 Aurélien Maury
Aurélien Maury



Il était une fois...
Le projet Abhra Shambhala a démarré en mars 2021, de cette envie de partager notre passion de la technique d'une façon fun et décalée, en y incluant une pointe de challenge, y compris pour nous. À l'heure de l'écriture de cet article, 235 personnes ont participé à notre jeu de piste, 22 ont rallié la ligne d'arrivée. Voyons un peu à quoi cela ressemble, sans spoiler le contenu des épreuves.
Objectifs
Faire manipuler aux joueurs :
- Git
- Docker
- Des manifestes Helm
- Un pipeline de déploiement automatisé
Bloquer la possibilité de modifier le build depuis les pull-requests, pour des raisons évidentes de sécurité.
Être en mesure de déployer/détruire la plateforme rapidement.
Avoir du déploiement continu sur nos composants applicatifs pour pouvoir livrer très rapidement en cas de problèmes.
Spoiler : quand on construit un jeu de piste technique, il y a toujours des problèmes.
Se faire plaisir en testant une stack complète avec un "vrai" projet.
Emmener les joueurs dans une histoire fun.
Outillage projet
La boîte à outils pour déployer et maintenir ce beau diagramme est composée de :
- Ansible comme grand orchestrateur. Toutes les opérations commencent par un playbook. Et le référentiel de variables est stocké sous forme de fichiers YAML au niveau des
group_vars. - Terraform pour le pilotage des ressources Scaleway, l'initialisation de Rancher et les déploiements sur le cluster Kapsule. Les opérations Terraform sont encadrées par un playbook qui gère les tâches de pré-requis, la collecte des output et la génération de fichier YAML dans les
group_varspour mettre les outputs d'une opération à disposition des playbooks suivants. - Make pour économiser la fastidieuse frappe de commandes
ansible-playbooktrop longues (et à répétition). - Direnv pour la gestion du virtualenv destiné à Ansible et le chargement des variables d'environnement de configuration Ansible et Terraform.
Architecture finale
La forme finale de notre architecture s'articule autour de 2 ressources centrales : une instance de compute et un cluster Kapsule. La vue d'avion peut se résumer à ce schéma :
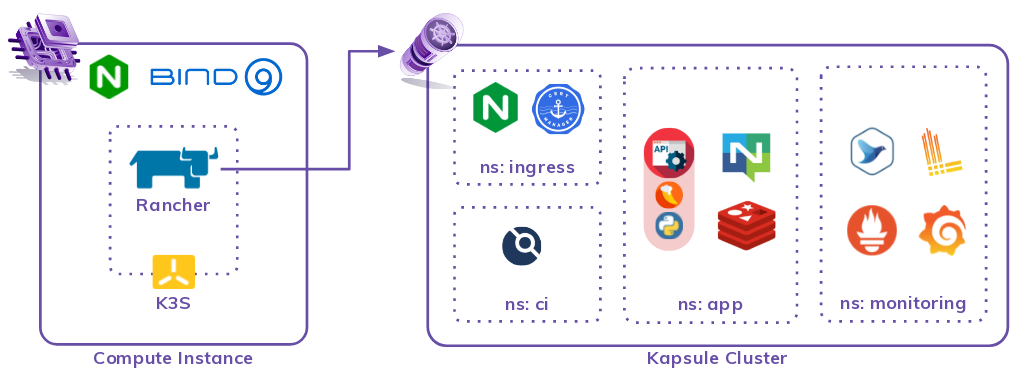
Compute Instance: Game Master
La pierre angulaire de la plateforme est une instance de compute classique, sous Debian 11, pour piloter :
- le domaine DNS que nous gérons pour nos applications
En effet, pour plus de flexibilité dans les déploiements, nous déléguons un sous-domaine à un démon Bind9 qui devient notre autorité DNS de référence. Les enregistrements DNS des déploiements applicatifs que nous exposons sur le net sont gérés ici. Les mises à jour sont poussées par un playbook Ansible.
- une jolie interface web pour gérer notre cluster Kapsule
Nous installons Rancher sur ce serveur plutôt que dans Kapsule pour pouvoir facilement changer de cluster Kapsule sans avoir à réinstaller Rancher. Comme Rancher se déploie par charts Helm, on maintient un cluster local avec une unique instance de K3S pour servir de socle d'exécution à Rancher.
Pour exposer le service Rancher, un Nginx installé de façon classique, au niveau système, fait office de reverse proxy vers un port local et porte les certificats TLS. Les API du K3S ne sont pas exposées à l'extérieur et accédées uniquement en local via Ansible.
- le déploiement de l'outillage des clusters
Une fois Rancher déployé, tout cluster qui est importé dans son périmètre de gestion peut recevoir le "rancher tooling", soit une stack d'observabilité que nous détaillons dans la section suivante.
Kapsule : Game Board
Une fois la base arrière déployée, nous démarrons un cluster Kapsule via un playbook Ansible qui :
- pilote Terraform pour la création du cluster.
- récupère les outputs utiles et lance une seconde action d'importation du cluster dans Rancher.
À l'importation, Rancher déploie ses sondes et son interface graphique d'inspection du cluster. Cela nous fournit notamment les outils pour visualiser les workloads, les logs de chaque pod et démarrer des terminaux sur chacun pour le troubleshooting.
Un dernier playbook de pilotage Terraform vient déployer :
- Grafana, le très connu dashboard manager qui cartonne, accompagné de dashboards adaptés aux composants applicatifs qui vont suivre.
- Logging Operator, une automatisation de Fluentbit et Fluentd par BanzaïCloud, qui facilite tellement la vie pour la centralisation de logs.
- Loki, pour l’agrégation et le stockage des logs à destination de Grafana.
- Le nginx-ingress-controller et cert-manager, qui serviront pour l'exposition de nos API.
Ouf ! Une fois tout ceci déployé, nous disposons d'une base de travail saine et bien équipée pour accueillir la partie applicative. Nous ne détaillerons évidemment pas ici le contenu de l'applicatif pour ne pas divulgâcher le codingame aux futurs participants !
Sachez seulement qu'il y a effectivement une composante de Continuous Deployment avec un Drone qui assure le job avec brio.
Automatisation
L'automatisation et la reproductibilité sont centrales dans notre travail. Une fois la base de code mûre, un environnement peut se monter en 2 commandes qui enchaînent un certains nombre de playbooks :
make core
- Création de l'instance Compute destinée à Rancher, via Terraform.
- Configuration du système
- Délégation de sous-domaine pour en faire l'autorité du domaine destiné aux services du jeu
- Création de certificats publics par challenge DNS auprès de Let's Encrypt
- Installation de K3S, de Rancher et exposition au travers du reverse-proxy Nginx
- Configuration initiale de Rancher, via Terraform
make kapsule
- Création du cluster Kapsule, via Terraform
- Import du cluster dans le management de Rancher
- Installation des charts Helm d'observabilité, de Rancher, via Terraform.
Retours de terrain
Ansible-Terraform
Le couple Ansible-Terraform pour la gestion de l'infra-as-code est une vraie réussite, même si l'encapsulation de Terraform par des playbooks peut paraître contre-intuitive. Dans ce contexte où le périmètre est clairement défini et qui implique de nombreuses tâches hétérogènes, Ansible comme point d'entrée facilite grandement la vie.
Ansible est une excellente glue et le module Ansible Terraform s'intègre parfaitement.
Fleet
Le composant GitOps de chez RancherLabs, Fleet, nous paraît encore jeune. L'abstraction en Custom Resources Definition proposée pour gérer les flux et les cibles de Continuous Deployment est quelque peu complexe à appréhender. Les redéploiements peuvent rapidement se mettre en PLS si trop de choses changent d'une version de chart Helm à la suivante.
De multiples messages d'erreur abscons sur des redéploiements nous ont poussés à revoir notre copie et à le supprimer de la stack en faveur de pipelines Drone. Il est recalé pour le moment, en espérant qu'il évolue (et dans le bon sens).
Drone CI
Léger, simple à déployer et à configurer, rendu graphique très sympa pour visualiser les dépendances entre tâches, les parallélisations, etc. Depuis le rachat de Drone par Harness en 2020, l'outil n'a que gagné en maturité, en fonctionnalités et en design.
Il y a une bonne bibliothèque d'actions de CI pré-mâchées et il est extrêmement simple de produire les siennes pour les mettre à disposition de vos équipes. Très bonne expérience, on recommande.
Rancher
L'automatisation de l'installation est assez directe et la configuration via le connecteur Terraform facilite grandement la mise en place. L'usage dans ce projet n'a pas été très poussé, mais clairement c'est un bon outil pour le management de cluster Kubernetes, même créés en dehors de Rancher.
Le gros plus est le fait d'avoir un chemin tracé pour l'outillage d'observabilité. On recommande.
Terraform & Scaleway
Rien de particulier à dire, si ce n'est que tout fonctionne comme dans les documentations et c'est très agréable !
La console est ergonomique et simple d’utilisation pour que le prototypage se passe à merveille. Quand vient l’heure de l’industrialisation, le provider Terraform facilite la vie et les ressources Cloud sont suffisamment explicites pour que la prise en main soit très rapide.
Conclusion
L'automatisation du montage de cette plateforme, application mise à part, a pris environ 10 jours (rapporté à un temps plein). C'est parfois frustrant, mais extrêmement formateur, de se poser un véritable objectif opérationnel plutôt que de tester uniquement pour de faux.
Au final, une bien belle aventure, qu'il est bien plus cool et motivant de partager une fois finie. Si le cœur vous en dit vous pouvez déployer votre propre instance de cette architecture et vous faire une idée par vous même en suivant ce tutoriel.
Have fun, hack in peace.
Une version anglaise de cet article est disponible sur le blog de Scaleway


Single-tenant VS Multi-tenant
En tant que fournisseur de solutions SaaS, certaines questions techniques ont un impact stratégique important sur votre métier. Celle de...