Mise en place de AWS EMR
Dans cet article, je voudrais partager mon expérience dans la mise en place un cluster AWS EMR. L'objectif est d'expliquer les points clés de ce service, et de vous permettre d'aller vite pour le lancer. Le code source est disponible ici si vous souhaitez y jeter un oeil.

Sommaire
EMR ou Elastic MapReduce, est un service managé par AWS agissant comme une boîte à outils, qui vous permet de lancer facilement une plateforme de Big Data native du cloud, utilisant des outils open source, tels qu'Apache Spark, Apache Hive, Apache HBase, Apache Flink, et Presto etc ... Pour plus de détails, vous pouvez suivre la documentation officielle ici.
Je voudrais remercier Christian Nuss l'auteur de ce projet : c'était mon point de départ, et cela m'a beaucoup aidé à mettre en œuvre ce projet. Merci beaucoup <3 <3 <3
Permettez-moi de vous présenter la boîte à outils que j'utilise pour ce projet :
- Compte AWS
- Terraform 0.11.14
- Ansible 2.8.3
- AWS EMR 5.23.0
Simple, non ...?!
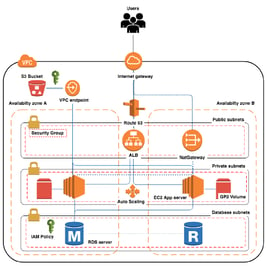
Je préfère faire un schéma qui montre l'infrastructure globale que je vais construire, cette infrastructure est à adapter à votre goût.
Les points clés de cette infrastructure sont :
Stockage :
J'utilise le premier compartiment S3 appelé bootstrap, qui va contenir des scripts de bootstrap pour le cluster, et c'est la seule façon de passer des scripts d'initialisation à EMR.
Le deuxième compartiment logs sert de support de journal, et contient tous les journaux de démarrage avant et après le lancement d'EMR.
J'utilise également des volumes EBS attachés à chaque instance de nœud. Vous pouvez choisir entre l'utilisation d'un stockage global comme le compartiment s3 avec EMRFS, afin que vos données puissent être facilement réutilisées par d'autres ressources. Vous pouvez aussi utiliser un stockage local comme les volumes EBS avec HDFS, afin que les données ne soient disponibles que dans votre cluster.
Chiffrement :
EMR prend en charge deux types de chiffrement :
Au repos :
Cela concerne tous les supports de données de stockage, comme les compartiment S3 et les volumes EBS. Pour S3, j'utilise le chiffrement côté serveur (SSE), c'est gratuit et ça suffit. Pour EBS, j'utilise une clé KMS, et c'est le seul moyen qu’on puisse utiliser pour chiffrer les données pour ce service.
En transit :
Il s'agit des données en transmission entre les nœuds du cluster. Pour cela, j'utilise un certificat auto-signé et généré par un provider Terraform.
Traitement de données :
Le cluster que j'ai utilisé contient un maître et deux nœudscore. J'expliquerai en détail ce choix plus tard. Pour en savoir plus sur le rôle de chaque composant, veuillez consulter ce lien.
Mise à l'échelle automatique :
L'élasticité est l'une de mes caractéristiques préférées du cloud. Pour des raisons de coût, j'aimerais que mon cluster évolue à chaque fois qu'il y a une charge de travail importante, et diminue ensuite. Le yarnMemory est la métrique la plus fréquemment utilisée dans ce cas, elle indique la quantité de mémoire disponible dans l'ensemble du cluster. Dans ma configuration, j'ai utilisé deux règles:
Lorsque la mémoire disponible est inférieure à 15% pour une fenêtre de 5 minutes, le cluster ajoute deux nœuds à la fois.
Lorsque la quantité de mémoire disponible est supérieure à 75% pour une fenêtre de 5 minutes, le cluster supprime un nœud après chaque vérification positive.
Vous pouvez vérifier la configuration en détail dans la couche EMR dans :
.
│ ├── emr
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ ├── templates
│ │ │ ├── autoscaling_policy.json.tpl
Gestion des accès avec IAM :
Le cluster a besoin de différents rôles IAM pour différents besoins :
- pour accéder aux compartiments S3,
- pour le bootstrap et les journaux,
- pour exécuter d'autres instances EC2 au démarrage de la mise à l'échelle automatique.
Réseau :
Je voudrais que mon cluster s'exécute dans un sous-réseau privé. J'ai donc créé un VPC avec des sous-réseaux privés et publics, des passerelles NAT, une passerelle Internet, des tables de routage, des groupes de sécurité, etc., en résumé, les classiques.
Hôte Bastion :
Cette instance EC2 est utilisée pour des raisons d'administration. Elle sera utilisée comme hôte de saut SSH vers différentes instances EMR.
Groupes de sécurité :
Les instances de cluster EMR acceptent uniquement le trafic provenant du bastion et de l'ALB. Par conséquent, ces derniers sont confrontés à Internet avec une plage d'adresses IP restreinte.
DNS et ALB :
Dans le cluster EMR, vous pouvez exécuter différents services qui exposent des interfaces Web. J'ai utilisé un ALB avec différents auditeurs. Cela peut être mélangé avec différents chemins Route53, afin d'acheminer le trafic vers le bon service.
Implémentation :
Dans cette partie, nous allons voir ensemble les différentes couches Terraform que j'ai utilisées pour construire ce projet :
La base de code est organisée comme suit :
- couche réseau
- couche bastion
- couche EMR
- couche DNS
1-Couche réseau :
Cette couche est la base de toutes les autres, elle héberge tous les composants du réseau.
J'ai utilisé un schéma classique de VPC, trois sous-réseaux publics, trois sous-réseaux privés, une passerelle Internet, une passerelle NAT (une seule dans mon cas), des tables de routage, des groupes de sécurité : un pour l'hôte bastion, un pour l’ALB, un pour les instances EMR, etc.
Le code de cette partie est assez simple, il existe un fichier principal qui appelle un module réseau qui crée tous les composants du réseau.
.
├── backend.tf
├── errored.tfstate
├── gateway.tf
├── inputs.tf
├── outputs.tf
├── provider.tf
├── routes.tf
├── subnets.tf
├── vars.tf
└── vpc.tf
2-Couche Bastion :
Créer un hôte bastion avec une IP élastique. Cela me permet d’accéder en SSH aux les différentes machines de la plateforme. Le fichier main.tf appelle les différents modules :
EC2: pour créer une instance EC2SGS: pour créer les groupes de sécurité attachés au bastion.DNS: pour créer une entrée DNS pour le bastion, c'est plus lisible par l'homme. Et ça permet également d'avoir une entrée fixe chaque fois que l'IP élastique change lors de la destruction et de l'application de cette couche Terraform.
.
├── backend.tf
├── generated
│ └── ssh
│ ├── bastion-default
│ └── bastion-default.pub
├── inputs.tf
├── main.tf
├── modules
│ ├── dns
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── vars.tf
│ ├── ec2
│ │ ├── eip.tf
│ │ ├── main.tf
│ │ ├── output.tf
│ │ ├── ssh.tf
│ │ └── vars.tf
│ └── sgs
│ ├── main.tf
│ ├── outputs.tf
│ └── vars.tf
├── outputs.tf
├── provider.tf
└── vars.tf
3-Couche EMR :
Cette couche est utilisée pour créer toutes les ressources EMR. Le fichier main.tf appelle les différents composants dans différents modules.
Bootstrap: pour les scripts de bootstrap.Sécurité: pour les stratégies et rôles IAM.EMR: pour créer les nœuds du cluster.
On notera que c’est la même hiérarchie utilisée dans le projet mentionné précédemment, avec des adaptations par rapport à mon schéma.
.
├── backend.tf
├── config.tf
├── generated
│ └── ssh
│ ├── default
│ └── default.pub
├── inputs.tf
├── main.tf
├── modules
│ ├── bootstrap
│ │ ├── files
│ │ │ ├── log4j_spark.properties
│ │ │ ├── logrotate
│ │ │ ├── logrotate.sh
│ │ │ └── syslog.conf
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ ├── templates
│ │ │ └── configure-system.sh.tpl
│ │ └── variables.tf
│ ├── emr
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ ├── templates
│ │ │ ├── autoscaling_policy.json.tpl
│ │ │ ├── configuration.json.tpl
│ │ │ └── security_configuration.json.tpl
│ │ └── variables.tf
│ ├── s3
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ ├── sec
│ │ ├── certs.tf
│ │ ├── iam.tf
│ │ ├── outputs.tf
│ │ ├── ssh.tf
│ │ └── variables.tf
│ └── sgs
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── outputs.tf
├── provider.tf
└── variables.tf
4-Couche DNS :
Cette couche est utilisée pour créer un ALB qui sert à acheminer le trafic vers différents services hébergés sur EMR master, en se basant sur l'écouteur et le filtrage des chemins. Il crée également différentes entrées DNS en fonction de chaque service du cluster. Le fichier main.tf appelle les autres modules :
ALB : pour créer un équilibreur de charge et des écouteurs
DNS : pour créer une zone hébergée privée avec des entrées DNS pour chaque service.
.
├── backend.tf
├── config.tf
├── inputs.tf
├── main.tf
├── modules
│ ├── alb
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ ├── target.tf
│ │ └── variables.tf
│ ├── dns
│ │ ├── dns_instances.tf
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ └── sgs
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── outputs.tf
├── provider.tf
└── variables.tf
Conclusion
Voilà, votre cluster est désormais prêt à être utilisé, et j’aimerais conclure avec les retours que j’ai eu de cette expérience :
limites que j’ai rencontrées
Eh bien, c'était ma première expérience d'utilisation de produits Big Data sur AWS, j'ai remarqué quelques points négatifs lors de la mise en œuvre, les différents points sont répertoriés ici :
Je ne pouvais pas utiliser l'option d'instances de flotte pour le groupe de mise à l'échelle automatique, cette option n’est pas encore implémentée dans Terraform (elle arrive prochainement). Mais elle est très importante, elle vous permet d'utiliser des instances ponctuelles dans la mise à l'échelle automatique. Vous pouvez également avoir jusqu'à cinq types d'instance, afin que le cluster puisse choisir parmi elles, en mise à l'échelle automatique, si un certain type n'est pas disponible.
Impossible d'utiliser les instances de «tâche». Dans les nœuds «Core», Spark utilise HDFS pour stocker des données dans le cluster. Les nœuds de tâche n'ont pas besoin de stockage local. Cela accélère le processus de mise à l'échelle / réduction d'échelle, elles n'ont pas à attendre la fin des processus HDF.
Dans le fichier de configuration EMR par défaut, les instances «Core» sont le paramètre par défaut. Vous n'avez pas de moyen pour modifier ce paramètre avant que votre cluster ne soit démarré. Vous pouvez tenter de le changer après, mais honnêtement, je ne connais pas les conséquences. Je ne suis pas allé si loin.
Impossible de changer le moteur par défaut "Tez" et d'utiliser plutôt "Spark" avec "Hive", je pense que c'était un problème d'incompatibilité avec les versions "Hive" et "Spark". Le problème ici, c'est que vous n'avez pas le contrôle total pour choisir la bonne version pour chaque produit. L'EMR est livré comme une boîte avec différents produits avec des versions fixes, et malheureusement vous ne pouvez pas les paramétrer.
Le fait que vous exécutiez votre cluster dans une seule AZ comme vous l’avez remarqué sur le schéma, cela signifie qu'en cas de perte de l’AZ, vous perdez votre cluster. Donc, vous devez peut-être réfléchir à la façon d'utiliser le cluster, comme démarrer le cluster uniquement lorsque vous en avez besoin pour traiter une grande quantité de données et l'arrêter après. C'est pourquoi nous avons ce paramètre API
termination_protection = false/true
terraform destroy: va toujours produire cette erreur
*module.emr_jobs.aws_emr_security_configuration.security_configuration (destroy): 1 error occurred:
* aws_emr_security_configuration.security_configuration: InvalidRequestException: Security configuration 'emr-default' cannot be deleted because it is in use by active clusters.
Il essaie de supprimer la configuration de sécurité alors que la suppression est toujours en cours, c'est une erreur de Terraform. La solution de contournement concernant cette erreur consiste à utiliser export TF_WARN_OUTPUT_ERRORS = 1 et à ré-exécuter terraform destroy.
Une autre option consiste à utiliser un local-exec avec un sleep qui permet d’attendre que l'emr est totalement supprimé avant la suppression de la configuration de sécurité.
À Améliorer
Voici les différents points d'amélioration que j'ai notés lors de la mise en œuvre de ce projet :
Dans différentes couches, j'ai un dossier qui contient tous les modules, dans chaque module il y a des répétitions de code, ces parties peuvent être implémentées dans des sous-modules pour avoir une meilleure apparence. Pour moi, ce n'était pas si important car je visais la simplicité.
Les différents points que j'ai mentionnés précédemment à propos des instances de flotte, des instances de tâches, etc., c’est très important s'ils peuvent être utilisés dans Terraform, en particulier pour l'optimisation des coûts.
À la fin
Même si le service AWS EMR a toujours des problèmes de compatibilité, il vous permet d'aller vite et d'avoir un cluster en 10 ~ 15 minutes, avec différents produits comme Spark, Hadoop, Hive .. etc. déjà installés, et ça c'est vraiment génial.
Je recommande fortement ce lien pour approfondir la compréhension du fonctionnement de EMR.
Je suis heureux de partager cette expérience avec vous, et j'espère que cela vous permettra d’aller plus vite dans vos projets AWS EMR.