
Comment gérer les clusters GKE, EKS et AKS sur Lens en 4 étapes
Introduction Dans l’article Les outils incontournables pour accélérer votre utilisation de K8s !, nous avons découvert l’utilisation de K9s...

Nomad est un orchestrateur de conteneurs développé par HashiCorp. Allié à Consul, c’est une excellente alternative à Kubernetes. L’outil est disponible en version Open Source et Entreprise. La différence se traduit par un support payant et des fonctionnalités ajoutées. La version Open Source est totalement utilisable en production en l’état et il n’est vraiment pas nécessaire d’avoir la version entreprise.
Avec Nomad, l’orchestration des applications est très simple et l’installation se résume au démarrage d’un binaire sur une VM avec des fichiers de configuration.
Ces derniers temps, Nomad conquiert de plus en plus de parts de marché, malgré tout, Kubernetes reste le leader dans son domaine et il reste l’application favorite quand il s’agit de déployer une stratégie applicative cloud-native.
À quel moment on en arrive à revoir l’ensemble de nos choix d’architectures ? C’est une migration très lourde avec beaucoup de conséquences. Un changement d’orchestrateur de conteneurs n’est pas une mince affaire et demande beaucoup de rigueur, de temps et surtout de connaissance.
L’installation de Nomad est son point fort, mais contrairement à ce que l’on peut penser, Nomad reste un outil dont l’écosystème est beaucoup plus léger comparé à Kubernetes. Nomad manque d’intégration et de fonctionnalités qui peut rendre son administration plus complexe qu’il n’y paraît. C’est dans ce genre de cas que les services managés deviennent plus avantageux à utiliser. La plupart des Cloud Provider publics possèdent des offres de services managés Kubernetes. C’est pour cela que Kubernetes EKS semblait, dans notre cas, être une offre plutôt intéressante.
De plus, Nomad demande une certaine rigueur et présente plusieurs défauts qui nous ont également fait nous mettre en recherche d’une autre solution. Notamment dans la résolution d’incident, la communauté étant restreinte, les recherches peuvent s’avérer très compliquées.
Il vous faut gérer la configuration des instances, la création d’instance et pour cela, il faut installer le binaire. Un rôle Ansible est disponible pour installer le produit, mais il est maintenu par la communauté et non par Hashicorp. À ce jour, la dernière version publiée du rôle Ansible date d’avril 2021 (21 mois d’intervalle pour donner un peu de perspective).
La configuration de l’outil reste simple. Par contre, plus vous poussez dans l’utilisation des fonctionnalités, plus vous aurez de mal à trouver comment y parvenir. Si vous avez des questions ou des besoins particuliers, les informations seront compliquées à trouver. La communauté est peu active et il y a peu de ressources ou de contributeurs pour vous aider.
Une fois que les instances sont configurées, il est important de les maintenir.
Du démarrage du cluster à la maintenance des instances, c’est dans les montées de version que la gestion de ce cluster peut devenir très compliquée. Il y a une directive précise, mais pas d’outil pour aider à la montée de version. C’est pour cela que ça rentre en faveur de l’utilisation d’un service managé.
Pour déployer sur le cluster, vous devez utiliser l’API Nomad directement. Aujourd’hui, il n’est pas possible d’utiliser Helm comme sur Kubernetes. Nomad-pack, une alternative à Helm pour Nomad a été lancé en février 2022, mais le développement étant encore en “technical preview”, il est à utiliser en connaissance de cause. Il vous faudra ainsi construire vos fichiers HCL ou JSON et les envoyer via l’API Nomad.
Néanmoins, Nomad reste préconisé pour une petite infrastructure. C’est également un problème pour le recrutement, il est beaucoup plus simple de recruter des experts Kubernetes que Nomad pour administrer une production.
Sur les aspects coûts, Nomad et Consul requièrent un déploiement sur des machines virtuelles ou physiques et donc des ressources à gérer. Pour information, ce n’est que dans les versions récentes (1.1.x) de Nomad que nous pouvons expliciter le nombre maximum de CPU ou de RAM pris par une application. Nous avons alors des instances avec plusieurs applications, mais toujours sous-utilisées. Pour pallier ce problème, AWS Fargate répond clairement à ce besoin, en payant seulement la consommation CPU et RAM des applications.
Pour être certain qu’AWS Fargate et AWS EKS répondent à nos besoins, il nous faut effectuer une étude de coût que nous verrons dans les parties suivantes.
Les étapes effectuées sont une liste non exhaustive de la manière dont il faut mener ce genre de migration, mais qui peut vous aider dans votre démarche. Et d’une certaine manière, ces étapes peuvent être appliquées pour une migration Nomad / Consul vers K8S ou l’inverse. (Ou vers tout autres orchestrateurs de conteneurs) Ces étapes ont été très fortement influencées par des expériences et des contextes particuliers.
Votre organisation sera primordiale pour mener à bien cette migration. Ce type de projet demande une certaine rigueur. Pour cela, je vous conseille d’utiliser votre framework d’agilité favori. Chacune des étapes doit être écrite, décrite, chiffrée, documentée. Et rien ne reste gravé dans le marbre ! C’est en avançant que vous aurez une vision beaucoup plus complète du projet en lui-même. Vous aurez une vision plus globale et vous noterez petit à petit les points d’attention, les potentiels oublis.
L’organisation est très importante, mais le suivi l’est tout autant. C’est pour cela que durant le POC, nous avons mis en place un document de type DeepDive. Ce document regroupe nos actions, nos réflexions, nos difficultés rencontrées, les résolutions et aussi le suivi de manière chronologique. Le but est d’inscrire tout dans ce document, sa lecture seule, peut permettre de construire le projet en lui-même et de comprendre les choix techniques. Il nous permet d’expliquer nos difficultés et surtout de transmettre nos connaissances. Dans un tel projet, tout doit être écrit.
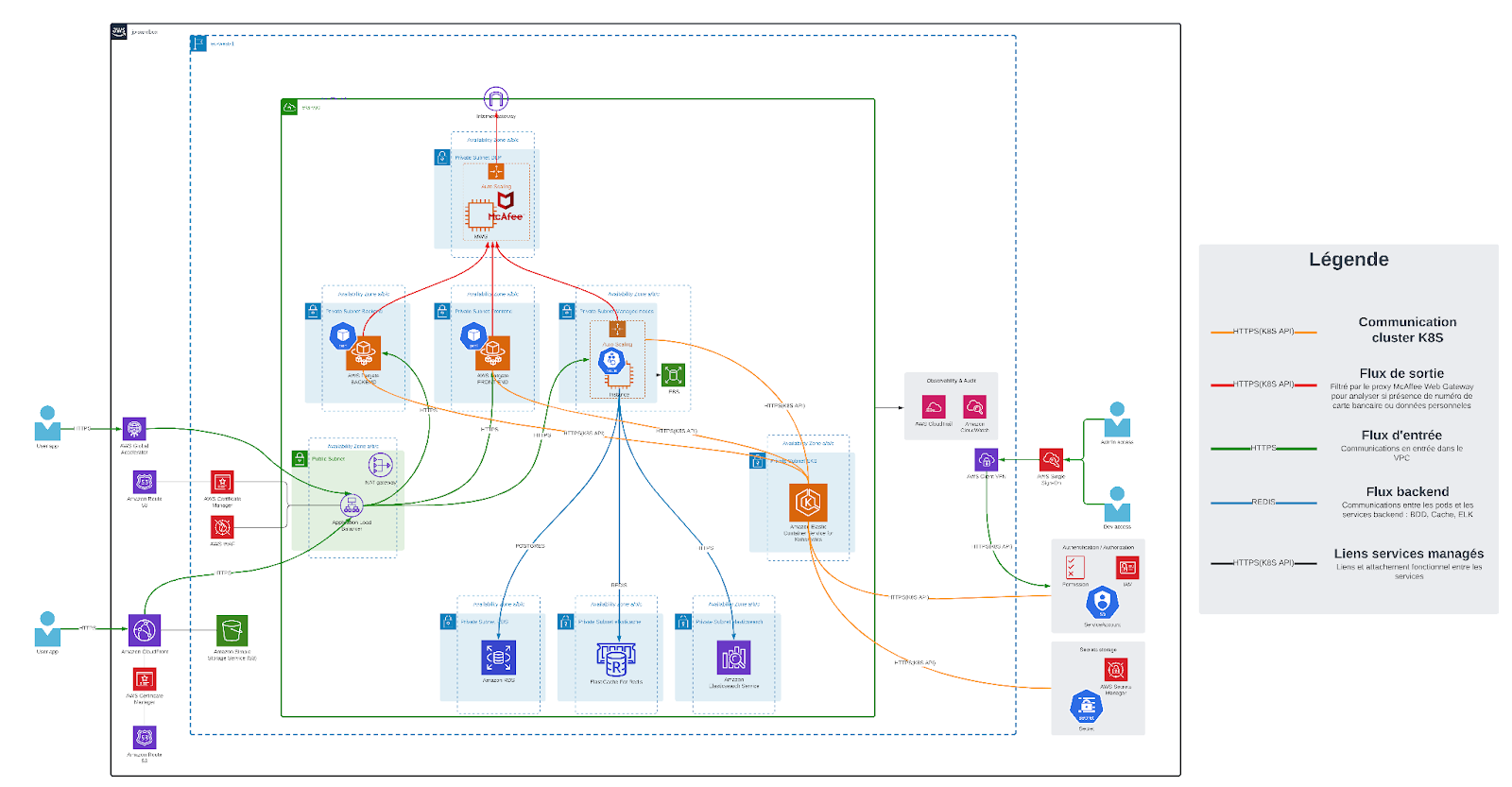
Je pense ne pas avoir besoin de faire une passe là-dessus, mais un schéma d’architecture est toujours le bienvenu avant de commencer le POC. Même si le schéma ne reste pas figé dans le marbre. Assurez-vous d’avoir une idée d’architecture au niveau des ressources qui seront allouées sur AWS pour le POC. Voici un exemple d’architecture qui a été effectué au début du POC.
Nous avons décomposé l’ensemble des actions sous forme de phases, dans le but d’avoir une architecture qui va un peu plus loin qu’un POC. Nous sommes partis du principe que chacune des sources devait être réutilisable pour de la production. Le temps étant manquant, nous sommes directement partis sur une vision plus globale qu’un POC.
Pour commencer, le déploiement d’un cluster qui correspondait à l’architecture décrite plus haut. Nous avons directement mis en place les sources Terraform pour déployer l’ensemble de la partie réseau, de nouvelles bases de données dédiées pour le POC, des clusters REDIS, un cluster Opensearch et enfin le cluster EKS.
L’ensemble des sources Terraform ont pour but d’être utilisées dans le cadre de la migration en production. Construisons rapidement, mais efficacement.
Nous répliquons la base de données de développement sur notre nouvel environnement.
La troisième étape de cette phase est de pouvoir déployer les premières applications et donc de valider une partie de leur fonctionnement, c’est pour cela que nous mettons en place toutes ces sources. De plus, notre infrastructure étant déjà déployée, nous réutilisons l’ensemble des sources Terraform déjà produites.
Point d’attention, redéployer un cluster totalement veut dire payer un nouvel environnement et peut engendrer un certain coût.
Le but de cette partie n’est pas de construire un monitoring complet lors du POC. Mais construire une bonne base pour avoir plus d’information sur la plateforme.
Nous allons ainsi déployer un Prometheus et Grafana.
Pour la mise en place de Grafana, nous avons pris des graphiques prêts à l’emploi, créés par la communauté.
Le dernier point important ici est la collecte de logs. Il est nécessaire de la retrouver dans notre cas dans AWS CloudWatch. Pour cela, je vous invite à suivre la documentation officielle AWS. Et pour les nœuds Fargate, il existe une documentation spécifique.
Une fois la base du cluster EKS mise en place, nous avons décidé de déployer nos premières applications. Nous avons au préalable installé le contrôleur AWS pour le load balancer. Nous devons retranscrire l’ensemble de nos déploiements provenant de Nomad / Consul sur EKS. Nos applications avaient été listées au préalable et doivent être déployées avec un ordre précis.
Nous avons construit par application, son deployment K8S, sa configmap associée, son service et son ingress (si nécessaire). Pour les déploiements K8S, c’est une configuration plutôt simple sur laquelle nous ajoutons une Affinity pour déployer l’application sur un profil Fargate, bien sûr des exceptions existent, car Fargate ne supporte pas les conteneurs avec le mode d’accès privilégié ni les daemonsets.
Par exemple, les configmaps nous permettent de définir les variables d’environnements utilisés par l’application, nous permettant de suivre le principe que nous utilisions sur Nomad avec les K/V Consul. Dans cette partie du POC, nous ne prenons pas en compte les variables sensibles. Évidemment, en cas de besoin, elles devront être déployées dans un gestionnaire de secrets comme Vault. Dans notre cas, nous choisissons AWS Secret Manager
Le service est plutôt simple, car nous utiliserons par la suite un service Mesh.
Pour l’ingress, nous le mettons en place avec les healthcheck que nous avions défini au préalable sur Nomad pour calquer les configurations existantes, pareil pour l’entête HTTP Host.
Si l’application ne rend pas d’erreur évidente et répond sur les healthcheck, nous passons à la suite. Nous ne faisons pas de test complet dès maintenant, nous définissons la compatibilité de certaines applications sur AWS EKS. Nous voulons voir comment calquer les applications provenant de Nomad / Consul sur AWS EKS, pour chiffrer le travail et définir la faisabilité. Ce qui a été validé haut la main ici et de manière plutôt simpliste, toujours dans le cadre d’un POC.
Cette phase nous permet de valider les coûts de l’infrastructure pour valider ou pas le choix de la migration. Après avoir travaillé sur le cluster quelque temps, nous sommes capables de définir ou non les coûts et de voir un peu plus la faisabilité de migration. Une fois validé, nous pouvons passer à la partie service Mesh, qui demande beaucoup de temps.
Posons-nous la question du coût, dans de nombreux cas, cela peut déterminer si la migration sera réalisée ou non.
Une quarantaine d’applications étaient déployées sur notre cluster et nous voulions utiliser un maximum d’AWS Fargate. Par rapport à la quantité de machines virtuelles déployées par notre cluster Nomad, AWS Fargate s’avère extrêmement avantageux. AWS Fargate est profitable uniquement parce que nos applications sont très peu demandeuses en CPU et en RAM, mais ça peut ne pas convenir à toutes les infrastructures. Sur AWS EKS, vous devrez compter, le prix du cluster EKS (environ $70, le prix varie en fonction des régions), deux instances EC2 managée par EKS (nécessaire pour le déploiement de certaines applications) et enfin le coût d’AWS Fargate (en fonction de votre usage RAM / vCPU). Attention, certaines applications ne peuvent être déployées sur AWS Fargate, pensez bien à compter une partie EC2 managée par AWS EKS.
Cette première étude de coût va permettre de chiffrer si la migration sera rentable… N’hésitez pas à vous aider de la calculette des coûts AWS, pour AWS Fargate et AWS EKS. Et pour le calcul du tarif des EC2, je vous conseille ce site, bien plus clair et précis que la calculatrice AWS.
Lors de votre POC, vous voudriez surement avoir un visuel précis des coûts en temps réel, pour cela je vous conseille d’installer sur votre cluster Kubernetes Kubecost ou sa version open source Opencost. Ces outils viennent avec des dashboards, des métriques Prometheus…
Le Weshare effectué en janvier 2022 nous parle justement des bonnes pratiques pour la gestion des coûts de cluster Kubernetes.
Tout d’abord, voici une estimation du coût au mois du POC sur AWS EKS avec toutes les ressources nécessaires au bon fonctionnement des applications.
|
POC EKS |
|
|
Service |
Coût en $ |
|
Amazon EKS cluster usage in EU (Ireland) |
75,45 |
|
AWS Fargate - Memory - EU (Ireland) |
25,29 |
|
AWS Fargate - vCPU - EU (Ireland) |
115,16 |
|
Amazon Elastic Compute Cloud running Linux/UNIX |
84,86 |
|
EBS |
10,00 |
|
Elastic Load Balancing - Application |
18,75 |
|
VPC |
50,00 |
|
Total cluster EKS |
379,51 |
Voici le coût d’un cluster Nomad / Consul au mois en comptant les mêmes ressources qu’au-dessus.
|
Cluster Nomad / Consul |
|
|
Service |
Coût en $ |
|
Amazon Elastic Compute Cloud running Linux/UNIX |
922,74 |
|
EBS |
184,84 |
|
Elastic Load Balancing - Application |
18,75 |
|
VPC |
50,00 |
|
Total Cluster Nomad / Consul |
1176,33 |
On peut voir que dans notre cas, AWS Fargate a un grand potentiel pour nos applications. La différence de prix est flagrante, si nous regardons le prix à l’année en comptant en plus un environnement de DEV et de STAGING, la somme est conséquente. Ces tableaux ne mettent pas en évidence le coût réel d’utilisation en production (traffic,...). Bien sûr, ce n’est que le coût fixe de l’infrastructure et ne prend pas en compte le coût humain et le temps alloué sur cette migration notamment.
Pour le service Mesh, nous avons retenu deux solutions, un service managé AWS : APP Mesh et Istio. Nous avons fait une étude pour savoir quel service Mesh s’adapterait le mieux à nos besoins. Istio reste la solution Open Source la plus populaire avec une intégration native avec Kubernetes. En comparaison, AWS APP Mesh est un service managé fait pour supporter les architectures microservice sur EKS.
Concernant les coûts, APP Mesh est peu onéreux sur le papier. En effet, il fait appel à d'autres services AWS tel que CloudTrail et CloudWatch, et est très verbeux ! Ce qui engendre une augmentation des coûts d'appels aux API AWS de manière substantiels, contrairement à Istio.
Istio ne génère pas de “vendor lock-in“, contrairement à AWS APP Mesh.
Nous avons conclu d’utiliser Istio. Istio est de facto le standard en tant que solution de service mesh sur Kubernetes via son support par la CNCF, c’est pour cela, notamment, qu’il apparaît comme le leader du marché.
Nous avons maintenant une bonne base solide, même si celle-ci n’est pas “production ready”, elle peut être utilisée pour construire cette fameuse production. Mais il y a quelques besoins essentiels qui n'avaient pas été définis jusqu’ici et qui nécessitent d’être faits pour passer au stade supérieur du POC, désormais que celui-ci a été validé.
Voici les quelques points manquants absolument nécessaires pour passer à la suite.
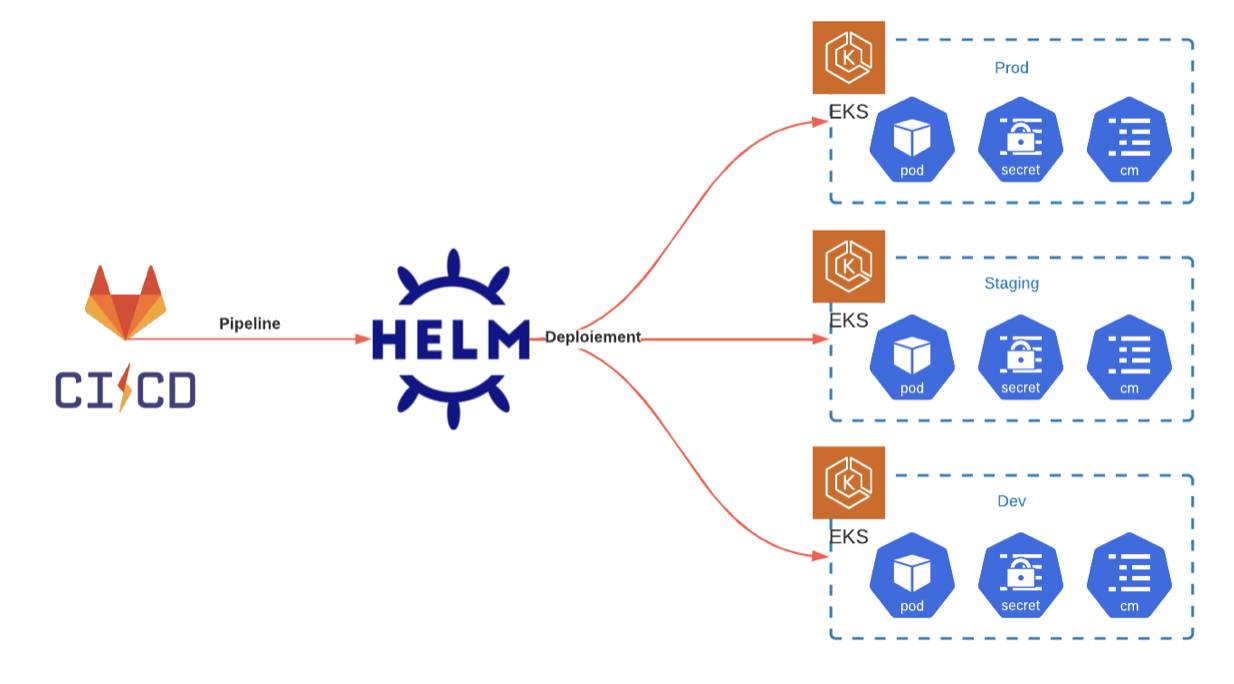
Il faut mettre en place la chaîne de déploiement et d’intégration continue (CI / CD). Définir quels outils nous devrons utiliser pour déployer les applications existantes sur le cluster. Plusieurs solutions s’offrent à nous, la création de Chart Helm pour nos applications ou l’utilisation de Kustomize, un peu plus simpliste, mais totalement viable dans notre infrastructure. Et surtout la création de la pipeline sur GitlabCi pour l’ensemble des applications. Les fichiers GitlabCI sont déjà partagés entre les projets et nous facilitent donc la tâche, nous n’avons pas besoin de modifier chacune des chaînes de déploiement une par une, mais simplement de modifier le modèle utilisé dans un dépôt central. Cela facilite l'exploitation des pipelines.
Nous avons besoin de créer dès lors une documentation d’exploitation pour la plateforme. Celle-ci change du tout au tout, il faut créer un document qui regroupe toutes les informations utiles et nécessaires au bon fonctionnement de la solution. Le document de deep dive fait durant toute la durée du POC peut nous aider à construire cette documentation.
Le but de cette documentation est d’offrir à tout nouvel intervenant une documentation lui permettant directement d’exploiter la plateforme, avoir toutes les informations et connaissances de celle-ci regroupées dans un document.
Mise en place des alertes sur incident ou consommation de ressource. Elles sont nécessaires pour les équipes d'exploitation pour permettre d'agir au plus vite sur tout dysfonctionnement détecté. C'est grâce au composant qui fonctionne de pair avec Prometheus, Alertmanager, que les alertes sont construites et envoyées à l'outil de communication pour le déclenchement de l’astreinte. Il est indispensable d’avoir cette partie, c’est un besoin pour le maintien en condition opérationnelle de la nouvelle plateforme. Sans ça, nous n’avons aucune gestion d’incident ni suivi possible. En fonction de leur criticité, les alertes seront envoyées sur différents canaux de communication. Pour les plus critiques sur PagerDuty et par mail ou messagerie instantanée pour les points d’attentions.
Nous ne construisons pas les applications et nous ne validons pas leur fonctionnement. Les personnes les plus à même de s’y connaître sont les développeurs eux-mêmes. Nous allons donc déployer la plateforme complètement avec l’ensemble des applications et valider avec eux, chacune des applications. Une fois validés, l’équipe QA lancera des tests end to end pour tamponner le bon fonctionnement.
Deux types de migration s’offrent à nous. Chacune avec ses avantages et ses inconvénients.
Pour cette migration, il est nécessaire de geler les mises en production et les modifications métier (opérationnel) pour une durée fixe, définie au préalable.
Nous avons une nouvelle plateforme opérationnelle sur laquelle les données de production devront être migrées. Une fois totalement validé, il faudra effectuer une bascule DNS. Le but est de faire basculer le trafic réseau d’un cluster à l’autre.
L’inconvénient est un gel total des mises en production et du métier.
L’avantage est que la coupure de service sera minimale et permet de décommissionner l’ancienne infrastructure au plus tôt.
C’est une migration application par application sur le nouveau cluster. C'est-à-dire que nous ferons une bascule DNS application par application. Il faudra geler les déploiements et le métier à chaque migration d’application, pour permettre de migrer les données et l’application.
Les inconvénients sont que ce sont des actions fastidieuses à faire et c’est beaucoup plus long. Il faudra une très grande rigueur pour ne pas s’emmêler les pinceaux. En plus, des gels intermittents pour les mises en production et le métier. Ça reste un très haut risque de garder une plateforme dite “legacy” pendant un très long moment. Il est plus onéreux de conserver deux plateformes en simultané. Cela implique également de continuer à exploiter la plateforme "legacy" et de gérer les différentes méthodes de déploiement inhérentes.
Cela demande plus de temps à gérer et complexifie l'organisation, ce qui est d'autant plus problématique si vous manquiez déjà de bras…
Ce projet de grande envergure a permis de remonter par mal de point. Tout d’abord, l’utilisation de Kubernetes. Les avantages sont assez évidents et peuvent faire gagner un temps opérationnel considérable. Les outils libres et communautaires nous permettent d’avoir énormément d'avantages, notamment sur la recherche de pannes et investigations qui nous posaient un problème sur Nomad. Ce POC a mis en lumière une plus grande facilité sur l’installation d’outil pour l’observabilité, les coûts et les performances de la plateforme. L’écosystème est beaucoup plus riche sur Kubernetes.
L’utilisation d’un service managé nous aide grandement pour le maintien en condition opérationnelle, il n’y a plus d’instance à administrer.
Grande surprise lors de ce POC, il n’y a pas besoin de faire de modification pour le runtime de nos conteneurs existant, pas de modification nécessaire entre Nomad / Consul sur Kubernetes, simplement de l’adaptation pour les accès aux volumes, variables d’environnement et secrets.
Après la mise en place de ce POC, Kubernetes apparaît comme un choix logique qui va permettre à l’équipe de gagner un temps considérable, de faciliter les recrutements, d'améliorer l’aspect opérationnel de la plateforme. L’écosystème Kubernetes devient un besoin et non un plus. Cette migration bien que compliquée ferait faire des économies.
Une migration d’orchestrateur de conteneurs n’est pas une mince affaire et peut-être fastidieux, mais en espérant que cet article puisse vous aider !

Introduction Dans l’article Les outils incontournables pour accélérer votre utilisation de K8s !, nous avons découvert l’utilisation de K9s...

La mesure de la consommation énergétique des applications est un sujet d’actualité, d’une part pour en prendre conscience et d’autre part pour...
