 Bastien Cadiot
Bastien Cadiot


Après un premier article sur la découverte des bases de Google Cloud et la création de notre compte, je vous invite maintenant à explorer la partie réseau.
L’infrastructure réseau de Google Cloud
Google Cloud bénéficie du réseau mondial utilisé par les autres services de Google, cela permet de construire notre propre infrastructure distribuée géographiquement. Afin de bien comprendre, nous allons séparer la vue globale de la vue régionale.
Globale
Plusieurs régions constituent l’infrastructure de Google Cloud, 15 à l’heure où ces lignes sont écrites et 19 d’ici fin 2018. Les régions sont interconnectées par un réseau privé et performant. Le détail du réseau de Google Cloud est visible sur la page dédiée de la documentation.
Durant le mois d'août 2017, Google a annoncé la séparation de la gestion du réseau entre deux offres : Premium et Standard. L’une utilise l’infrastructure globale du réseau Google Cloud pour relier utilisateurs et régions, l’autre utilise Internet pour atteindre la région de destination.

Le service est encore en Alpha, mais il est intéressant de commencer à réfléchir dès aujourd’hui à nos choix sur cet aspect. Sauf cas particulier, je conseillerais d’utiliser la solution Premium. Des premiers tests de performances ont été réalisés afin de vous donner une idée et d’aiguiller votre décision : GCP Networking Performance.
Régionale et zonale
Chaque région est composée de plusieurs zones correspondant à autant de datacenters distincts. La zone constitue la plus petite unité de disponibilité, cela signifie qui si l’on souhaite déployer en haute disponibilité, il est nécessaire de construire son infrastructure sur au moins deux zones. C’est justement ce que nous nous efforcerons de faire tout au long de nos déploiements !
Les régions permettent de déployer les services à proximité des utilisateurs, et garantissent une faible latence entre les zones.
Chaque zone offre des fonctionnalités qui lui sont propres et qu’il faut prendre en compte au moment du déploiement. Par exemple la région europe-west1-b permet d’ajouter des GPUs sur les serveurs alors que la zone soeur europe-west1-c ne le permet pas.
Pour plus de détails quant aux régions et aux services par zone la documentation dédiée est très complète.
Quels sont les services réseaux ?
La plateforme offre de nombreux services réseaux, l’idée ici n’est pas de tous les lister et de les expliciter mais plutôt de présenter un échantillon des plus importants pour construire notre infrastructure de base. Si vous voulez un focus supplémentaire sur certains services, n’hésitez pas à le demander dans les commentaires ou via twitter.
Les VPCs ou Networks
Lorsque votre projet a été créé, un réseau virtuel (ou VPC) a été provisionné par défaut. La particularité des réseaux sur GCP est la possibilité de créer un réseau global mondial et d’avoir des sous-réseaux dans chaque région. Ainsi, tous les serveurs déployés au sein d’une région disposent d’adresses IP dans le même sous-réseau, quelle que soit la zone de déploiement. La politique de routage du réseau global permet à tous les serveurs de communiquer directement entre eux à travers le monde, sans restrictions.
Deux modes existent pour la création de VPC :
- Le mode automatique va créer un sous-réseau sur chaque région suivant un plan d’adressage non modifiable. Ce mode suffit aux besoins classiques.
- Le mode personnalisé permet de choisir les sous-réseaux et les régions de déploiement. Par exemple, ci-après un VPC dans lequel plusieurs réseaux sont définis, mais où un seul est étiqueté “public” afin qu’une seule région serve de point d’entrée. Bien entendu le routage réel n'apparaît pas ci-dessous, il ne s’agit que de nommage.
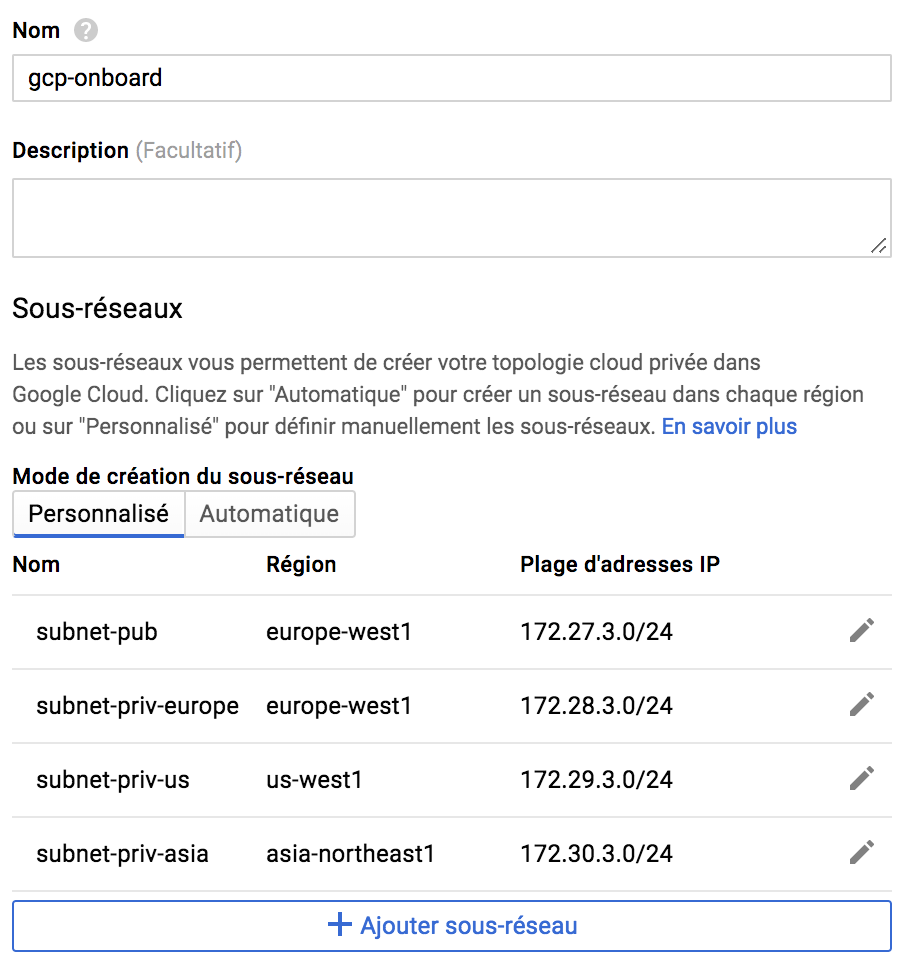
A vous de jouer maintenant sur la console GCloud pour créer vos propres réseaux. Il n’y a pas de facturation associée à la création de réseaux donc n’hésitez pas à tester et à créer plusieurs réseaux.
Adresses IP externes
Par défaut, nos services déployés n’ont que des adresses IP privées et ne sont donc pas accessibles de l'extérieur. Il est donc important de leur affecter des adresses IP externes pour qu’ils soient joignables depuis internet. Ces IP externes sont de deux types : éphémères ou statiques.
Les adresses éphémères sont par définition volatiles, elles sont prévues pour fournir un accès temporaire et où l’adresse elle-même n’a pas d’importance. Ce genre d’usage est typiquement adapté dans le cas de tests, ou lorsque nos services sont cachés derrière un répartiteur de charge. Notre premier article montrait la création d’un serveur virtuel utilisant justement une adresse éphémère.
Les adresses statiques sont quant à elles prévues pour durer dans le temps, on les utilise typiquement comme destination de serveurs VPN, ou comme cibles des répartiteurs de charge. Elles sont soit régionales, soit globales, en fonction de vos besoins.
Vous pouvez gérer les adresses statiques dans la console. Attention une adresse non utilisée est facturée.
Règles de pare-feu
La sécurité réseau des projets est gérée au niveau des règles de pare-feu du réseau VPC entier. Quelques règles par défaut sont proposées, mais il est possible (et même conseillé) d’écrire ses propres règles.
Les règles sont définies pour être mises en œuvre suivant les filtres appliqués au trafic. Il est possible de choisir de les filtrer suivant :
- L’adresse IP (ou réseau) source ou destination. C’est le comportement classique de n’importe quel pare-feu
- Un tag appliqué aux instances. Par exemple, il est possible de tagger des instances “app” et d’autres “db” et de n’autoriser le trafic sensible qu’entre ces deux tags.
- Enfin, il est possible d’attacher un compte de services aux instances et de filtrer le trafic entre comptes de services.
Bien entendu, les sources et cibles peuvent être mixées suivant ces 3 possibilités. Enfin, une notion de priorité s’applique pour hiérarchiser l’ordre d’utilisation des règles.
Essayez de vous connecter à la section pare-feu de la console, et d’ajouter une règle autorisant le trafic HTTP sur les instances ayant le tag “webapp”.
Hint : allow tcp:80 from net:0.0.0.0/0 to tag:webapp
Ensuite il vous suffira de créer une instance et de lui associer le tag webapp pour que le trafic HTTP soit autorisé depuis n’importe où.
Répartition de charge
Le dernier aspect réseau que j’aimerais aborder avec vous est la répartition de charge (ou load balancing). C’est un aspect complet et complexe d’une architecture cloud, nous allons en parler un peu mais nous l’aborderons plus en détail dans un prochain article.
Lorsque l’on parle de répartition de charge, il nous faut distinguer la charge externe (provenant d’internet) de la charge interne (entre les machines virtuelles), chacune offrant des possibilités différentes que nous allons étudier. Un élément important à noter est que les répartiteurs multi-région vont automatiquement distribuer le trafic des visiteurs vers la région la plus proche d’eux.
Trois types de répartiteurs de charge sont offerts :
- HTTP / HTTPS : Conçu uniquement pour le trafic externe vers nos instances. Ce type de répartiteur prend en charge la terminaison SSL et est particulièrement adapté à la distribution mondiale du trafic. En outre, il est possible de concevoir des architectures microservices en séparant le trafic selon le chemin HTTP (par exemple /profil peut diriger vers certaines instances, et /admin vers d’autres)
- TCP / SSL : Comme son nom l’indique ce répartiteur est conçu pour le trafic TCP en général, il est aussi bien adapté au trafic externe qu’interne. Il peut être distribué sur plusieurs régions pour les clients externes, mais se limite à une région pour le trafic inter VM.
- UDP : Ce dernier répartiteur s’adresse au trafic UDP, il peut être utilisé pour le trafic externe comme interne, néanmoins il ne peut s’utiliser que sur une unique région.
N’hésitez pas à aller jouer avec la console, nous créerons un répartiteur de charge lors d’un prochaine article dédié à la performance. Si vous créez un répartiteur, pensez bien à le supprimer après vos tests sinon il vous sera facturé.
Conclusion
La découverte du réseau est terminée, nous allons pouvoir avancer sur les étapes suivantes, restez connectés pour en apprendre plus ! Le code de nos exemples est disponible sur GitHub : https://github.com/bcadiot/gcp-from-scratch.
Vous avez des questions ? Vous voulez plus de détails ? N’hésitez pas dans les commentaires de l’article ou via Twitter.
À très vite pour la suite de notre découverte de Google Cloud. La prochaine étape sera consacrée à la performance et à la haute disponibilité.
Et la saga continue...
A lire et à relire, les articles de la saga "Google Cloud From Scratch".
-Episode 1 : "Commencer par la base"
-Episode 2 : "Parlons Réseau"

