

13 minutes de lecture

Introduction
Lorsqu'on souhaite entamer la consolidation d’un système d’information, il est important de s’intéresser à la centralisation des logs (évènement système et log applicatif). Dans cet article, nous allons voir en quoi cela consiste et ce que cela apporte en matière de gestion et de sécurité. Nous aborderons également les étapes et processus à mettre en place pour accomplir cette tâche.
La centralisation des logs est une opération simple à faire sur des systèmes d’informations peu étendus (au niveau réseau comme au niveau géographique). Cela s’avère plus complexe sur des infrastructures de grande taille ou dans le Cloud. C’est une opération à mener pour éviter certains risques et avoir une vue réelle de l’état d’un SI.
Je tiens à préciser que dans des environnements conteneurisés (avec Kubernetes et plus globalement la conteneurisation applicative), la gestion est différente. Une application exécutée dans un conteneur doit répondre à un certain nombre de critères dans son développement pour bénéficier pleinement des avantages des plateformes Cloud. Si l’on se base sur 12 Factor App et plus spécifiquement la règle N°11 qui traite de la gestion des événements, il est important que votre application conteneurisée génère ses logs dans les sorties standards (stdout et stderr).
Un log est un événement d’une importance plus ou moins élevée envoyé par un service, un système, un élément réseau ou une application. Les journaux d’événements permettent de retracer les actions et la vie d’un système ou d’une application. Ils ont un intérêt et une importance cruciale en informatique, car il s’agit là de savoir ce qui s’est passé sur un ensemble d’applications ou systèmes pour pouvoir expliquer ou être informé d’une erreur, d’un comportement ou d’un crash sur un service ou une application.
Syslog est un protocole définissant un service de journaux d'événements d'un système informatique. C'est aussi le nom du format qui permet ces échanges.
Dans un log au format syslog (RFC5424), les informations peuvent varier en fonction des besoins spécifiques de l'application ou du système. Cependant, voici quelques exemples courants qui peuvent être inclus :
2017-05-11T21:14:15.003Z mymachine.example.com - ID47 [exampleSDID@32473 iut="3" eventSource=" eventID="1011"] BOMAn application log entry…
- la date à laquelle a été émis le log ;
- le nom de l'équipement, système ou application ayant généré le log ;
- une information sur le processus qui a déclenché cette émission ;
- le niveau de priorité du log ;
- un identifiant du processus ;
- un corps de message.
Il convient de noter que certaines ces informations sont optionnelles tel que l’adresse IP qui n’est pas obligatoire mais contractuelle. Elles peuvent varier en fonction de la configuration du système et des applications qui génèrent les logs. La structure et le contenu précis des logs peuvent être personnalisés pour répondre aux besoins spécifiques de l'environnement de journalisation.
La priorité du message permet de déterminer la catégorie et la gravité du journal. Cette indication est particulièrement importante car elle normalise de fait la représentation de la catégorie et de la gravité d'un log.
Les niveaux de gravité Syslog, appelés Severity level en anglais, sont au nombre de huit, représentés par un chiffre de 0 (Emergency) à 7 (Debug).
Aujourd’hui, la grande majorité des systèmes, applications et éléments réseau produisent des logs. Dans la quasi-totalité des cas sans centralisation, les événements sont stockés de manière locale sur la machine ou le conteneur.
La centralisation des logs consiste simplement à mettre l’ensemble des logs émis sur un même système ou une même plateforme. On reprend alors le principe de la supervision, qui consiste à centraliser les éléments de surveillance sur une plateforme unique. On appellera cela un point unique de communication, ou point unique de contact (Single Point Of Contact – SPOC) pour l’analyse des logs.
La centralisation des logs offre une vue globale sur divers types de logs, chacun apportant des informations précieuses pour comprendre l'activité d'une entreprise.
Les logs système permettent de suivre les événements et l’état de santé des systèmes et des services.
Les logs applicatifs fournissent des informations sur l'exécution des applications, les erreurs rencontrées, les transactions et les actions effectuées.
Les logs réseau permettent de surveiller les flux de données, de détecter les problèmes de connectivité et d'analyser le trafic réseau.
Enfin, les logs de sécurité sont essentiels pour détecter les tentatives d'intrusion, les violations de politiques de sécurité et les comportements suspects.
La centralisation de ces différents types de logs permet une analyse unifiée, offrant une visibilité complète sur les activités des systèmes et des applications. Cela facilite l'identification rapide des problèmes, l'analyse des tendances et la détection des menaces potentielles, ce qui contribue à renforcer la sécurité et à améliorer la stabilité des services de l'entreprise.
Vous serez en capacité de retrouver un événement même après une attaque ou un crash et de faire corréler un ensemble d’événements pour amener à la meilleure gestion des systèmes. Cela permet d’avoir un appui solide pour la prise de décision quant à l’évolution du SI. La plupart du temps, les logs sur les systèmes ou applications sont ouverts uniquement lors d’un problème. Ils peuvent nous aider à déboguer une situation. Le reste du temps, ils ne sont lus que par les scripts et les outils d’archivage ou de suppression. Or un événement, surtout lorsqu’il a une criticité élevée, requiert un niveau d’urgence important, soit pour le corriger, soit pour connaître l’impact derrière ces avertissements.
La centralisation n’est pas un processus qui se fait du jour au lendemain. Cela implique de réfléchir à plusieurs étapes de mise en place :
- la communication entre différents systèmes ;
- le parcours des paquets au travers des différents réseaux pour arriver à une même cible ;
- les catégories et l’organisation à avoir ;
- les informations à exporter et celles à mettre de côté, etc.
Je vais détailler ces aspects tout au long de cet article.
Contexte et objectifs
Si vous n’avez pas de solution de centralisation en place, il y a fort à parier que vos serveurs et applications gardent une trace de leur activité au travers d’événements stockés dans des fichiers de logs locaux, sans traitement ni filtrage. Dans ce cas de figure, il est difficile d’avoir une analyse consolidée sur l’ensemble de l’activité de vos services.
Dans un premier temps, il faut définir les objectifs de ce projet qui est, rappelons-le, de mettre en place une solution de gestion des logs centralisée.
On peut se poser quelques questions pour fixer les objectifs :
- À quelles équipes sera destinée la plateforme ?
- Quels types de logs l’on souhaite centraliser ? (système, applicatif, réseau, etc.)
- Est-ce que l’on veut une plateforme hautement disponible ?
- etc.
Identifier les besoins
L’identification des besoins est une étape cruciale. Vous allez devoir définir les exigences de votre plateforme et évaluer les éléments attendus. Cette étape permet d'analyser les attentes et d'être capable de mesurer si ceux-ci ont été atteints.
Généralement, pour des projets de centralisation des logs, nous allons porter une attention sur la fiabilisation du système pour ne pas perdre de logs. Bien souvent, on souhaite avoir l’ensemble des logs utiles et exploitables sur une même plateforme. Il faudra alors prévoir des règles de filtrages. L’aspect légal est à prendre en considération. Les logs peuvent contenir des informations sensibles et confidentielles, tant au niveau des données personnelles des utilisateurs que des informations internes à l'entreprise. Par conséquent, il est nécessaire de se conformer aux réglementations, telles que le Règlement général sur la protection des données (RGPD) en Europe ou les lois nationales sur la confidentialité des données. Il est nécessaire d'établir des règles claires sur la durée pendant laquelle les logs doivent être conservés, en fonction de leur type et de leur importance. Certaines réglementations peuvent imposer des délais spécifiques, tandis que d'autres permettent une certaine flexibilité. Par exemple, les logs relatifs aux transactions financières peuvent nécessiter une conservation à long terme pour des raisons de conformité et d'audit, tandis que d'autres logs peuvent être conservés pendant des périodes plus courtes.
Cette liste est bien évidemment propre et adaptable à chaque projet, en fonction de votre contexte et de vos objectifs.
Analyser l’existant
Procéder à une analyse de l’existant pour ce projet est essentiel. Cela va permettre de prendre connaissance de la gestion ou non des logs au sein de votre SI et d’adapter votre projet en conséquence.
Cette analyse a pour but de recenser les informations relatives aux logs afin de déterminer s’il y a des systèmes déjà mis en place et utilisés par vos équipes ; le but étant de prendre connaissance de ce qu’il faudra garder, modifier, supprimer ou concevoir. Dans cet article nous
Voici une liste de questions non-exhaustives auxquelles vous devriez vous pouvoir répondre à la fin de votre analyse :
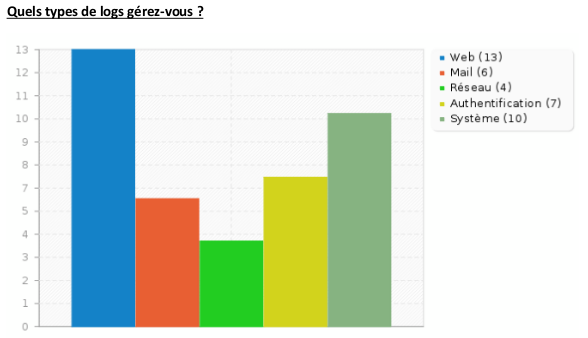
- Quels sont les types de logs gérés ?
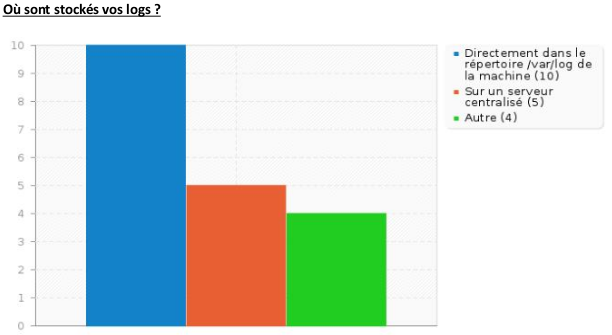
- Où sont-ils stockés ?
- Est-ce que les logs sont consultés ou recherchés à l’aide d’une interface graphique ?
- Quels outils sont utilisés pour la gestion des logs ?
- Quelle est la durée de rétention des logs et l’espace disque occupé ?
- Sont-ils compressés ?
- Quelle est l’utilisation des logs (Lecture simple, debug, alerte, historisation, etc.) ?
- Des filtrages sont-ils appliqués ?
- etc.
Vous pouvez ensuite exporter les données en graphique pour interpréter au mieux les résultats de votre enquête (dans le cadre de cet article, il est question d’une enquête par questionnaire menée auprès des différentes équipes). Voici un exemple de graphiques :
Ce type d’enquête permet d’avoir une vue d’ensemble de l’utilisation et de la gestion des logs à date, au sein de votre SI.
Vous pourrez, par exemple, constater que vos logs sont consultés de manières très différentes entre vos équipes, ce qui confirmera l’utilité de votre projet de centralisation.
Le deuxième point important sont les informations recueillies, telles que les durées de rétention et de l’espace de stockage utilisé. Cela va vous aider dans le choix et la configuration de votre prochaine solution.
Vous allez également pouvoir vous baser sur ces résultats pour effectuer une étude comparative des différentes solutions qui peuvent être mises en place pour répondre à la problématique de votre projet.
Étude comparative des solutions du marché
Dans un projet de centralisation des logs, une étude comparative des différentes solutions est indispensable. Elle permet de déterminer les solutions les plus adaptées pour répondre à votre cahier des charges.
Elle peut se présenter sous forme d’une étude consacrée à la présentation des outils. Ensuite, il conviendra de comparer ces différentes solutions sur des critères que vous aurez déterminés.
On peut prendre les quelques leaders du marché :
La suite Elastic est une offre composée de 3 outils principaux :
- Elasticsearch qui est un moteur de recherche orienté document facilement évolutif pour répondre à de gros volumes de données,
- Logstash qui permet de configurer des flux d’entrées et des flux de sortie,
- Kibana qui est une IHM (Interface Homme Machine) permettant de consulter les documents d’une base Elasticsearch et d’en sortir des tableaux de bords.
Ces 3 produits sont maintenus par la société Elastic.
Cette solution est très simple à mettre en œuvre avec des outils qui se prennent en main rapidement.
Logstash permet, grâce à de nombreux plugins, d’intégrer des logs en provenance de fichiers, d’un RabbitMQ (protocole AMQP), d’un syslog, etc. Kibana permet de créer des tableaux de bords très complets avec de nombreux widgets : camembert, graphique, mappemonde, etc.
La suite Elastic propose également des fonctionnalités payantes comme des API pensées pour les développeurs, des fonctionnalités de sécurité conçues pour les entreprises, du Machine Learning et des graphiques d’analyse.
Graylog est une solution composée de 3 briques :
- Elasticsearch qui est un moteur de recherche orienté document facilement évolutif pour répondre à de gros volumes de données
- MongoDB qui est une base NoSQL orientée documents permettant de stocker la configuration et quelques autres paramètres,
- Graylog pour la collecte et la visualisation des logs à l’aide d’une interface graphique.
Graylog permet d’intégrer des logs au format syslog mais également des documents au format GELF (Graylog Extended Log Format). C’est un syslog amélioré contenant des métadatas et qui n’a pas de limite de taille sur la longueur du message. Les logs sont traités par la partie serveur et enregistrés dans Elasticsearch qui est un moteur de recherche Open Source écrit en Java basé sur Lucene (bibliothèque Open Source écrite en Java qui permet d'indexer et de chercher du texte).
Il utilise une base de données NoSQL orientée document qu’il indexe et interroge via une API REST qui, dans mon cas, sera via l’interface Graylog. Autrement dit, via une requête de type « HTTP PUT », il va remplir et mettre à jour la base de données et via une autre requête comme « HTTP GET », il va accéder à ces données et renvoyer le résultat de la recherche. L’interface graphique permet d’effectuer des recherches et de configurer des flux (catégorisation des événements), des alertes, des tableaux de bords, gérer des utilisateurs et des droits d’accès.
Après avoir présenté ces 2 outils, il est possible de comparer leurs fonctionnalités, dans un tableau par exemple :
| Critères |
Suite Elastic |
Graylog |
| Limitation de postes/serveurs |
Pas de limitation |
Pas de limitation |
| Filtrage des logs |
Oui |
Oui |
| Consultation des logs brut |
Oui (si non parsé/découpé) |
Oui (si non parsé/découpé) |
| Règles de rétention |
Oui |
Oui |
| Gestion des logs Windows |
Oui |
Oui |
| Interface Web |
Oui |
Oui |
| Sécurité (Connection à l’interface web |
Oui via le plugin x-pack |
Oui |
| Répond au critère |
Répond partiellement au critère |
Ne répond pas au critère |
Bien évidemment, il convient d’adapter les critères suivant votre cahier des charges et vos besoins.
Nous aurions pu également présenter Grafana et Loki qui sont deux outils couramment utilisés pour la centralisation des logs.
Grafana est une plateforme open source de visualisation et de monitoring des données, tandis que Loki est un système de gestion des logs spécialement conçu pour fonctionner avec cet outil de visualisation. Ensemble, ils permettent d'explorer, de filtrer et de consulter les logs de manière conviviale.
Il se distingue de ses concurrents dans le domaine de la gestion des logs grâce à plusieurs caractéristiques clés. Il stocke les logs comme des métriques, il réalise les parsing à la lecture et non à l'écriture. Concernant le stockage des données, il s'intègre parfaitement avec du stockage objets permettant de limiter les coûts et d’augmenter la sécurité.
Loki stocke les index et les métadonnées des logs, ce qui permet d’économiser du stockage. Grafana offre une interface utilisateur pour créer des tableaux de bord et des alertes basées sur les données de logs collectées par Loki. Cette combinaison offre une vue d'ensemble complète de votre infrastructure.
Ce duo de choc, pour la centralisation des logs permet une analyse efficace, facilitant ainsi la détection rapide des problèmes et l'amélioration des performances de votre infrastructure cloud. Car oui, la solution Grafana et Loki est largement utilisée dans les environnements d'infrastructure basés sur le cloud, y compris les déploiements cloud natifs, les architectures de microservices et les conteneurs.
Pour en revenir avec ce tableau comparatif, nous pouvons imaginer que dans une startup ou une entreprise de petite taille, la suite Elastic sera rapidement mise en place. Suivant les besoins, il sera possible de la faire évoluer avec les produits proposés par la société Elastic à l’aide de plugins supplémentaires mais payants (Watcher, Shield, X-Pack, etc.) ou de développer ses propres outils pour gérer les alertes. Dès lors qu’une entreprise aura besoin d’une authentification pour les utilisateurs et d’alertes pour pouvoir agir rapidement, la solution Graylog sera la plus à même de répondre au besoin.
Il convient également d’aborder les clients tels que Fluentd, Filebeat et Promtail qui sont des agents de collecte de logs. Ils sont couramment utilisés pour l'acheminement des logs vers des systèmes de centralisation.
Fluentd est open source il peut agréger, filtrer et router les logs vers différentes destinations. Il dispose d'une architecture flexible et prend en charge de nombreux formats de logs, ce qui en fait un choix polyvalent pour la collecte de logs à grande échelle.
Filebeat, quant à lui, est un agent léger développé par Elastic. Il est conçu pour la collecte de logs et d'autres données dans les environnements distribués. Filebeat surveille les fichiers de logs spécifiés et les envoie de manière fiable à des systèmes de centralisation tels que Elasticsearch ou Logstash.
Promtail est un agent spécialement conçu pour l'intégration avec Loki, le système de gestion des logs de Grafana. Il permet la collecte et l'expédition des logs au format Loki, en utilisant des modèles de scraping pour extraire des informations spécifiques à partir de différentes sources de logs.
Ces clients offrent des fonctionnalités de collecte de logs efficaces, mais diffèrent légèrement dans leur conception et leurs capacités. Le choix entre Fluentd, Filebeat, Promtail ou d'autres agents dépendra des besoins spécifiques de votre infrastructure, de la compatibilité avec les systèmes de centralisation utilisés et des fonctionnalités supplémentaires requises, telles que la prise en charge de formats de logs spécifiques, la scalabilité ou la facilité d'intégration avec d'autres outils.
On peut également citer l'utilisation de services managés dans le cloud, tels que le service Opensearch d'AWS ou Grafana Cloud, offre plusieurs avantages significatifs. Tout d'abord, ces services déchargent les tâches de gestion et de maintenance de l'infrastructure sur le fournisseur cloud, ce qui permet aux équipes de se concentrer sur des tâches à plus forte valeur ajoutée. Cela réduit la complexité opérationnelle et libère des ressources internes.
En optant pour des services managés, vous bénéficiez également d'une évolutivité et d'une flexibilité accrues. Ces services sont conçus pour s'adapter dynamiquement aux besoins de votre application ou de votre infrastructure. Vous pouvez facilement ajuster les capacités à la demande, que ce soit en augmentant les ressources pour faire face à une augmentation du trafic ou en réduisant les coûts pendant les périodes de moindre activité.
Choix et tests de la solution
Après avoir étudié les tableaux comparatifs, il faut tester les solutions, de préférence dans un environnement spécifique dédié. Ce dernier vous permettra d’isoler vos tests du réseau de l’entreprise pour être plus libres, sans vous soucier de la dégradation du réseau en cas de mauvaises manipulations.
Pour les premières phases de tests, je vous conseille de rester dans une configuration simple avec un serveur et un client. Jugez de la pertinence ou non de la solution avant d'itérer vers une architecture plus complexe.
Ces tests vont vous permettre de valider les besoins spécifiés dans votre cahier des charges et de faire faire le choix de la solution.
Sauvegarde et surveillance
Surveiller en temps réel le bon fonctionnement de l’infrastructure de log est capitale. Vous devrez mettre en place une solution qui vous permet de mesurer constamment les niveaux de qualité de service de vos outils informatiques : serveurs, réseaux, logiciels et applications afin d’être alertés immédiatement si un problème ou une baisse des performances venait à survenir.
En cas de dysfonctionnement ou de non-atteinte des objectifs de qualité de service, le système de supervision permet d’envoyer des alertes 24h/24 et 7j/7 avec tous les éléments techniques qui facilitent l’établissement rapide du diagnostic de panne. Cela permet de réagir plus rapidement et de limiter au maximum les perturbations pour les utilisateurs des outils informatiques.
Il faut également penser à la durée de rétention des logs qui est un aspect crucial à prendre en compte lors de la centralisation des logs.
Il est essentiel de définir des politiques claires concernant la conservation des logs en fonction de leur type et de leur importance. La durée de rétention peut varier en fonction des exigences légales, de vos besoins opérationnels et des politiques de sécurité de votre entreprise. Certains types de logs, tels que les logs de sécurité, peuvent nécessiter une rétention à long terme pour des raisons légales, de conformité au d’audits. D'autres types de logs, tels que les logs système ou applicatifs, peuvent être conservés pendant une période plus courte en fonction des besoins de dépannage.
Les fournisseurs cloud déploient des architectures redondantes et répartissent les charges de travail sur plusieurs zones de disponibilité, ce qui réduit les risques de temps d'arrêt et assure une continuité de service élevée. De plus, ces services incluent souvent des mécanismes de sauvegarde, de récupération en cas de sinistre et de sécurité avancée, vous permettant de protéger vos données et vos applications de manière fiable. Ceci présente un autre avantage majeur des services managés qui est, la haute disponibilité et la résilience intégrées.
Formation des utilisateurs
Les bénéfices d'un changement d'outil ne seront perçus que si les utilisateurs finaux parviennent à effectuer sans peine la transition.
Le premier objectif consiste à limiter toute perte de productivité des utilisateurs finaux liée à cette transition. Il s'agit de les élever au niveau de compétence requis pour qu’ils puissent effectuer leur travail plus rapidement et précisément qu’avec les anciens logiciels et méthodes.
Il s'agit ensuite d'évaluer le niveau de compétences techniques de ceux qui utilisent l’outil au quotidien. Comme plusieurs niveaux de compétences techniques peuvent se retrouver dans un même groupe, il faut proposer différents niveaux de formation. Les novices auront besoin d’éléments progressifs et plus ciblés, tandis que les utilisateurs plus avertis saisiront plus rapidement ces bases pour utiliser des fonctionnalités plus avancées. Dans une formation commune aux deux groupes, les novices seront dépassés et perdus, tandis que les plus expérimentés perdront du temps.
Pour former les utilisateurs, il est indispensable de cerner leurs besoins. La formation sera plus efficace si elle est adaptée à l’utilisation pratique au quotidien.
Nous pouvons prendre pour exemple Kibana et Grafana qui, de base, n’ont aucune visualisation. On en trouve sur la communauté où on peut en créer pour qu'ils collent à nos besoins, d’où le besoin de former les utilisateurs.
Le principe de base est d’être flexible, pour convenir aussi bien à quelques utilisateurs (par exemple, lors de nouvelles embauches) qu’au plus grand nombre (utilisation du nouveau produit par les différentes équipes de l’entreprise).
Conclusion
En conclusion, la centralisation des logs offre de nombreux avantages pour la gestion et la sécurité des systèmes informatiques d'une entreprise. Elle permet de rassembler les informations pertinentes rapidement et facilement, de créer des dashboards personnalisés et de filtrer les données pour comparer le comportement de plusieurs machines.
Les logs centralisés permettent également de détecter plus rapidement les comportements anormaux, les accès non autorisés et les anomalies au niveau des applications et services. En cas d'intrusion réussie, les cybercriminels auront des difficultés à effacer leurs traces, car les logs sont stockés dans un dépôt central. Les administrateurs système et les équipes DevOps peuvent ainsi assurer plus facilement la stabilité et la sécurité de leurs systèmes tout en évaluant en temps réel l'impact des modifications et mises à jour qu'ils déploient.
De plus, les logs peuvent être utilisés pour effectuer des audits de conformité, identifier les goulots d'étranglement dans les processus métier, améliorer les performances des applications et optimiser les ressources informatiques. En comprenant et en exploitant pleinement le potentiel des logs, les entreprises peuvent tirer parti de ces données précieuses pour améliorer leur efficacité opérationnelle, renforcer leur sécurité et prendre des décisions plus éclairées.
La centralisation des logs est une solution incontournable pour minimiser les risques d'erreurs, simplifier les actions complexes de mise en production et garantir la performance et la stabilité de l'infrastructure informatique.

Préparez votre certification PCI-DSS sur AWS
Payment Card Industry Data Security Standard (PCI-DSS) compliance is a requirement for any business that stores, processes, or transmits cardholder...

Comment mettre en place une politique de tagging sur AWS ?
La façon dont nous déployons, gérons et mettons à l'échelle nos ressources informatiques a radicalement changé avec l’adoption du Cloud. AWS (Amazon...