Aurélien Maury
Aurélien Maury
AWS Autoscaling avec SaltStack
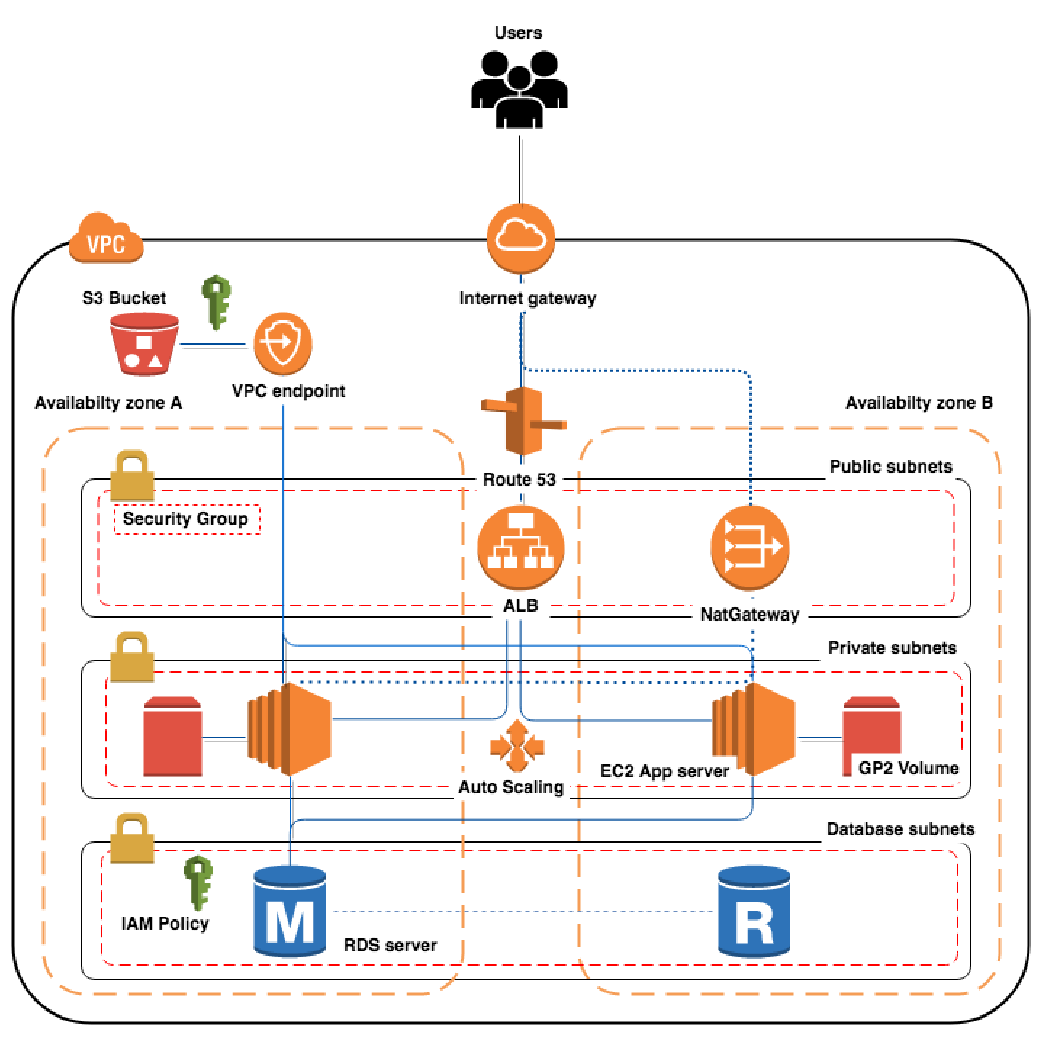
Infrastructure Pour mettre en place les notifications hooks sur un autoscaling group, il faut tout d’abord disposer d’une gateway de notification SNS...

Dans le cas d’une mise à jour de la launch configuration associée à un autoscaling group, les instances déjà lancées ne se renouvellent pas de façon automatique. Il nous faut donc orchestrer cette opération.
Pour la suite, nous nous plaçons dans le cas de figure où les instances actives ne sont pas liées à la launch configuration en vigueur sur votre autoscaling group.
Afin d’éviter la technique du Big Bang (qui consiste à éteindre toutes nos instances et les laisser redémarrer) nous allons commencer par choisir un batch_size, qui déterminera combien de serveurs doivent être manipulé à la fois. Une fois cela fait, on automatise le scénario suivant :
En respectant les temps des health check, cela assure la continuité du service.

Les pré-requis pour utiliser aws_asg_roller :
Il existe plusieurs méthodes pour que les modules AWS d’Ansible s’authentifient. J’ai choisi dans ce projet de garder celle qui me paraît la plus simple et portable, à savoir s’appuyer sur les variables d’environnement.
Pour le lecteur pressé, voici comment lancer le playbook :
git clone https://github.com/WeScale/aws_asg_roller.git
cd aws_asg_roller ansible-playbook aws_asg_roller.yml \
-e aws_region=$ASG_REGION \
-e target_asg_name=$ASG_NAME \
-e batch_size=2
Le playbook s’appuie principalement sur le module ec2_asg. Le petit piège de ce module est que certains paramètres ont une valeur par défaut. Par conséquent, si nous souhaitons maintenir tous les attributs de notre autoscaling group pendant l’opération, il faut s’appuyer sur la ligne de commande AWS pour collecter toutes les valeurs des attributs afin de les réinjecter dans nos appels à ec2_asg.
La collecte est réalisée dans le fichier inc/collect_asg_facts.yml.
Ensuite, il faut effectuer un savant calcul pour déterminer combien de temps notre module doit patienter pour voir les nouvelles instances arriver et choisir si leur démarrage est effectif. Tout ceci est déjà câblé, ne vous inquiétez pas.
Le calcul est différent en fonction du type de health check en place :
Si au bout de ce délai les instances ne sont pas healthy (ET InService dans le cas d’un check ELB), alors le module ec2_asg s’arrêtera avec une erreur.
Pour assurer le nombre d’instances actives, on lance un premier appel pour augmenter les valeurs de min_size, max_size et desired_capacity de la valeur de batch_size.
Ensuite, on réalise un deuxième appel avec les paramètres replace_all_instances: yes et replace_batch_size pour assurer la rotation des instances.
Pour finir, un dernier appel pour remettre les min_size, max_size et desired_capacity à leurs valeurs initiales, en ajoutant le paramètre wait_for_instances: no. On fait confiance à AWS pour réduire le nombre d’instances de façon autonome.
Les appels au module ec2_asg qui impliquent des destructions d’instances spécifient les termination policies pour s’assurer que les instances concernées soient celles liées à la launch configuration la plus ancienne (voir la variable termination_policies dans le fichier aws_asg_roller.yml).
Avant de vous lancer dans l’utilisation de ce playbook, vérifiez bien que les valeurs de healthy threshold et check interval sur vos load balancers et health check grace period sur votre autoscaling group sont finement définies. Cela vous évitera un temps d’attente trop long, fortement désagréable quand on effectue ce genre d’opérations.
Merci Ansible ! En espérant que ça puisse vous rendre service, je vous encourage à faire des retours, à le diffuser ou à soumettre des pull requests si vous avez des suggestions.
Have fun. Hack in peace.

Infrastructure Pour mettre en place les notifications hooks sur un autoscaling group, il faut tout d’abord disposer d’une gateway de notification SNS...

Préambule Conjointement aux solutions techniques d’Infrastructure as Code, les pratiques qui visent à améliorer la qualité des livrables ont elles...