 Ismael HOMMANI
Ismael HOMMANI


Même sans le succès qu’on pouvait lui prédire, App Engine a su trouver son public et permis l’évolution de la GCP vers ce qu’elle est devenue. GCS, Cloud Tasks et Cloud Scheduler sont des services qui nous viennent du service App Engine.
Inversement, de nouveaux services GCP sont venus enrichir l’expérience utilisateur de GAE, avec l’usage de Cloud Build notamment. Malgré plus de 10 ans d'existence, c'est un service qui reste pertinent dans un contexte Cloud Native où GKE, Cloud Run et autres Cloud Functions sont sur toutes les lèvres.
App Engine, une technologie Serverless
La notion de Serverless est avant tout opérationnelle. On y paie que pour ce que l’on consomme en mémoire, temps de compute, bande passante et stockage. Contrairement à un cliché tenace, la technologie FaaS (Function as A Service), dont le service AWS Lambda est la mascotte, n’est pas synonyme de serverless. Elle en est une illustration mais le serverless existe sous d’autres formes.
Google App Engine standard en est un exemple, Google Cloud Run un autre. Bien que leur implémentation technique et leur philosophie diffèrent, elles se rejoignent sur un point essentiel : le cycle de vie de la runtime (et de l’instance associée) qui porte le compute est à la charge exclusive du cloud provider ou du framework derrière la technologie. Nous pouvons même ajouter que ce cycle est théoriquement borné par l’arrivée d’une requête et l'émission d’une réponse.
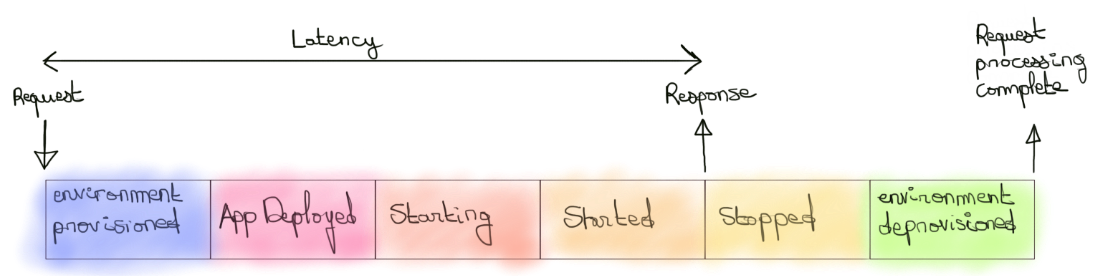
Le fait que telle technologie soit mono ou multi-threadée, qu’elle envisage une granularité de service à la fonction ou à l’application, qu’elle expose potentiellement un cluster Kubernetes, etc peuvent se considérer comme des détails techniques en vue de répondre au mieux à des besoins métier et/ou organisationnels.
L’important est de bien comprendre ce qui lie ces approches dans un contexte serverless à savoir un cycle de vie de runtime managé.
Il est à noter que les cloud providers vont potentiellement optimiser la consommation et la réactivité de leurs ressources en ne les éteignant pas directement, préférant attendre un certain temps l'émission de nouvelles requêtes qui pourront directement être traitées.
Cela reste une optimisation et ne remet pas en cause l’idée d’un cycle de vie borné et entièrement managé.
App Engine et l’approche Cloud Native
Dans une de nos vidéos sur le Cloud Native, nous donnions une définition de cette notion comme étant la capacité à construire des applications plus robustes que l’infrastructure sur laquelle elle se base.
Cela est motivé par l’existence de pannes ou de mises à jour fréquentes et non déterministes sur l’infrastructure Cloud. Ajoutons aussi la terminaison volontaire d’instance, ce que nous avons décrit dans la partie précédente.
Autrement dit, une technologie serverless vous encourage fortement à utiliser des patterns Cloud Native : Applications orientées services, services stateless, asynchronisme des communications inter-services, services de données, déploiement de nouvelles versions sans interruption de services, ...
Pointons aussi le fait que dans ce contexte un développeur doit prêter attention au coût de démarrage d’une instance qui participe au phénomène de “cold start”. En effet, “serverless” bien que synonyme de coût moindre peut aussi surtout être synonyme d’une expérience utilisateur dégradée. Un coût que vous payez en nombre d’utilisateurs.
Les usages classiques et les réflexions à avoir
App Engine sera en général conseillé pour des applications Web 3-tiers contenant un service front, un service backend et une base de données.
En réalité, cette vision est réductrice et n’importe quel type de compute peut se penser à travers App Engine. Seulement il faut être au courant des contraintes imposées par sa runtime standard.
Elle se décline sur plusieurs points :
- Type d’instance
Les instances qui porteront vos services n'offrent pas le même choix que sur du GCE par exemple. Vous serez limités à des types précis dont le coût à la seconde suit les performances en CPU et RAM. Néanmoins, le plafond peut paraître bas comparativement à l’existant GCE, et des applications gourmandes en mémoire ou CPU (voir GPU) ne seront pas adaptées pour ces types d’instance. - Langage supporté
App Engine standard ne reconnaît qu’une liste limitée de langages dans des versions particulières. Les cycles de vie de langages sont assez grands pour vous laisser le temps de vous retourner mais il faut avoir en tête que contrairement à des services où vous contrôlez la runtime, votre code devra s’adapter aux changements d’App Engine.
Par ailleurs, tous ne sont pas égaux en termes d’empreinte mémoire. Il est donc intéressant d’envisager vos services sur différents langages en fonction du travail effectué.
Enfin, selon le langage, certains appels systèmes ne seront pas permis et il est conseillé de se référer à la documentation. - Temps d’exécution d’une requête/tâche
Une instance App Engine comprend deux types d'événements : les requêtes HTTP et les événements Cloud Task. Dans les deux cas, le processus déclenché ne peut pas excéder 10 min d'exécution.
Il faut donc adapter le code à cette contrainte. Des stratégies de “checkpointing” ou “événementielles” permettent de s’en affranchir. - Filesystem
Sur chaque instance, seul /tmp est accessible en écriture. Si utilisé, cela l’est exclusivement pour du stockage de données local au traitement d’une requête. Vous n’avez aucune garantie sur la durée de vie de stockage de cette donnée. L'utiliser dans un autre cadre que du stockage temporaire sera source d’incohérences. - Multi-threading
Par multi-threading, nous comprenons la capacité de notre code à déclencher des threads pour paralléliser un traitement. Cela n’est tout simplement pas permis. Par contre une instance pourra traiter plusieurs requêtes en parallèle. Nous pouvons donc parler de multi-threading mais totalement contrôlé par App Engine et non votre code. Notons que c’est la même approche pour Cloud Run managé. Par contre, dans le cas de Cloud Functions nous sommes dans une approche mono-threadé i.e une requête, une fonction. Les traitements en parallèle s'envisagent à travers des Cloud Tasks qui seront traitées par App Engine ou d’autres services de la GCP (Cloud Functions, Cloud Run, GCE). Cela dit, on déplorera l’absence d’un système de fork/join natif qui permet de savoir à quel moment toutes les tâches parallèles d’un même contexte sont terminées. - Manipulation de la runtime
L’apport d’App Engine est de permettre aux développeurs cloud native de s’abstraire de l'opérationnel tout en ayant un niveau de performance intéressant en terme de latence. Cela est conditionné par un certain nombre de concessions, dont le fait de se contenter de la runtime et l’environnement fourni.
C’est à ces conditions que vous bénéficierez du management et des performances d'élasticité offertes par App Engine. D'autres limites existent, liées à des quotas d’appels ou de ressources, mais elles remettent moins en cause la manière de penser son application.
Le cas App Engine flexible
Les précédentes contraintes peuvent ne pas convenir et dans ce cas, il existe App Engine Flexible sur lequel un Dockerfile vous permettra de contrôler la runtime. La plupart des contraintes précédentes disparaîtront, mais au dépend de trois inconvénients majeurs :
- On ne scale plus à 0 pour un service donné. Nous ne sommes plus dans un paradigme serverless du fait d'un coût plancher.
- Le temps de déploiement est considérablement augmenté, ce qui nuit à l’expérience de développement.
- Une nouvelle instance sera provisionnée à la minute et non à la seconde, dégradant la latence de l’application.
La sortie de service tel que Cloud Run managé rend App Engine Flexible moins attrayant mais nous n’entrerons pas ici dans ces détails là.
App Engine et l’expérience développeur
Un projet App Engine se pense à travers des versions de service dont chacune représente du code poussé par une équipe de développement.
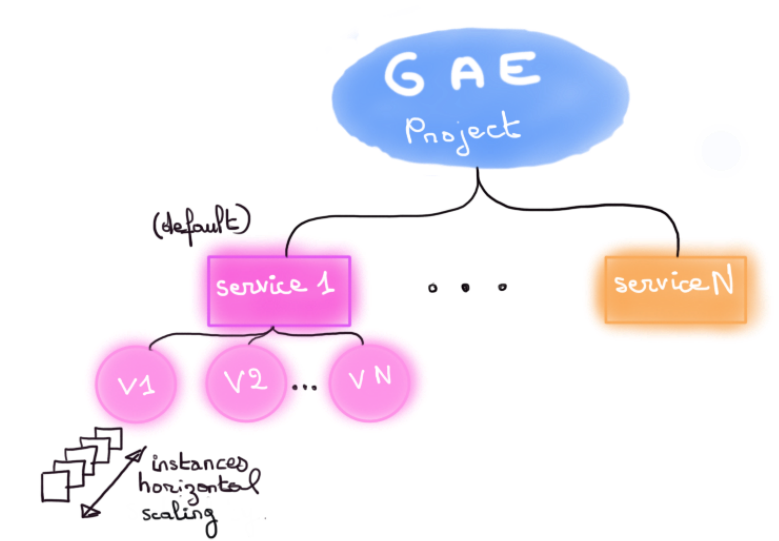
Pas de cérémonie particulière, un simple gcloud app deploy suffira à déployer une version d’un service.
Chaque service se configure avec un fichier app.yaml qui décrit différents aspects, dont le service à créer ou mettre à jour, sa scalabilité, la runtime associée, ainsi que les handlers de requêtes (i.e quelles parties de mon code pour gérer /A ou /B).
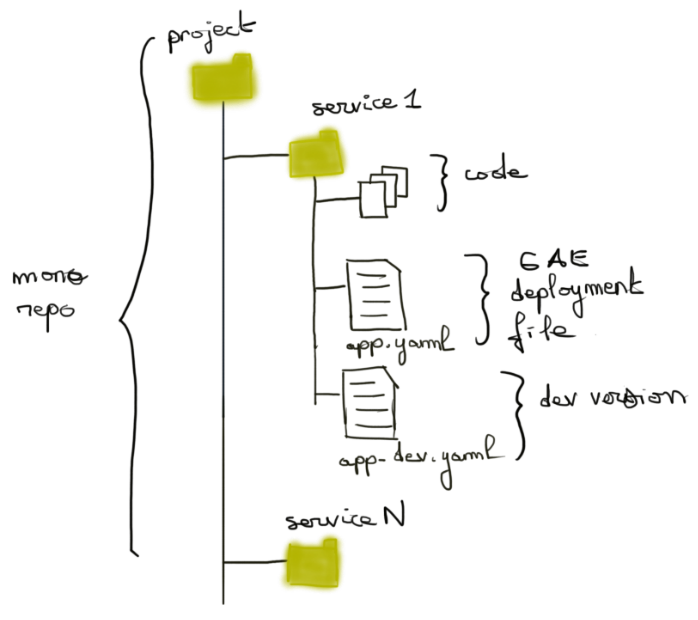
Ce sont les seuls éléments opérationnels dont un développeur devra se soucier. En général, il se contentera de coder des logiques métiers et fonctionnelles dont la définition des points d’entrée est aujourd’hui très standardisée par des frameworks Web (Spring Boot, Flask, Rails,...).
À sa charge aussi optionnellement d’organiser ce code en services App Engine, avec leur propre runtime et leur propre périmètre de responsabilité (a.k.a une approche microservice).
La communication pourra alors se faire par appel direct HTTP ou de manière asynchrone avec Google Cloud Task ou Cloud PubSub.
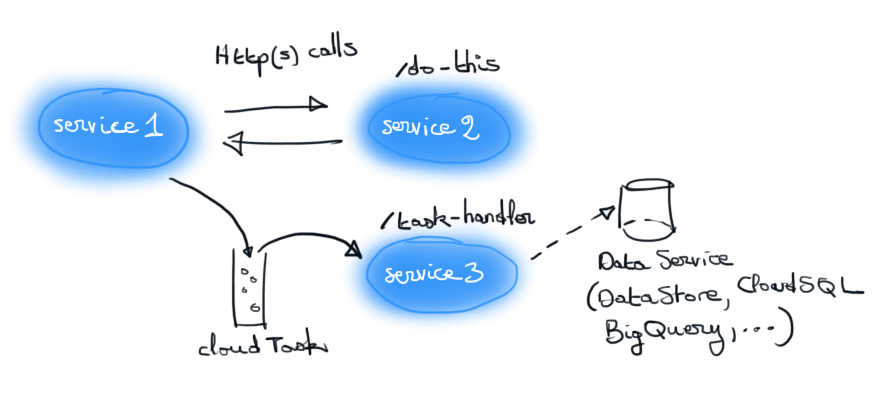
L’adhérence du code à App Engine est assez faible. Il suffira de se contraindre aux runtimes supportées pour faire en sorte que l’expérience de test de votre webApp en local se rapproche de ce qui se passera sur App Engine.
Ce raisonnement est limité par l’usage de PubSub ou Cloud tasks pour la communication inter services. Dans ce cas, il faudra envisager les tests en local de manière plus cloisonnée et abandonner l’idée de reproduire une architecture iso à celle qui est montée sur App Engine.
Autrement dit, App Engine on-premise n’existe pas et n’existera d’ailleurs pas.
Notons enfin la synergie de App Engine avec d’autres services serverless tel que Google IAP pour ajouter une couche d’authentification Google à nos services ou Google Api Gateway pour permettre une meilleure gouvernance des APIs exposées.
Plus classiquement on y associera des services data et de communications inter-service ou avec l'extérieur.
La partie Ops
La relative simplicité d’usage de GAE ne doit pas faire oublier ce que la GCP prend à sa charge.
En premier lieu, la scalabilité horizontale par service a été et reste l’argument marketing fort. En mode automatique (mode par défaut), vos services s’adaptent de manière optimale à la charge en créant ou supprimant des instances à des délais d’ordre de la milliseconde.
La partie Network est aussi entièrement à la charge de la GCP. Vous ne pouvez pas accéder au VPC qui supporte votre projet App Engine, et Google s’assure que tout s’y passe correctement en termes de sécurité, load balancing des requêtes, DNS, haute disponibilité, etc.
En ce qui concerne le load balancing un système intégré de traffic splitting sur les versions de services déployés vous permettra d’envisager de manière simple des stratégies de release.
Point intéressant, GCP vous fournit un certificat TLS sur les domaines par défaut de vos services.
La partie CI/CD, qui consiste à packager votre code en image OCI et le déployer, a longtemps été une boîte noire… jusqu’à récemment.
Désormais, le processus est transparent et se base sur des services existant de GCP et peut se résumer ainsi : votre code est exposé sur un bucket GCS pour être consommé par un pipeline Cloud Build qui, via Cloud Native BuildPack, génère une image OCI stockée dans Google Cloud registry.
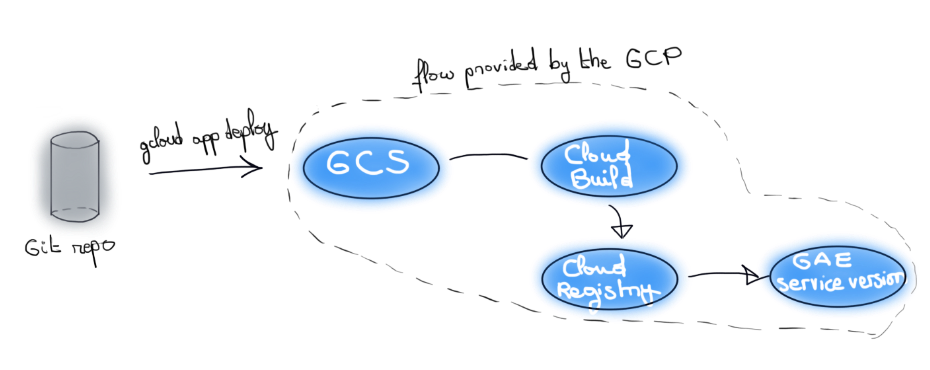
Il est très instructif de voir ces éléments en action. On laissera en exercice pour les curieux le soin de jouer avec l’image produite avec l’outil Dive, et de tester la compatibilité de cette image avec un service comme Cloud Run ou Cloud Functions.
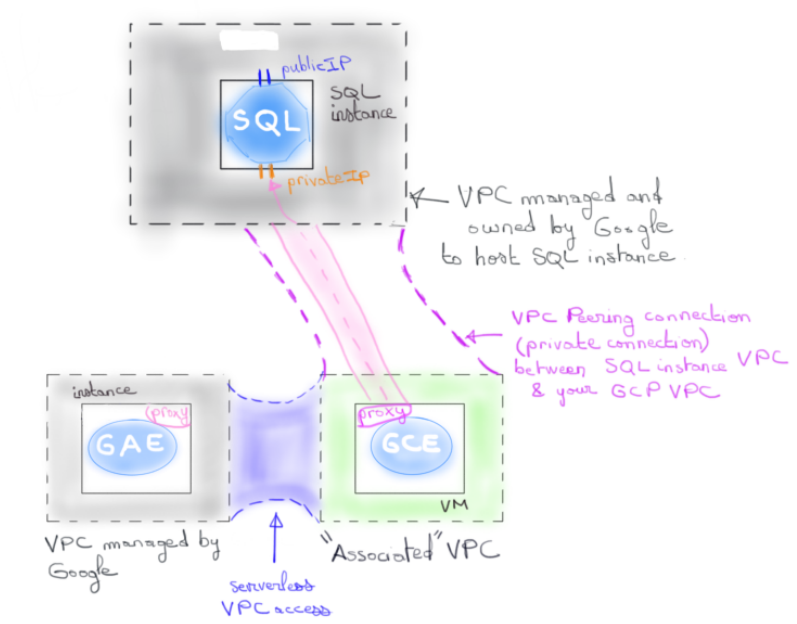
Il existe cependant une situation où vous devrez mettre les mains dans le cambouis. Lorsque vous souhaitez communiquer avec des ressources n’exposant pas d’IP publique se trouvant sur un VPC de votre projet, il est nécessaire d’établir une connexion entre ladite ressource et votre réseau App Engine. Un connecteur Serverless VPC access vous permettra d’autoriser cette communication. Nous en parlions d’ailleurs lors d’un précédent article sur Cloud SQL.
Problèmes de fond
Le vendor lock-in a souvent été un point d’accroche à l’usage de ce service. Cela devient de moins en moins évident du fait que la runtime des langages ne soit plus propre à App Engine et nous dirons que le problème n’est pas là. Du code fait pour tourner sur App Engine tournera ailleurs sans problème.
Clairement en avance sur son temps en 2008, App Engine reste emprunt d’une réflexion d’une autre époque. Depuis 2008, la forme a certes évolué mais pas le fond. On est vraiment sur une technologie qui pense avant tout service mais pas tant leur relation et la data qui gravite autour. Certes la cohérence des services GCP atténue ce problème et on intégrera aisément un service cloud task, pub/sub, datastore, cloud SQL, … Mais ce sont des mécaniques qui commencent à devenir trop manuelles et surtout trop explicites. Des approches plus modernes rendent abstraites ces considérations via des frameworks comme Dapr allié à Kubernetes. App Engine y est par nature incompatible. Plus largement, il est incompatible avec de nombreuses approches modernes prônées par le mouvement Cloud Native.
Comment penser par exemple du Chaos Engineering avec une application App Engine ? Comment penser l’intégration avec des produits Open Source autrement que par des approches manuelles ? Comment penser des stratégies systématiques de retry pour les communications entre services autrement que manuellement ?
Autant de questions que l’on peut résumer à une question unique : comment penser Cloud Native façon 2021 sur une plateforme qui reste ancrée sur des choix de 2008 ?
La réponse est simple, vous ne pouvez pas. Attention, cela ne veut pas dire que App Engine est intrinsèquement à éviter. C’est justement cette capacité à vous prendre par la main qui va faire que cette technologie est la bonne dans de nombreux cas. Celui de la startup qui doit monter son business rapidement est le premier venant à l’esprit. Snapchat tourne par exemple entièrement sur App Engine.
La problématique revient donc à déterminer à quel point je suis capable de me projeter avec App Engine et si j’ai la maturité suffisante pour envisager d’autres options.
Bien sûr c’est rarement un choix absolu qui est fait et un projet sur App Engine n’empêche pas d’aller sur une autre technologie pour un autre.
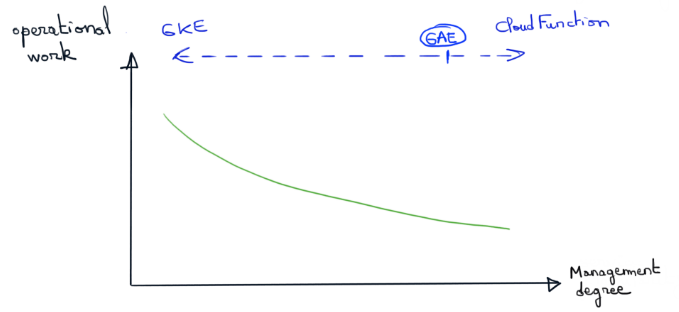
Les graphiques suivants résument l’idée selon laquelle la solution adaptée à votre business et vos équipes n’existe qu’à travers des compromis. A vous de trouver le bon positionnement du curseur..
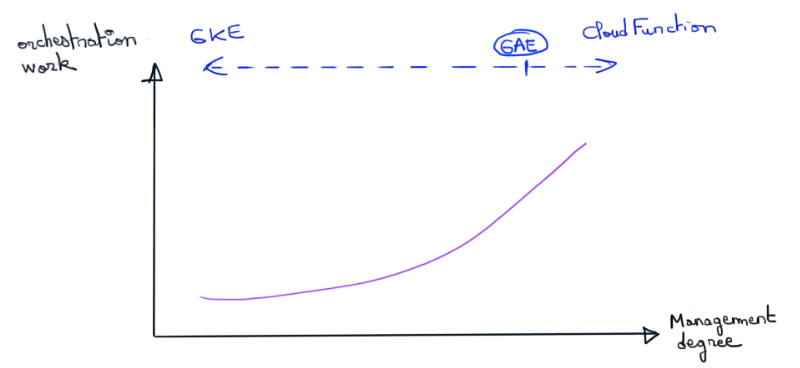
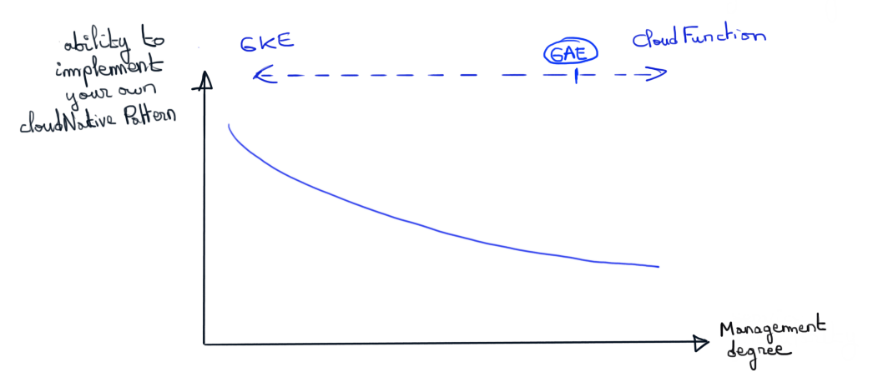
Un futur pérenne ?
Google a une appétence prononcée pour offrir des services managés. La position extrême étant le paradigme serverless où le management va jusqu’au cycle de vie de l’instance qui porte votre compute. En 2008, cela n’était pas forcément une tendance, et le pari gagnant de fournisseurs Cloud comme AWS ou Azure a été de répondre à une demande plutôt que de la créer. Google a cependant rectifié le tir en proposant des solutions se rapprochant de la philosophie de la concurrence sans pour autant dénigrer ses premiers amours.
La sortie récente de GKE Autopilot est une sorte de confirmation de cette idée.
En sortant un produit vous permettant de raisonner uniquement au niveau du pod (le node étant à la charge de GCP), Google dit assez pudiquement “vous n’êtes pas assez bon pour gérer cette complexité, laissez-nous faire". Alors évidemment, on enrobe tout cela d’un pragmatique “concentrez-vous sur votre code et la valeur business” mais le point principal est là : on converge vers des solutions à la App Engine.
En 2008, Google proposait l’orchestration de conteneur du futur avec App Engine : “Occupez-vous juste du code”.
En 2015, Google répond au besoin de faire du Kubernetes sur GCP avec GKE. Une offre semi-managée tant il reste des degrés de contrôle à la charge du client.
En 2017, les Cloud Functions sortent et nous l’interprétons plus comme une réponse aux AWS lambdas que comme une avancée stratégique du serverless Google.
En 2018, Cloud Run arrive et on se rapproche plus d’un serverless autour de Kubernetes avec en bonus pour les intéressés, une version managée qui vous permet de ne vous occuper que des conteneurs.
2021, nous avons une nouvelle version GKE dite Autopilot dont l’annonce est “Occupez-vous seulement des pods”.
Le schéma ci-dessous résume l’idée avec un vocabulaire Kubernetes :
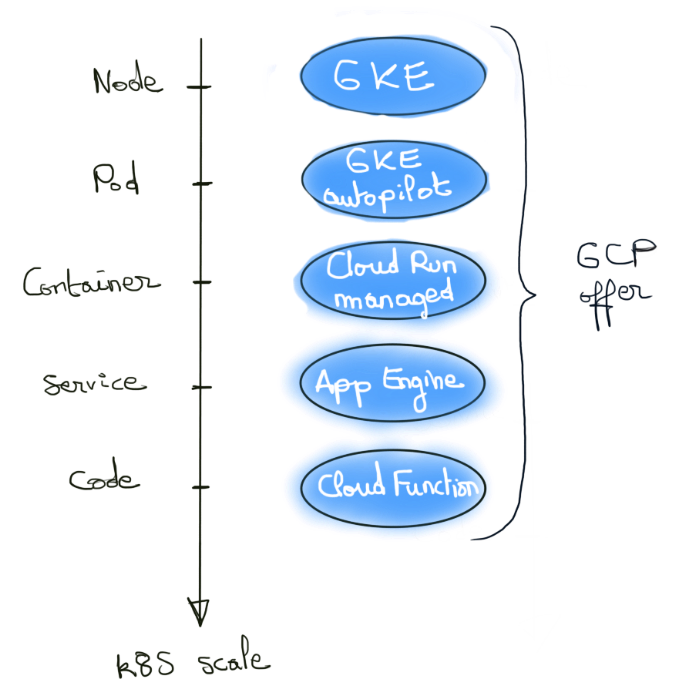
Voyez-vous où tout cela nous mène ? On peut penser que GCP veut convaincre à bas bruit que ses choix initiaux étaient les bons. Les mouvements des autres Cloud leur donnent raison, mais telle la Cassandre de Troie, il a fallu attendre un certain temps avant d’accepter un postulat de 2008 en décalage de la doxa.
On distingue la forme, mais quel est le fond ? On imagine aisément que pour les équipes de SRE Google, App Engine reste une niche technologique qui demande des compétences particulières de gestion par rapport à des services tels GKE.
Il est donc probable que nous assistions aujourd’hui à une convergence technologique, dont le point final sera un service unique du point de vue Google et dont le paramétrage permettra de balayer le spectre des produits actuels.
Que ces paramétrages vous soit exposés ou non sera une décision relevant du marketing, mais du point de vue SRE Google, ce sera blanc-bonnet et bonnet-blanc :)
Conclusion
App Engine est un produit d’une exceptionnelle longévité qui a été en avance sur son temps. Les nouveaux produits sortis sur la GCP ou chez la concurrence atténuent cette affirmation et son choix relève aujourd’hui plus de besoins spécifiques que de bénéficier d’une rupture technologique.
Des besoins d’hébergement d’application Web seront toujours présents et App Engine continuera d’y répondre. La présence d’autres services tels Cloud Run se pose néanmoins comme des alternatives crédibles à l’approche dirigiste de GAE.
Dans une approche Cloud Native, App Engine est une plateforme avec une base solide. Peut être un peu trop solide, car vous serez limités en terme de mise en place de patterns dits Cloud Native.
Mais en avez-vous vraiment besoin ? Une question à laquelle on vous laissera le soin de répondre.
