

Pourquoi et comment optimiser vos lambdas AWS ?
De plus en plus d'applications sont aujourd'hui déployées en mode "serverless" (comme en témoigne cet article Silicon.fr), c'est-à-dire que le code est envoyé à un service dédié chez le cloud provider, et celui-ci se charge de son exécution.

Sommaire
Lambda est le service AWS le plus connu pour ce type de déploiement. Il supporte nativement plusieurs langages (dont Python et NodeJS) et permet de faire tourner un service backend en quelques minutes.
Cependant, un point important est parfois difficile à évaluer : le rapport performance/coût.
Cet article présente la nécessité d’un outil de tuning, son usage et vous permettra ainsi de juger de son intérêt selon votre contexte.
Pourquoi utiliser un outil de tuning ?
Un code a parfois besoin de plus de ressources pour s’exécuter plus rapidement, et AWS facture le temps d'exécution (à la milliseconde) selon un tarif dépendant de la quantité de mémoire vive (RAM) demandée. En fonction de cette quantité, une part proportionnelle de CPU sera également allouée à l’exécution de votre code.
Allouer peu de mémoire à votre lambda ne garantit donc pas un prix bas, puisque celle-ci mettra potentiellement plus de temps à exécuter votre code. De même, attribuer beaucoup de RAM à votre code le fera peut-être s’exécuter plus vite, mais à un coût à la milliseconde supérieur.
Afin de faciliter l'estimation de ce coût, et surtout de choisir le meilleur ratio temps d’exécution VS facturation, j'ai récemment utilisé l'outil aws-lambda-power-tuning, de Alex Casalboni (Developer Advocate chez AWS).
Celui-ci automatise le lancement de votre lambda selon plusieurs configurations mémoire, et mesure les temps d'exécution ainsi obtenus.
Installation
Six modes d’installation sont proposés dans la documentation officielle.
Pour ma part, j’ai choisi le déploiement manuel en un clic à partir de ce template Serverless :

Quelques paramètres doivent être renseignés (cf. illustration ci-dessous). Les valeurs par défaut suffisent, mais vous pouvez par exemple personnaliser le nom de la stack. Il faut également accepter la création des rôles IAM.
Seulement quelques dizaines de secondes après avoir cliqué sur Deploy, la douzaine d’objets nécessaires au lancement d’une campagne de tests est prête.
Configuration
Pour configurer votre campagne de tests, il est nécessaire de compléter un fichier JSON avant de lancer quelques commandes shell.
Pour ce faire, je suis parti de l’exemple fourni dans le dépôt officiel pour créer une copie du fichier scripts/sample-execution-input.json :
{
"lambdaARN": "arn:aws:lambda:eu-west-1:XXXXXXXXXXXX:function:handler-lambda",
"powerValues": [128, 256, 512, 1024, 2048],
"num": 5,
"payload": { "userId": 123456789, "payload": "Message to push", "type": "refresh" },
"parallelInvocation": true
}
Les points à modifier ici sont :
- lambdaARN : l’ARN de la lambda cible à tester
- powerValues : les valeurs de mémoire à utiliser lors du test
- num : le nombre de lancements à effectuer avant de calculer une moyenne des temps d’exécution pour chaque valeur de RAM
- parallelInvocation : si des invocations en parallèle sont autorisées ou non
- payload : le payload attendu par votre lambda (équivalent strict de l’objet event).
Il existe de nombreuses autres options de configuration de votre test, et notamment :
- La possibilité de fournir plusieurs payloads différents, avec chacun un pourcentage de fréquence d’utilisation lors des N exécutions
- La stratégie de choix de la meilleure configuration parmi :
- cost : la moins chère
- speed : la plus rapide
- balanced : le meilleur compromis coût/rapidité, en fonction du curseur fourni avec le paramètre balancedWeight.
La liste exhaustive et documentée des paramètres est disponible ici (en anglais).
Lancement
Pour l’exécution de la campagne de mesure, le dépôt téléchargé précédemment comporte un script permettant de lancer facilement toutes les commandes vers l’API AWS.
Avant de lancer ce fichier scripts/execute.sh, il faut le rendre exécutable (avec chmod u+x) et l’adapter en deux endroits :
- Ligne 3 : modifier le nom de la stack selon ce que vous avez choisi lors du déploiement
- Ligne 4 : spécifier le nom de votre fichier JSON créé juste avant.
Vous pouvez ensuite exécuter le script (dans une console où vous aurez préalablement configuré vos accès AWS).
Si votre campagne se passe bien, vous aurez en retour un message JSON de ce type :
$ scripts/execute.sh
Execution started.............SUCCEEDED
Execution output:
{"power":850, "cost":5.717578125000001E-7, "duration":40.74, "stateMachine": {"executionCost":3.0E-4, "lambdaCost":4.15762528125E-4,
"visualization":"https://lambda-power-tuning.show/XXXXXXXX"}}
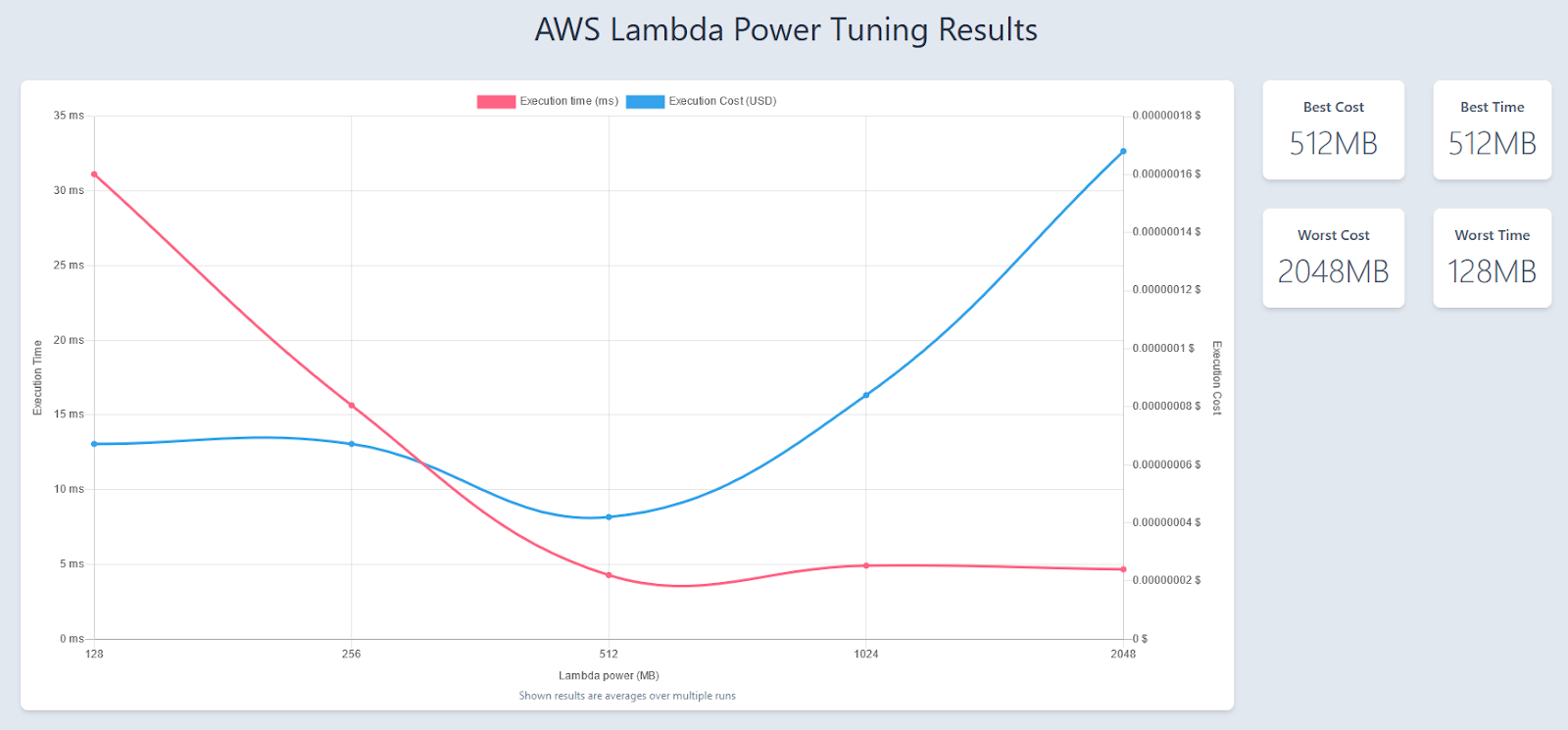
Le retour en succès indique donc la valeur de mémoire permettant de minimiser le coût (car c’était la stratégie ciblée). On y trouve également une URL publique permettant de visualiser en détail les temps mesurés.
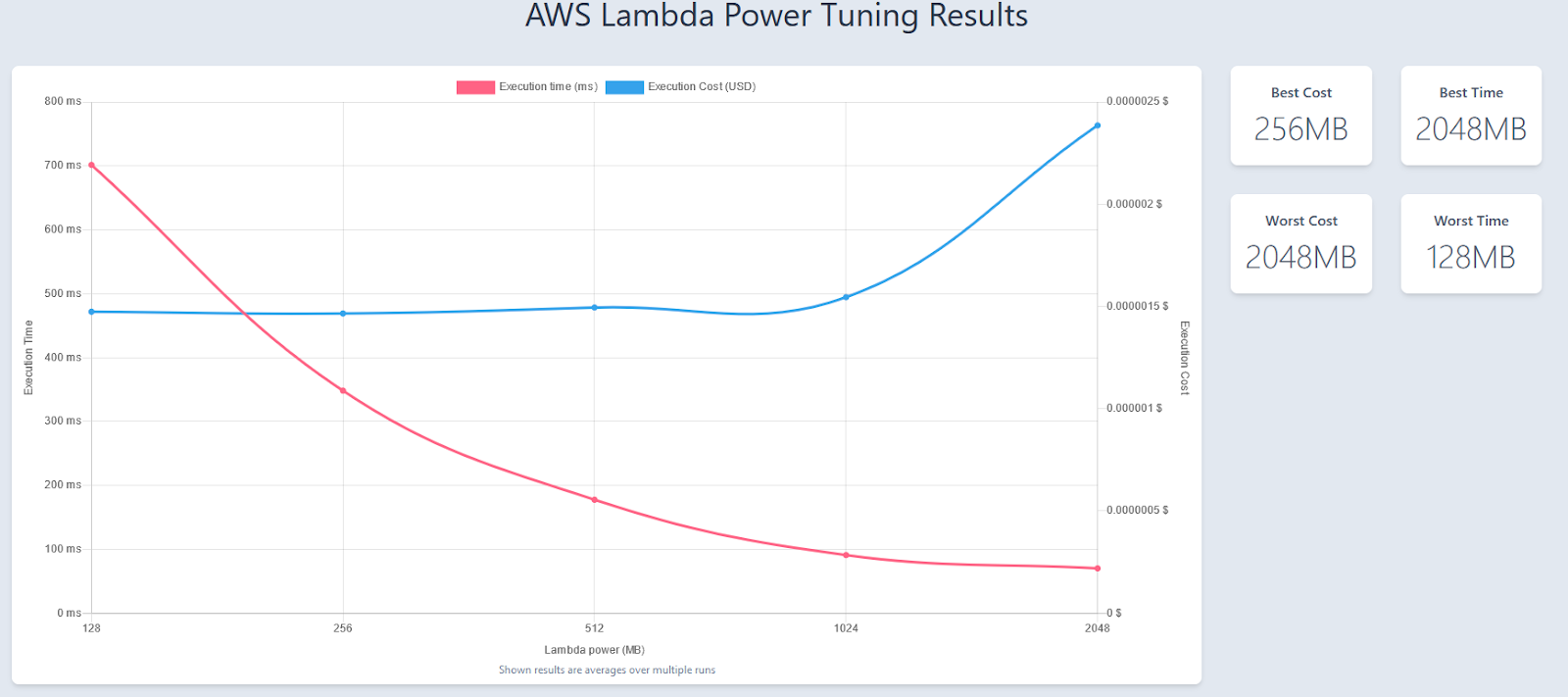
À noter : si vous souhaitez avoir un meilleur temps de réponse par exemple, vous pouvez tout à fait choisir une valeur différente de celle préconisée. Dans l’illustration ci-dessous, bien que la préconisation soit de 256 MB (stratégie cost), une configuration à 1024 MB permettra de fortement réduire le temps de réponse avec un coût quasiment identique.
Conclusion
Il est important de ne pas négliger l’aspect FinOps d’une application serverless, surtout si le trafic devient important. En quelques minutes, un outil tel que aws-lambda-power-tuning permet d’identifier la configuration optimale pour concilier temps de réponse et maîtrise du coût.
Évidemment, le premier levier d’optimisation à votre portée est celui du code bien écrit, minimal et efficace, mais ceci fera l’objet d’un prochain article ;)


