 Ismael HOMMANI
Ismael HOMMANI


Dans l’un de nos précédents articles, nous parlions de Google BigQuery comme d’un service différenciateur pour la Google Cloud Platform. Ses performances alliées à sa facilité d’utilisation en font une solution de choix dans le marché des Data Warehouse. Le succès de BigQuery ne doit rien au hasard et nous avons vu que disruption technique, facilité d’utilisation et communication font partie d’un cocktail nécessaire au succès commercial. Nous employons le mot nécessaire car l’exemple d’un autre service démontre que ce n’est pas suffisant.
Nous pensons en particulier à Dataflow, qui malgré ses apports théoriques dans le traitement de flux de données et son modèle opérationnel serverless, ne trouve toujours pas sa vitesse de croisière en terme d’adoption. Pourtant son lien fort avec le framework Apache Beam, sa robustesse et sa facilité d’utilisation plaident en sa faveur. Il est cependant intéressant de constater que les technologies qui le précèdent, Spark en premier lieu, mais aussi Hadoop, sont toujours là et semblent l’être sur le long terme.
Afin de comprendre la thèse de cet article, il est nécessaire d’introduire dans un premier temps les concepts de batch et data streaming. S'ils sont complexes, cela n’en reste pas moins des sujets passionnants tant dans leur évolution que dans ce qu’ils permettent de faire. Il sera alors possible de réfléchir à la situation de Dataflow et l'avenir que nous pouvons lui imaginer.
Batch et Stream processing, des similitudes au delà des différences
Dataflow est ce qu’on appelle un moteur de stream processing. Par processing entendons “action” et par stream “données en mouvement”. Prenez l’exemple d’un robinet ouvert sous lequel nous placerions différents tamis pour y mettre des additifs. En filant la métaphore nous nous rendons compte que le débit du robinet ne s’arrête jamais. La donnée que nous traitons n’est donc pas bornée en nombre d’éléments.
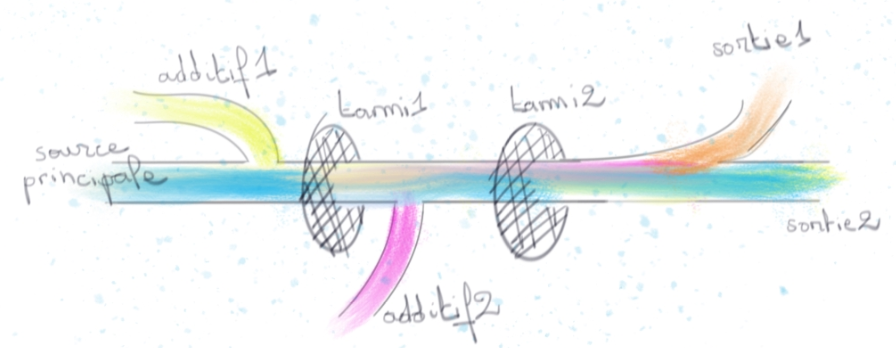
Historiquement cette approche est opposée à celle de “batch processing” dont la différence principale est de traiter de la donnée en quantité bornée.
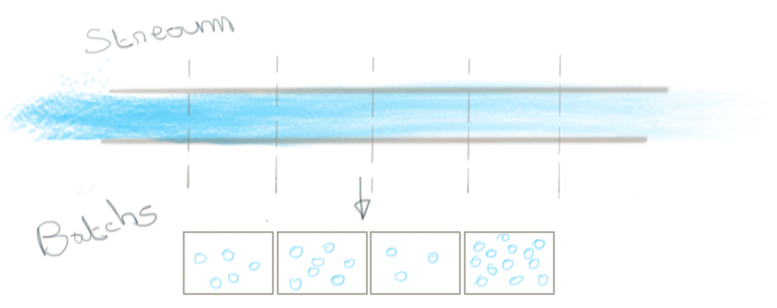
Pour autant, ces deux approches ne sont pas assignées à résidence. En discrétisant un flux de données en une succession infinie de blocs bornés (et nous omettons de dire sous quelle dimension pour l’introduire plus tard), un moteur de batch peut traiter des flux de données non bornées. L’infini y est un cas particulier du fini.
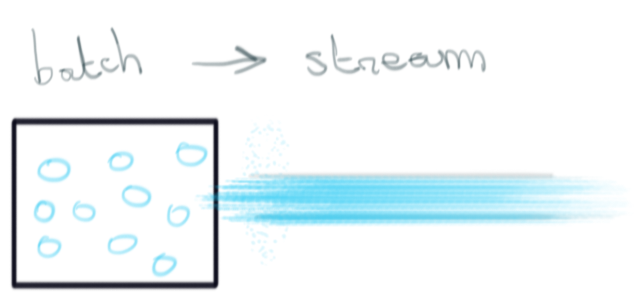
Inversement, en considérant le stream comme une vue élément par élément de l’évolution d’un dataset à travers le temps, i.e. comme de la donnée en mouvement, le batch qui consiste à faire passer de la donnée d’un état A à B peut être vu comme du streaming. Le fini est un cas particulier de l’infini.
Est-ce pour autant dire que c’est blanc-bonnet et bonnet blanc ? Non, et l’historique de ces approches va nous permettre de comprendre pourquoi.
Petit historique du data processing
Au début des années 2000, le data processing se concevait essentiellement à travers du batch processing. La donnée était collectée dans un datawarehouse pour ensuite être travaillée.
Google, à travers MapReduce a permis de sortir du modèle des appliances pour utiliser du hardware plus classique tout en améliorant les performances de l’ancien modèle. Cela inspira une communauté qui donna naissance à Hadoop. Technologies à la pointe, elles permettaient de traiter de la donnée à l’échelle du Tera voir du Pétabyte dans des délais “courts” tout en garantissant une cohérence forte de la donnée et donc un résultat précis.
Néanmoins, le manque d’agilité opérationnelle et le besoin de code spécifique se sont vite avérés être des freins pour une adoption consensuelle et la collaboration entre équipes. À cela s’ajoute le besoin de traiter des flux de données en temps réel, chose non gérée à l’époque.
Deux visions se sont proposées pour répondre à cette problématique. L’une étant de discrétiser le flux de données en blocs de données finis à traiter en batch (qu’on appellera micro-batchs) tout en estompant les défauts de jeunesse des moteurs de batch. La seconde étant d’embrasser la nature infinie du stream à travers un nouveau paradigme. Dans ce dernier cas, la faible latence était atteinte en faisant des concessions sur la cohérence de la donnée lors des traitements. Le résultat final était là “rapidement” mais plus ou moins digne de confiance du fait de potentielles duplications dans le traitement de la donnée. Une approche était donc d’associer ce système à celui du batch pour avoir “rapidement” des résultats “probables” dans un premier temps, complétés par des résultats “sûrs” lorsque toutes les données ont été collectées.
Cette architecture dite “lambda” a pour inconvénient d’imposer de travailler avec deux technologies différentes et surtout de devoir se baser sur des résultats plus ou moins fiables pendant un certain temps.
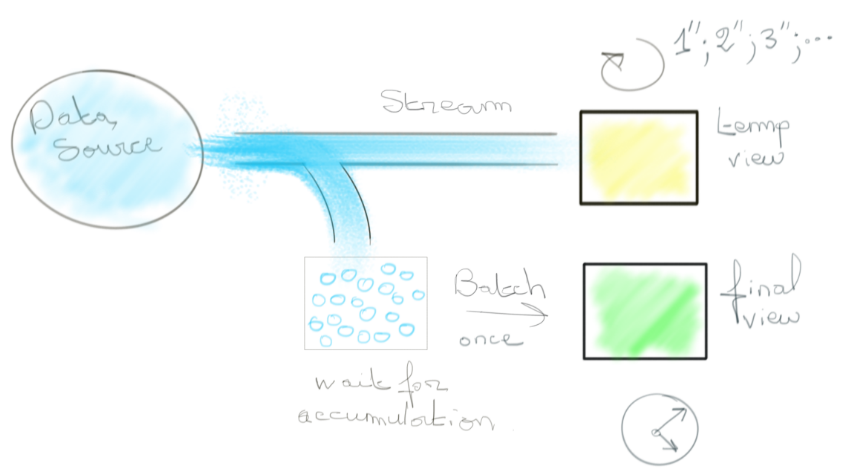
Le besoin de fusionner le meilleur des deux mondes (latence et exactitude) s’est vite fait ressentir. Nous revenons donc sur la première vision dont Spark est devenu l’implémentation la plus aboutie. En transformant un stream de données en une suite infinie de micro-batch, Spark permit de retrouver les même garanties offertes par du batch classique (high throughput and strong consistency) avec une latence à la minute, voire la seconde. C’est la naissance de Spark Streaming. Les puristes insistent sur le fait qu’il ne s’agit pas stricto sensu d’un moteur de streaming car la nature infinie du stream est effacée, ce qui a des implications au-delà des concepts.
En effet, jusqu’à présent nous opposons les moteurs de batch et de streaming par la matière sur laquelle ils travaillent. Respectivement de la donnée bornée opposée à une suite infinie d’éléments. Un glissement conceptuel permettant à l’un d’opérer sur du stream et l’autre sur du batch.
En considérant des moteurs de streaming matures tels Flink et Dataflow, ce qui va les distinguer c’est leur capacité respective à penser le temps associé aux éléments traités.
La dimension temporelle, clé de voûte de la différenciation batch/stream processing
Lorsqu’un moteur de batch processing discrétise l'infini, il le fait sur la dimension temporelle. Les éléments passant dans le pipeline sont regroupés par fenêtres temporelles fixes et contiguës qui ont dès lors un nombre fini d’éléments. Pour classifier les éléments dans ces différentes fenêtres temporelles, on utilisera le “processing time” de ce dernier. Il s’agit simplement du temps à partir duquel l'élément est “observé” dans le pipeline.
Note : A ne pas confondre avec le temps d’ingestion de l’élément qui est figé tout le long du pipeline, là où le processing time croît avec l’avancée de l’élément dans le pipeline.
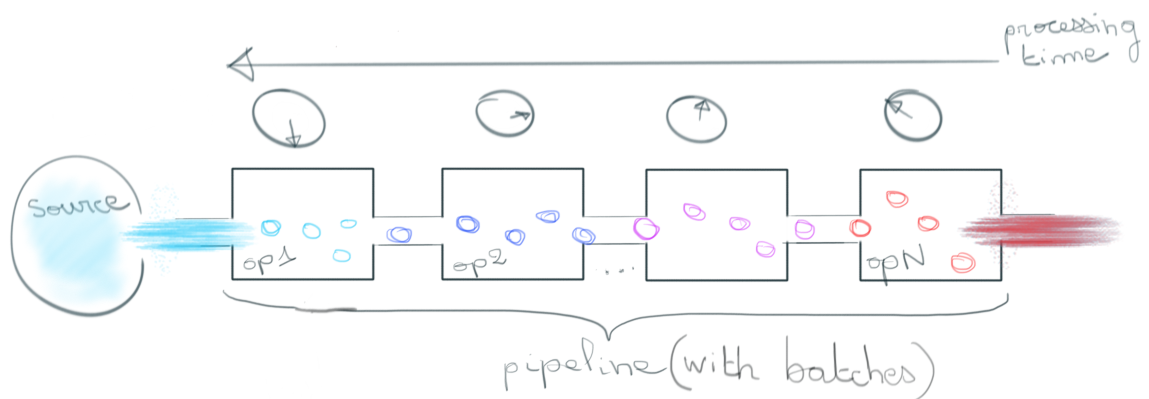
Cette approche est idéale si les transformations que l’on applique sont agnostiques au temps. Filtrage et opérations de jointure en sont de bons exemples.
Dans le cas contraire, elle implique des hypothèses fortes :
- Les éléments de notre stream de données sont ordonnés selon leur instant de création (event time)
Sans cette hypothèse, il est possible de fournir des résultats incohérents avec la réalité. En notifiant par exemple d’une hausse d'activité sur une fenêtre temporelle (de processing time) qui mélange des éléments dont les instants de création sont trop distants entre eux pour pouvoir considérer un pic d’activité effectif dans le monde réel.

- La latence entre cet instant de création et l’instant d’observation dans le pipeline est raisonnable
Nous faisons référence aux éléments “en retard”. Pour avoir un résultat le plus cohérent possible avec la réalité il faut avoir une certaine tolérance aux retards dûs par exemple à des latences du réseau. Autrement nous pouvons manquer une part substantielle d’éléments pour une prise de décision.
Certaines sources de données sont adaptées à ces partis pris comme par exemple Kafka. D’où le succès du binôme {Kafka, Spark}.
Mais la réalité étant ce qu’elle est (les éléments sont non ordonnés et arrivent de manière non prédictive), ce genre d’hypothèse ne peut être garantie. Il faut à un moment donné pouvoir raisonner sur l’exhaustivité de la donnée observée et surtout composer avec l’incertitude. Dans le cas {Kafka + Spark} l’incertitude est là mais est cachée par Kafka du point de vue de Spark. Ce qui ne fait que déplacer le problème.
Autre point problématique de l’approche, la coupure entre les différents batchs qui rend complexe la fusion avec de la donnée entre fenêtres successives. C’est pourtant un cas d’usage répandu pour déterminer des sessions d’activité d’un utilisateur par exemple.
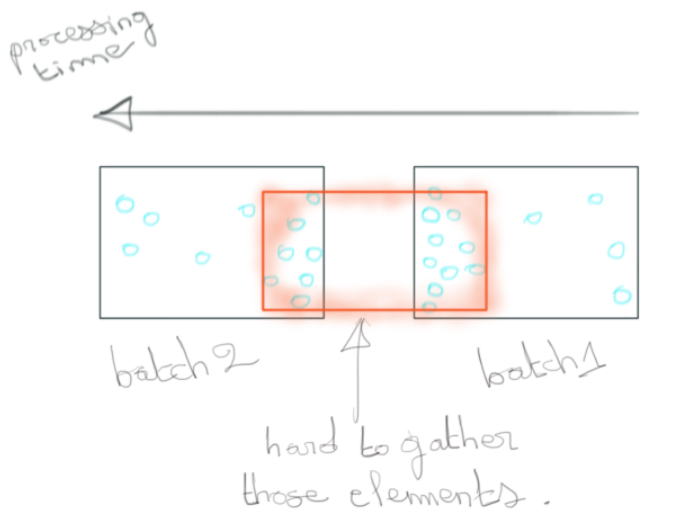
Finalement le temps n’est que purement utilitaire dans cette approche. Il permet “seulement” de regrouper les éléments en fonction de leur instant d’entrée dans le pipeline (création des micro-batches) ce qui n’est pas lié à l’élément en lui-même.
Dans une approche stream processing moderne, on qualifiera la matière à traiter plus volontiers d’évènements que d’éléments. À l’évènement s'arrime deux notions de temps, en supplément de la donnée qu’il porte : son instant de création (event time) et celui de son observation dans le pipeline (processing time). Chacun y joue un rôle tout aussi important. Assez logiquement, sans donnée il n’y a pas de transformation. Les deux dimensions temporelles permettent quand à elle de composer avec les incertitudes précédemment citées selon un modèle que l’on peut résumer en substance par les points suivants :
- Raisonner sur l’event time de la donnée
On groupe les événements sur leur “event time” plutôt que leur “processing time”. Nous gardons le nom de fenêtre temporelle pour définir ces regroupements. - Raisonner sur l’exhaustivité de la donnée
En fonction de la source de la donnée considérée, il faut être capable de proposer des modèles heuristiques pour représenter assez finement la notion de progression d’arrivée des évènements.
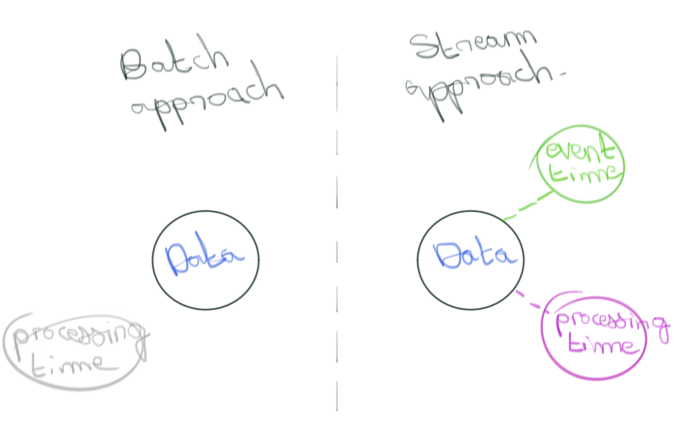
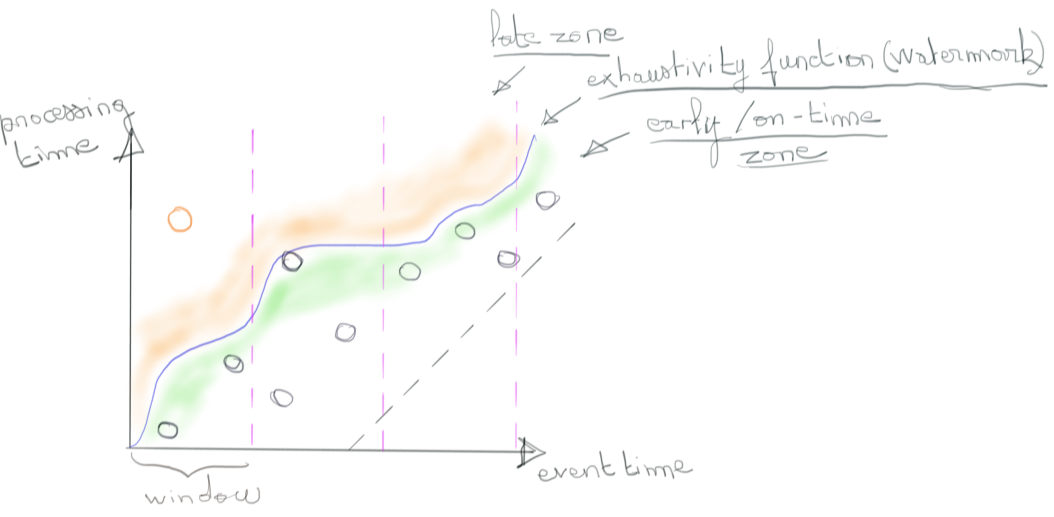
C’est l’approche de Dataflow. Avant de l’évoquer plus en détail dans la partie dédiée à Apache Beam, revenons sur un point important. Le stream processing à ses débuts faisait des concessions importantes sur la qualité des résultats fournis. Ce n’est plus le cas. La cohérence des résultats fournis ainsi que le débit de donnée traitée rejoint ce que l’on observe dans le batch processing. Cela dit en passant, l’architecture lambda n’a donc plus lieu d’être. Mieux, le modèle de programmation proposé permet d’envisager plus simplement des cas métiers, autrement plus compliqués à traiter avec une approche batch.
La détection de sessions d’activité (pic d’activité, suivi d’une plage de baisse d’activité) qui se détermine à travers les event times d'événements successifs en est un parfait exemple.
Enfin, dans l’esprit “qui peut le plus, peut le moins”, il est aisé pour cette approche de mimer du batch processing en implémentant une fenêtre temporelle “globale”.
Dataflow, un moteur et un SDK
Dataflow est né d’une succession de projets Google dont la genèse est MapReduce. L’expérience acquise sur les Flume, Millwheel et WindMill a permis d’acquérir les caractéristiques offertes par le batch processing (strong consistency, high throughput), tout en proposant un nouveau modèle de programmation. Ne manquait plus alors qu’une abstraction pour manipuler les concepts temporels que nous évoquions. Le Dataflow SDK a eu ce rôle.
Le fait est que les ingénieurs de Google, ainsi que la communauté, pensent sincèrement que leur modèle de programmation de stream processing est la bonne approche. C’est le résultat d’une maturation de plus de dix ans à naviguer entre succès et échecs sur lesquels ils ont capitalisé.
Cette fois, contrairement à MapReduce où Google n’a produit que des papiers, la communauté étant responsable d’en trouver une implémentation (Hadoop), le code de Dataflow SDK a été séparé du spécifique Dataflow et confié à la fondation Apache en tant que Apache Beam. Les raisons sont évoquées ici.
Le moteur reste propriétaire et innove par son approche serverless. Nous ne dirons pas que c’est le plus important d’un point de vue data processing.
Ce qui compte réellement c’est la cohérence des résultats, la latence que l’on peut en espérer et la quantité d'évènements que l’on peut traiter. Néanmoins, d’un point de vue utilisateur l’apport serverless est intéressant tant il permet à ce dernier de se concentrer sur les enjeux business plutôt qu'opérationnels.
Note : Il faut souligner que les équipes de Dataflow ne sont pas les seules à soutenir Apache Beam. Flink est un moteur de streaming open-source tout aussi capable et qui a très tôt adopté les mêmes concepts. L’équipe à son origine a autant été impliquée dans les réflexions autour de Beam que les équipes de Google.
Permettons-nous d’insister sur la différenciation entre Dataflow et Apache Beam.
Dataflow n’est pas Beam et Beam n’est pas Dataflow. Dataflow est encore moins une version managée de Apache Beam. Restons dans les affirmations simples : Beam est une abstraction logique à laquelle Dataflow fournit un environnement d'exécution Serverless. La confusion vient du fait que Dataflow sans Beam n’est pas. Par contre la réciproque n’est pas vraie.

Apache Beam, une ambition
Apache Beam est avant tout un modèle de programmation qui rend le développement hautement distribué sur de fortes volumétries de données en mouvement “simple”. “Simple” relativement à ce qu’il vous serait demandé de faire même avec des frameworks déjà haut-niveau pour l’époque tel Hadoop. Il ne faut en effet pas oublier que derrière tous ces traitements se trouvent des systèmes distribués constitués d’instances de calcul et de mémoire. Tout ce beau monde doit communiquer, se mettre d’accord, économiser les ressources, être tolérant aux pannes pour offrir des caractéristiques telles que le “exactly once processing” associées à une faible latence. Dans les coulisses, c’est tout un système de buffer, de checkpoint, de gestion d’états qui doit être adressé. Voilà quelque chose que l’on ne qualifierait pas de “simple”. Le tour de force d’Apache Beam est de réussir à cacher cela. C’est aussi une couche d’abstraction qui ambitionne de devenir le “parler commun” du stream et batch processing. En général, nous parlons de moteur de batch ou de stream comme d’entité monolithique. En réalité, à côté du moteur se trouve un modèle de programmation permettant d’exprimer les opérations souhaitées et qui est compatible avec le moteur.
Dataflow avait son Dataflow SDK, Spark son API associée à Spark Core, etc.
Le passage de l’un à l’autre implique donc de maîtriser, sinon un langage différent, au moins une API différente. Apache Beam propose d’unifier l’ensemble de ces moteurs derrière une API commune. Plus besoin de réécrire son programme pour Spark, Dataflow, Flink ou autre pourvu que le moteur sous jacent soit supporté par le SDK Beam. Cela suppose évidemment que les moteurs d'exécution jouent le jeu et Beam précise d’emblée le propos. Il ne s’agit pas de trouver le modèle minimum dénominateur commun entre tous les moteurs d'exécution. Son idée est plutôt de permettre un support API des “meilleures” idées que l’on peut retrouver dans les différents moteurs de streaming et à son tour d’en proposer pour orienter le développement des moteurs.
L’idée étant que les moteurs ne jouant pas le jeu se coupent des utilisateurs de Beam. Beam a donc non seulement une vision unificatrice du traitement batch et stream, mais aussi des moteurs de data processing disponibles sur le marché. Pour les développeurs c’est la garantie de n’écrire qu’une seule fois son code et pour les décideurs d’adhérer à une technologie à l’épreuve du futur.
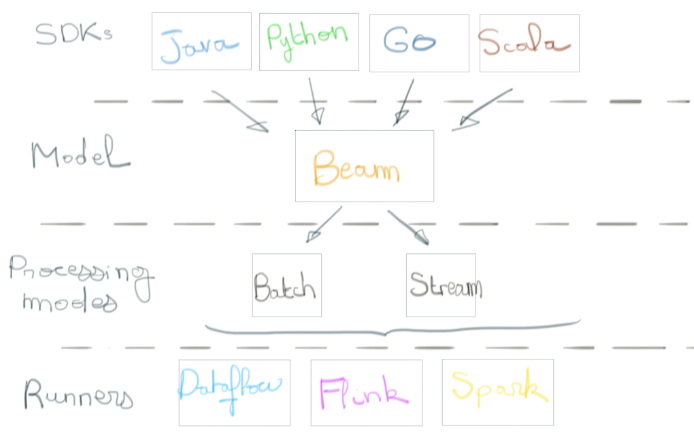
La matrice de compatibilité entre le modèle Beam et différents moteur de Data processing.
Encore faut-il adhérer à la vision Beam de ce qu’est le data streaming. Essayons d’en extraire les points principaux, tout en laissant aux articles fondateurs le soin d’aller dans le détail pour ceux qui le souhaitent. Streaming 101 et 102.
Apache Beam, un modèle de programmation
À haut niveau, Beam vous permet de trouver dans la transformation de la donnée un compromis entre les notions suivantes :
- Rafraîchissement des résultats
À quelle fréquence je souhaite avoir des résultats de mes opérations de transformation ? - Exactitude
Quel degré de tolérance ai-je vis-à-vis des données manquantes ? - Coût
Corollaire direct des deux questions précédentes, en fonction de ce que l’on souhaite privilégier il en coûtera plus au moteur en terme de compute, network et mémoire.
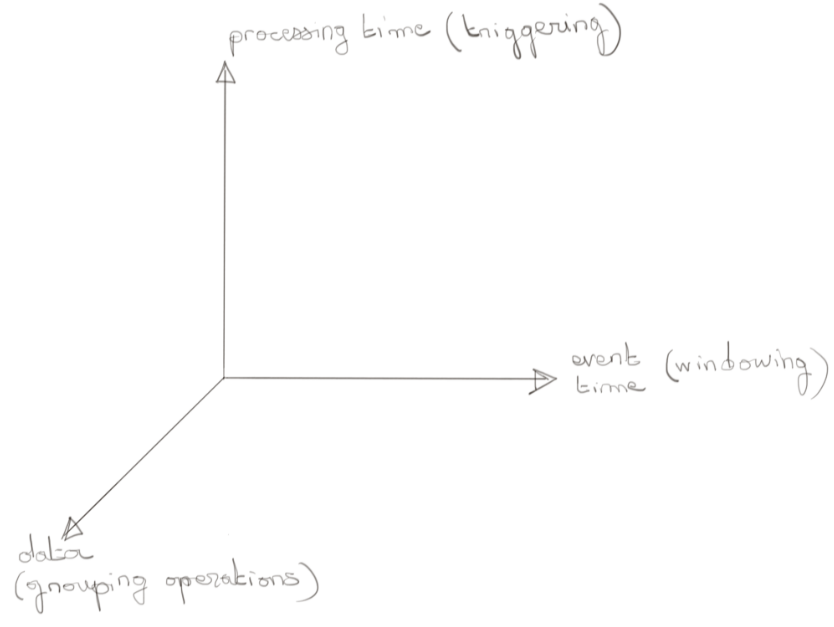
Les initiateurs du projet Apache Beam résument le modèle à travers quatre questions :
- What
Quelle(s) opération(s) vais-je appliquer sur la donnée ? (filtering, grouping, datasink,...) - Where
Dans quelle fenêtre d’event time cette opération se situe ? - When
Sur quelles conditions le résultat du “What” se produit ? Sur un déclencheur associé au processing time ? Sur la complétude de la donnée de ma fenêtre temporelle ? L’arrivée d’un événement ? Un mélange de tout ça ? - How
Par quelle accumulation lie-t-on les résultats successifs d’une même fenêtre d’event time ?
Ces questions seront le fil conducteur de tout pipeline construit avec Beam.
Beam va nous donner des éléments conceptuels pour répondre à ces questions. Cet article n’a pas vocation à être une redite d’articles que nous avons précédemment cités mais insistons néanmoins sur un point qui selon nous distingue Beam de la concurrence, à savoir son système de fenêtre temporelle (Windowing). Une window, ou fenêtre temporelle, est ce qui va permettre de regrouper des événements par instant de création (event time) pour appliquer une opération au sous-ensemble d'événements appartenant à cette dernière. Autrement dit, c’est ce qui permet de raisonner sur des données arrivant dans le désordre.
Le cas simple est d’en donner une taille fixe et de les aligner entre elles.
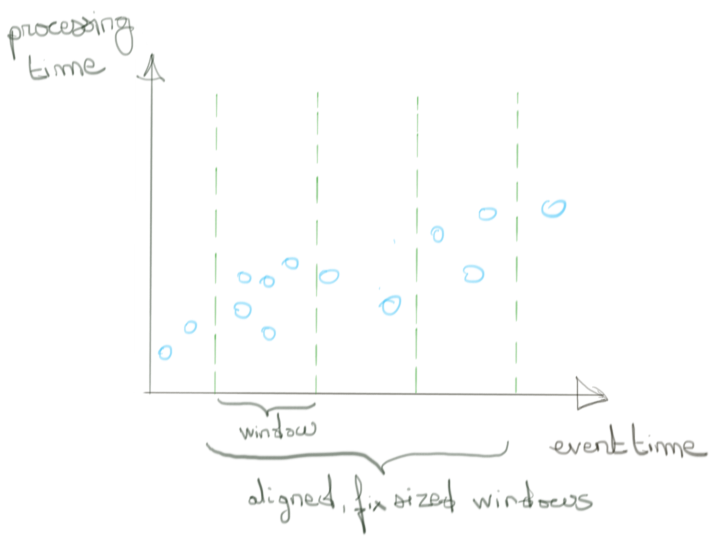
Un cas plus complexe est d’en garder une taille fixe en en retirant l'alignement. Ce sont des fenêtres glissantes.
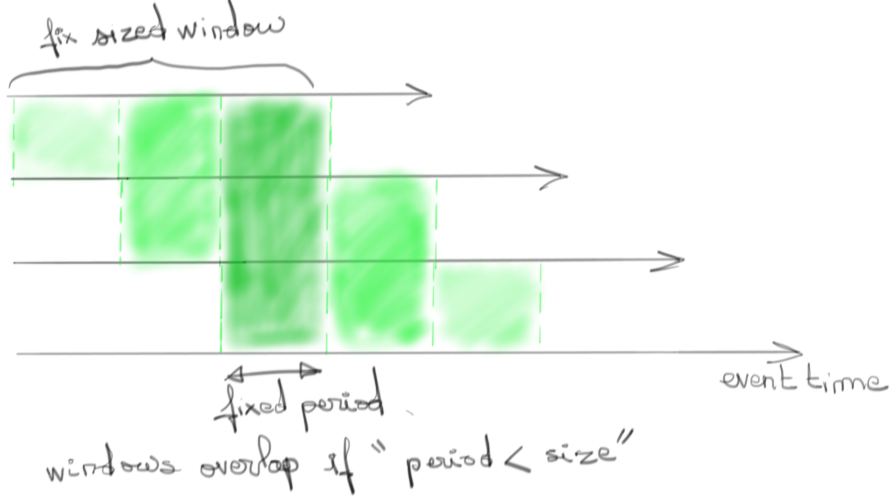
Là où Beam brille par sa simplicité, c’est sur la création de fenêtres à taille dynamique. Nommée Session window, il suffit au concepteur du pipeline de définir un laps de temps maximum (sur l’event time) entre deux événements pour les considérer comme appartenant à une même fenêtre et donc une même “session”.
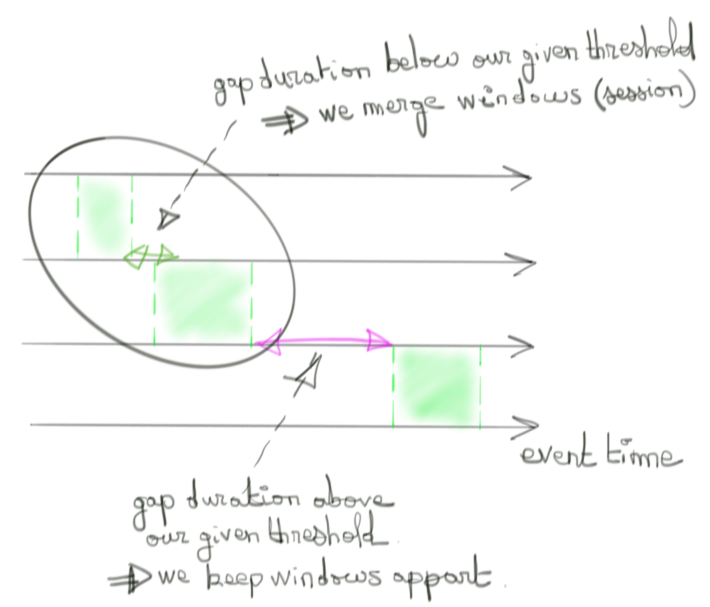
Ces modes de fenêtre par défaut sont utiles mais peuvent impliquer des problèmes de performance. Dans le cas des fenêtres alignées par exemple, déclencher le calcul d’un résultat sur un même “processing time” va soumettre le moteur sous-jacent à une forte charge de calcul. Dans le cas d’une session, rien ne l’empêche de grandir indéfiniment impliquant le même genre de problème. C’est pour cela que Beam permet de construire sa propre logique de fenêtre temporelle pour laisser court à l’imagination du développeur. Soulignons que cette possibilité est une des forces principale du modèle : guider l’utilisateur à travers des cas usuels mais ne pas le contraindre non plus en lui permettant d’adapter simplement ce modèle à son contexte. Cela peut consister à définir une durée maximale de session, ou de mimer des fenêtres alignées sur le processing time plutôt que l'event time.
Signalons enfin que du code Beam se comprend assez bien pour peu que l’on soit à l’aise avec du MapReduce ou le concept de composition de fonctions.
Pipeline p = Pipeline.create(options);
double samplingThreshold = 0.1;
p.apply(TextIO.read().from(options.getWikiInput()))
.apply(MapElements.via(new ParseTableRowJson()))
.apply(new ComputeTopSessions(samplingThreshold))
.apply("Write", TextIO.write().to(options.getOutput()));
p.run().waitUntilFinish();
Des performances et propriétés intéressantes, un modèle simple et agile, et enfin une ambition à lier le batch processing au stream processing à travers un langage commun à différents moteurs de data processing.
Beam a de nombreux atouts à faire valoir. Mais sont-ils entendus dans la communauté de data engineering ?
Et la concurrence ? Hadoop l’ancien et l’ogre Spark
Le monde du data processing est vaste et il est compliqué d’être exhaustif dans la comparaison de l’adoption de Beam par rapport à sa concurrence. Nous préférons donc nous attarder sur le cas de deux géants du domaine que sont Hadoop et Spark. Plusieurs précisions s’imposent.
Techniquement parlant comparer Beam à Spark ou Hadoop n’a pas trop de sens. D’un côté, nous avons un modèle de programmation, de l’autre deux écosystèmes. Il serait par exemple plus juste de comparer Spark à {Beam + Dataflow}. Pourtant dans le parler-commun, cela a du sens tant finalement ces trois termes se réfèrent plus à des visions qu’à des entités techniques. C’est donc du point de vue vision que l’on se placera. Autre point qu’un lecteur attentif aura sûrement remarqué : il devient moins question dans cet article de Dataflow que de Beam. Cela est voulu et motivé par le fait que Dataflow est très lié à Beam (et nous avons vu que la réciproque n’est pas vraie). Avoir une vision de l’adoption de Beam nous permettra de raisonner sur l’adoption de Dataflow. Extrapolons donc les Google Trends avec adoption d’une vision en considérant que plus un terme apparaît, plus il est populaire parmis la communauté de développeur. Positionnons en premier lieu Hadoop par rapport à Spark.
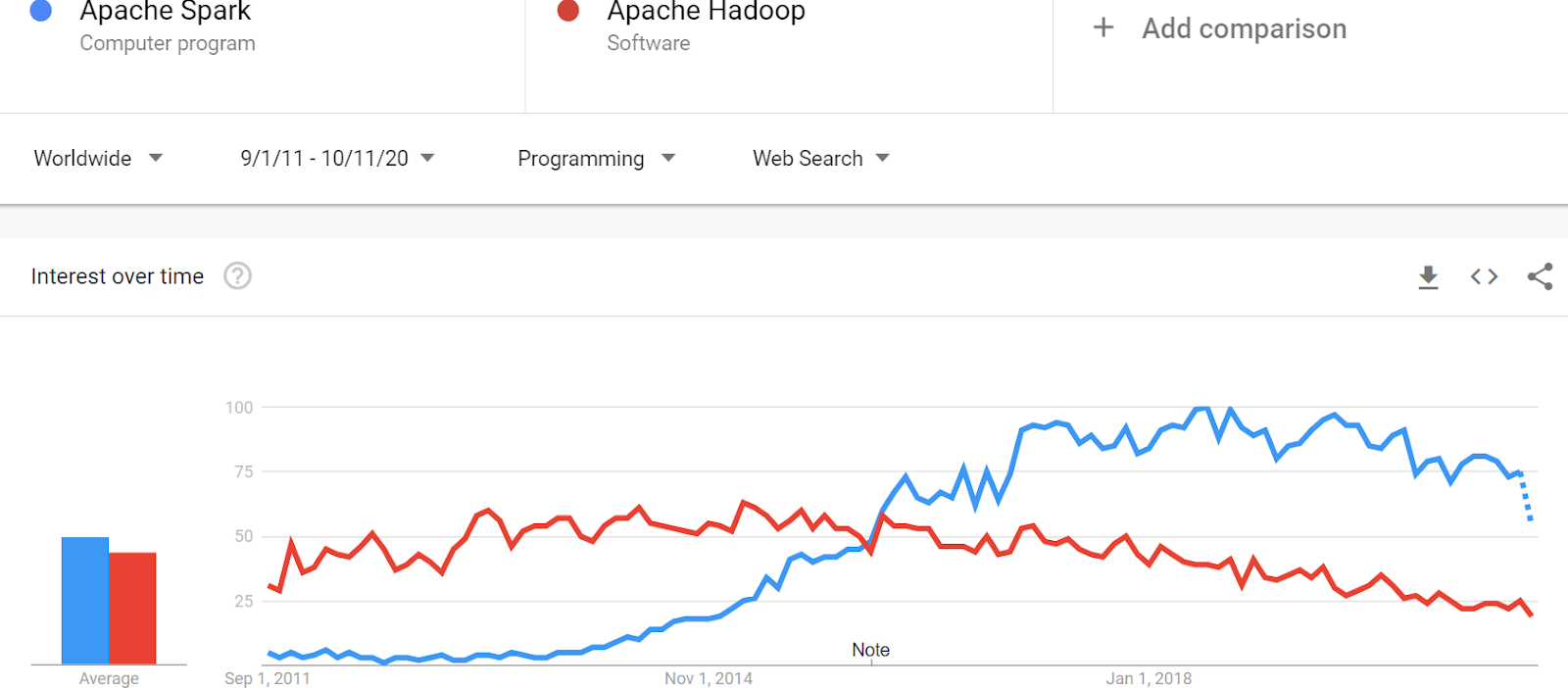
Clairement, Hadoop est en bout de course et semble sur le déclin. Spark domine les débats depuis 2015 après plus d’un an d’existence en version stable. Comparons maintenant Spark à Beam :
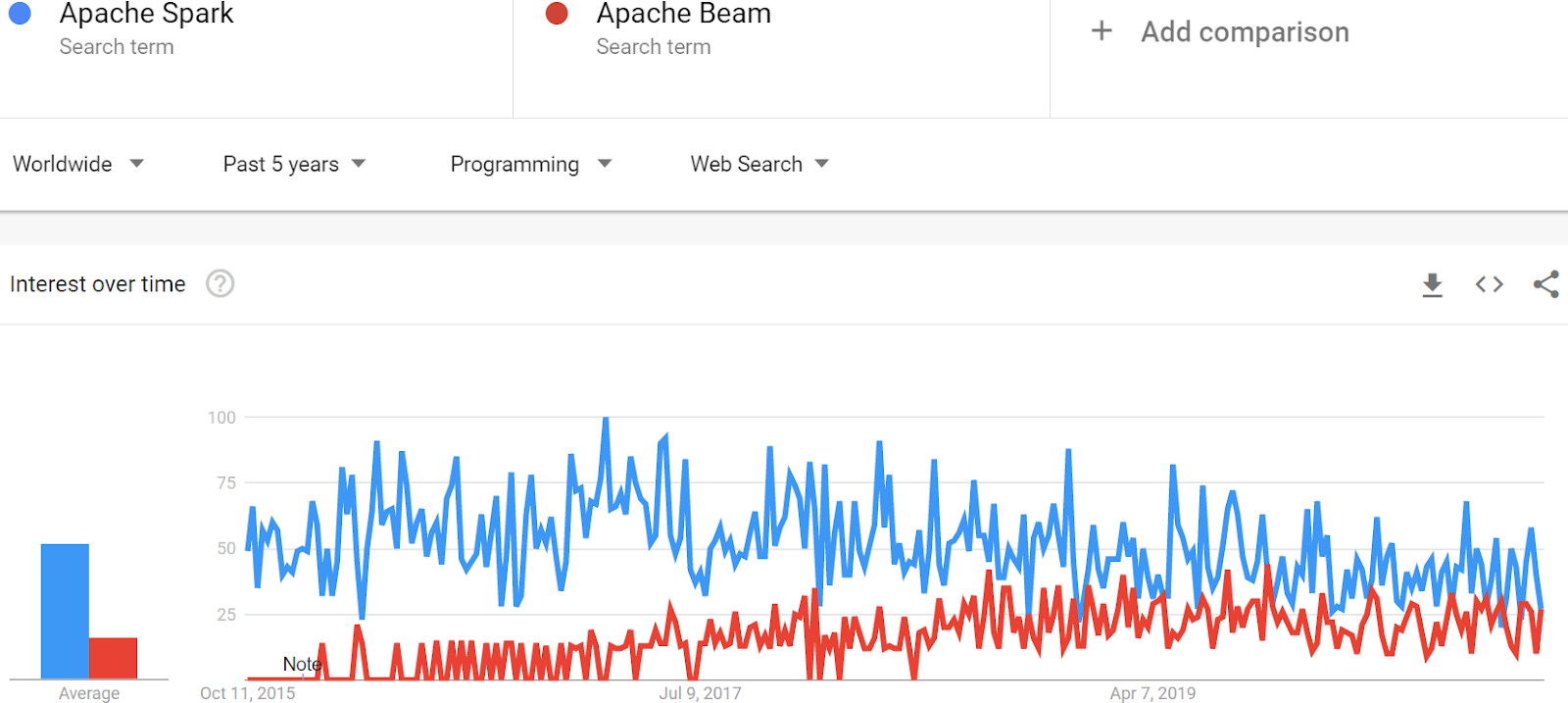
Une baisse de forme du côté de Spark s’associe à une montée de Beam. Nous ne dirons pas pour autant qu’il s’agit d’un transfert de Spark vers Beam et Spark domine toujours quoi qu’il en soit.
Que dit le monde l’open-source?
(ordonnée droite: nombre d'étoiles accumulées; ordonnée gauche: nombre d'étoiles à la journée)

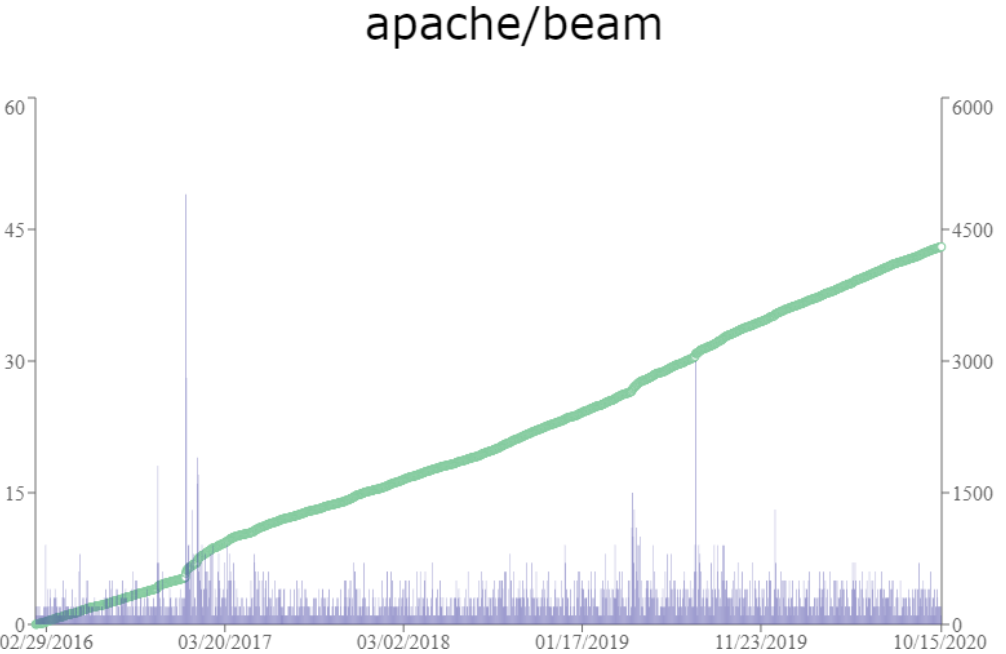
Et celui des développeurs?
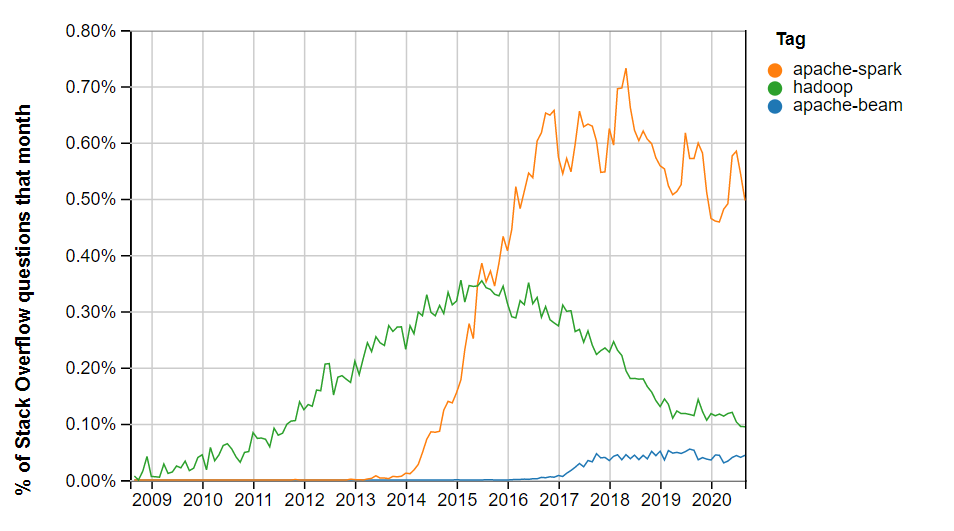
Spark domine assez nettement. Comment expliquer cela ?
Comme tout succès, on peut raisonnablement penser que Spark a su répondre à un besoin au bon moment et surtout en y apportant un lot d’innovations tellement importantes qu’elles en justifiait son adoption massive. À une époque où le temps de traitement Hadoop devenait trop long pour l’industrie, où son modèle devenait trop manuel, voire archaïque pour les développeurs, Spark est apparu comme une bouffée d’air frais. Sa communauté grossissant, un cercle vertueux s’est installé en permettant une évolution constante du moteur et de son modèle. Aujourd’hui, Spark en est à sa version 3.0 et, bien que se basant toujours sur une approche microbatch, propose un modèle assez proche de celui de Beam. On y retrouve la notion de processing time, d'event time et de windowing sur cette dernière dimension. Au-delà de la technologie et de la communauté, c’est l’existence d’un vrai écosystème qui en a pérennisé l’usage. Databricks, qui est une plateforme de données reconnue, se base sur Spark pour faire ses traitements de données. SparkML est une solution de choix pour les data scientists, Spark SQL une aubaine pour la BI, etc. Certes, le passage d’une version à une autre de Spark nécessite du travail. Mais ce travail est moins risqué qu’un passage sur Beam. Bien que Spark ait toujours un modèle plus rigide que celui de Beam (il y est par exemple plus difficile (voire impossible) de raisonner sur la complétude de sa donnée ou d’y décrire des fenêtres temporelles customisées), force est de constater que l'ingénierie de la donnée est toujours bien ancrée au niveau de Spark.
Dans quelles conditions Beam peut-il alors espérer tirer son épingle du jeu ?
Une adoption avec un coût
Une telle adoption de Spark ne milite guère pour une adoption du modèle de programmation offert par Beam. Cette dernière nécessite en effet une réécriture complète des pipelines. Beam a beau jeu de mettre en avant l’interopérabilité de son code avec les différents moteurs du marché. D’un point de vue stratégie d’entreprise, cela a du sens en faisant un pari sur la pérennité de Beam. D’un point de vue pratique cela devient moins évident. Le développeur s’en retrouve encore une fois contraint. C’est comme dire à des développeurs Java “maintenant, nous passons à Scala pour les raisons X et Y. Mais ne vous inquiétez pas, Scala tourne aussi sur la JVM !”. On laisse au lecteur le soin d’imaginer le plébiscite...
Autrement dit, ça ne change rien à la problématique d’apprentissage qu’il faudra traiter bon gré mal gré et cela a un coût d’autant plus élevé que l’on prend le risque de se couper d’une communauté déjà bien établie.
...et un retour sur investissement
Pour autant il y a une vraie question quant au choix de l’adoption car les moteurs compatibles offrent des avantages non négligeables. Dataflow, le plus emblématique, a une approche serverless qui permet de faire des économies d’échelle sur le coût opérationnel. Du fait de l’interopérabilité de Beam, le spectre du vendor-lock-in s’efface et l’on peut pleinement jouer sur la concurrence. Apache Flink est un moteur open-source qui offre des performances comparables à Dataflow. Libre à chacun de l’héberger on-premise ou sur un cloud avec des prix compétitifs. AWS en a récemment sorti une version managée avec Amazon Kinesis Data Analytics, créant par là même un challenger à Dataflow. Bref, passer sur un modèle Beam, c’est s'ouvrir à des perspectives intéressantes. Pour en maîtriser la prise de risque, un modèle que l’on observe souvent en entreprise qui migre dans le cloud est de procéder par un lift & shift pour les pipelines Spark existants (via EMR sur AWS ou Dataproc sur GCP). Beam sera alors considéré pour les nouveaux pipelines lorsqu’un moteur managé est disponible. Cela dit, si Beam a une carte à jouer c’est bien sur l’agilité de son modèle qui offre des solutions élégantes pour des cas métier autrement plus compliqués à résoudre avec d’autres approches.
Et Dataflow ?
Revenons pour conclure sur notre sujet initial. Comment Dataflow se positionne dans ce contexte ? Le succès de Dataflow se jouera sur deux axes. L’adoption de son modèle de programmation d’une part, l’adoption de la Google Cloud Platform d’autre part. La libération de son modèle vers Apache Beam est une bonne décision pour sa diffusion auprès d’une communauté en demande d’open-source. Et nous pensons que le modèle, après plus de quatre années d’existence, est mature et présent sur le long terme. L’ajout de différents langages (Go, Java, Scala, Python) témoigne de l’adoption qui en est faite, sinon commercialement, au moins au niveau de la communauté des data engineers. Côté GCP, il y a cet horizon indépassable pour Dataflow qui est l’adoption de la plateforme par les grands groupes. Pas d’adoption, pas d’usage. GCP est toujours un bon troisième dans la compétition que se livre les fournisseurs cloud et il va être intéressant de voir l’impact du changement de stratégie impulsé par Thomas Kurian (le nouveau CEO de Google Cloud) dans les années qui arrivent. Notons par ailleurs que Dataflow peut subir la concurrence de services internes à GCP. Nous avons vu Dataproc, qui à travers sa notion de Workflow template offre du serverless. Il y a aussi ce mouvement Extract Load Transform (implémenté par exemple avec un datawarehouse type BigQuery et un orchestrateur type Airflow) qui par sa simplicité gagne la préférence des analystes tant il leur permet de gagner en autonomie (seules des connaissances SQL suffisent). Le chemin n’est donc pas de tout repos pour Dataflow. La technologie est là, le support par Google aussi. Reste aux marchés et aux utilisateurs de pipeline d’y donner suite.
Conclusion
Dataflow était et reste innovant. Son meilleur leg réside dans son modèle de programmation, Apache Beam, considérant le traitement batch et streaming en tant que deux faces d’une même pièce. La libération de ce dernier n’en fait plus une initiative propre à Google mais celle d’une communauté se basant sur les succès et échecs des modèles précédents pour proposer une vision universelle du data processing. Pourtant, on constate encore trop souvent la confusion entre le contenu (Beam) et le contenant (Dataflow), contribuant à l'idée tenace que faire du Beam en dehors de la GCP n’est pas possible ou pour le moins souhaitable.
Réussir à dissocier les deux dans l’esprit des développeurs serait gagnant-gagnant pour Beam et Dataflow. Pour Beam car cela augmenterait sa communauté encore (trop ?) proche de Google. Pour Dataflow car mécaniquement cela augmenterait le nombre d’utilisateurs potentiels de ce service. C’est dans cette optique que cet article oppose finalement Apache Beam en tant que challenger de Spark plutôt que Dataflow. Derrière cette opposition se cachent deux conceptions du stream processing, l’une reposant sur du micro-batch, l’autre sur du “vrai” streaming. Pour le moment, la plupart des cas business tolèrent les limitations imposées par le premier tant il est vrai que Spark a réussi à les atténuer au fil de ces différentes versions.
Cela en sera-t-il ainsi dans l’avenir, ou Beam réussira-t-il à imposer un modèle mieux adapté aux nouveaux besoins ?
Difficile à dire, mais il est sûr que la question est plus pertinente du côté de Beam qui a encore du chemin avant d’égaler la reconnaissance de Spark auprès des data engineers.
Dans un prochain article, nous laisserons les hypothèses de côté pour nous concentrer sur un cas original d’utilisation de Dataflow permettant de faire des économies substantielles sur sa facturation GCP.

1 minutes de lecture
Google Cloud Next 2021
La Google Cloud Platform a bien évolué depuis ses débuts en 2008 avec App Engine. C’est aujourd’hui un cloud qui se veut leader dans la data, la...

Amazon Spot Instances : optimiser ses dépenses et booster son infrastructure
On vous ressasse en permanence qu’un des avantages essentiel du Cloud est sa flexibilité ! Vous avez parfaitement compris qu’avec un tel système,...