 Akram BLOUZA
Akram BLOUZA
Sécuriser l'accès à vos données depuis QuickSight
Énoncé Prenons le cas d’une infrastructure AWS qui est localisée dans la région parisienne (eu-west-3). Nous souhaitons exposer dans QuickSight une...

Vous avez déployé votre application dans une infrastructure AWS sécurisée, résiliente, hautement disponible et scalable. Ensuite, vous avez besoin d’être rassuré sur le fait que cette machine tourne comme vous le souhaitez et d’être alerté dès qu’il y a une défaillance dans ce que vous avez mis en place.
Il s’agit de l’objectif de cet article, qui vous donnera la recette détaillée vous permettant de surveiller votre infrastructure et vos applications dans AWS.
Pour une meilleure gestion de votre SI, il est intéressant de centraliser tous les logs qui concernent vos applications.
Pour vos applications déployées sur AWS, c’est CloudWatch Logs qu’il faut utiliser.
Deux possibilités existent pour pouvoir centraliser vos Logs applicatifs. La première solution est d’utiliser le SDK AWS correspondant (les liens des SDK par langage de programmation : Java, Php, Go, Python ) pour publier vos logs dans CloudWatch.
Pour un projet de migration d’une application vers le Cloud AWS, je n’ai pas choisi cette méthode parce qu'elle nécessite une refonte du module Logging et j’ai opté pour la méthode de journalisation utilisant des agents CloudWatch.
En premier lieu, il est nécessaire d’installer le programme d'installation de l'agent CloudWatch Logs au niveau des instances EC2 qui hébergent vos applications. Il est intéressant d’effectuer cette installation au niveau de l’AMI de vos instances EC2 pour que le démarrage de vos instances EC2 soit plus rapide. Dans mon cas, j’ai créé une AMI à partir d’une instance EC2 construite à partir de l’image officielle CentOS 7 :
sudo yum -y install python-pip
sudo pip install --upgrade pip
sudo curl https://s3.amazonaws.com/aws-cloudwatch/downloads/latest/awslogs-agent-setup.py -o /tmp/awslogs-agent-setup.py
sudo chmod +x /tmp/awslogs-agent-setup.py
Dans mon projet de migration, j’utilise cette AMI pour l’installation de plusieurs applications. C’est pour cela que j’ai opté pour l’installation et la configuration de l’agent CloudWatch au démarrage de l’instance dans la configuration de lancement :
sudo /tmp/awslogs-agent-setup.py -n -r ${deploy_region} -c /tmp/awslogs-config.conf
sudo service awslogs restart
Comme vous le remarquez, vous devez préciser le nom de la région de vos instances EC2, ainsi que le fichier de configuration. Ici, le fichier de configuration est /tmp/awslogs-config.conf. Il permet à l’agent CloudWatch de déterminer l’ensemble des logs à exporter au niveau CloudWatch Logs.
Ce fichier est composé d’une section générale indiquant le chemin du fichier d’état de l’agent CloudWatch et plusieurs sections définissant chacune les informations d’un fichier de logs qu’on veut exporter. Les détails de chaque section sont dans ce fichier exemple :
#Section générale
[general]
state_file = /var/awslogs/state/agent-state # Chemin du fichier d’état de l’agent
#Section pour le fichier de log /var/log/messages
[/var/log/messages]
datetime_format = %b %d %H:%M:%S #Format de la date de l’extraction des logs
file = /var/log/messages #Chemin du fichier de log
buffer_duration = 5000 #Durée du regroupement des événement des logs
log_stream_name = {instance_id} #Le nom du flux de logs de destination.
initial_position = start_of_file #Spécifie l’endroit ou commencer à lire la log
log_group_name = log-system-app #Le nom du groupe des logs au niveau cloudwatch
Si le nom du groupe n’existe pas dans CloudWatch, il sera créé automatiquement.
Dans mon cas, je préfère garder une maîtrise de l’ensemble des ressources et composants créés.
J’utilise Terraform pour la création de mon infrastructure AWS :
resource "aws_cloudwatch_log_group" "log-group-system-app" {
name = "log-system-app"
retention_in_days = 5
}
Pour vérifier l’export des logs, il suffit de naviguer dans AWS : Services ⇒ CloudWatch ⇒ Logs => Log Group ⇒ Log Stream.
Il est maintenant intéressant de planifier des alarmes quand ces fichiers de logs affichent par exemple des erreurs. Ainsi, nous pourrons anticiper et corriger des anomalie applicatives.
La première étape est de créer un filtre permettant de filtrer par exemple le pattern “ERROR” pour les logs présents dans le groupe des logs “log-system-app”. Une nouvelle métrique sera aussi créée et prendra la valeur “1” à chaque fois où le pattern “ERROR” renvoie un résultat :
resource "aws_cloudwatch_log_metric_filter" "log-metric-filter-app" {
name = "Filter_metric_log_fonctionnel"
pattern = "ERROR"
log_group_name = "log-system-app"
metric_transformation {
name = "ErrorCountApp"
namespace = "LogMetricsApp"
value = "1"
default_value = "0"
}
}
Ensuite, nous créons une alarme rattachée au filtre et qui enverra un mail de diffusion dès que la métrique “ErrorCountSystemApp”est supérieure ou égale à 5 pendant une période de 120 secondes :
resource "aws_cloudwatch_metric_alarm" "alarm_error_system_app" {
alarm_name = "system-errors-alarm"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "ErrorCountSystemApp"
namespace = "LogMetricsApp"
period = "120"
statistic = "Sum"
threshold = "5"
alarm_description = "Alarm if presence of pattern error in system app logs"
alarm_actions = [ "${aws_cloudformation_stack.sns_topic.arn}" ]
}
Les types d’alarme sont précisés avec la propriété alarm_actions. Dans mon cas, j’ai souscris un topic SNS d’envoi de mail. D’autres types de notifications pourraient être programmés, tels que l’envoi de sms, l’exécution d’une fonction Lambda, un message Slack…
Avec Terraform, il n’est pas possible de créer un topic SNS d’envoi de mail car le protocole email n’est pas supporté. Pour plus d’informations sur ce sujet, vous pourrez lire les détails du module aw_sns_topic_subscription ici.
Ainsi, j’ai utilisé Terraform pour créer une stack CloudFormation permettant d’envoyer un mail :
data "template_file" "cloudformation_sns_stack" {
template = "${file("./templates/email-sns-stack.json.tpl")}"
vars {
display_name = "${var.display_name}"
subscriptions = "${join("," , formatlist("{ \"Endpoint\": \"%s\", \"Protocol\": \"%s\" }", var.email_addresses, var.protocol))}"
}
}
resource "aws_cloudformation_stack" "sns_topic" {
name = "${var.stack_name}"
template_body = "${data.template_file.cloudformation_sns_stack.rendered}"
tags = "${merge(
map("Name", "${var.stack_name}")
)}"
}
Voici le template email-sns-stack.json contenant le code CloudFormation permettant de créer le topic email :
{
"AWSTemplateFormatVersion": "2010-09-09",
"Resources" : {
"EmailSNSTopic": {
"Type" : "AWS::SNS::Topic",
"Properties" : {
"DisplayName" : "${display_name}",
"Subscription": [
${subscriptions}
]
}
}
},
"Outputs" : {
"ARN" : {
"Description" : "Email SNS Topic ARN",
"Value" : { "Ref" : "EmailSNSTopic" }
}
}
}
variable "display_name" {
type = "string"
default = "Alert AWS: Need you verification"
}
variable "email_addresses" {
type = "list"
default = ["it@app-admin.com"]
description = "Email address to send notifications to"
}
variable "protocol" {
default = "email"
type = "string"
}
Pour vérifier la création de ces filtres, il suffit de naviguer dans AWS : Services ⇒ CloudWatch ⇒ Logs => Metric Filter. L’état de l’alarme créée s’affiche au niveau de la rubrique Alarm : OK, INSUFFICIENT ou ALARM.
Quand vous avez construit votre infrastructure AWS, vous avez certainement établi des règles de sécurité, de versionning et autres. Vous avez aussi peut-être créé des tags pour vos ressources vous permettant de les retrouver rapidement.
Votre infrastructure continuera d’évoluer et le risque d’introduire une erreur dans l’une de ces règles devient très élevé. Contrôler l’évolution des configurations de vos ressources AWS devient ainsi primordial pour être averti au cas où l’une de ces règles n’est plus respectée.
J’ai utilisé le service managé AWS Config qui permet de contrôler et d'évaluer les configurations de vos ressources AWS.
Voici un exemple de règle permettant de contrôler que le protocole ssh est désactivé en entrée de vos ressources.
resource "aws_config_config_rule" "restricted-ssh" {
name = "restricted-ssh"
description = "Checks whether security groups in use do not allow restricted incoming SSH traffic."
source {
owner = "AWS"
source_identifier = "INCOMING_SSH_DISABLED"
}
}
Pour vérifier que la règle aws-config est bien créée au niveau de la console AWS, il suffit de naviguer vers services -> AWS Config -> Règles.
Comme vous pouvez le remarquer, AWS Config évalue les ressources AWS. Nous avons ainsi le statut de conformité par ressource :
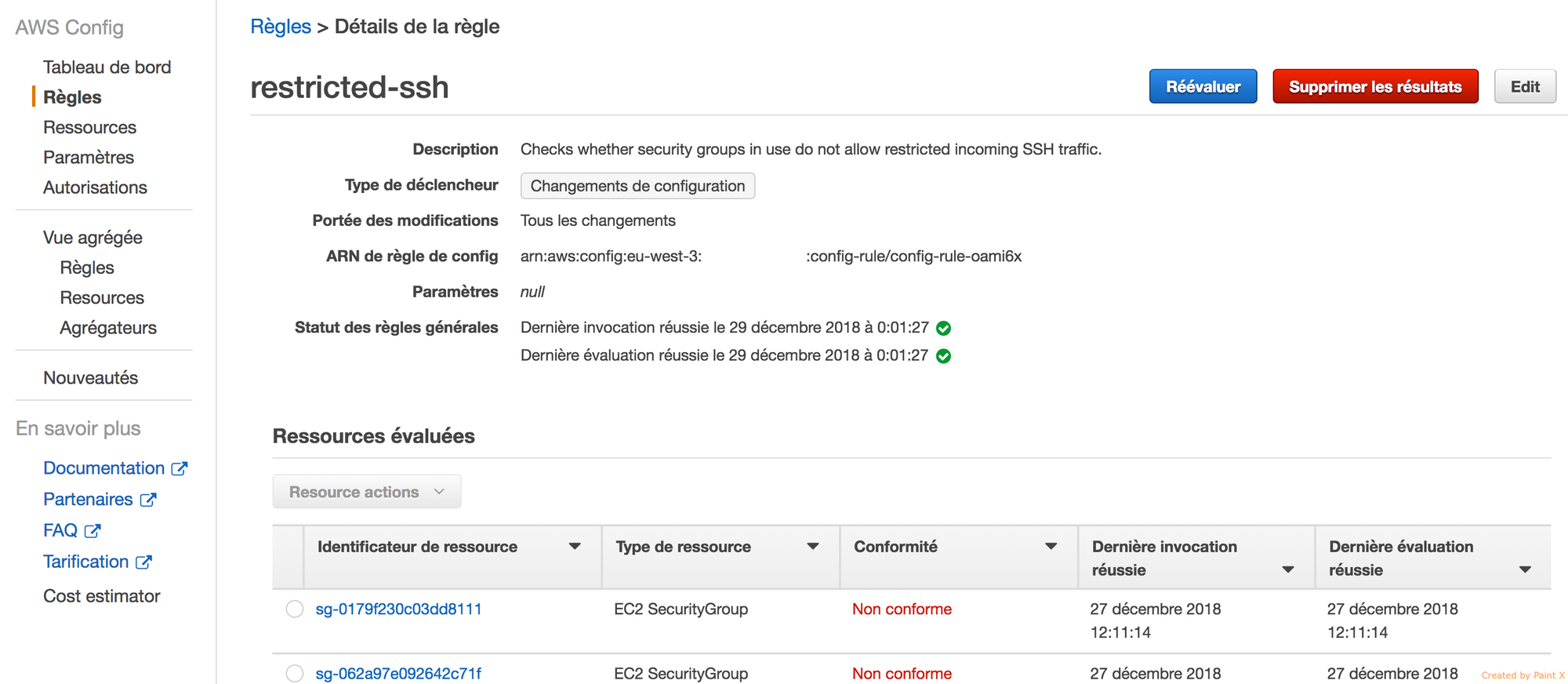
Il est possible d’exporter ces résultats dans un Bucket S3 chiffré avec une clé KMS. Cette partie ne sera pas abordée dans cet article, par contre vous trouverez le code Terraform de l’ensemble des règles AWS Config que j’ai développé sur les buckets S3, RDS, AMI et EC2, ainsi que l’export S3 ici.
Une fois que les règles AWS Config sont implémentées, il devient intéressant d’être averti au cas où certaines ressources ne sont plus conformes. J’utiliserai ici le même type d’alerte décrit plus haut, c’est à dire le mail, ainsi que le même topic SNS.
Pour cela, j’ai utilisé CloudWatch Event qui permet de détecter et nous avertir au cas où la configuration des ressources et les règles établies dans AWS config ne correspondent plus.
Voici un code terraform qui permet de créer un Event CloudWatch permettant de détecter un échec de conformité de vos règles AWS Config.
resource "aws_cloudwatch_event_rule" "config_compliance_check_fail_event" {
name = "config-compliance-check-fail-event"
description = "Get notifications when a compliance check to your rules fails."
event_pattern = <<PATTERN
{
"source": [
"aws.config"
],
"detail-type": [
"Config Rules Compliance Change"
]
}
PATTERN
}
A la détection de cet événement, une alerte est envoyée par mail.
resource "aws_cloudwatch_event_target" "config_resource_check_alerting" {
target_id = "resource_check_target"
arn = "${aws_cloudformation_stack.sns_topic.arn}"
rule = "${aws_cloudwatch_event_rule.config_resource_change_event.name}"
}
D’autres événements CloudWatch permettant de détecter les modifications du statut d'événements AWS Config sont présents ici
Vous avez peut-être planifié des snapshots de votre base de données RDS et vous avez besoin d’être notifié quand le snapshot est effectué. Pour cela, j’ai utilisé CloudWatch Event.
Voici le code Terraform permettant de réaliser ceci :
resource "aws_db_event_subscription" "snapshot_rds_event" {
name = "Snapshot-rds-event-notification"
sns_topic = "${aws_cloudformation_stack.sns_topic.arn}"
source_type = "db-snapshot"
event_categories = [
"creation"
]
}
Si vous avez besoin d’être alerté pour d’autres types d’événement sur vos bases de données, voici le code Terraform précisant l’ensemble des événements qu’il est possible de détecter par cloudWatch Event.
resource "aws_db_event_subscription" "instance_rds_event" {
name = "instance-rds-event"
sns_topic = "${aws_cloudformation_stack.sns_topic.arn}"
source_type = "db-instance"
event_categories = [
"availability",
"deletion",
"failover",
"failure",
"low storage",
"maintenance",
"notification",
"read replica",
"recovery",
"restoration",
]
}
Un autre type d'événements CloudWatch très intéressant à programmer est la détection d’échec de terminaison ou démarrage de vos instances EC2 rattachées à un autoscaling group :
resource "aws_cloudwatch_event_rule" "unsessful_event" {
name = "capture-ec2-scaling-unsecssful-events"
description = "Capture all EC2 unsecssful events"
event_pattern = <<PATTERN
{
"source": [
"aws.autoscaling"
],
"detail-type": [
"EC2 Instance Launch Unsuccessful",
"EC2 Instance Terminate Unsuccessful"
]
}
PATTERN
}
Même si vous construisez une infrastructure résiliente, il est parfois intéressant d’anticiper les problèmes liés à vos ressources et d’être informé quand un recouvrement d’une instance en échec est fait, ou quand un healthcheck d’un load balancer renvoie une erreur.
Ici, je vous détaille l’ensemble des contrôles que j’ai mis en place pour assurer ces points.
Par défaut, seules certaines métriques couvrent l’instance EC2. Ces métriques ne couvrent pas la mémoire et le disque. Pour pouvoir ajouter ces métriques manquantes, vous devez installer certains packages et fournir certains scripts pour les exécuter.
Exactement comme nous l’avons fait au niveau de la centralisation des logs, nous installons les packages nécessaires au niveau de l’AMI de vos instances :
sudo yum -y install perl-Switch perl-DateTime perl-Sys-Syslog perl-LWP-Protocol-https perl-Digest-SHA
Ensuite, nous ajoutons les bons droits aux instances via le profil d’instance pour pouvoir publier des logs dans CloudWatch:
(...)
{
"Sid": "CloudWatchAgentServerPolicy",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": ${data_cloudwatch_policy}
}
(...)
Et au démarrage de l’instance, nous fournissons l'ensemble des scripts nécessaires :
sudo curl http://aws-cloudwatch.s3.amazonaws.com/downloads/CloudWatchMonitoringScripts-1.2.1.zip -o /tmp/CloudWatchMonitoringScripts-1.2.1.zip
sudo unzip -o /tmp/CloudWatchMonitoringScripts-1.2.1.zip -d /tmp
Puis nous exécutons ce playbook Ansible qui crée des crontab s'exécutant toutes les 5 minutes en lançant le script python mon-put-instance-data.pl que je viens de fournir.
Ce script permet de récupérer les métriques mémoire et disque et de les enregistrer dans CloudWatch (mémoire/espace utilisé en pourcentage ou megaoctet, mémoire/espace disponible).
- cron:
name: cloudwatch-memory-asg-job
minute: "*/5"
user: root
job: "/tmp/aws-scripts-mon/mon-put-instance-data.pl --mem-util --mem-used --mem-avail --auto-scaling=only"
cron_file: cloudwatch_asg_memory
- cron:
name: cloudwatch-disk-space-asg-job
minute: "*/5"
user: root
job: "/tmp/aws-scripts-mon/mon-put-instance-data.pl --disk-path=/ --disk-space-util --disk-space-avail --disk-space-used --auto-scaling=only"
cron_file: cloudwatch_asg_space_disk
Pour vérifier si ces métriques ont été bien remontées, il suffit d’aller au niveau de la console sur Services -> CloudWatch -> Metrics -> Linux System -> AutoScalingGroupName
Maintenant que toutes les métriques intéressantes sont présentes au niveau CloudWatch, je vais les exploiter pour créer des alarmes quand elles atteignent des seuils définis.
Concernant l’espace disque, la métrique s’appelle DiskSpaceAvailable. Je crée une alerte qui envoie un mail dès que l’espace disque disponible est inférieur ou égal à 2Go. La vérification est faite deux fois toute les cinq minutes.
resource "aws_cloudwatch_metric_alarm" "disk_app" {
alarm_name = "web-disk-alarm-app"
comparison_operator = "LessThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = "DiskSpaceAvailable"
namespace = "System/Linux"
period = "300"
statistic = "Average"
threshold = "2"
alarm_description = "Alarm space available disk <= 2Go"
alarm_actions = [ "${aws_cloudformation_stack.sns_topic.arn}"]
dimensions {
AutoScalingGroupName = "${data.terraform_remote_state.app.asg_alb_app_name}"
MountPath = "/"
Filesystem = "/dev/xvda1"
}
}
Concernant le CPU, la métrique s’appelle CPUUtilization. Je crée une alerte qui envoie un mail dès que la consommation du CPU atteint 80%. La vérification est faite deux fois toutes les deux minutes.
resource "aws_cloudwatch_metric_alarm" "cpu_app" {
alarm_name = "web-cpu-alarm-app"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = "120"
statistic = "Average"
threshold = "80"
alarm_description = "This metric monitors ec2 cpu utilization"
alarm_actions = [ "${aws_cloudformation_stack.sns_topic.arn}" ]
dimensions {
AutoScalingGroupName = "${data.terraform_remote_state.app.asg_alb_app_app_name}"
}
}
Concernant la mémoire, la métrique s’appelle MemoryUtilization. Je crée une alerte qui envoie un mail dès que la consommation de la mémoire atteint 80%. La vérification est faite deux fois toutes les cinq minutes.
resource "aws_cloudwatch_metric_alarm" "memory_app" {
alarm_name = "web-memory-alarm-app"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = "MemoryUtilization"
namespace = "System/Linux"
period = "300"
statistic = "Average"
threshold = "80"
alarm_description = "This metric monitors ec2 memory for high utilization on agent hosts"
alarm_actions = [ "${aws_cloudformation_stack.sns_topic.arn}" ]
dimensions {
AutoScalingGroupName = "${data.terraform_remote_state.app.asg_alb_app_name}"
}
}
Quand vous maîtrisez la quantité de flux en entrée et en sortie sur vos instances et vos bases de données, il devient intéressant de surveiller ceci en envoyant une alerte dès qu’une quantité de flux est atteinte. Ainsi, vous pourrez anticiper un potentiel accès à vos instances EC2 ou bases de données pour récupérer des données.
Concernant le flux réseau en entrée aux instances, la métrique s’appelle NetworkIn. Je crée une alerte qui envoie un mail dès que la taille du flux réseau en entrée des instances rattachées à un autoscaling groupe atteint 2Go pour une période d’une journée.
resource "aws_cloudwatch_metric_alarm" "network_app_in" {
alarm_name = "web-network-in-app"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "NetworkIn"
namespace = "AWS/EC2"
period = "86400"
statistic = "Sum"
# 2Go
threshold = "2000000000"
alarm_description = "Alarm if Network in flow for the database> 2 GB"
alarm_actions = [ "${aws_cloudformation_stack.sns_topic.arn}" ]
dimensions {
AutoScalingGroupName = "${data.terraform_remote_state.app.asg_alb_app_name}"
}
}
Concernant le flux réseau en entrée de la base de données, la métrique s’appelle NetworkReceiveThroughput. Je crée une alerte qui envoie un mail dès que la taille du flux réseau en entrée des instances rattachées à un autoscaling groupe atteint 2Go pour une période d’une journée.
resource "aws_cloudwatch_metric_alarm" "db_netowork_in" {
alarm_name = "db-network-in"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "NetworkReceiveThroughput"
namespace = "AWS/RDS"
period = "86400"
statistic = "Sum"
threshold = "2000000000"
alarm_description = "Alarm if Data Base Space in < 2 GB"
alarm_actions = [ "${data.terraform_remote_state.sns_mail.arn}" ]
dimensions {
DBInstanceIdentifier = "db-master-${var.deploy_env}"
}
}
Pour être averti quand le nombre d’instances rattachées au load balancer est inférieur au nombre d’instances désirées et planifiées, voici le code Terraform correspondant :
resource "aws_cloudwatch_metric_alarm" "alarm-healthcheck-alb-app" {
alarm_name = "alarm-healthcheck-alb-app"
comparison_operator = "LessThanThreshold"
evaluation_periods = "2"
metric_name = "HealthyHostCount"
namespace = "AWS/ApplicationELB"
period = "120"
threshold = "1"
statistic = "Average"
alarm_description = "Alarm if HealthyHostCount < 2"
alarm_actions = [ "${data.terraform_remote_state.sns_mail.arn}" ]
dimensions {
LoadBalancer = "${data.terraform_remote_state.app.alb_app_app_cloud_watch_suffix}"
TargetGroup = "${data.terraform_remote_state.app.asg_target_group_cloudwatch_suffix_app}"
}
}
Suivre les activités, ainsi que les appels API sur vos ressources est nécessaire pour garantir plus de sécurité à vos infrastructures en détectant les failles de sécurité au plus tôt. Ceci est possible avec le service managé AWS CloudTrail.
Ici, je vais créer une ressource CloudTrail pour récupérer l’ensemble des appels API effectués sur les ressources, les exporter vers un groupe de Log CloudWatch et un bucket S3 chiffré avec une clé KMS, puis créer des alertes sur les appels API que je veux surveiller.
Je commence à créer un groupe de Log CloudWatch :
resource "aws_cloudwatch_log_group" "cloudtrail_logging" {
name = "CloudTrail/MonAppLogGroup"
retention_in_days = 1
}
Je crée ensuite une ressource CloudTrail. Le paramètre s3_bucket_name indique le nom du bucket S3 permettant de sauvegarder l’historique des appels à l’API concernant les ressources.
Le paramètre kms_key_id indique l’id de la clé KMS permettant de chiffrer et déchiffrer les données depuis le bucket S3. L’ARN du group Log de CloudWatch est renseigné dans le paramètre cloud_watch_logs_group_arn.
Pour que la ressource CloudTrail puisse écrire dans le bucket S3 et puisse récupérer la clé KMS, il est nécessaire de fournir les droits adéquats.
Nous devons aussi fournir à la ressource CloudTrail le rôle IAM que CloudWatch Logs doit assumer pour écrire dans le groupe des Logs CloudWatch. Ce rôle IAM est renseigné au niveau du paramètre cloud_watchlogs_role_arn.
Pour cela, Il faut créer un rôle IAM et le renseigner au paramètre cloud_watchlogs_role_arn.
resource "aws_cloudtrail" "trail" {
name = "${var.basename}-cloudtrail"
s3_bucket_name = "${data.terraform_remote_state.trail-config-bucket.s3_bucket}"
s3_key_prefix = "${var.basename}"
include_global_service_events = true
is_multi_region_trail = true
kms_key_id = "${data.terraform_remote_state.trail-config-bucket.kms_bucket}"
enable_log_file_validation = true
cloud_watch_logs_role_arn = "${data.terraform_remote_state.cloudwatch-log-groups.aws_cloudwatch_log_group_arn}"
cloud_watch_logs_group_arn = "${aws_iam_role.cloudtrail_to_cloudwatch_role.arn}"
event_selector {
read_write_type = "All"
include_management_events = true
data_resource {
type = "AWS::S3::Object"
values = ["arn:aws:s3:::"]
}
}
}
Le détail du rôle IAM décrit plus haut est le suivant :
resource "aws_iam_role" "cloudtrail_to_cloudwatch_role" {
name = "cloudtrail_to_cloudwatch_role"
assume_role_policy = "${data.aws_iam_policy_document.cloudtrail_to_cloudwatch_assume_role_policy.json}"
}
// IAM Policy Document: Allow CloudTrail to AssumeRole
data "aws_iam_policy_document" "cloudtrail_to_cloudwatch_assume_role_policy" {
statement {
sid = "AWSCloudTrailAssumeRole",
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["cloudtrail.amazonaws.com"]
}
}
}
data "aws_iam_policy_document" "cloudtrail_to_cloudwatch_create_logs" {
statement {
sid = "AWSCloudTrailCreateLogStream"
effect = "Allow"
actions = ["logs:CreateLogStream"]
# var.deploy_region: region en cours
# var.account_id : compte aws
resources = ["arn:aws:logs:${var.deploy_region}:${var.account_id}:log-group:${aws_cloudwatch_log_group.cloudTrail_logging.name}:log-stream:${var.account_id}_CloudTrail_${var.deploy_region}*"]
}
statement {
sid = "AWSCloudTrailPutLogEvents"
effect = "Allow"
actions = ["logs:PutLogEvents"]
resources = ["arn:aws:logs:${var.deploy_region}:${var.account_id}:log-group:${aws_cloudwatch_log_group.cloudTrail_logging.name}:log-stream:${var.account_id}_CloudTrail_${var.deploy_region}*"]
}
}
resource "aws_iam_role_policy" "cloudtrail_to_cloudwatch_create_logs" {
name = "CloudTrailToCloudWatchCreateLogs"
role = "${aws_iam_role.cloudtrail_to_cloudwatch_role.id}"
policy = "${data.aws_iam_policy_document.cloudtrail_to_cloudwatch_create_logs.json}"
}
Pour vérifier l’export des logs, il suffit de naviguer dans AWS : Services ⇒ CloudWatch ⇒ Logs => Log Groups ⇒ CloudTrail/MonAppLogGroup.
Maintenant, je crée un filtre qui permet de créer la métrique AuthorizationFailureCount qui sera valorisée s’il y a des appels API non autorisés aux ressources :
resource "aws_cloudwatch_log_metric_filter" "filter-unauthorized-operation" {
name = "AuthorizationFailures"
pattern = "{ ($.errorCode = \"*UnauthorizedOperation\") || ($.errorCode = \"AccessDenied*\") }"
log_group_name = ${aws_cloudwatch_log_group.cloudTrail_logging.name}"
metric_transformation {
name = "AuthorizationFailureCount"
namespace = "CloudTrailMetrics"
value = "1"
default_value = "0"
}
}
Enfin, je crée une alarme utilisant la métrique AuthorizationFailureCount pour alerter par mail en cas d’opération non autorisée pendant une période de 5 minutes.
resource "aws_cloudwatch_metric_alarm" "alarm-unauthorized-operation" {
alarm_name = "alarm-unauthorized-operation"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "AuthorizationFailureCount"
namespace = "CloudTrailMetrics"
period = "300"
statistic = "Sum"
threshold = "1"
alarm_description = "Alarm if unauthorized operations"
alarm_actions = [ "${data.terraform_remote_state.sns_mail.arn}" ]
}
Dans cet article, nous avons vu qu’il est possible dans AWS de mettre en place un monitoring très approfondi vous permettant d’anticiper des problèmes pour agir au plus vite. Ceci est intéressant même si vous êtes confiants dans la résilience de votre infrastructure.
Nous avons également vu que nous pouvons surveiller l’évolution de votre infrastructure afin qu’elle continue de respecter les règles que vous avez mis en place en terme de sécurité, résilience et scalabilité.
Ceci se résume avec ce schéma d’architecture :
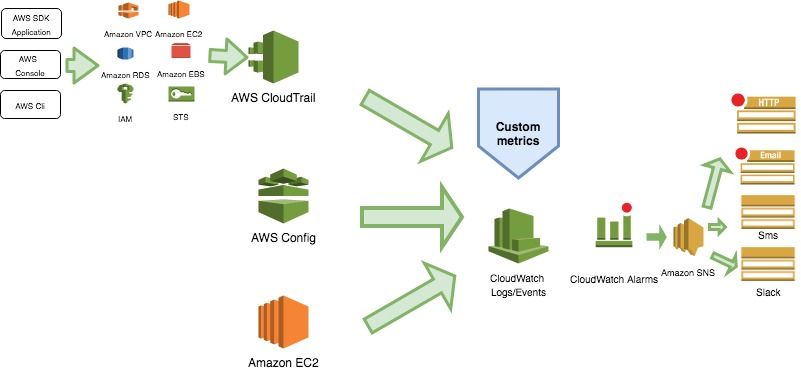
Pour aller plus loin, nous pourrions mettre en place un exporter au niveau CloudWatch pour envoyer les métriques vers un outil de monitoring déjà exploité dans votre entreprise tels que Prometheus ou Nagios. De même, nous pourrions aussi exporter les Logs CloudWatch vers une stack ELK externe ou dans AWS.

Énoncé Prenons le cas d’une infrastructure AWS qui est localisée dans la région parisienne (eu-west-3). Nous souhaitons exposer dans QuickSight une...
Objectifs Il y a des modes en informatique et l’utilisation de “BuzzWord” est fréquente. Dans les derniers de ceux-ci, un terme revient souvent :...

Mise à jour le 22/12/2021 Ce contenu a été mis à jour le 22/12/2021 pour pointer vers la version 2.5.5 de Traefik Proxy. La gestion d'ECS n'est...