 Clément Loiselet
Clément Loiselet

Passer son application sous Kubernetes permet de simplifier bien des aspects, mais ne garantit pas de l’avoir en haute disponibilité. Entre déploiements successifs, recyclage de nœuds et interruptions aléatoires, l’application peut avoir du mal à répondre aux requêtes à temps !
Dans cet article nous vous expliquerons comment bien définir son application pour qu’elle soit hautement disponible sur un cluster Kubernetes, en passant sur les différentes parties à configurer et les actions à mettre en place sur la durée.
Dans le paysage technologique actuel, Kubernetes est devenu le choix incontournable pour l'orchestration de conteneurs. Son adoption généralisée témoigne de sa capacité à simplifier et à rationaliser le déploiement, la gestion et la mise à l'échelle des applications conteneurisées. L'ascension fulgurante de Kubernetes met aussi en lumière le changement de mentalité qui s'est opéré dans le monde de l'infrastructure, la gestion de serveurs "pet" contre la gestion "cattle".
La gestion d’applications traditionnelle nécessite une attention particulière à chaque serveur, avec des opérations manuelles pour les garder fonctionnels, comme pour un animal de compagnie : c’est la mentalité « pet », où l’on choie nos serveurs.
La mentalité “cattle” consiste à traiter nos ressources sur une plus grande échelle, sans porter une attention particulière à chaque serveur. Cette méthode amène son propre lot de contraintes, en prônant par exemple une durée de vie moins longue des serveurs et un redémarrage plus fréquent des applications.
Ces interruptions plus fréquentes doivent être prises en compte lors d’une migration vers Kubernetes, et demandent de configurer votre application pour qu’elle soit hautement disponible.
Explorons ensemble quels sont les éléments à choisir et configurer pour s’assurer que notre application soit toujours disponible et qu’elle réponde dans des délais acceptables aux requêtes de nos clients à travers un exemple.
Considérons notre application “haute disponibilité” si elle est capable de répondre à plus de 99% des requêtes en moins d’une seconde, et celà 24h/24, 7j/7.
Choisir le type de notre application
Sur Kubernetes, une application web peut être déployée de deux manières :
- Avec un Deployment = idéal pour les applications "stateless" qui n'ont pas besoin de garder leur état en local pour fonctionner, comme par exemple une simple page d'accueil
- ou avec un StatefulSet, pour les applications qui stockent des données localement, comme par exemple un compteur de visites.
Il est plus simple de passer une application “stateless” en haute disponibilité qu’une application “stateful”, car l’application stateful devra gérer des paramètres supplémentaires pour qu’une mise à l’échelle fonctionne, comme par exemple synchroniser l’état entre différentes instances ou s’assurer qu’un client n’accède qu’à une seule et même instance. La cohérence des données d’une application stateful est un point important à conserver, sans quoi deux mêmes requêtes d’un client pourraient renvoyer un résultat différent.
Aujourd’hui, une application web standard ne devrait pas garder son état localement. Les modèles d’applications les plus utilisés préconisent de séparer la partie donnée de la partie “compute” / “code”, en utilisant une architecture 2-tiers / 3-tiers / N-tiers. Ce type d’architecture va découper les fonctionnalités de l’application et les isoler pour permettre de simplifier leur maintenance; chacune de ses fonctionnalités devra être déployée en haute disponibilité.
L’application que nous allons déployer est une simple page statique “hello world”, qui n’a pas besoin de stocker d’état. Nous utiliserons l’image “nginx” dans nos exemples.
Nous allons donc utiliser un Deployment pour notre application.
Un Deployment permet de configurer plusieurs éléments :
- un template d’un pod, l’élément qui va faire tourner une instance de votre application
- le nombre de pods que vous souhaitez avoir en parallèle
- la stratégie de déploiement : comment un nouveau déploiement doit s’effectuer (tout remplacer, ou remplacer les anciens pods petit à petit).
De plus, le Deployment va vérifier en continu que le nombre de pods spécifié soit respecté : si un pod est supprimé, le Deployment va s’empresser de le remplacer.
Choisir le placement de l’application
Pour avoir un déploiement “haute disponibilité”, il nous faut au moins deux instances de l’application pour permettre d’éventuelles interruptions sur l’une d’entre elles.
Il faut aussi s’assurer que ses pods ne se trouvent pas sur le même nœud, voir si possible dans la même zone géographique. En effet, si un problème survient sur le nœud (ou sur la zone), alors toutes les instances de l’application seraient affectées d’un seul coup.
Il existe deux méthodes pour spécifier où les pods peuvent être placés en fonction de l’application :
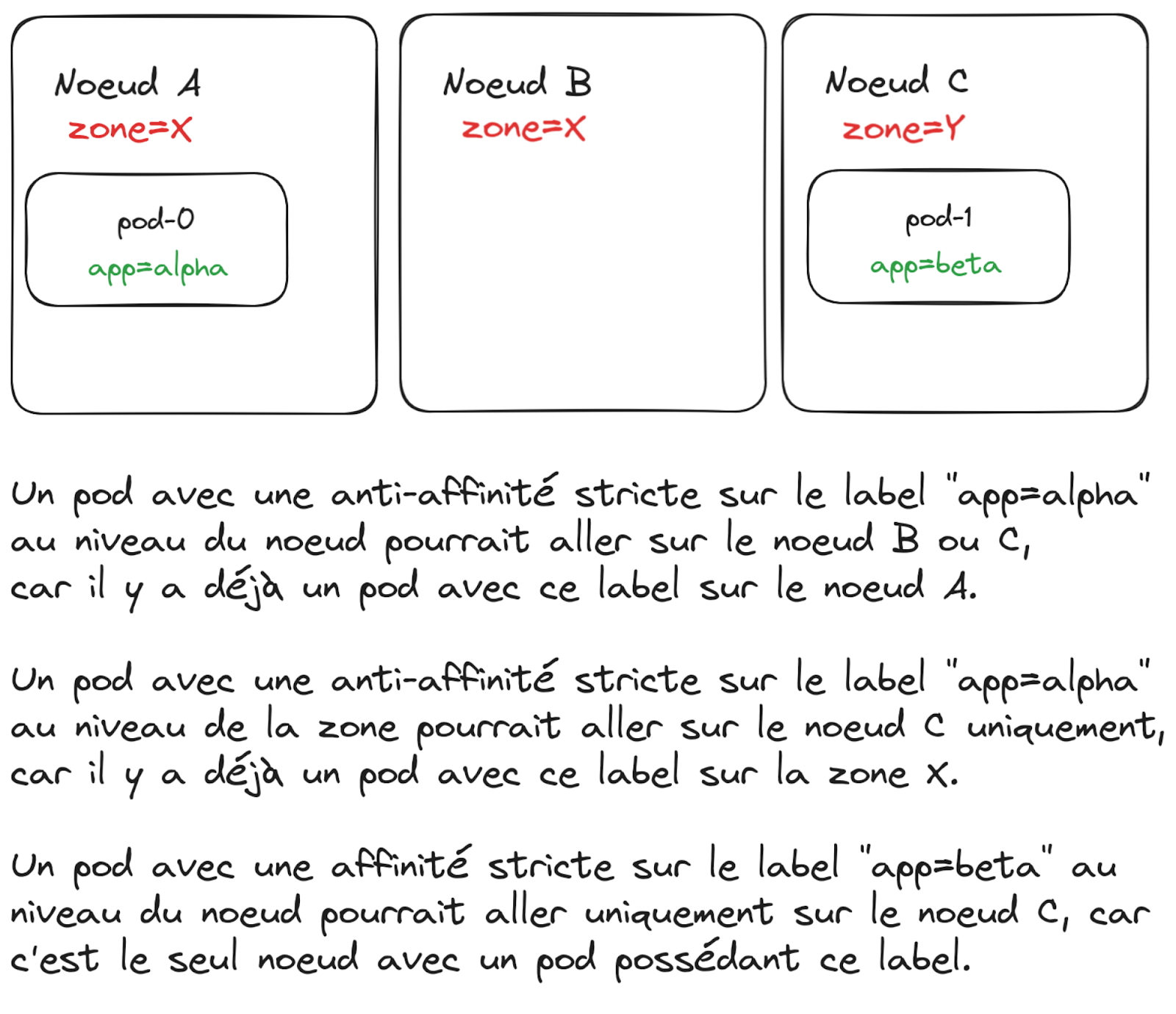
- PodAffinity et PodAntiAffinity : Cette méthode permet d’indiquer à Kubernetes que notre application souhaite avoir ses pods proches ou isolés des pods d’une autre application.
Par “proche”, on entend en fonction d’un label mis sur le nœud : la proximité peut être en fonction de la zone, ou du serveur physique.
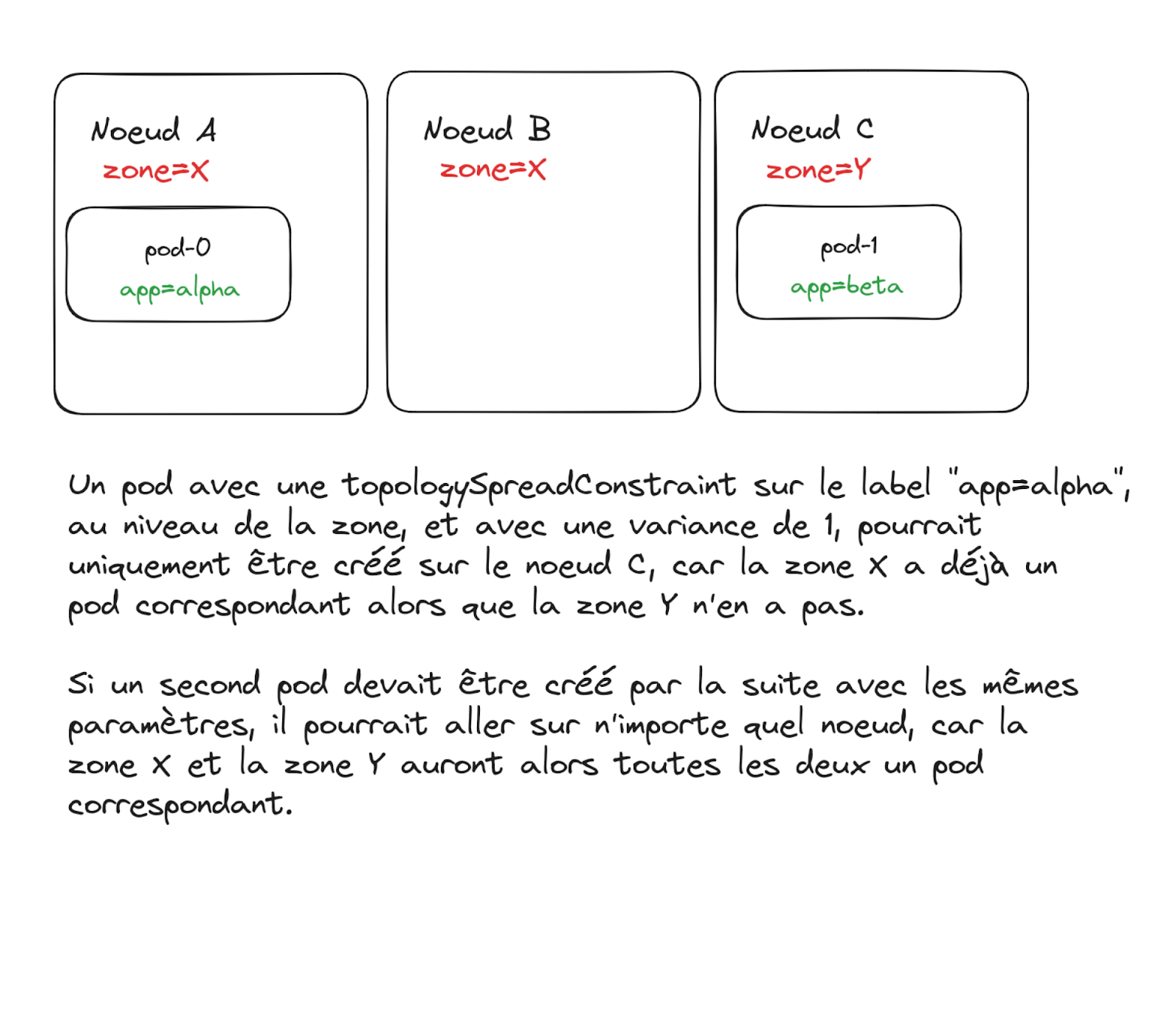
- TopologySpreadConstraint : Cette méthode plus récente permet de définir comment l’application devrait être répartie en fonction du nœud / de la zone. La répartition doit être équitable en fonction du paramètre de sélection choisi, avec une variance maximale tolérée : par exemple, si le sélecteur est la zone et si la variance maximale est de 1, chaque zone aura un nombre similaire de pods, et un nouveau pod sera toujours mis sur la zone avec le moins de pods de l’application.
Pour réaliser ce que nous souhaitons, nous allons devoir utiliser à la fois un PodAntiAffinity et un TopologySpreadConstraint, afin de donner les instructions suivantes :
- un pod de l’application par noeud au maximum : PodAntiAffinity
- un pod de l’application sur chaque zone : TopologySpreadConstraint
Notez que limiter un seul pod par nœud fonctionnera mieux sur les clusters qui ont une taille conséquente, avec au moins plus de nœuds que d’instances de l’application.
Voici un exemple de l’implémentation à réaliser sur notre déploiement :
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
# deux instances minimum
replicas: 2
template:
metadata:
labels:
app: example
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# cette partie s'assure que deux pods de la même application
# ne puisse pas être mis sur le même noeud.
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- example
topologyKey: "kubernetes.io/hostname"
topologySpreadConstraints:
# cette partie s'assure que les zones aient un nombre égal de pod,
# avec une variance de 1.
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: example
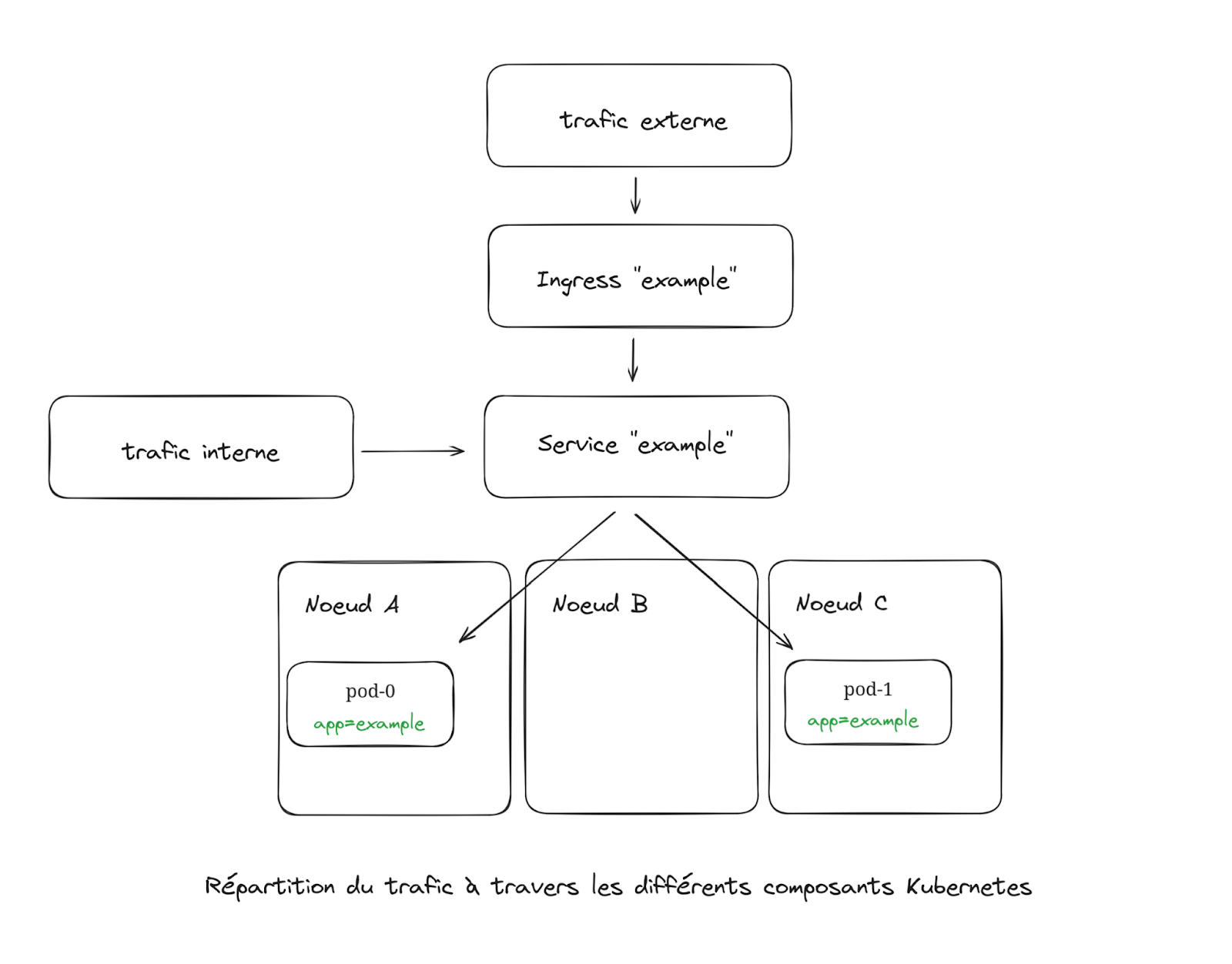
Par ailleurs, pour pouvoir faire des appels sur les instances de ce déploiement, il va falloir créer un Service. Pour notre application, nous allons choisir un service de type “ClusterIP”, interne au cluster Kubernetes.
Ce service va répartir équitablement le trafic sur les instances de notre application. Les instances qui sont considérées comme non-fonctionnelles par une ReadinessProbe ne recevront pas de trafic par le service.
apiVersion: v1
kind: Service
metadata:
name: example
spec:
type: ClusterIP
ports:
- port: 80
selector:
app: example
Notre application est maintenant disponible depuis l’intérieur du cluster. Il existe plusieurs méthodes pour la rendre disponible depuis l’extérieur du cluster, qui vont dépendre de la configuration de votre cluster et de votre réseau.
Le standard aujourd’hui semble se diriger vers l’objet Ingress, nous allons donc définir cet objet pour qu’il utilise le Service ci-dessus pour accéder à notre application.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: example.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: example
port:
number: 80
À ce stade, notre application est déployée avec plusieurs instances, qui seront déployées sur plusieurs hôtes et différentes zones. Nous sommes donc protégés des interruptions dues à un problème critique de l’hôte ou de la zone, notre application devrait toujours répondre à des appels 24h/24, 7j/7. Notre application est accessible depuis le cluster Kubernetes et depuis l’extérieur du cluster.
Regardons maintenant comment configurer notre application pour qu’elle puisse toujours répondre dans des temps acceptables aux requêtes des clients.
Définir les ressources d’une instance
Tout d’abord, il va falloir s’assurer que notre application dispose de ressources suffisantes pour bien fonctionner : nous allons donc inscrire dans notre déploiement les requêtes en CPU et en mémoire dont notre application a besoin.
De plus, nous allons limiter la quantité de mémoire que l’application a le droit d’utiliser, ce afin de protéger les autres applications sur le nœud s’il y a une fuite de mémoire sur notre application.
containers:
- name: example-container
resources:
# Notre application a accès à au moins
# 1 cpu et 1 GiB de mémoire
requests:
cpu: 1
memory: 1Gi
# Nous imposons une limite à notre application
# pour protéger le noeud et les autres applications
# qui tournent sur ce nœud.
limits:
memory: 2Gi
# Le container doit redémarrer s'il s'arrête,
# quelle que soit la raison.
restartPolicy: Always
Avec ces paramètres, Kubernetes va maintenant s’assurer de placer ces pods sur des nœuds capables d’offrir ces ressources. Nous recommandons d’effectuer le paramétrage tel que votre usage réel correspond à 80% de ce que vous avez demandé dans les requêtes, pour garder un peu de marge.
Monitorer le cycle de vie de chaque instance
Maintenant, intéressons-nous au cycle de vie du pod. Le pod va démarrer, lancer le processus principal, et le garder actif jusqu’à ce qu’il s’arrête ou que le pod doive l’arrêter. Kubernetes va, par défaut, envoyer du trafic à ce pod dès que le pod aura démarré, alors que le service web peut prendre jusqu’à plusieurs minutes à démarrer en fonction de votre application.
Il va donc falloir indiquer à Kubernetes lorsque le pod est prêt à recevoir du trafic. Nous faisons cela avec les Probes :
- StartupProbe: effectue un test régulier, lors du démarrage du pod, pour savoir lorsque le service aura démarré et redémarre le pod si elle arrive en timeout.
- LivenessProbe: une fois que la startupProbe a fini, vérifie que le service fonctionne correctement; si ses tests sont en échec, elle redémarre le pod.
- ReadinessProbe : Une fois que le Pod est démarré, vérifie que le service fonctionne correctement; si ses tests sont en échec, elle empêche Kubernetes d’envoyer du trafic à ce pod en le retirant des endpoints autorisés pour les services.
Nous pouvons utiliser les trois probes avec le même test, “vérifie que l’appel /healthz fonctionne”, pour obtenir les résultats que nous souhaitons :
containers:
- name: example-container
image: nginx
ports:
- name: http
containerPort: 80
# Ce test tournera depuis le démarrage du container
# jusqu'à ce qu'il réussisse.
startupProbe:
httpGet:
path: /healthz
port: 80
failureThreshold: 30
periodSeconds: 10
# Ce test redémarrera le container en cas d'erreur
livenessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 5
# Ce test arrêtera de servir du trafic au container en cas d'erreur
readinessProbe:
httpGet:
path: /healthz
port: 80
periodSeconds: 5
failureThreshold: 2
Notre application est maintenant capable de savoir lorsque l’une des ses instances a des problèmes, peut réguler le trafic vers cette instance et la redémarrer si elle ne se remet pas en marche dans des bons délais.
Maintenant, il faut s’assurer que notre application fonctionne correctement même si elle subit un pic de trafic.
Mettre à l’échelle automatiquement son application
Nous pouvons faire cela avec un HorizontalPodAutoscaler, qui va comparer l’usage réel de CPU / mémoire avec les requêtes que nous avons donné à nos instances et augmenter ou réduire le nombre de réplicas dans le déploiement en fonction des résultats.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment
# au moins 2 instances
minReplicas: 2
# au maximum 10 instances
maxReplicas: 10
# ajuste le nombre d'instances en fonction
# de l'usage CPU; nous ciblons un usage
# de 80 %.
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
Nous choisissons ici d’avoir 2 instances au minimum et 10 au maximum. Il faut prendre en compte la capacité de votre cluster avec ce provisioning dynamique des pods. Dans un contexte cloud, vous pouvez aussi faire du provisioning dynamique de nœud, ce qui nous permet de mettre de l’autoscaling sur les nœuds.
Par exemple, nous pouvons utiliser Karpenter pour garantir que nous avons suffisamment de nœuds pour nos pods. Cet outil vous permet de définir un ou plusieurs types de nœuds à ajouter dynamiquement à votre cluster en fonction de la demande. De plus, il est capable de supprimer des nœuds lorsque le cluster n’en a plus besoin, ce qui permet de réduire les coûts. Cette suppression de nœud peut survenir alors qu’il y a des pods de notre application sur le nœud à retirer, c’est pourquoi il est important d’avoir notre application en haute disponibilité.
> Attention, une mauvaise configuration d’un autoscaler sur les nœuds peut vous coûter cher ! Pensez à toujours mettre en place une limite du nombre de nœuds à créer, et à monitorer le coût total du cluster.
Nous avons donc maintenant une application déployée sur plusieurs nœuds et plusieurs zones, qui a suffisamment de ressources et qui est capable de ne pas servir du trafic à des instances KO. Nous avons donc géré la totalité des interruptions non volontaires du service, il faut maintenant regarder du côté des interruptions volontaires 🙂.
Gestion des interruptions volontaires
Il y a deux types d’interruptions volontaires: celles générées lors d’un déploiement, et celles générées par des applications systèmes. D’un point de vue applicatif, elles sont identiques : le serveur web reçoit un signal (SIGTERM) lui indiquant qu’il doit s’arrêter, et sera forcé de le faire au bout d’un certain temps (SIGKILL).
Notre travail ici est de vérifier que ces interruptions ne soient pas envoyées à toutes les instances de notre application en même temps.
Pour protéger notre application lors d’un déploiement, il faut que notre Deployment applique la stratégie “RollingUpdate” pour mettre à jour l’application. Cette méthode remplace les instances les unes après les autres, en s’assurant que la nouvelle instance déployée est prête à recevoir du trafic avant d’en supprimer une ancienne. C’est la stratégie de déploiement par défaut du Deployment, mais nous pouvons aussi le rendre explicite dans notre manifeste :
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
# la stratégie de mise à jour RollingUpdate s'assure qu'on
# ait toujours des instances disponibles lors de la mise à jour.
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
Pour protéger notre application des interruptions venant des applications systèmes, nous allons devoir créer un PodDisruptionBudget, qui va définir le nombre de pods que notre application peut se permettre d’interrompre ou le nombre minimum de pods non interrompu.
Vous pouvez atteindre cet objectif de deux manières :
- Soit en utilisant le paramètre “minAvailable” pour indiquer le nombre minimal de pods qui doivent être prêts à tout moment.
- Soit en utilisant le paramètre “maxUnavailable” pour spécifier le nombre maximum de pods que l’application peut se permettre de perdre.
Pour notre application, nous allons autoriser uniquement 1 pod à être interrompu à la fois.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: example-pdb
spec:
# un seul pod devrait être interrompu à la fois
maxUnavailable: 1
selector:
matchLabels:
app: example
À noter que le PodDisruptionBudget va empêcher l’interruption volontaire de vos pods en “best effort”; certaines applications peuvent ne pas respecter ce budget, ou être forcées de le contourner.
Notre application est maintenant déployée sur plusieurs nœuds et plusieurs zones. Elle n'aura pas de problèmes de ressources, et sera capable de divertir le trafic des instances qui ont des problèmes. De plus, les interruptions d'instances sont maîtrisées et n'impactent pas la disponibilité de l’application.
Superviser le tout
Notre application devrait donc maintenant être considérée comme étant “haute disponibilité”, mais il faut s’en assurer et pour cela, ajouter de la supervision.
Cette supervision devrait se faire sur plusieurs niveaux, et idéalement devrait aussi avoir un composant capable d’alerter les équipes si des valeurs limites sont atteintes.
Dans Kubernetes, il faut monitorer ces métriques :
- usage CPU + throttling du pod
- usage mémoire du pod
- nombre de redémarrages des pods
- nombre de pods déployés
- temps de réponse au 99ème percentile de l’application
Elles nous permettront en tant qu’administrateur du cluster de voir que l’application fonctionne correctement, et surtout avoir rapidement des alertes lorsque l’application rencontre des problèmes.
Pour implémenter cette supervision, le combo Prometheus + Grafana est aujourd’hui le plus courant dans le monde Kubernetes.
Les métriques spécifiées ci-dessus sont des métriques facilement obtenables en tant qu’administrateur Kubernetes, sans modifier l’application. Si vous pouvez modifier l’application, ajouter des métriques issues directement du code vous permettra de savoir au plus vite comment fonctionne votre application, et quels points pourraient avoir des problèmes. Le framework OpenTelemetry vous permettra de sortir rapidement des métriques de votre application, d’une manière compatible avec la plupart des outils de collectes.
Il faut aussi vérifier que l’application soit accessible depuis notre cible, les métriques précédentes provenant uniquement de l’intérieur du cluster. Il existe divers outils permettant de faire des tests réguliers pour voir si l’application répond à une URL donnée, comme par exemple UptimeRobot ou Uptime Kuma.
Ce type de test nous permet de vérifier que tous les composants entre internet et notre application fonctionnent : si par exemple une règle du firewall était changée, seul un test d’accès externe au cluster pourrait détecter le problème.
Un monitoring régulier est nécessaire pour s’assurer que votre application fonctionne. Il vous faudra aussi régulièrement adapter la configuration de votre application pour prendre en compte les évolutions de code et de trafic qu’elle aura au cours de sa vie.
Conclusion
Modifier son application pour qu’elle soit hautement disponible demande de configurer plusieurs éléments pour couvrir tous les cas possibles d’interruptions. Kubernetes nous permet de le faire relativement simplement, tant que l’on connaît toutes les causes possibles de problèmes que l’on peut rencontrer.
Passer une application en haute disponibilité va augmenter son coût en raison du nombre d’instances supplémentaires, et peut aussi se traduire par des temps de déploiements plus longs = c’est un échange nécessaire sur les environnements de production, mais qui peut ne pas être voulu sur les environnements de développement.
Pour finir, voici le code complet pour avoir une stack Nginx en haute disponibilité, qui inclut tous les éléments discutés dans cet article :
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
# deux instances minimum
# si l'on utilise un HorizontalPodAutoscaler, il faut retirer la mention explicite dans ce manifeste pour
# laisser à l'HPA le soin de le gérer.
# replicas: 2
# la stratégie de mise à jour RollingUpdate s'assure qu'on
# ait toujours des instances disponibles lors de la mise à jour.
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# cette partie s'assure que deux pods de la même application
# ne puisse pas être mis sur le même noeud.
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- example
topologyKey: "kubernetes.io/hostname"
topologySpreadConstraints:
# cette partie s'assure que les zones aient un nombre égal de pod,
# avec une variance de 1.
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: example
containers:
- name: example-container
image: nginx
ports:
- name: http
containerPort: 80
resources:
requests:
cpu: 1
memory: 1Gi
limits:
memory: 2Gi
# Ce test tournera depuis le démarrage du container
# jusqu'à ce qu'il réussisse.
startupProbe:
httpGet:
path: /healthz
port: 80
failureThreshold: 30
periodSeconds: 10
# Ce test redémarrera le container en cas d'erreur
livenessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 5
# Ce test arrêtera de servir du trafic au container en cas d'erreur
readinessProbe:
httpGet:
path: /healthz
port: 80
periodSeconds: 5
failureThreshold: 2
---
apiVersion: v1
kind: Service
metadata:
name: example
spec:
type: ClusterIP
ports:
- port: 80
selector:
app: example
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: example.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: example
port:
number: 80
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment
# au moins 2 instances
minReplicas: 2
# au maximum 10 instances
maxReplicas: 10
# ajuste le nombre d'instances en fonction
# de l'usage CPU; nous ciblons un usage
# de 80 %.
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: example-pdb
spec:
# un seul pod devrait être interrompu à la fois
maxUnavailable: 1
selector:
matchLabels:
app: example

Installer Jenkins sur votre instance AWS en 3 étapes clés
Jenkins est l'un des outils de CI/CD (Intégration et déploiement continu) les plus populaires et les plus utilisés dans l'industrie. Il permet aux...
