Mise en place de AWS EMR
EMR ou Elastic MapReduce, est un service managé par AWS agissant comme une boîte à outils, qui vous permet de lancer facilement une plateforme de Big...
7 minutes de lecture
Il existe aujourd'hui trois players importants dans le domaine des cloud providers : AWS, GCP & Azure. C'est sur ce dernier que nous allons appliquer notre stratégie d'automatisation. Ayant une philosophie DevOps et un fort engouement pour les technologies open source, je décide avec mon équipe d'utiliser notre boîte à outils habituelle pour relever ce challenge. Celle-ci permet de réaliser l'automatisation de construction d'une application Cloud native tout en répondant aux contraintes et aux besoins de notre client, à savoir réversibilité et agnocité. Pour rappel, Azure est en passe de devenir un acteur incontournable puisque de récentes études le placeraient en tête des plus grands bénéfices pour cette année 2018. Une très belle croissance qui sera confirmée (ou pas) d'ici quelques semaines.
Attention esprit troller, nous allons ici parler du vilain méchant Windows du Cloud et vous démontrer à travers ce retour d'expérience (simplifié) une plutôt bonne surprise à nos yeux : ça fonctionne ! De toute façon, ils ont tous leurs points de faiblesse : Google Cloud vole mes données !! Et AWS est un concurrent sur le Retail !! Bref, allons au delà de ces clichés et apprenons à être objectif.
Je vais vous présenter la démarche que nous avons adoptée pour automatiser la construction d'une application full Cloud native, le tout inscrit dans un mindset Devops.
Dans le cadre de cet article j’ai pris le parti de simplifier l’architecture tout en faisant en sorte qu’elle soit représentative. J’ai choisi de présenter une application de type gestion des tâches, souvent connue sous le nom de todolist.
L’architecture des services de cette application est la suivante :
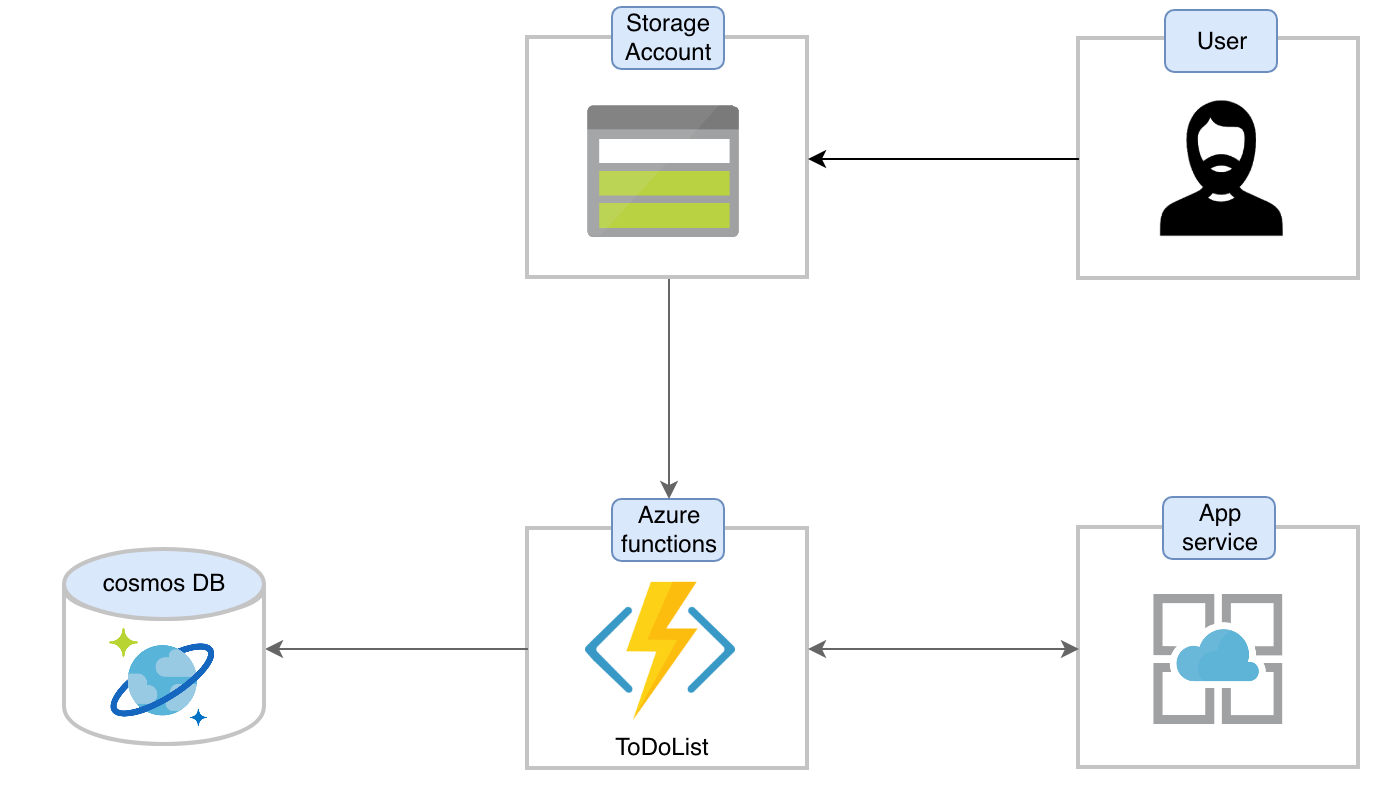
Les Azure functions permettent d'exécuter du code dans un environnement serverless sans avoir à créer au préalable une VM ou à publier une application Web. Les Azure functions nécessitent des App services pour héberger leurs exécutions.
De manière classique, le projet est déployé sur trois environnements, j'ai décidé de :
Prendre ce parti me permet de maintenir une cohérence dans l'infrastructure déployée sur les différents environnements. Cela évite aussi la duplication de code et limites les erreurs. Le “switch” d’un environnement à un autre se fera via l’utilisation de fichiers de variables.
Voici comment s’organise notre dossier Terraform, (le code source est dans le repo github Anteraz) :
├── main.tf #Provisioning des ressources
├── variables.tf #Déclaration des variables
├── output.tf #Déclaration des informations à recueillir
├── prod
│ ├── backend.tfvars #Configuration de backend prod env
│ └── env.tfvars #Variables spécifiques prod env
├── uat
│ ├── backend.tfvars #Je pense
│ └── env.tfvars #que vous
├── dev
│ ├── backend.tfvars #avez compris
│ └── env.tfvars #le principe :)
Nous avons également un “resource_group” de management qui va héberger nos tfstates. Il est réservé aux ressources qui nécessitent un accès à plusieurs ou tous les autres environnements, tel un Bastion/Jumpbox par exemple.
Pour relever les challenges mentionnés en préambule, nous avons fait le choix de technologies de gestion de configuration et d’infrastructure as code (IaC) orientées Open source et non dépendantes d’un fournisseur particulier : respectivement Ansible et Terraform. A noter que depuis la version 2.5, Ansible met à disposition un module Terraform pour gérer les “plan” et les déploiements, ce qui nous autorise un dialogue fluide entre les deux solutions. Il s’agit d’un point important pour la stratégie que nous avons adoptée.
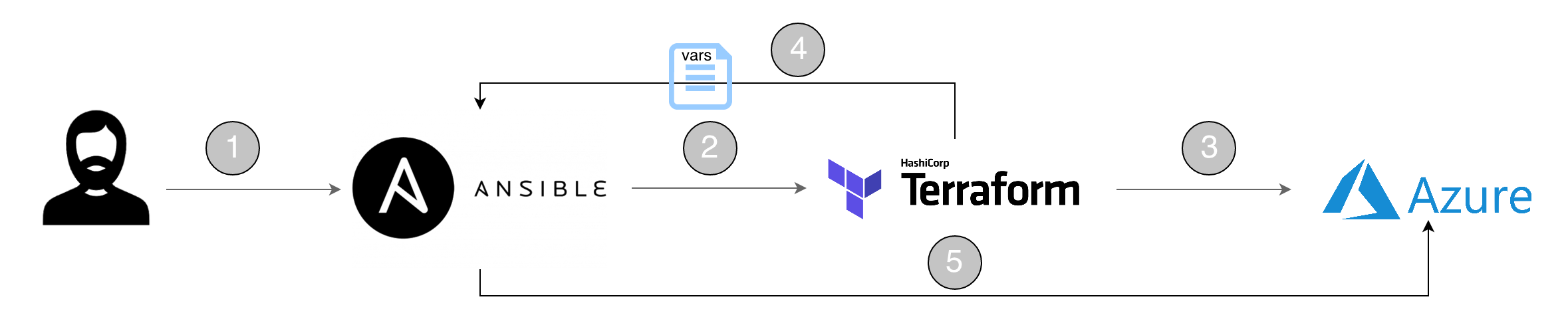
Plus précisément, les outils utilisés sont les suivants :
Dans notre playbook Ansible, nous faisons appel au module Terraform pour la construction des ressources de base (comprendre les services). Terraform nous fournit les informations des ressources créées en sortie d’exécution. Ensuite nous pouvons, soit directement passer ces informations à des variables qui serviront à la configuration des ressources dans la suite du playbook, soit construire un fichier de variables. Enfin nous sauvegardons nos fichiers tfstates dans notre Storage account.
Ainsi, l’appel de déploiement Terraform se présente sous cette forme :
- name: Terraform edit
terraform:
project_path: “”
variables:
resource_group_name:
env:
state: “”
register: outputs_tf
- name: Getting terraform outputs
set_fact:
var1: ""
var2: ""
Les variables d’environnement définies ci-dessus seront passées au moment de l’exécution. Pour l’environnement de PROD, on aura par exemple :
$ ansible-playbook deploy.yml -e "env=prod state=present"
Cette commande va appliquer le playbook “deploy.yml” :
env=prod : pour par exemple sélectionner l’environnement de productionstate=present : pour créer (identique à la commande “terraform apply”)Nous avons pris le parti de stocker nos fichiers “tfstates” directement chez notre fournisseur. Il s’agit d’un mode de configuration de l’outil nommé “remote backend”. Celui-ci présente plusieurs avantages dont les principaux sont :
Vous pouvez soit :
resource "azurerm_resource_group" "anterazmgnt" {
name = "anterazmgntrg"
location = "westeurope"
}
resource "azurerm_storage_account" "anterazmgnt" {
name = "anterazmgntstorageaccount"
resource_group_name = "${azurerm_resource_group.anterazmgnt.name}"
location = "westeurope"
account_tier = "Standard"
account_replication_type = "LRS"
tags {
environment = "staging"
}
}
resource "azurerm_storage_container" "anterazmgnt" {
name = "anterazmgntvhds"
resource_group_name = "${azurerm_resource_group.anterazmgnt.name}"
storage_account_name = "${azurerm_storage_account.anterazmgnt.name}"
container_access_type = "private"
}
Dans la souscription Azure, créer un compte Azure Storage Account, et dans le service blob, créer un conteneur.
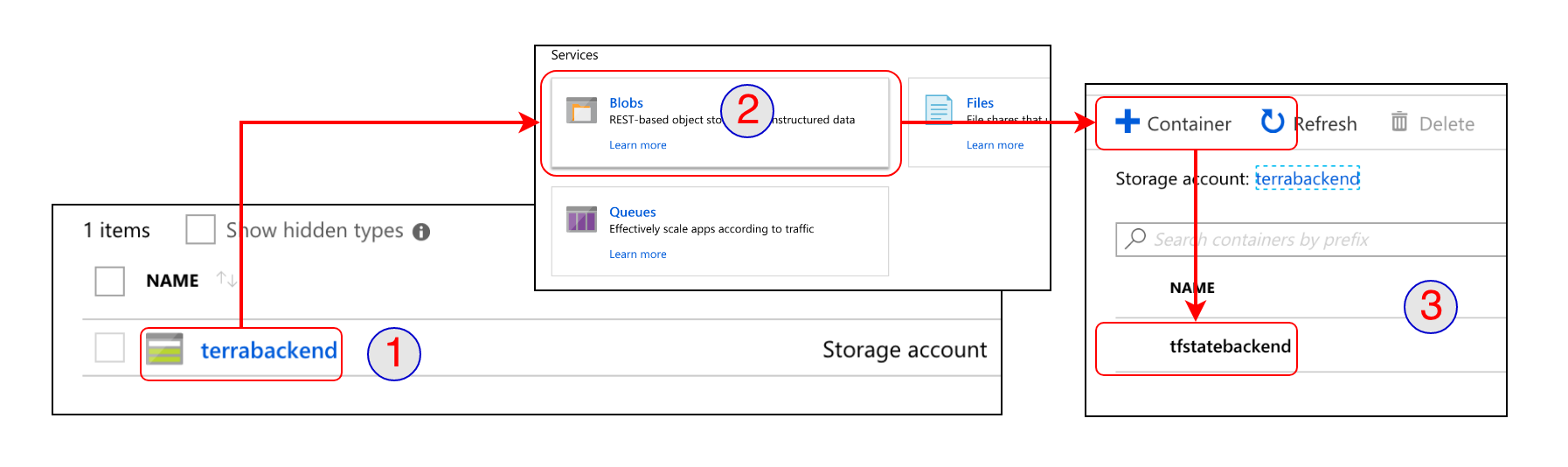
Pour configurer notre remote backend, nous ajoutons tout simplement les lignes suivantes au début de notre fichier principal Terraform :
#main.tf
terraform {
backend "azurerm" {
}
}
Nous créons un fichier pour les paramètres de configuration du backendbackend.tfvars :
resource_group_name = "***"
storage_account_name = "***"
container_name = "***" # Le nom du conteneur créé ci-dessus
access_key = "***" # Storage account key
key = "path/terraform.tfstate" # L’arborescence définie dans “path” sera créée à l’exécution
Ce fichier sera passé en paramètre lors de l’initialisation du dossier Terraform.
$ terraform init -backend-config=path/backend.tfvars
Dans notre organisation, nous avons décidé d’appeler cette configuration depuis Ansible.
J’ai également confronté mon système à des enjeux de sécurité. Je vais m’attarder sur deux principaux aspects :
Il s’agit ici de prouver sa propre légitimité à exploiter une ressource. La méthode d’authentification peut varier en fonction du niveau d’action. Par exemple, la création d’une ressource (Cosmos, Search, vm, etc.) nécessite un système d’authentification par token, généré à base du secret azure_tenant.
Par contre, pour effectuer des opérations à l’intérieur d’une ressource existante, il faut récupérer ses “access_key” ou “keys” ou “*_key” (enfin, vous voyez), pour ensuite parfois construire un token spécifique.
Les éléments clés sont l’”azure_client_id” et ’”azure_client_secret”. Ce sont des informations rattachées à une souscription Azure. Le principe est de construire une requête http dans laquelle nous incluons ces informations. Le résultat contient un token que nous passerons en paramètre (Authentification : bearer ) en header de tous les appels à l’API Rest Azure.
Ici, l’élément important est la “primary_key”. C’est un attribut généré automatiquement lors de la création de la CosmosDb. Le principe consiste à créer un token, mais cette fois-ci à partir d’un script. Nous avons choisi de le réaliser via Python parce que ce langage fait déjà partie de notre écosystème de développement.
#script token pour db
import hmac
import hashlib
import base64
from datetime import datetime
import urllib
import sys
key = sys.argv[1]
now = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:00 GMT')
payload = ('post\ndbs\n\n' + now + '\n\n').lower()
payload = bytes(payload).encode('utf-8')
key = base64.b64decode(key.encode('utf-8'))
signature = base64.b64encode(hmac.new(key, msg = payload, digestmod = hashlib.sha256).digest()).decode()
authStr = urllib.quote('type=master&ver=1.0&sig={}'.format(signature))
print authStr+";"+(now).lower()
Il est important de manipuler les informations d’authentification de façon sécurisée. En effet, pour implémenter les techniques d’authentification mentionnées au point précédent, les secrets doivent généralement être passés en paramètre. Ansible-vault nous permet de ne pas écrire en clair les secrets dans notre playbook. Il suffit de les encrypter avec un mot de passe choisi. Ce mot de passe sera passé en paramètre lors de l’exécution du playbook.
(voir Repo/playbook/vars)
Derrière cet article, je n'ai pas voulu vous présenter une solution complète et clé en main mais plutôt vous faire un retour d'expérience concernant la stratégie que j'ai pu mettre en place avec mon équipe. Ce principe remporte l'adhésion de l'équipe de part sa simplicité et son efficacité. Terraform se trouve exactement à la place pour laquelle il est efficace, à savoir la construction d'infrastructure et Ansible dans son rôle de gestion de configuration. Il prend la main pour lancer les exécutions et compléter les configurations qui ne sont pas disponibles à travers le provider AzureRM de Terraform.
A ce titre, j'ai deux remarques concernant ce provider : premièrement il est loin d'être aussi complet que celui pour AWS par exemple. Notamment dans la création de ressources, plusieurs configurations ne sont pas encore supportées, il faut prendre la main via une task Ansible qui sollicitera l’API Azure.. Pour les configurations supportées via Terraform, plusieurs informations ne sont pas disponibles en attributs de référence ( c’est à dire exportables via un output.tf). c’est le cas par exemple des keys d'un Search service. Ce provider a néanmoins le mérite d'exister.
Github (récemment acquis par Microsoft) ressort beaucoup de discussions sur des demandes d'évolutions de telle ou telle ressource, ce qui présage d'un dynamisme certain. Deuxièmement, j'ai pris le parti de ne pas solliciter de template ARM à travers les scripts Terraform car la lisibilité s'en retrouve grandement réduite (c'est une autre syntaxe différente du HCL hashicorp configuration language). Cela ajoutait aussi une troisième compétence à posséder pour maintenir ensuite l'automatisation de la plateforme.
En ce qui concerne l’interaction Azure avec Ansible, celle-ci s’avère simple même si parfois la documentation de l'API Rest Azure présente quelques zones d'ombre. Elle couvre quasiment l'ensemble de ce que vous pouvez faire via le portail ou via la CLI. On notera aussi un effort important de la part de Microsoft sur l'ouverture de ses outils. Par exemple, la version 2 des Functions App vous autorise le debugging en local sur MacOS. D'ailleurs, il est intéressant de constater que l'ensemble des nouveautés vont dans ce sens, à savoir une plus grande ouverture.
De même, je n'ai pas mentionné certains aspects concernant un bon contrôle de la plateforme telle qu'une application d'orchestration des playbooks et scripts Terraform. J'ai commencé à benchmarker la solution devops.azure.com (anciennement VSTS) pour ce faire. Il s'avère qu'elle dispose des agents adéquats pour le lancement de playbook Ansible et Terraform. De plus, le côté managé correspond aux souhaits du client.
Je pense que vous disposez maintenant des éléments fondamentaux pour envisager l'automatisation chez Azure tout en conservant un bon niveau d’ouverture. Avec cette stratégie, vous pourrez envisager de l'exploiter dans le cadre d'une infrastructure multi-cloud.

EMR ou Elastic MapReduce, est un service managé par AWS agissant comme une boîte à outils, qui vous permet de lancer facilement une plateforme de Big...
Dans CloudFormation, vous allez définir vos différentes ressources qui correspondent à des types proposées par AWS, comme les EC2, les S3, les RDS,...

Introduction Parmi les services de la Google Cloud Platform il en est certains qui se démarquent aisément de la concurrence. Sorti en 2008, AppEngine...