


Sommaire
Introduction
Dans une application la configuration peut se définir comme tout ce qui varie d’un déploiement à un autre. Cela peut concerner des sujets applicatifs (URLs de services tiers, identifiants, ...), comme technique (IP de la machine hôte).
Dans l’un de nos précédents articles nous présentions Lightbend config, une solution simple et puissante de fédération de configurations d'applications. Nous la qualifiions alors d’adaptée aux applications dites cloud-natives.
Pour comprendre les fondements de cette affirmation, il est nécessaire de qualifier la relation entre un applicatif et sa configuration dans un environnement “cloud”. Quelles problématiques pose la gestion d’une configuration ? Comment y répond-on ? Ce n’est pas tant que le Cloud ait créé de nouvelles problématiques qu’il ne les a exacerbées.
L’application de nouvelles approches de gestion de configuration devient alors nécessaire plutôt qu’optionnelle. Au-delà des réponses qu’apportent des solutions comme Lightbend config, ce qui nous intéresse ici c’est de comprendre comment ces questions se sont posées et comment les solutions peuvent se penser.
Rappel sur le cloud native
Le Cloud, très porté sur les promesses d’élasticité, de consommation à la demande et de globalité, ne doit pas faire oublier sa faillibilité.
Rappelée par la citation du CTO d’AWS “Everything fails All the Time”, cette constance doit se traiter par différentes pratiques et applications de patterns architecturaux.
L’objectif de l’approche Cloud Native est d’apporter à l’application hébergée sur le Cloud un comportement déterministe. Le même que nous aurions dans un environnement on-premise tout en bénéficiant des avantages du Cloud.
Le comportement d’une application, d’un service, serait alors porté par les deux éléments centraux que sont le code source et sa configuration. Une de ces approches Cloud Native est de dissocier les deux entités tant en termes d’existence que de cycle de vie. Dans un paradigme hautement distribué et de haute disponibilité où une application peut scaler sur des milliers d’instances, abstraire le concept de configuration en facilite son contrôle et sa définition.
La configuration dans le cloud, problématiques
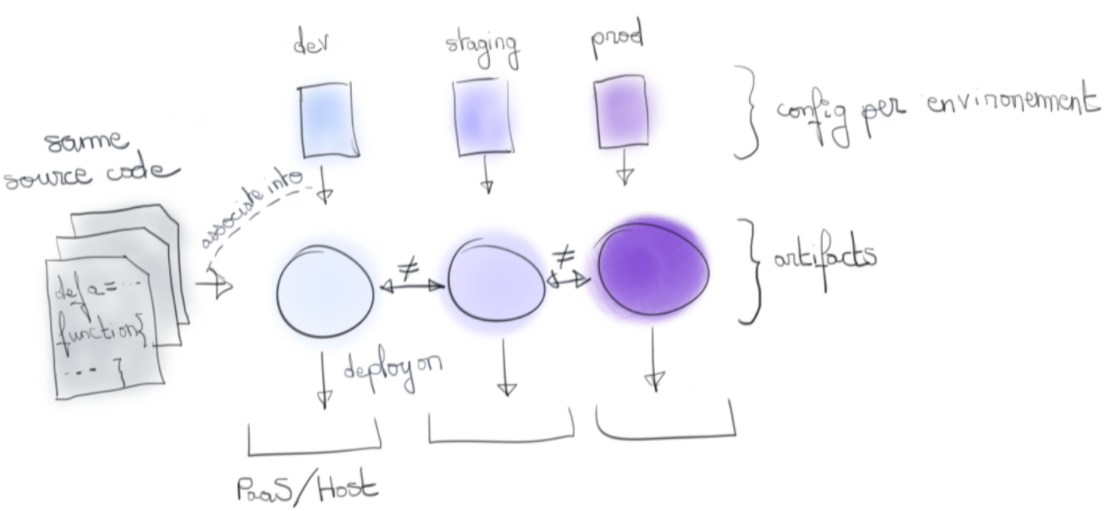
Il fut une période où une application se pensait comme un artefact issu du code source auquel on intégrait une configuration pour déterminer son comportement. Nous rencontrons encore cette approche avec des langages compilés tel java où le .jar embarque un .properties.
Selon l’environnement visé, l'artefact était donc différent puisqu’une configuration de développement ne saurait être la même qu’une configuration de production.
Cette approche devient problématique dès lors que l’on requiert une traçabilité forte. Comment s’assurer que telle version de l’artefact déployée en production est bien celle qui était en développement il y a un sprint de cela ?
Un checksum identique serait une gageure, mais impossible à obtenir si l’artefact contient une configuration différente.
Il n’y a pas de problème particulier à inclure le modèle de la configuration à l’artefact de livraison. À même version de code, il ne change pas d’un environnement à l’autre. Le problème que nous décrivons se pose à partir du moment où nous y embarquons aussi les valeurs au moment de la construction de l’artefact.
Le facteur 3 des 12 Factors app apporte un début de réponse à ce problème :
“Stockez la configuration dans l’environnement”.
Cela nous dit en réalité moins que ce que l’on imagine. Il ne précise pas de quel type de configuration nous parlons ni de quelle manière elle doit se consommer.
Certes un appel à getEnv peut répondre à la question mais cette approche affiche vite ses limitations. Comment avoir une vision globale de notre modèle de configuration ? En scannant le code à la recherche des différents appels à getEnv ? …
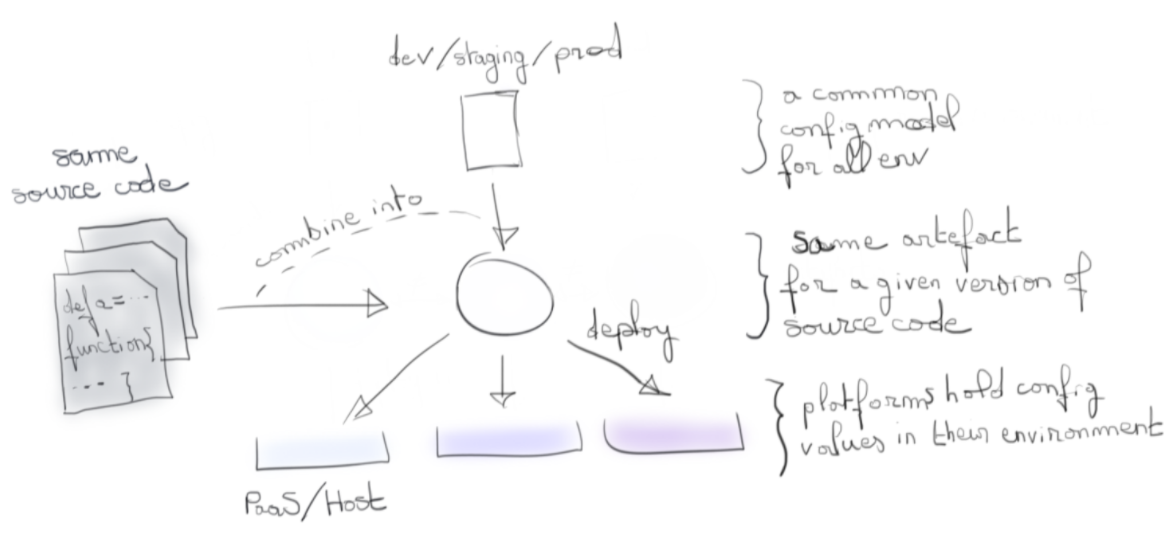
Il serait alors intéressant d’allier le meilleur des deux mondes :
Le modèle de configuration agnostique, et les valeurs spécifiques stockées dans l’environnement.
Différents types de configurations
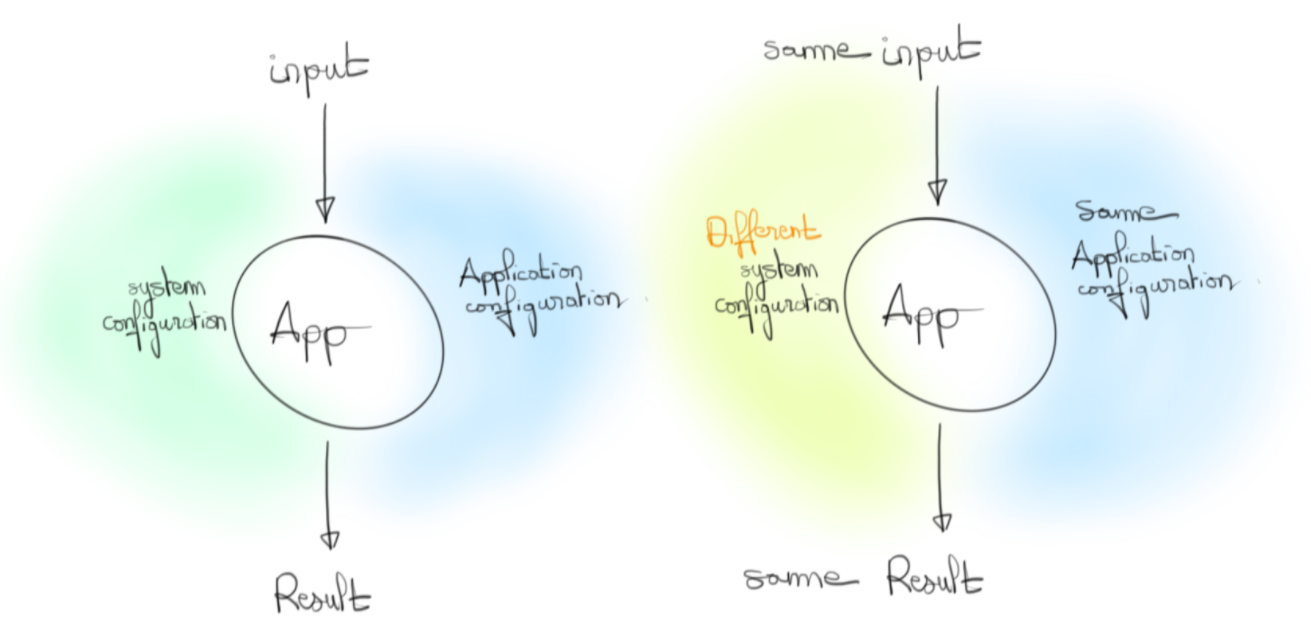
Nous sommes restés jusqu’à présent assez vague sur le contenu de la configuration. Nous concevons assez bien que nous allons y trouver des éléments liés aux connexions aux bases de données, des URLs d’APIs à des services tiers, des éléments liés au comportement du code, etc. Nous qualifierons ces éléments comme faisant partie de la configuration applicative.
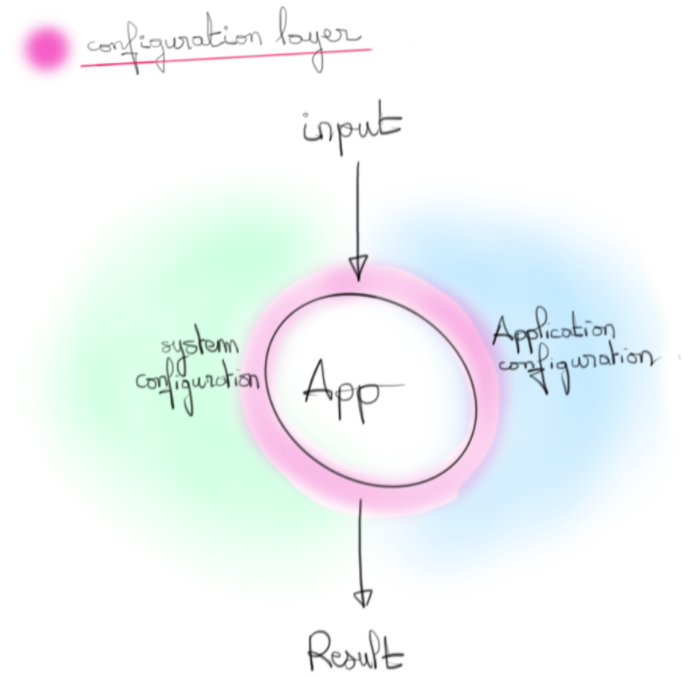
Par ailleurs, la configuration englobe aussi les valeurs systèmes portées par l’environnement dans lequel est déployé l'artefact. L’adresse IP de l’instance par exemple. Contrairement à la partie applicative, ce ne sont pas des éléments sur lesquels nous avons forcément prise et surtout, leur modification ne doit pas affecter le comportement fonctionnel de l’application.
Une configuration a donc en réalité plusieurs sources. En suivant stricto sensu le facteur 3, ces sources doivent être mergées dans l'environnement. Nous n’avons donc plus qu’une source pour récupérer les valeurs et l’ubiquité des variables d’environnement nous permet d’envisager l’approche à peu près partout.
Le problème est que d’une part l'environnement ne peut servir de modèle de configuration dans le cas où des applications partagent le même environnement. D’autre part, il n’est pas réellement adapté à de la consommation depuis un applicatif qui serait rempli d’appel à getEnv.
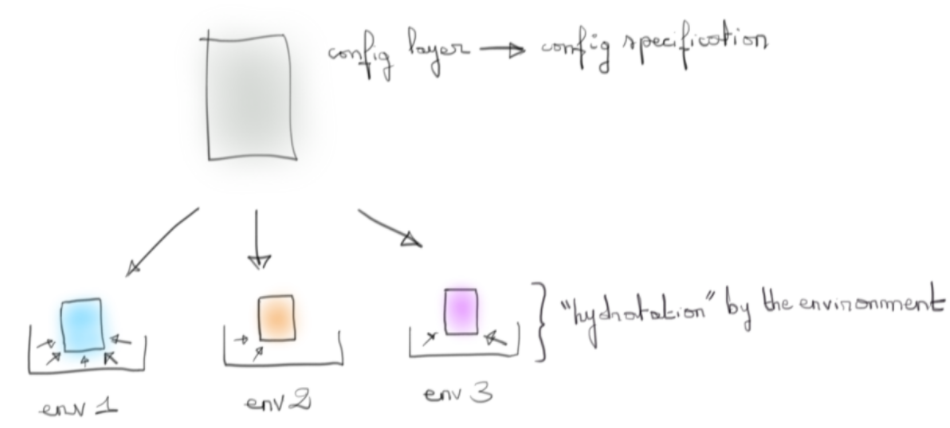
D’où l’idée d’une couche intermédiaire, notre modèle, qui serait hydratée (telle une éponge) par l’environnement dans laquelle on la déploie afin d'offrir un point d’entrée unique à notre code.
L’état final de cette couche dépendrait alors de l’environnement dans lequel on la déploierait.
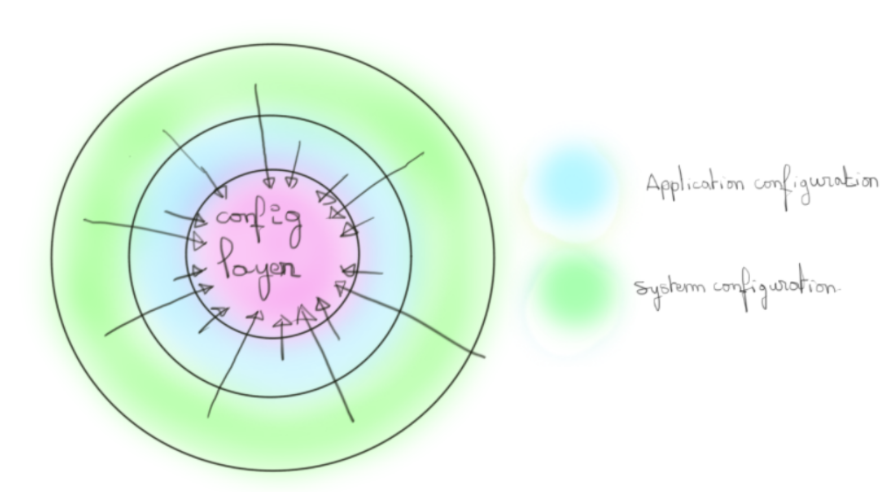
Les flèches concentriques vers la couche du modèle de config représentent le travail qu’effectue un outil comme LightBend config (cf la notion de fusion établi dans l’article). La politique d’override, de contrôle de type, ..., est du détail propre à la machinerie interne de l’outil choisi. Mais l’image générale est là.
Aller plus loin
Les points précédents permettent de décorréler conceptuellement la configuration de l'application à laquelle on l’applique. Pour autant, nous ne pouvons pas parler de cycle de vie propre à la configuration. Son modèle est certes sourcé avec le code mais pas les valeurs associées qui sont provisionnées dans l’environnement hébergeant l’application.
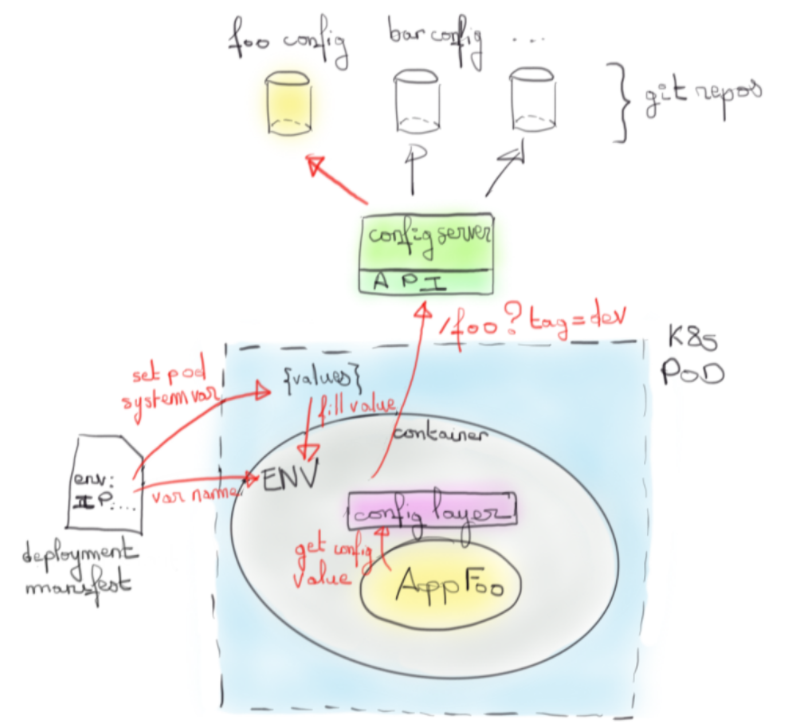
Nous pourrions imaginer un service indépendant (serveur web, Key/value Store, ...) qui contiendrait les valeurs de configuration de chaque application pour chaque environnement. En particulier, avec ce serveur reposant sur un dépôt Git comme backend, nous aurions en plus une traçabilité forte des différents ajouts et modifications selon l’application et environnement considéré.
C’est l’approche de Spring Cloud Config qui offre alors une place centrale pour contrôler les valeurs de configuration par application et environnement.
Au passage, on notera que la couche de configuration joue le rôle d’une gateway du contexte applicatif. Les valeurs sont en coulisse cherchées à différents endroits, mais du point de vue de l’application c’est un point unique.
De l’agilité supplémentaire
L’immutabilité d’une application déployée est une règle communément admise. En la suivant stricto-sensu, changer en direct une configuration est interdit car cela revient à modifier sans tracer. Mais est-ce vraiment le cas?
Avec l'approche du serveur de configuration, changer une configuration en direct n’est plus problématique car cette fois-ci tracée. Nous gagnons donc énormément en agilité dans des environnements de production. La configuration bénéficie du même traitement que le code applicatif et revêt une même importance.
Des offres managées de fournisseurs Cloud existent. On peut citer à ce titre, Firebase remote config.
On notera que ce concept est une des composantes du control plane utilisé dans les services mesh : une place unique où gérer et appliquer la configuration du mesh de services. Anthos configuration management en est un exemple chez GCP.
Une question qui reste cependant en suspens est la compatibilité entre les versions du code et celles du modèle de configuration. À partir du moment où l’on réussit à décorreler le code application de sa configuration, la question se pose assez naturellement. Encore plus dans un environnement Cloud ou des versions différentes d’un même code applicatif peuvent coexister (A/B testing par exemple). Nous pourrons traiter cette question lors d’un prochain article mais il s’agit d’une des composantes traitées par les stratégies de releases (Blue/Green deployment, Rolling release, Canary release).
Des écosystèmes inégaux
Il est intéressant d'observer que tous les écosystèmes ne se valent pas en termes d’outils de management de configuration. Les écosystèmes liés à la JVM sont très fournis à ce niveau. C’est plus compliqué chez les autres et des alternatives à Lightbend n’existent pas forcément.
Pour autant, cela ne veut pas dire que tel ou tel écosystème est incompatible avec une approche cloud native de la gestion de configuration. Plus que les outils, ce sont les concepts qui importent. Évidemment on ne peut pas nier qu’il sera plus simple de s’y conformer avec des outils existants mais la théorie décrit une approche accessible à tous. Il est à noter à ce titre, que bien que Spring soit très lié à l’écosystème Java, l’approche client/serveur portée par Spring Cloud Config rend l’outil consommable par tout type de langage.
Conclusion
La configuration ne doit plus avoir le rôle secondaire qu’on lui attribuait auparavant. Elle doit se penser avec son cycle de vie propre et de manière fédérée. Des outils existent pour répondre à cette nouvelle vision et selon l’écosystème de développement considéré ils seront plus ou moins riches et nombreux. Lightbend config est un bon exemple de ce type d’outil. Néanmoins, plus que les réponses apportées, ce sont les concepts qu’il faut appréhender. C’est de là que naîtra la bonne approche d’architecture d’une application dans le Cloud, celle que l’on qualifie de cloud native.



