 Ismael HOMMANI
Ismael HOMMANI
Helm pour les nuls et moins nuls
Kubernetes est aujourd’hui un outil de gestion de conteneurs incontournable, présent chez tous les grands fournisseurs de cloud. Il existe plusieurs...

Parmi les services de la Google Cloud Platform il en est certains qui se démarquent aisément de la concurrence. Sorti en 2008, AppEngine a longtemps été un porte-étendard de la GCP. Mais ces derniers temps son attrait a pu décliner avec la montée en puissance de services basés sur la technologie de conteneur tels GKE et CloudRun.
On pourrait penser avec justesse que les progrès technologiques viendront systématiquement relativiser le positionnement d’une technologie phare. Issu de Borg, une technologie interne à Google, Kubernetes a en quelques années complètement révolutionné le paysage cloud, relayant Appengine à des usages de niche. Paradoxalement c’est ce dernier qui avait initié la GCP.
Pourtant un service a su faire mentir ce raisonnement en se nourrissant des progrès technologiques pour consolider une position déjà bien ancrée. Il est ici question de Google BigQuery. Sorti en 2011, le postulat était et reste toujours de faire parler vos petabytes de donnée en quelques secondes. En soit, cela reste un marqueur fort même si d’autres produits concurrents le proposent.
Là où BigQuery se démarque, c’est dans la facilité de consommation de ce service qui loin de rester sur ses acquis est aussi en constante évolution. Car si Google a bien compris une chose, c’est que dans la bataille du cloud, le nerf de la guerre c’est la data.
Pour comprendre l’évolution de BigQuery, il faut revenir à la base de son offre. C’est à dire l’exploration de la donnée.
Le discours commercial est plutôt simple. En transférant vos données semi-structurées sur BigQuery, vous serez en mesure de l’explorer sur des échelles de temps de l’ordre de la seconde ou de la minute et ce, quel que soit le volume envisagé.
S’y ajoute un aspect “as a Service” et une compatibilité avec du SQL standard, qui rendent BigQuery accessible au plus grand nombre.
Evidemment cela à un coût que nous détaillerons plus loin. Mais en terme de business le raisonnement doit se positionner sur “combien cette exploration va me rapporter ?” plutôt que “combien elle va me coûter ?”. D’autant plus que l’infrastructure sous-jacente est entièrement managée par Google se traduisant par des économies d’échelle pour les entreprises consommatrices.
Nous résumons tout cela dans le schéma suivant :
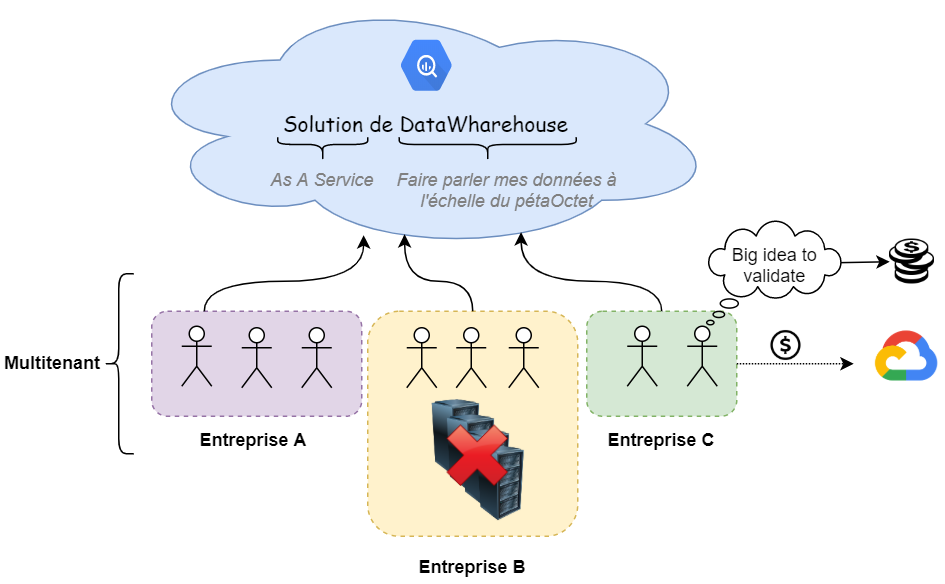
Il n’est pas inintéressant non plus de comprendre comment Google a pensé le produit en décorrélant le compute du stockage. Ce schéma produit par Google en résume la substance.
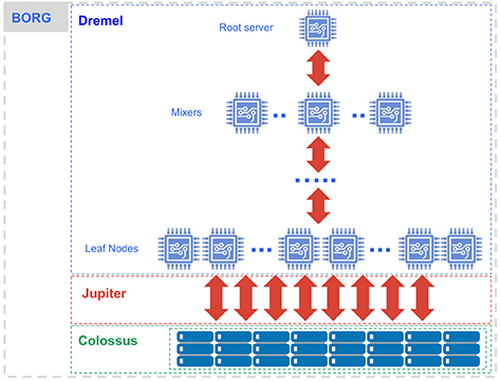
Une exploration de donnée commence par une requête qui sera interprétée par le moteur d'exécution Dremel. Cette dernière sera séparée en éléments atomiques chargés de récupérer notre donnée depuis le filestore Colossus et de communiquer entre eux via un réseau dédié nommé Jupiter. Et enfin, l'orchestration de tous ces noeuds en parallèle est assurée par Borg.
En tant qu’utilisateur, il est inutile de comprendre ce truchement mais il permettra de mettre en perspective la facturation de BigQuery par rapport à la reproduction d’une telle puissance de calcul, de stockage et de redondance par vos propres moyens. Cet article anglophone en fait d’ailleurs une belle démonstration.
A contrario, pour l’utilisateur il est nécessaire de comprendre le modèle de BigQuery. Peu complexe, il se résume par le schéma suivant :
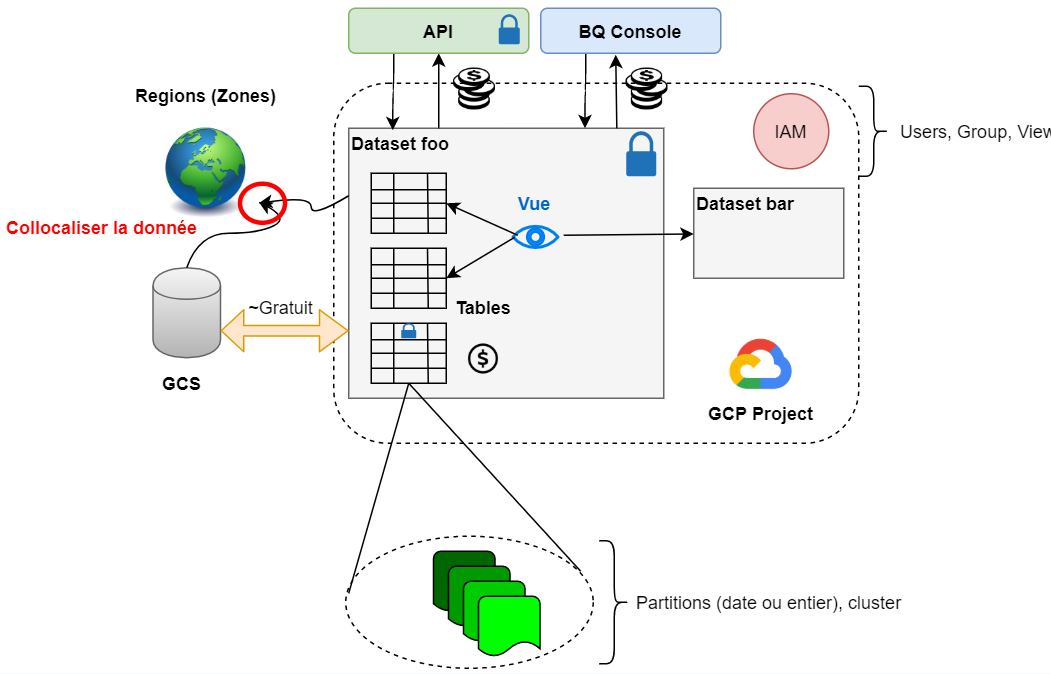
Un projet GCP héberge des datasets régionalisés sur lesquels sont appliqués des permissions en lecture/écriture et qui contiennent des tables optionnellement partitionnées (sur une colonne de type data ou entier) et clusterisées.
Pour exposer les résultats des requêtes et palier à des permissions ne s’appliquant nativement qu’au niveau du dataset, les vues viendront compléter ces notions.
L’IAM du projet décidera les accès à BigQuery en tant que service, par exemple, qui peut y lancer des requêtes, plutôt que l’accès à la donnée géré au niveau du dataset. Cependant, pour des raisons de commodité, les droits IAM impliquent des droits au niveau dataset qu’il sera possible de surcharger.
Note : Depuis début 2020, les droits de lectures peuvent être associés au niveau colonne des tables.
L'interaction avec BigQuery se fera essentiellement avec la BigQuery Console ou l’API. Enfin, mentionnons Google Cloud Storage comme véritable service partenaire avec lequel des transferts de données Est/Ouest ou Ouest/Est sont gratuits et natifs aux produits.
Le postulat de base de BigQuery quant à l’exploration de la donnée ne saurait rendre compte de l'évolution du produit. Analysons-la de plus près à travers sa release note.
Ci-dessous se trouvent regroupés par catégorie et dates les points d’entrée de la release note.
N.B : Ce n’est pas un diagramme officiel et est de ce fait non contractuel.
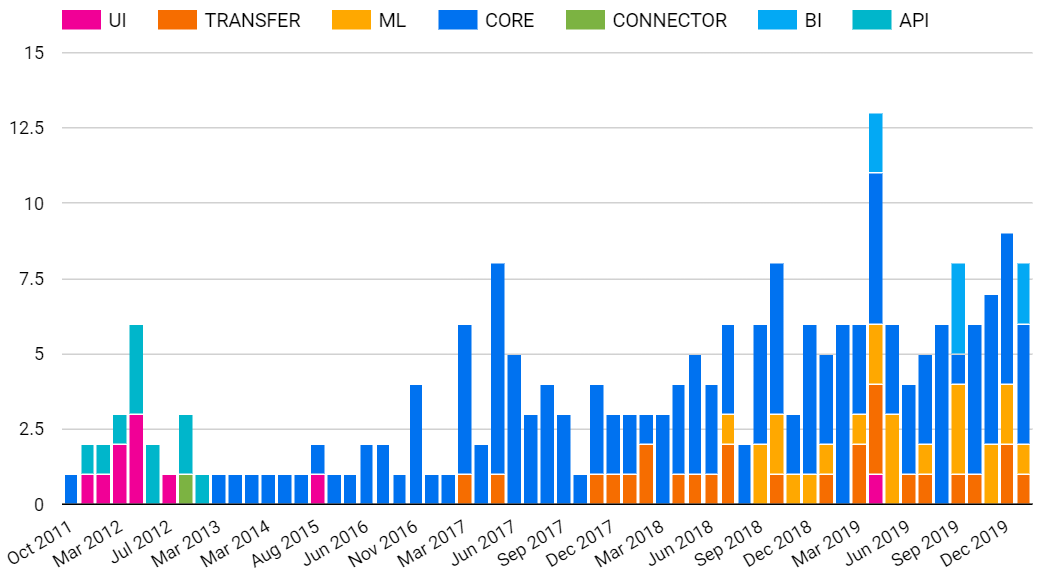
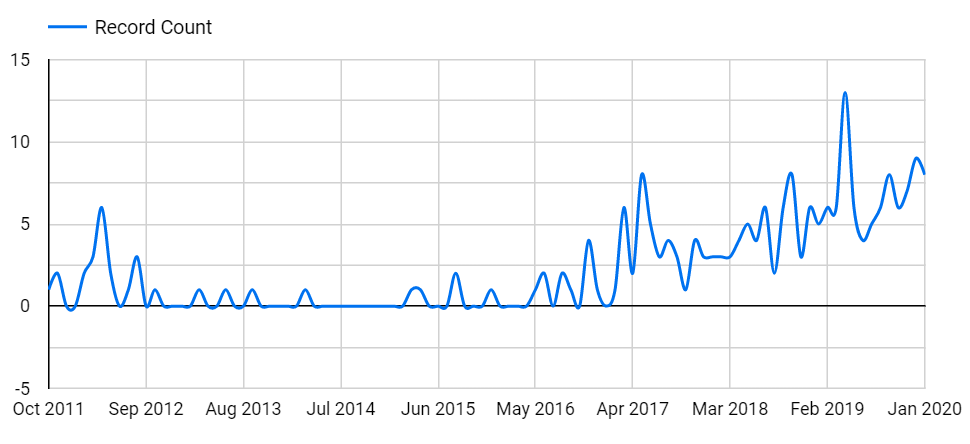
Ce que démontre ces diagrammes est qu’après une relative stabilité en terme d’apports tant en nombre qu’en type, une accélération notable est en marche depuis 2017. Plus intéressant que la quantité est la diversification des sujets traités. Bien évidemment les fonctionnalités dites core concernant les améliorations de performance, de quota ou d’accessibilité sont toujours présentes.
Mais c’est surtout l’apport Machine learning et BI que l’on notera.
L’année précédente, 2016, est d’ailleurs l’année où l’intelligence Artificielle made in Google a fait grand bruit avec AlphaGo. Simple coïncidence? Non.
En amenant l’intelligence Artificielle à BigQuery, il est facile de détecter l’existence d’une stratégie de fond pour démocratiser l’usage de l’IA avec le machine learning.
Cette intégration de sujets transverses n’est pas isolée et est une continuité de la volonté de créer un outil multifonctionnel, à opposer au principe “un besoin, un outil”.
La relation privilégiée entre BigQuery et GCS que nous évoquions tend à l’être de moins en moins avec l’apparition d’un continuum technologique assez cohérent illustré ci-dessous.
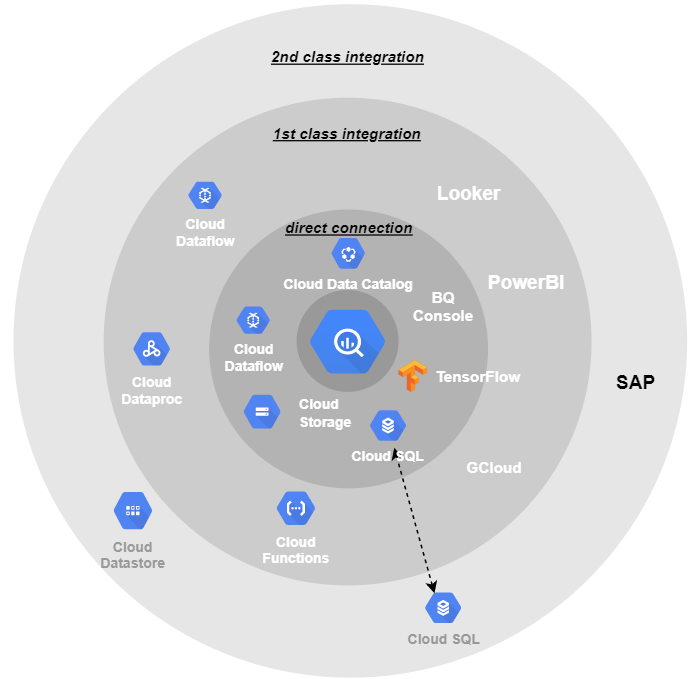
Les connexions directes permettent d’utiliser un service depuis BigQuery sans que cela implique d’effort particulier.
On pensera aux federated queries permettant de requêter de la donnée auprès d’une source autre que BQ, à la capacité d'entraîner des modèles Tensorflow ou encore la création de pipelines Dataflow depuis la console BigQuery.
Les connexions de première classe se reposent sur une API riche et accessible facilitant des interactions personnalisées.
Enfin, des interactions devront passer par un driver ou un service intermédiaire pour établir une communication. On peut penser au data store, dont un transfert de data vers BigQuery passera par dataflow ou cloud Storage.
Note : Cloud SQL y apparaît comme un cas particulier car ce service est compatible avec les federated queries mais nécessite un service tiers pour faire des transfert de données de l’un vers l’autre.
On comprendra aisément qu’un tel produit implique un coût. Plutôt que de faire une redite de la documentation officielle, concentrons-nous sur le nuage de mots suivant.
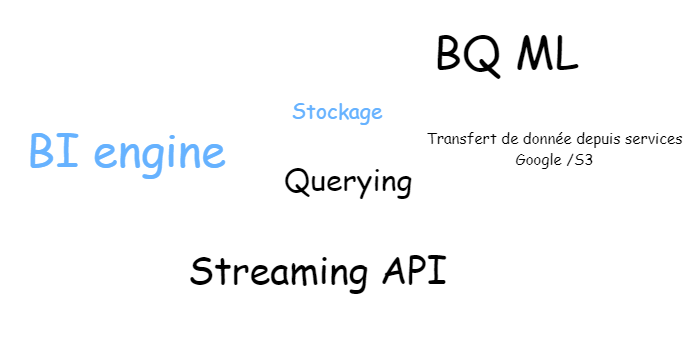
Plus le terme apparaît, plus son usage vous coûte. Par défaut la facturation se fait à la donnée consommée/scannée. On parle de tarification on-demand car elle est fonction de l’usage. Dans le cas du stockage (en bleu) la facturation est mensuelle et proportionnelle à la quantité de donnée stockée. Sur la pratique usuelle de BigQuery, de par sa fréquence, c’est essentiellement le requêtage de la donnée (querying) qui arrive en tête du coût. Ce point ternit injustement la réputation de BigQuery.
Il faut en effet comprendre que BigQuery met à disposition de nombreux leviers pour vous aider à maîtriser son coût. Par exemple, la définition de quota maximum de requêtage par utilisateur ou par projet. La capacité de transférer gratuitement la donnée vers GCS pour bénéficier d’une tarification de stockage moindre. Outre ces leviers, c’est aussi à l’utilisateur de s’adapter à la technologie, acquérir de nouveaux réflexes, challenger ses besoins.
Si l’on prend l’API Streaming qui est essentiellement là pour permettre des analyses temps-réel il est de bon ton de challenger ce besoin.
Est-ce vraiment opportun, ou est-ce qu’une latence de 5 mn suffit?
L’une ou l’autre de ces réponses aura un impact significatif sur la tarification.
Dans les cas où la tarification on-demand paraît trop risquée, BigQuery propose une offre flat-rate qui vous garantit une prédictibilité dans le coût mensuel de votre usage. En vous allouant des slots de calcul, BQ bride votre coût… au même titre que vos performances. Il y est possible de prioriser des requêtes sur d’autres mais cela apporte une complexité supplémentaire.
Le coût est une affaire de juste milieu à trouver qui dépendra toujours de vos cas d’usage. Google a bien compris ce point et offre de multiples options avec lesquelles composer pour trouver votre bon équilibre.
Ciblant initialement la data analyse, le produit a montré la capacité de s’introduire dans d’autres domaines métier. Dans chaque cas les considérations sont différentes bien que le socle technique soit commun.
Les entités BigQuery que nous évoquions plus haut doivent avoir un cycle de vie maîtrisé afin d’éviter la foire d’empoigne. Il est important d’y apporter de la gouvernance, de la cohérence et pour les consommateurs de pouvoir s’y retrouver.
Ce rôle incombe généralement aux ops qui ont une expérience sur ce genre de sujet via l'infrastructure As Code (IaC).
Google propose son propre deployment manager mais on retiendra surtout l’existence de modules Terraform BigQuery.
Le flow se traduira simplement par le schéma suivant :
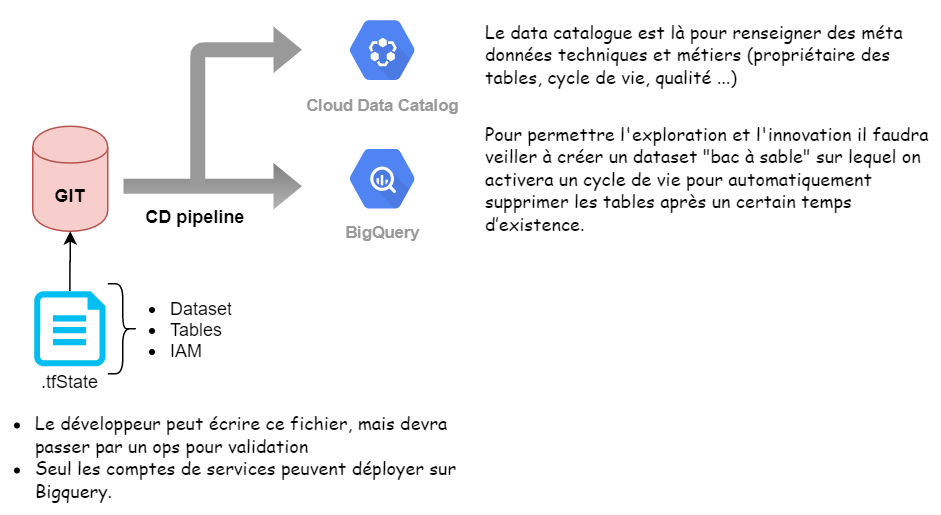
Assez classiquement on adoptera un flow de type gitops pour que les modifications soient tracées et historisées. D’un point de vue consommateur de la donnée un Data Catalog permettra de l’explorer et de la comprendre de manière autonome. Il est donc important d’en tenir compte lors d’un processus de déploiement. On notera au passage que le sujet de cataloging n’est pas propre à la donnée sur BigQuery mais concerne plus généralement la data platform.
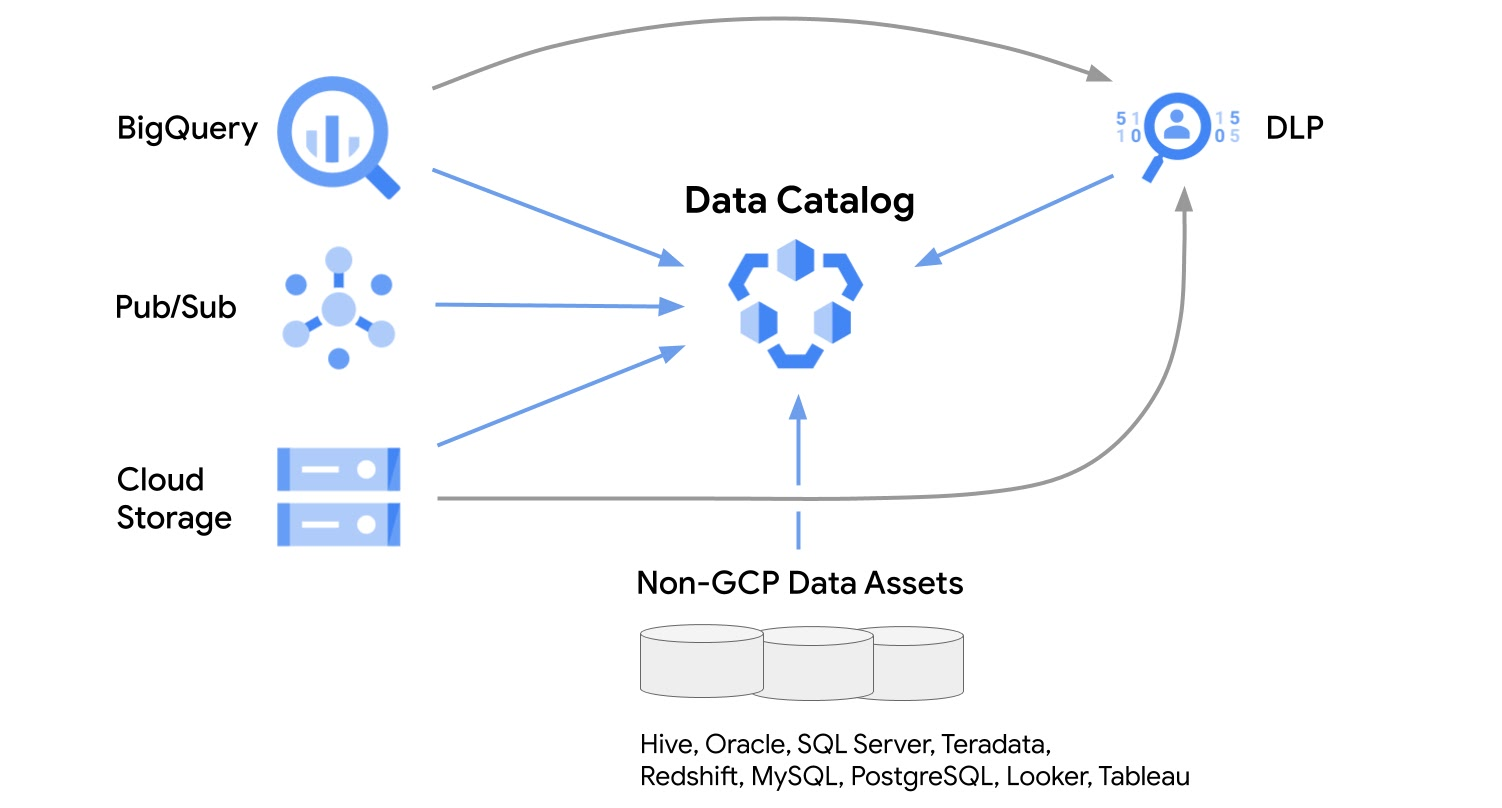
Plus originalement on pourra appliquer le système de boucle de contrôle Kubernetes aux entités Bigquery. GKE offre à ce titre des config connectors dont les datasets et tables Bigquery sont des ressources accessibles.
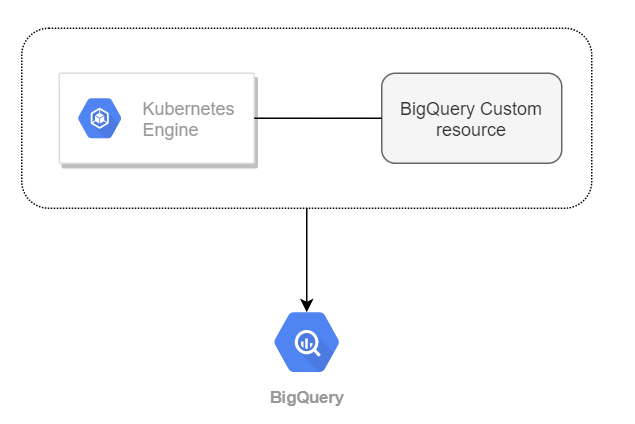
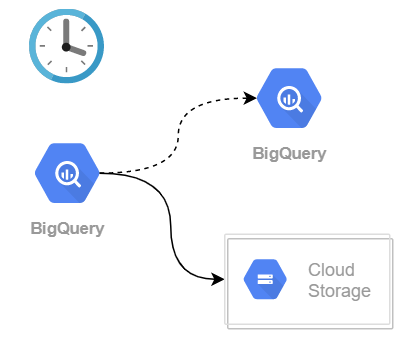
Attention, ce contrôle ne doit pas se faire aux dépens de l’exploration et de l’innovation. Un développeur et/ou data-analyste est en besoin permanent de créer des tables éphémères.
Un contrôle trop rigide freinera l’usage et donc les bienfaits de BigQuery.
Des datasets bac à sable permettront de répondre aux besoins des autres métier, les ops garantissant alors l'infrastructure finale de la donnée plutôt que son état intermédiaire et donc éphémère.
La mise en place de politique de backup complètera le cycle de vie de la donnée. La récurrence pourra être géré avec des outils tels que cloud scheduler. Google met en avant GCS comme plateforme de sauvegarde de données. On peut aussi simplement penser à BigQuery qui pour un coût acceptable permettra d’analyser instantanément ses backups en cas de besoin.
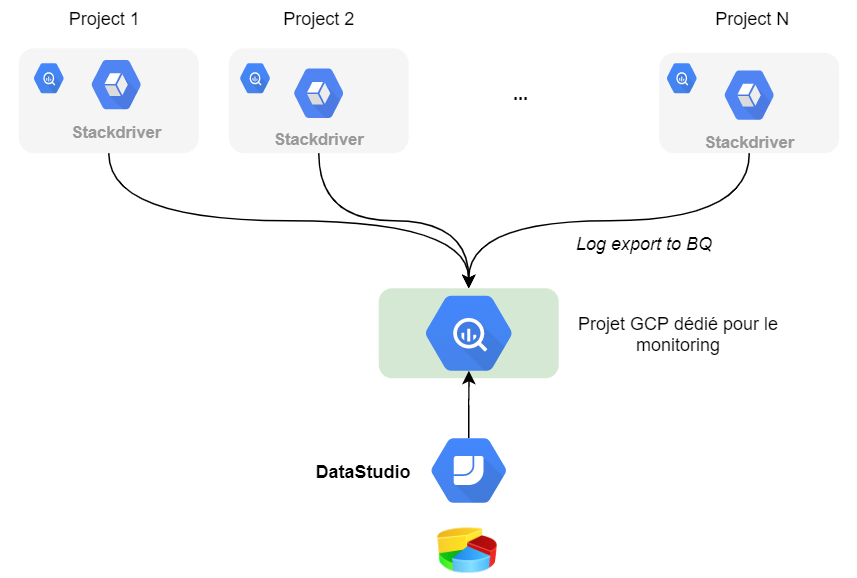
Concluons sur la partie contrôle des coûts. Stackdriver permet d’exporter les logs BigQuery dans... BigQuery pour y brancher un outil de dataviz.
Datastudio faisant parfaitement l’affaire pour ce cas d’usage.
Gros grain, le rôle d’un data engineer s’apparente à celui de porteur de donnée. Travaillant en étroite collaboration avec les data scientists et analystes, il doit industrialiser l’extraction de la donnée, son nettoyage et son accessibilité. On parle de pipeline ETL (Extract Transform & Load) pour décrire son unité de travail.
BigQuery étant la plateforme utilisée par les analystes, il apparaît naturellement comme un datasink, c’est-à-dire comme une plateforme où la donnée sera “livrée”.
Par conséquent, nous voyons souvent l’association de technologies de pipeline telles Apache Beam, Spark ou Hadoop avec BigQuery.
Ce que décrit le schéma ci-dessous.
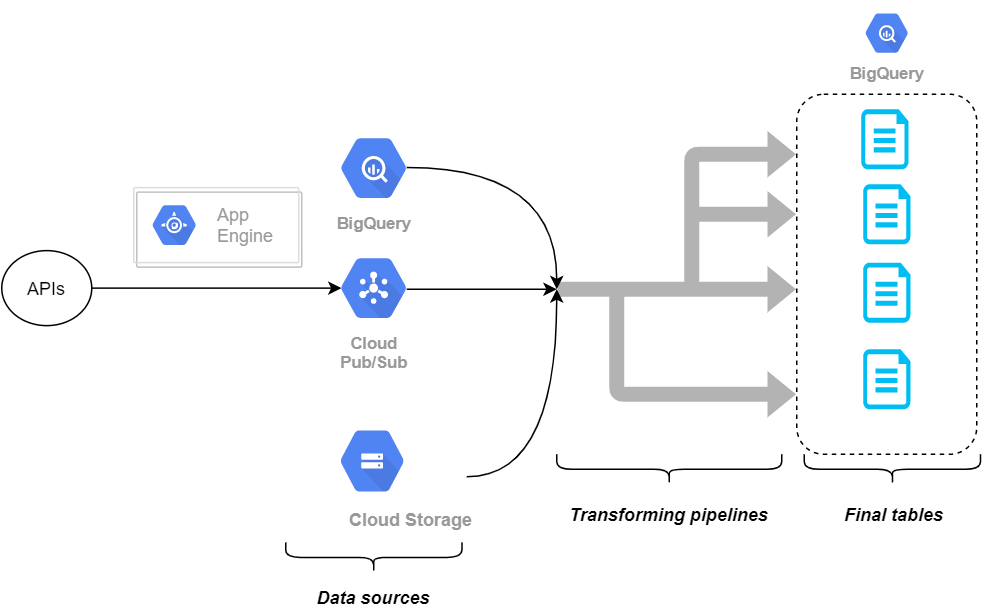
ETL : A gauche, les sources de donnée (Extract), au milieu les transformations (Transform), à droite BigQuery (Load)
Ce schéma est challengé par l’approche ELT (Extract Load Transform). Lorsque le datasink offre de bonnes performances en temps de réponse, il peut être opportun d’y déporter les opérations de transformation et ainsi se substituer à Beam, Spark et autres. Dans notre cas, les transformations seraient portées par des requêtes BigQuery. Cette simplification se fait au prix d’une dépendance plus forte à BigQuery et d’un nouveau besoin d’orchestration auquel Apache Airflow répondra.
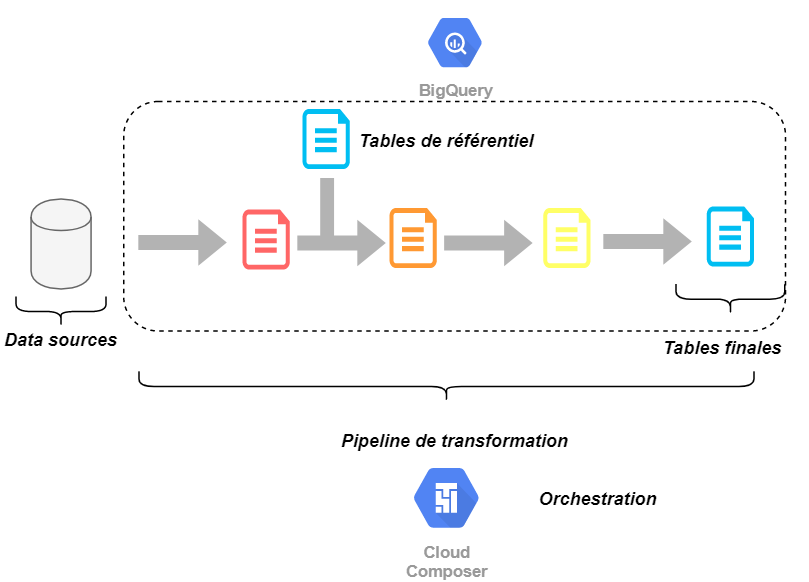
ELT : A gauche, les sources de donnée (Extract), un chargement de la donnée brute dans BigQuery (Load), puis une suite de transformation par requêtes BigQuery (Transform)
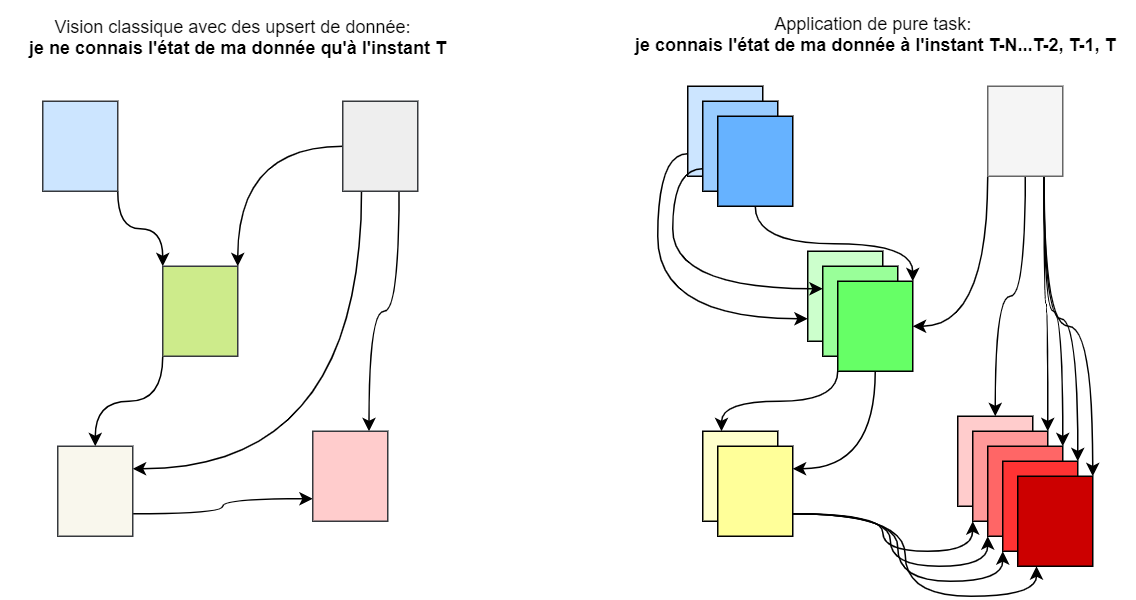
Afin d’avoir la propriété de rejouabilité des transformations et donc de généalogie de la donnée (data lineage), un data engineer cherchera à appliquer le concept de pure task. Ceci peut faire l’objet d’un article entier et nous comprendrons ce concept comme étant le pendant data de pure function dans la programmation fonctionnelle. Dans ce paradigme, la donnée y est immutable et, à sources identiques, une transformation donne systématiquement le même résultat (idempotence). Toute opération de type UPSERT, synonyme de mutation, est interdite et la partition d’une table devient l’unité de changement.
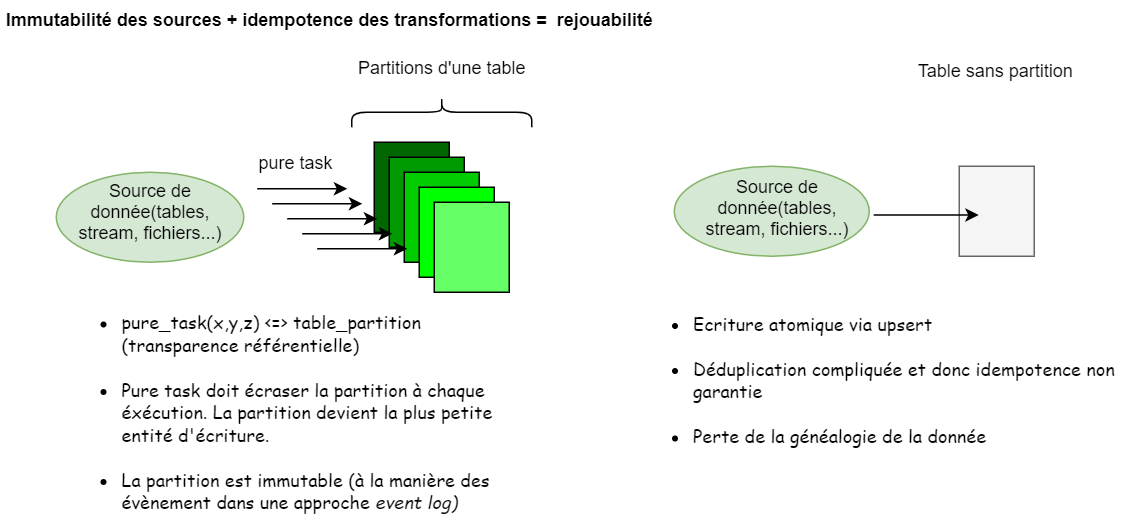
Pour plus de détails je ne saurai trop vous conseiller la lecture de cet article.
Voici comment peut se décliner un pipeline ELT avec ce concept. On notera que chaque instanciation d’une pure task à son propre chemin nommé dérivation afin d’éviter tout effet de bord et ainsi garantir l’idempotence.
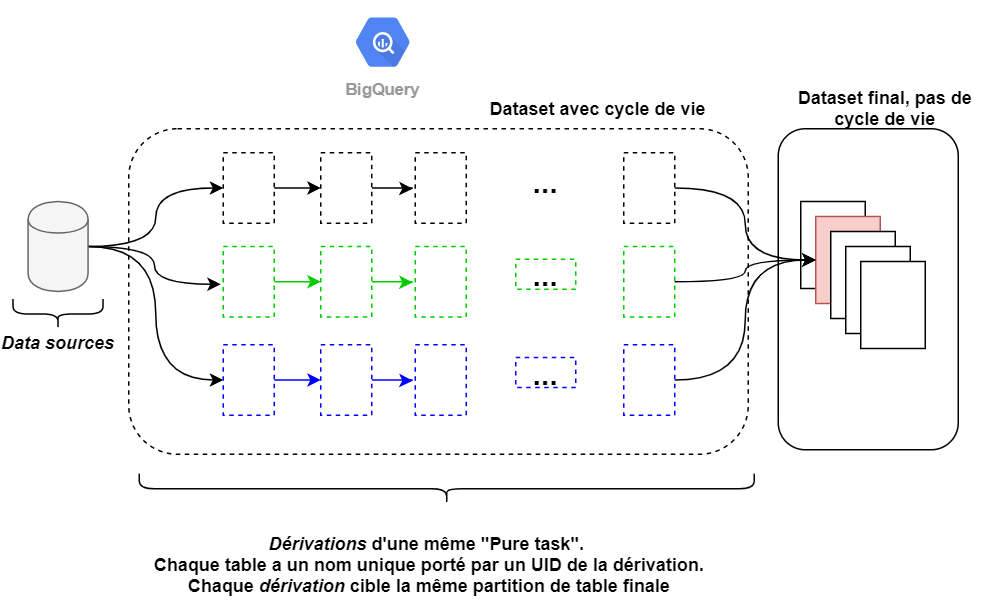
Dans BigQuery les partitions sont limitées à 4000 par table au moment d’écrire ces lignes et se font sur des colonnes de type date ou entier. Dans le cas de la date, la partition se fera à la granularité de la journée uniquement. Cette limitation impose surtout à notre pipeline de transformation un couplage fort avec BigQuery dont il faut avoir conscience. Appliquer ces propriétés demande une réflexion et un travail supplémentaire. Cela est nécessaire car le rôle d’un data engineer n’est pas juste de livrer de la donnée transformée. C’est aussi d’en garantir l’intégrité, la qualité et la rejouabilité.
Enfin, il est à noter l’existence d’un langage de scripting BigQuery (Data Modelling Language et Data Definition language) qui offre des possibilités supplémentaires pour la définition et la transformation de sa donnée.
Néanmoins, on peut penser que ces options sont plus à destination de profil data administrateur reconverti dans du datawarehousing permettant une transition plus douce.
Une fois la donnée livrée vient la phase d’exploration. Ce rôle est généralement attribué aux data scientists et analystes. BigQuery offre certes des temps de réponse performants sur des volumes de données gigantesques mais cela ne se fait pas sans adapter son schéma de donnée.
La normalisation de la donnée est couramment utilisée dans un souci de mutualisation de la donnée. Une table unique n’aura pas de sens métier. C’est sa jointure avec d’autres tables qui donnera du sens métier et permettra l’exploration de la donnée.
Une règle non officielle de BigQuery serait d’en limiter son usage en dénormalisant la donnée quitte à la dupliquer, l’argument étant que le stockage de la donnée étant bien moins cher que son compute.
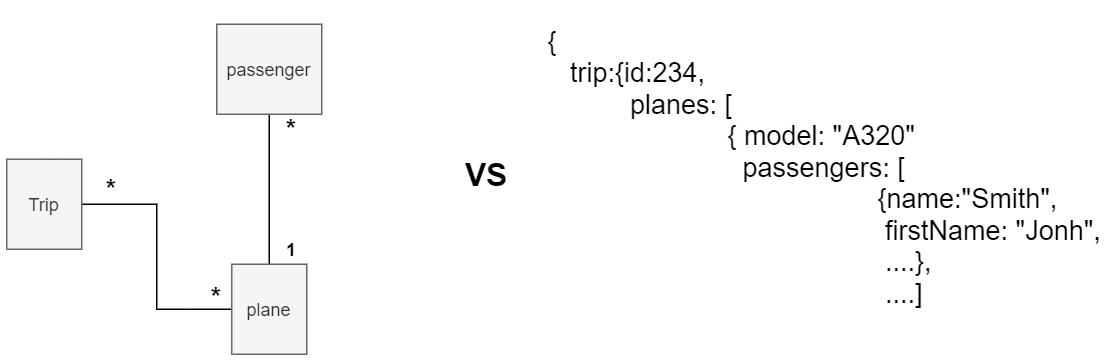
Ainsi, il est possible d’injecter dans une table des donnée semi-structurée dont le niveau d'imbrication peut aller jusqu’à quinze. Les data scientists doivent prendre en compte ce fait dans la définition de leur modèle mais aussi de leur requête qui devra utiliser des mots-clés particuliers pour disjoindre la donnée.
Cet article est très éclairant sur ce point.
Lorsque nous discutions du coût, nous parlions d’adaptation de l’utilisateur à la technologie. Ce que nous entendons par là, c’est d’apprendre de nouveaux réflexes de travail. Éviter des scans entiers de table, utiliser le cache, penser à regarder la prédiction de volume de donnée scannée sur chaque requête, sont autant de nouveaux points à prendre en compte. La console BigQuery est aussi un outil collaboratif qu’il faut savoir mettre à profit en partageant ou sauvegardant ses résultats de requêtes. Enfin, il faut savoir bénéficier du continuum technologique de Google avec les intégrations des plateformes Tensorflow et Datalab pour ne pas les citer.
Le choix d’une technologie et plus encore, d’une plateforme de Data Warehouse est lourd de conséquence. C’est un choix qui se mûrit et se pèse en fonction de contextes, d’affinités, de capacités, etc.
BigQuery fascine et effraie à la fois. Fascine car ses performances et sa facilité d’utilisation ont peu d’équivalent sur le marché. Effraie, car son coût et son lock-in nourrit beaucoup de fantasmes, fondés ou non.
Ces deux points sont à nuancer. La performance n’est en effet pas garantie. Il faut se plier à certaines règles pour en avoir tout le potentiel et ce travail doit être quantifié avant toute prise de décision.
A contrario, le coût est un faux débat. BigQuery propose des leviers nombreux et variés pour atténuer significativement son coût. Il ne faut pas non plus oublier que nous sortons de plusieurs décennies de Big Data Appliance dont le coût s’élevait à plusieurs millions d’euros par an avec un lock-in évident. BigQuery est un progrès énorme à ce niveau-là. En demander la quasi gratuité car le cloud à la réputation d’être peu cher n’est pas raisonnable.
Le même raisonnement peut être appliqué au lock-in. Reconnaissons tout de même qu’en utilisant BigQuery se pose inévitablement la question de la propriété de la donnée puisqu’elle doit se trouver dans BigQuery pour pouvoir être manipulée.
Des approches concurrentes et open-source vous laisseront le choix. Nous pensons notamment à Presto ou encore DataBricks (SparkSQL + Delta-io). Mais vous ne retrouverez pas pour autant le même degré “As A Service” offert par BigQuery. D’autres solutions “As A service” existent mais retombent dans le débat du lock-in, comme SnowFlake par exemple.
Vous l’aurez compris, il n’y a pas de solution parfaite. Il y a des solutions adaptées à des contextes et nous espérons que cet article offre des pistes de réflexion.
BigQuery a été, est, et nous pensons qu’il restera. Il s’agit d’un produit stratégique pour Google.
Premièrement car c’est ce que nous pourrions qualifier de produit d’appel d’offre. Fort de promesses alléchantes en termes de performance, c’est un des seuls produit cloud existants qui soit en mesure à lui seul de justifier l’adoption d’un fournisseur cloud.
Ensuite, parce qu’il est courant que le choix d’un fournisseur cloud soit fortement guidé par “où se situera ma donnée”. Il est aisé de comprendre qu’une donnée hébergée sur la GCP sera très facilement consommable par la suite de services de ce même fournisseur, et que donc nous y mettrons aussi notre compute.
Enfin, à travers BigQuery, Google veut démocratiser l’usage de concepts plus complexes à prendre en main tel que le data engineering et le machine learning.
Bien entendu tout n’est pas rose dans ce monde du Big Data made in Google. Des contraintes ici et là peuvent ternir le tableau idyllique qui nous est vendu. Nous pensons moins aux contraintes d’ordres techniques ou financiers qui peuvent être mitigées voire dépassées avec l’évolution du produit.
Non, nous pensons à des contraintes plus profondes telles que la propriété de la donnée, sa localisation, etc. En définitif, BigQuery est un produit qui a toujours su garder une avance sur son temps et dont l’usage pour des utilisateurs avertis est un réel plaisir.

Kubernetes est aujourd’hui un outil de gestion de conteneurs incontournable, présent chez tous les grands fournisseurs de cloud. Il existe plusieurs...

Définitions Connaissez-vous le Confused Deputy Problem ? Il s’agit d’une vulnérabilité dans laquelle une entité qui n’a pas l’autorisation...

Dans le paysage dynamique de l'informatique du Cloud, la gestion dynamique et agile des conteneurs est devenue essentielle pour les entreprises...