application actuellement déployée utilise le cluster de stockage en lecture uniquement, et les clusters de services peuvent fonctionner indépendamment.
Cela ne perturberait pas le service, et le répartiteur global pourrait continuer à distribuer le trafic sur les deux clouds.
Perte d'un fournisseur de cloud
En cas de perte de la totalité d'un fournisseur de cloud, ce dernier se retrouverait désactivé au niveau du répartiteur global et le trafic ne serait envoyé que sur celui restant. À propos du cluster de stockage il continuerait de fonctionner mais uniquement en lecture seule, plus aucune écriture ne serait possible.
Les clusters de services sont conçus pour fonctionner indépendamment et ne seront donc pas impactés.
Perte des load balancers locaux
Ces répartiteurs de charge locaux Traefik sont doublés afin de tolérer la panne de l'un d'entre eux :
- Perte d'un LB local : La perte d'un seul service a un impact très limité. Les tests de vie au niveau du répartiteur global tomberont en erreur sur cet équipement mais le second disponible reste accessible et tous les accès transiteront par lui.
- Perte des deux LB locaux : Dans ce cas, c'est l'ensemble du point d'accès du fournisseur de cloud qui se retrouve désactivé. La charge qui peut être encaissée sur notre fournisseur de cloud se retrouve limitée mais cela n'a pas d'impact au niveau du service. Le trafic est redirigé sur le second cloud, et le cluster de stockage reste actif en écriture, comme il existe toujours.
Perte du load balancer global
Pour terminer, le dernier composant est le répartiteur de charge global. La perte de ce composant serait critique car aucun système n'est prévu pour reprendre le rôle de ce service.
Cela renforce l'impératif d'être vigilant quant au niveau de service en choisissant le service de répartition de charge globale.
Conclusion
Notre série d'articles prend fin, le déploiement d'applications résilientes multi-cloud n'a plus de secret pour vous à présent.
L'ensemble du code est disponible sur https://github.com/bcadiot/multi-cloud.
Merci d'avoir suivi ces articles, et à bientôt pour de nouveaux sujets !
Si vous avez des questions n'hésitez pas dans les commentaires ou via twitter @bcadiot

