

Flannel : les réseaux de conteneurs par CoreOS
Parmi les solutions de SDN existantes on trouve Flannel, de CoreOS. Cette solution est couramment utilisée de concert avec Kubernetes. Dans cet article, nous allons mettre en place un POC pour voir comment Flannel fonctionne et mettre en perspective ce fonctionnement avec la théorie relative au SDN et aux réseaux d’overlay.
Sommaire
Cet article est la suite de Les réseaux d’overlay, principes et fonctionnement et de SDN: principes et fonctionnement. Vous pouvez vous y référer pour éclaircir les notions exploitées ici (notamment les termes FDB, VTEP, VXLAN, etc.).
Qu’est ce que Flannel ?
Flannel est une solution réseau orientée conteneurs, open-source, issue de CoreOS (également à l’origine de la distribution du même nom, mais aussi de Etcd, Rkt, Clair, Tectonic…). La documentation du projet définit Flannel de la façon suivante : “Flannel is a simple and easy way to configure a layer 3 network fabric designed for Kubernetes.” On comprend donc que cela permet de mettre en place une fabrique l3 (un maillage de routeurs, censés permettre automatiquement à l’infrastructure de s’étendre) pour donner la possibilité à des conteneurs répartis sur plusieurs machines, spécifiquement s’ils sont orchestrés par Kubernetes, de communiquer. Flannel fournit également l’automatisation nécessaire pour mettre en place la configuration réseau sous-jacente, à savoir, soit par une couche d’encapsulation permettant la connectivité entre les machines hôtes au-dessus d’un réseau existant, soit par le pilotage directement de la solution réseau d’un cloud provider. Flannel fournit également une couche d’abstraction vis à vis de la technologie employée pour mettre en place ces réseaux. Ce projet peut être affilié aux solutions de SDN, puisqu’il propose :
- d’automatiser les configurations réseau nécessaires à de nombreux pods (dans Kubernetes) et conteneurs, pour communiquer
- de mutualiser des données nécessaires aux différents éléments du réseau, ici les hôtes des pods et conteneurs
La mutualisation de ces données nécessaires à la configuration des agents s’effectue grâce à un registre clef:valeur. Flannel s’appuie sur Etcd (surprise !) pour ce faire. Chaque démon Flannel, installé sur les machines hôtes, contacte le cluster Etcd, pour récupérer la configuration du réseau. L’agent effectue alors la configuration adéquate sur la machine hôte, en fonction des paramètres reçus.
Flannel propose plusieurs “backends”. Un backend est une implémentation choisie pour le plan de données (data plane). Le backend principal recommandé est VXLAN (voir l’article sur les réseaux d’Overlay), c’est celui que nous utiliserons dans cette démonstration. Parmi les autres backends, on peut citer :
- AWS VPC
- GCE
- AliVPC
- IPIP
Flannel permet donc également de piloter vos réseaux sur AWS, GCP et AliCloud, ce qui offre des perspectives intéressantes (j’en parlerais peut être dans un prochain article). IPIP (RFC1853) est un protocole d’encapsulation, au même titre que VXLAN. Il est à noter que ces backends sont marqués “non recommandés” dans la documentation de Flannel et ne sont donc pas (encore ?) prêts pour de la production.
Architecture cible
L’architecture du POC est la même que dans l’article sur les réseaux d’Overlay. Nous utiliserons trois machines virtuelles dans le même réseau local, dans le sous réseau 10.0.0.0/24 (test porte la 10.0.0.2, test2 la 10.0.0.3 et test3 la 10.0.0.4). Le choix de ce subnet n’est pas obligatoire mais si vous en changez, veillez à choisir un réseau différent au niveau de la configuration saisie dans Etcd, pour éviter de créer des doublons au niveau des entrées de la table de routage des machines hôtes (et potentiellement perdre l’accès aux machines elles-mêmes :) ). Nous aurons besoin d’un cluster Etcd pour partager les données de configuration entre toutes les machines et d’un démon flanneld par machine. Les machines virtuelles sont lancées sur un hyperviseur libvirt/KVM local, mais vous pourriez très bien mettre en place la même architecture chez votre cloud provider préféré. Les machines utilisées ici sont installées en debian 9.
Nous allons donc configurer une architecture Flannel, dont le plan de données reposera sur VXLAN. Le plan de contrôle est assez basique, en ce sens qu’il consiste uniquement en un partage de données grâce à Etcd. Il n’y a pas de véritable intelligence de ce côté là. Le peu de traitement effectué à partir de ces données est fait par les agents Flannel. Nous verrons en quoi il consiste.
POC
Toutes les configurations présentées ici ont été écrites dans le cadre d’une expérimentation. Elles ne sont pas prêtes pour de la production.
Déploiement du cluster Etcd
Cet article n’est pas axé sur Etcd, donc j’ai souhaité factoriser l’installation du cluster dans un playbook Ansible pour pouvoir se concentrer sur la suite. Vous pourrez retrouver ce playbook ici.
Une fois l’installation effectuée, le cluster devrait être opérationnel. Pour le vérifier, entrez les commandes suivantes :
root@test2:~# **etcdctl cluster-health**
member aeb6950c050a83f3 is healthy: got healthy result from http://10.0.0.4:2379
member ee274cacce804b21 is healthy: got healthy result from http://10.0.0.2:2379
member fe9c64eaf3991d47 is healthy: got healthy result from http://10.0.0.3:2379
**cluster is healthy**
Le message de retour devrait être explicite.
Déploiement des agents Flannel
Toujours pour simplifier la mise en place et raccourcir cet article, nous allons légèrement tricher. Nous déployons ici un cluster de trois noeuds Etcd… sur trois machines au total. Nous verrons que les agents Flannel sont configurés par défaut pour discuter avec une instance Etcd locale sur localhost:2379. De ce fait, nos trois agents Flannel pourront discuter directement avec le cluster Etcd sans configuration supplémentaire. Pour permettre à un agent Flannel de discuter avec le cluster Etcd depuis d’autres machines, il faut utiliser l’option -etcd-endpoints de flanneld.
Une fois de plus, les étapes de configuration présentées ici sont également applicables à l’aide d’un playbook Ansible présent ici. Nous allons tout de même les détailler comme si elles étaient effectuées à la main, pour comprendre le déroulement.
Installation de Flannel
Commençons par télécharger Flannel :
wget https://github.com/coreos/flannel/releases/download/v0.6.2/flanneld-amd64 -O /usr/local/bin/flanneld
chmod 700 /usr/local/bin/flanneld
A ce stade, nous devrions pouvoir utiliser l’exécutable puisque nous l’avons placé dans un dossier faisant partie du PATH par défaut :
flanneld --version
v0.6.2
Histoire d’être reboot proof, créons un service systemd pour Flannel. Plaçons le fichier flanneld.service suivant, dans /lib/systemd/system :
[Unit]
Description=Flanneld networking service
Documentation=flanneld --help
[Service]
ExecStart=/usr/local/bin/flanneld -iface=ADRESSE_IP_DE_ETH0
ExecStop=/usr/bin/killall flanneld
[Install]
WantedBy=sysinit.target
Pensez à remplacer l’adresse IP par celle de l’interface eth0 de la machine courante (dans mon cas, 10.0.0.2 pour test, 10.0.0.3 pour test2, 10.0.0.4 pour test3).
On demande alors à systemd de prendre en compte le nouveau service, mais il ne faut pas le démarrer tout de suite, puisque la configuration n’est pas encore écrite dans Etcd :
systemctl daemon-reload
systemctl enable flanneld
Placement de la configuration dans Etcd
Il nous faut écrire la configuration destinée aux agents Flannel. Depuis n’importe laquelle de nos trois machines (puisque chacune héberge un noeud du cluster Etcd), écrire le fichier flannel-network.json suivant :
{
"Network": "192.168.0.0/16",
"SubnetLen": 24,
"SubnetMin": "192.168.0.0",
"SubnetMax": "192.168.5.0",
"Backend": {
"Type": "vxlan",
"VNI": 100,
"Port": 8472
}
}
Analysons rapidement le contenu de la configuration :
- le champ Network définit le sous-réseau global, que l’ensemble des démons Flannel auront le droit d’utiliser
- SubnetLen définit la taille du sous-réseau que chaque démon aura le droit de s’attribuer
- SubnetMin et SubnetMax définissent respectivement l’adresse de réseau du premier sous-réseau allouable par un démon et celle du dernier réseau (tout en respectant la taille du masque de sous-réseau définit par SubnetLen).
Le second bloc de configuration définit le backend utilisé par Flannel. Comme nous l’avons expliqué, Flannel propose plusieurs backends mais met principalement en avant le backend VXLAN, qui utilise le protocole d’encapsulation du même nom (voir le premier article de cette série). On définit également dans ce bloc le numéro de VNI (Virtual Network Identifier) qui permet d’identifier les différents tunnels VXLAN montés par une même machine. Dans cet article nous n'utilisons que l’ID 100, pour les trois tunnels vxlan. Je dis trois, car Flannel monte des tunnels VXLAN en unicast. Ceci signifie qu’il contacte directement l’adresse IP de la VTEP distante pour transmettre les paquets encapsulés. Nous avons trois machines, donc trois tunnels potentiels. L’option port définit le numéro de port UDP utilisé par la VTEP pour monter les tunnels VXLAN.
Entrons maintenant la configuration dans Etcd, au niveau de la clef /coreos.com/network/config (clef lue par défaut par flannel) :
etcdctl set /coreos.com/network/config < flannel-network.json
Vous devriez pouvoir lire cette configuration depuis tous les membres du cluster Etcd (depuis chaque machine, en local) :
etcdctl get /coreos.com/network/config
On peut alors démarrer le service Flannel :
systemctl start flanneld
A ce stade, nous devrions pouvoir voir les sous-réseaux réservés par les machines hôtes, depuis Etcd :
root@test2:~# etcdctl ls /coreos.com/network/subnets/
/coreos.com/network/subnets/192.168.0.0-24
/coreos.com/network/subnets/192.168.4.0-24
/coreos.com/network/subnets/192.168.5.0-24
On voit que les sous-réseaux utilisés sont 192.168.0.0/24, 192.168.4.0/24, 192.168.5.0/24. Si on regarde le contenu d’une de ces clefs :
root@test2:~# etcdctl get /coreos.com/network/subnets/192.168.4.0-24
{"PublicIP":"10.0.0.3","BackendType":"vxlan","BackendData":{"VtepMAC":"6e:af:8f:41:72:26"}}
On voit ici les données qui serviront à remplir la FDB de chaque VTEP. Pour rappel, la FDB ou Forwarding DataBase est la table contenant les entrées de correspondance: adresse mac distante - adresse IP de la VTEP responsable de cette adresse MAC.
Vérifions l’état du service :
systemctl status flanneld
Nous devrions maintenant voir les entrées correspondantes aux machines alentours dans la FDB (issues des valeurs présentes dans Etcd), exemple sur test2 :
bridge fdb show
**02:b7:12:89:ca:6a** dev **flannel.100** dst **10.0.0.2** self permanent
**2e:ed:91:21:92:fe** dev **flannel.100** dst **10.0.0.4** self permanent
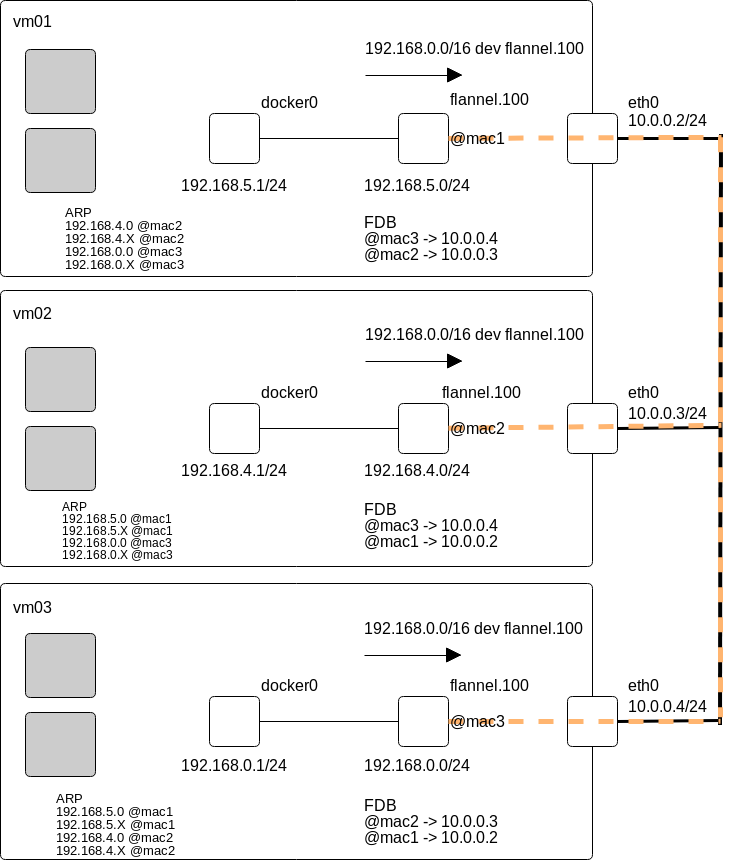
On voit donc que le démon Flannel renseigne, dans la FDB, l’adresse MAC de chaque machine hébergeant un agent Flannel. Ceci est lié au fonctionnement de VXLAN. Les tunnels sont donc maintenant opérationnels, ce qui signifie que nous disposons de réseaux de niveau 2 (virtuels) dédiés entre chaque machine.
Comme expliqué en introduction, Flannel configure également le routage nécessaire à la communication entre les machines et les conteneurs. Nous pouvons le voir dans la table de routage de la machine hôte :
root@test:~# ip r
default via 10.0.0.1 dev eth0 onlink
10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.2
**192.168.0.0/16 dev flannel.100**
...
Nous constatons que le routage configuré par Flannel se résume à une route concernant tout le réseau Network spécifié dans Etcd. Tout le trafic à destination de ce réseau passe par l’interface flannel.100. De cette manière, tout le trafic en question est encapsulé. Comme décrit dans l’article sur les réseaux d’overlay, les VTEP ont besoin de connaître les adresses MAC présentes derrières les autres VTEP. Nous avons vu que nous disposons d’une entrée permanente dans FDB, comprenant l’adresse MAC de chacune des VTEP distantes. La configuration de l’interface flannel.100 peut nous interpeller, puisqu’elle porte l’adresse de réseau du sous-réseau choisi par le démon :
5: flannel.100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 16:19:49:a0:af:b0 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.0/16 scope global flannel.100
valid_lft forever preferred_lft forever
inet6 fe80::1419:49ff:fea0:afb0/64 scope link
valid_lft forever preferred_lft forever
Comment une VTEP fait alors pour savoir comment joindre une adresse IP située derrière une autre VTEP ? La réponse est simple, Flannel se repose sur le protocole ARP. Après avoir raccordé des conteneurs à notre installation, nous regarderons la table ARP des machines hôtes, pour mettre en évidence ce fonctionnement.
Raccordement de conteneurs
Nous allons maintenant configurer le démon Docker pour permettre aux conteneurs de discuter les uns avec les autres par l’intermédiaire de Flannel.
Le démon Flannel interprète la configuration lue depuis Etcd et en déduit le sous-réseau qu’il doit utiliser. Cette information est stockée dans /run/flannel/subnet.env. Nous allons donc récupérer ces données de configuration et s’en servir pour configurer le démon Docker :
source /run/flannel/subnet.env
systemctl stop docker
ip addr flush docker0
ip addr add $FLANNEL_SUBNET dev docker0
/usr/bin/dockerd --bip=$FLANNEL_SUBNET --mtu=$FLANNEL_MTU &
Vérifions que le service fonctionne bien et que la configuration est correcte. Nous devrions avoir deux bridges sur chaque machine : flannel.100 et docker0. flannel.100 doit porter l’adresse de réseau que flanneld a choisi (/24), docker0 doit porter l’adresse de passerelle (en .1).
Il est nécessaire d’ouvrir les flux au niveau de la table forward iptables, si ceci n’est pas fait. Ceci permet au trafic de passer par le bridge flannel.100 (qui fait aussi office de routeur). Dans le cadre de cet article nous changerons simplement la police par défaut, dans un contexte de production, il convient d’appliquer des règles plus fines.
iptables -P FORWARD ACCEPT
Une fois ceci fait, nous devrions être en mesure de joindre les bridges Docker de chaque machine. Comme nous l’avons vu, ceci est permis par la route globale présente dans la table de routage de l’hôte, pour tout le sous réseau renseigné dans Etcd :
192.168.0.0/16 dev flannel.100
flanneld doit, de son côté, encapsuler les paquets qui passent par cette interface, en direction des autres machines. Essayons.
Voici les bridges Docker de chacune des machines de mon installation :
root@test:~# ip a s docker0
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:a5:67:bb:5e brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 brd 192.168.5.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:a5ff:fe67:bb5e/64 scope link
valid_lft forever preferred_lft forever
root@test2:~# ip a s docker0
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:f6:d7:c8:c1 brd ff:ff:ff:ff:ff:ff
inet 192.168.4.1/24 brd 192.168.4.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:f6ff:fed7:c8c1/64 scope link
valid_lft forever preferred_lft forever
root@test3:~# ip a s docker0
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:49:58:ef:9d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 brd 192.168.0.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:49ff:fe58:ef9d/64 scope link
valid_lft forever preferred_lft forever
Depuis test2, je devrais pouvoir joindre 192.168.5.1 et 192.168.0.1 :
root@test2:~# ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
64 bytes from 192.168.5.1: icmp_seq=1 ttl=64 time=1.60 ms
root@test2:~# ping 192.168.0.1
PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data.
64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.591 ms
Notre installation semble fonctionnelle, voyons maintenant ce qu’il en est en lançant des conteneurs, sur les trois machines. Exemple sur test2 :
root@test2:~# docker run -d --name test busybox sh -c "while true; do sleep 3600; done"
95ce2afa2d60a43162519c7b9ff46e6b39f2c79c790aac5b27420d4b790cf703
root@test2:~# docker exec test ip a s eth0
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:c0:a8:04:02 brd ff:ff:ff:ff:ff:ff
inet 192.168.4.2/24 scope global eth0
valid_lft forever preferred_lft forever
Le conteneur a bien récupéré une adresse ip dans le sous-réseau réservé par l’agent Flannel local. Il doit être en mesure de joindre les autres conteneurs :
root@test2:~# docker exec test ping 192.168.5.2
PING 192.168.5.2 (192.168.5.2): 56 data bytes
64 bytes from 192.168.5.2: seq=0 ttl=62 time=1.153 ms
64 bytes from 192.168.5.2: seq=1 ttl=62 time=0.942 ms
root@test2:~# docker exec test ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
64 bytes from 192.168.0.2: seq=0 ttl=62 time=3.027 ms
64 bytes from 192.168.0.2: seq=1 ttl=62 time=2.255 ms
Regardons ce qui se passe sous le capot, depuis l’hôte test2 :
root@test2:~# tcpdump -i eth0 -n udp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:23:05.291422 IP 10.0.0.3.38897 > 10.0.0.4.8472: OTV, flags [I] (0x08), overlay 0, instance 100
IP 192.168.4.0 > 192.168.0.2: ICMP echo request, id 4608, seq 142, length 64
00:23:05.292505 IP 10.0.0.4.58880 > 10.0.0.3.8472: OTV, flags [I] (0x08), overlay 0, instance 100
IP **192.168.0.2** > **192.168.4.0**: **ICMP** echo reply, id 4608, seq 142, length 64
00:23:05.419922 IP **10.0.0.3**.40116 > **10.0.0.2**.8472: OTV, flags [I] (0x08), **overlay** 0, instance **100**
Nous pouvons voir les paquets ICMP encapsulés dans les datagrammes UDP du tunnel VXLAN, portant l’ID 100.
Il nous reste maintenant à regarder les tables ARP des machines, comme expliqué dans la section précédente. Exemple sur test3 :
root@test3:~# arp -a
**? (192.168.5.0) at 16:19:49:a0:af:b0 [ether] on flannel.100**
? (192.168.5.2) at 16:19:49:a0:af:b0 [ether] on flannel.100
**? (192.168.4.0) at 6e:af:8f:41:72:26 [ether] on flannel.100**
? (192.168.4.2) at 6e:af:8f:41:72:26 [ether] on flannel.100
? (192.168.5.1) at 16:19:49:a0:af:b0 [ether] on flannel.100
? (192.168.0.2) at 02:42:c0:a8:00:02 [ether] on docker0
…
Récapitulons : la VTEP (le démon Flannel) de test3 sait comment joindre les VTEP de test2 et test et les adresses MAC des interfaces flannel.100 sur ces machines, grâce aux entrées correspondantes dans la FDB. test3 dispose d’une route à destination du réseau global /16, passant par l’interface flannel.100. L’interface flannel.100 encapsule tout le trafic sortant (et désencapsule le trafic entrant).
Du point de vue de la machine source, il suffit de lire la table de routage, soit envoyer tout le trafic à destination du réseau en /16 en passant par flannel.100. A ce niveau, les entrées dans la table ARP nous montrent que toutes les adresses IP d’un même sous-réseau (et donc d’un même hôte distant) sont référencées avec l’adresse MAC de l’interface flannel.100 correspondante. Exemple depuis test3 (16:19:49:a0:af:b0 est l’adresse MAC de flannel.100 sur test).
root@test3:~# arp -a
? (**192.168.5.0**) at **16:19:49:a0:af:b0** [ether] on flannel.100
? (**192.168.5.2**) at **16:19:49:a0:af:b0** [ether] on flannel.100
? (10.0.0.2) at 52:54:00:b1:ec:ff [ether] on eth0
? (192.168.4.0) at 6e:af:8f:41:72:26 [ether] on flannel.100
? (192.168.4.2) at 6e:af:8f:41:72:26 [ether] on flannel.100
? (**192.168.5.1**) at **16:19:49:a0:af:b0** [ether] on flannel.100
? (192.168.0.2) at 02:42:c0:a8:00:02 [ether] on docker0
? (10.0.0.3) at 52:54:00:43:ad:c9 [ether] on eth0
? (10.0.0.1) at 62:39:3e:aa:41:be [ether] on eth0
La correspondance est ensuite faite avec la FDB, qui dit à quelle adresse IP de VTEP il faut envoyer les paquets encapsulés pour pouvoir joindre cette adresse MAC. Flannel prend ensuite le relai sur l’hôte de destination pour distribuer les paquets au conteneur ou à l’interface concernée. Le schéma ci-dessous résume les informations que nous avons mis en évidence dans cet article (les tirets oranges représentent les tunnels VXLAN) :
Conclusion
Flannel est une solution réseau qui applique les principes du SDN de la manière la plus simple. Le control plane se résume à un ensemble de services de stockage en mode clef:valeur avec Etcd et des actions de configuration basiques exécutées sur les agents/démons. Le data plane fournit une couche d’abstraction au-dessus de plusieurs backends. Il est possible d’encapsuler le trafic avec VXLAN, pour être agnostique à l’infrastructure sous-jacente, ou bien de piloter directement les VPC GCP ou AWS si vous déployez la solution sur un de ces cloud providers. Cette dernière partie est à mon sens le point fort de Flannel. La simplicité du control plane indique clairement que cette solution est faite pour être pilotée par une autre solution, plus évoluée sur ce point. Ceci peut être le cas lorsque Kubernetes contrôle Flannel directement. Une autre solution consiste à coupler Flannel avec une autre solution réseau disposant de plus de fonctionnalités avancées en terme de contrôle, mais aussi de routage, de firewalling, etc. Cette tendance est à l’origine du rapprochement entre Flannel et le projet Calico, qui a donné le projet Canal. Nous étudierons Calico et Canal dans un prochain article.
En pratique, Flannel n’est pas limité à la mise en place de réseaux de conteneurs. Outre le manque de fonctionnalités de sécurité ou de control plane, son fonctionnement est suffisamment générique pour s’en servir pour connecter des machine virtuelles au-dessus d’un réseau existant. Son utilisation en pilotant les VPC des différents cloud providers est également intéressante. Il est également possible de créer son propre backend. Imaginez demander à Flannel de provisionner automatiquement des tunnels VPN entre vos machines…
Sources



