



{kind=link}
{kind=link}
Infra as code depuis Kubernetes avec Crossplane
Pourquoi vouloir gérer son Infra as Code depuis Kubernetes ? Avant de voir le fonctionnement de Crossplane, intéressons-nous au problème qu’il cible.
6 minutes de lecture

Nous aborderons dans cet article, le rôle de l’opérateur dans un environnement Kubernetes, nous approfondirons dans cet article leurs fonctionnements, quelques exemples d’utilisation et l’ensemble des bénéfices que cet outil peut vous apporter.
Nous vous présenterons également un site répertoriant une grande quantité d’opérateurs pour des usages divers et variés.
Enfin, nous aborderons la question visant à (re)connaître le moment où développer votre propre opérateur pourrait se révéler intéressant, ainsi que des ressources vous permettant de vous lancer dans cette aventure.
Un opérateur est un outil permettant de packager, déployer, ainsi que de maintenir une application déployée sur Kubernetes. Ce n’est ni plus ni moins qu’une extension qui permet d’automatiser un certain nombre de tâches qu’un SRE (Site Reliability Engineering) pourrait être amené à faire régulièrement dans un environnement plus complexe qu’un simple pod sans état.
Autrement dit, nous pouvons dire qu’un opérateur n’est autre qu’un contrôleur personnalisé, contrairement à un replicaSet qui est un contrôleur natif.
Notons bien que contrairement à Helm, l’opérateur ne se contente pas de packager et de déployer, il est également chargé de maintenir nos applications en bonne santé, tout en effectuant des opérations de maintenance dont elle aurait besoin.
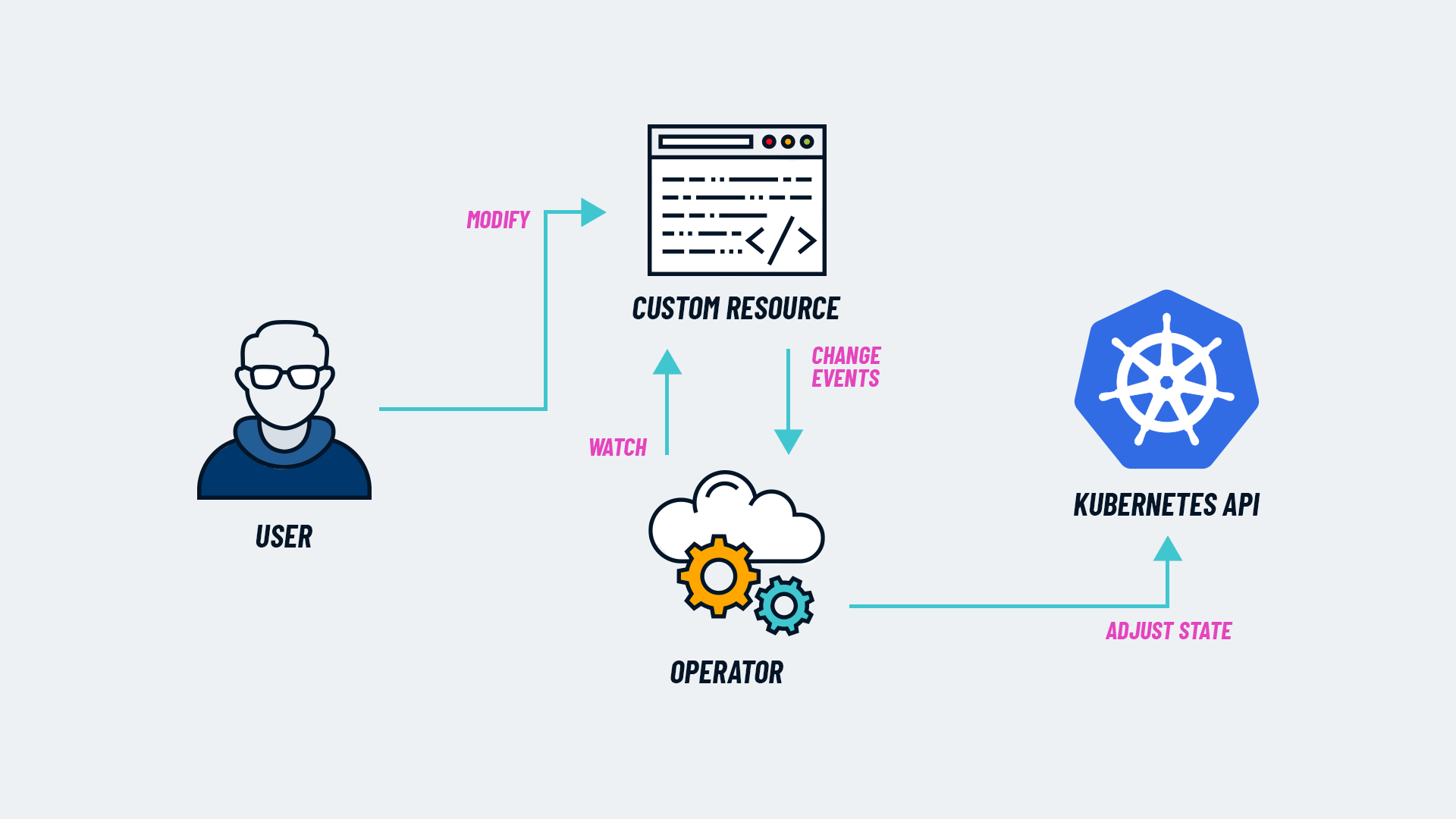
Comme dit supra, un opérateur est une extension du control plane et de l’API. Dans sa forme la plus simple, un opérateur va ajouter un “endpoint” à l’API Kubernetes via une “custom resource” (CR) avec laquelle vous pourrez désormais communiquer à travers la commande kubectl (ex : kubectl get mycr ), ainsi qu’un composant dans le “control plane” vous permettant de monitorer et de maintenir ces nouvelles ressources spécifiques. À noter également que le scope d’un opérateur peut diverger selon votre besoin. Vous pouvez le configurer pour qu’il gère vos ressources dans un namespace en particulier, ou sur l’ensemble de votre cluster.
Fonctionnement d’un opérateur - Source : cncf.io
Il est tout à fait possible de gérer son propre cluster soi-même via un ensemble d’outils nécessaires au bon fonctionnement de votre cluster de base de données. La force d’un opérateur, dans ce cas de figure, vise à remplacer les étapes laborieuses, telles que la configuration, la gestion des pannes, le scaling, ou même la gestion des sauvegardes.
Dans cet exemple, nous allons approfondir le rôle de l’opérateur à travers l’opérateur MySQL développé par Oracle.
Voyons d’abord comment fonctionne aujourd’hui un cluster MySQL classique déployé sur plusieurs hosts.
Comme vous pouvez le voir sur le schéma ci-dessous, nous avons besoin :
Fonctionnement d’un cluster de base de données MySQL -Source : percona.com
Vous l’aurez compris, un cluster de base de données MySQL InnoDB devient un véritable défi à installer dans un environnement Kubernetes sans un administrateur de base de données aguerri et un Ops Kubernetes ayant de solides connaissances pour maintenir et avoir une telle architecture dans un cluster .
Maintenant, prenons le cas où vous devez renouveler cette opération pour différentes équipes dans différents environnements, et qu’à chaque fois vous devez en prévoir la maintenance. C’est dans ce cas précis que l’opérateur intervient.
À partir d’un Helm chart, nous allons pouvoir déployer l’opérateur MySQL dans notre cluster Kubernetes.
Une fois l’opérateur installé, celui-ci va prendre en charge un certain nombre de tâches plus ou moins laborieuses pour vous accompagner dans la configuration de vos clusters MySQL InnoDB.
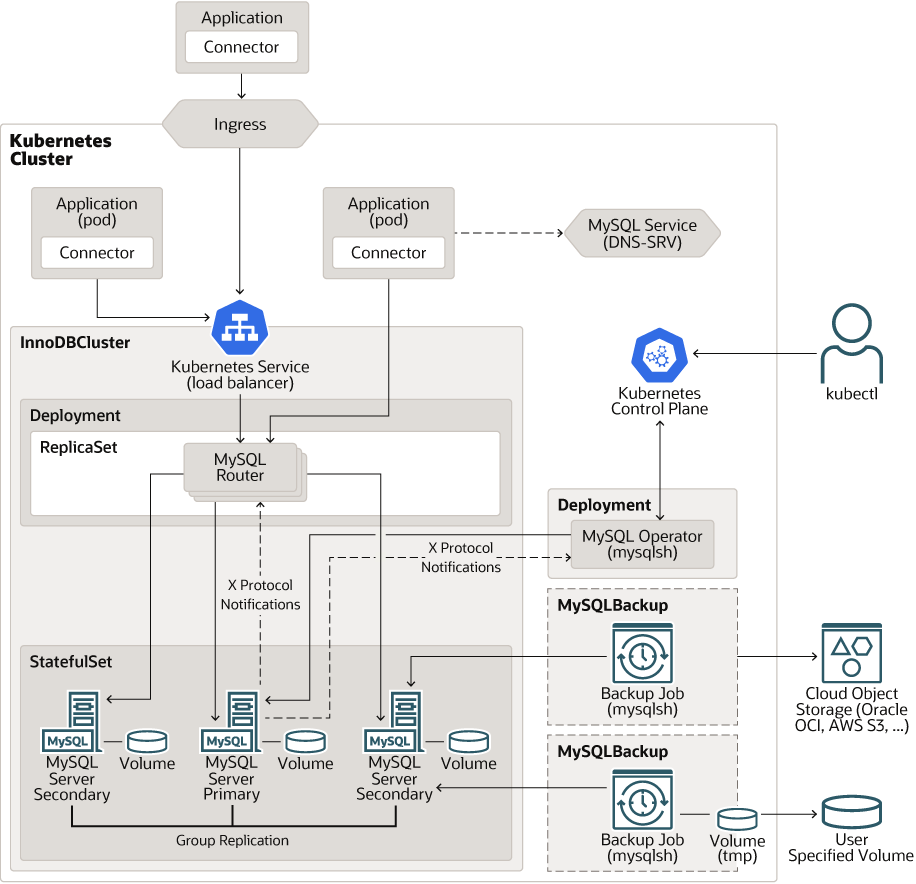
Concrètement, voici ce que l’opérateur va prendre en charge, une fois que vous aurez créé la ressource liée à votre cluster MySQL.
Voici un récapitulatif du fonctionnement de notre opérateur MySQL au travers d’un schéma :
Fonctionnement de l’opérateur MySQL - Source : mysql.com
Lorsque que l’on travaille sur des environnements de production, nous avons tous eu, un jour ou l’autre, le besoin d’utiliser des certificats TLS afin de chiffrer et de sécuriser les communications avec vos applications. À première vue, la difficulté est tout à fait acceptable, cela dit, des opérations basiques telles que générer un certificat ou leur renouvellement, peuvent devenir un véritable calvaire au fur et à mesure que votre SI s’agrandit.
L’opérateur cert-manager va dans notre cas faciliter la création, le renouvellement, s’assurer de sa validité auprès de différentes autorités de certifications ACME (let’s Encrypt), Hashicorp Vault, Venafi, etc. Afin de les mettre à disposition auprès de vos applications sur Kubernetes au travers de vos différents services ou de votre ingress via différents secrets contenant vos certificats TLS.
Fonctionnement de l’opérateur cert-manager - Source : banzaicloud.com
Dans le cas où vous auriez besoin d’un opérateur pour une tâche en particulier, sachez que vous pourrez trouver une offre conséquente sur le site operatorhub qui se trouve être un site lancé initialement par Red Hat et le trio Microsoft, Amazon et Google. Ce site a pour but de rassembler les différents opérateurs qui ont été développés pour des technologies relativement communes.
Une notion importante à considérer lorsque vous choisirez un opérateur, est son niveau de capacité que vous pourrez retrouver sur la page de chacun d’entre eux et s’appuyant sur le schéma ci-dessous : 
Comme vous pouvez le constater, le degré d’automatisation d’un opérateur peut aller de la simple installation à la gestion complète d’un déploiement comprenant les upgrades, les sauvegardes, le monitoring, le scaling et l’auto-remédiation.
Si vous souhaitez plus d’informations à ce sujet ainsi que l’exhaustivité de ce qu’englobe chaque niveau, vous pouvez vous rendre sur le site operator framework .
Avant d’aborder la partie sur la création de votre propre opérateur, il peut être intéressant
d’étudier au préalable la pertinence de développer votre propre opérateur.
Voici quelques cas de figures où le développement de votre propre opérateur pourrait se révéler intéressant :
En revanche, si l’unique intérêt de votre opérateur est de déployer une application sans aucune tâche de maintenance ou de configurations post-déploiement, mieux vaut rester sur des solutions plus appropriées telles que Helm ou Kustomize.
Si vous êtes maintenant convaincu(e) des bénéfices à développer votre opérateur, ou si vous souhaitez simplement approfondir leur fonctionnement à travers le développement de votre opérateur, voici différents projets vous permettant de vous lancer.
Les 3 premiers SDK (Software Development Kit) que nous présenterons ont une couche d’abstraction assez forte.
Si vous souhaitez développer un opérateur en ayant moins d’abstraction, les 3 projets ci-dessous devraient pouvoir répondre à vos attentes. Avec une attention particulière pour Kubebuilder, qui pourra interagir nativement en Go et vous permettant d’améliorer votre compréhension du fonctionnement des API Kubernetes.
Maintenant que vous avez un point de départ pour vous lancer, rappelons quelques bonnes pratiques auxquelles vous devez faire attention lors du développement de votre opérateur :
Nous voici à la fin de notre article sur les opérateurs, et nous espérons qu’à présent, vous avez une idée un peu plus précise du fonctionnement de ceux-ci. Comme vous l’aurez vu tout au long de cet article, les opérateurs sont des outils de plus en plus prisés pour automatiser des tâches répétitives à l’intérieur de vos clusters Kubernetes.
Ce besoin d’automatisation répond à un objectif-clé des SRE visant à faire croître vos applications, sans avoir à faire grandir vos équipes en conséquence pour garantir la fiabilité de vos applications.
En parlant de SRE, découvrez la conférence sur le sujet de Henri Gomez, Cloud Advisor chez WeScale (ex Lead SRE @Doctolib et ex Lead SRE @Saagie)

Pourquoi vouloir gérer son Infra as Code depuis Kubernetes ? Avant de voir le fonctionnement de Crossplane, intéressons-nous au problème qu’il cible.
Votre organisation a décidé d’adopter une plateforme Cloud ?C’est l’occasion rêvée pour envisager un move to cloud global du système d’information....

Introduction Sécuriser son système d’information demeure une préoccupation majeure. Et avec l’adoption des conteneurs et Kubernetes, de nouvelles...