 Ismael HOMMANI
Ismael HOMMANI




Revue de presse de Septembre 2019
Service Mesh Maesh : La guerre des services Mesh dans Kubernetes continue toujours, et cette fois c’est l’annonce de Maesh. Il s’agit d’un nouveau...

La data, c'est la clé du succès. C’est en ces termes que la plupart des entreprises comprendront la valeur de la donnée produite par leur métier. L’arrivée du Cloud et sa consommation effrénée n’ont fait que confirmer la prépondérance de la donnée dans la stratégie d’une entreprise. Dans le milieu, nous parlons de devenir “data driven”, c'est-à-dire tirer de la donnée la compréhension des succès et des échecs d’une stratégie business et par conséquent les étapes futures à entreprendre.
Les approches classiques échouent cependant à trouver la juste mesure à l’exploitabilité de cette donnée. Elles articulent la donnée autour de concepts techniques, en oubliant par là leur vocation à être exploités et fédérés autour de problématiques métiers. La démocratisation du Big Data, portée par les offres managées des fournisseurs Cloud, n’a fait qu’accentuer cette observation.
En 2019, Zhamak Dehghani fait date en formulant le concept de Data Mesh avec le but de repenser notre approche de la gestion de la donnée. Le succès quasi immédiat ne doit pas cacher le fait que le terme de Data Mesh est aussi devenu un buzzword.
Bien que complet, son manifeste n’en reste pas moins difficile d’accès, voire élitiste. De là découlent des malentendus et des incompréhensions autour de la nature réelle du Data Mesh qui se source dans le concept de Software Design bien connu qu’est le Domain Driven Design (DDD dans la suite de cet article).
L’auteure ne se cache nullement de l’inspiration, mais fait l’économie de l’introduire.
Dans cet article, nous souhaitons revenir sur cet élément fondamental à la compréhension du Data Mesh et observer que certains concepts du DDD se retrouvent naturellement dans le Data Mesh.
Avant de parler de DDD, il convient de rappeler les limitations des approches communes relatives à l'exploitation de la donnée avant la formulation du Data Mesh.
Il est commun de séparer la donnée en deux catégories :
La donnée opérationnelle, optimisée pour du transactionnel et du temps réel, modélise un métier : les relations entre entités, leur contenu, leur cycle de vie…
C’est la donnée que nous produisons à l’usage d’une application.
La donnée analytique, elle, a vocation à donner une vue sur les performances d’un business et fournir des pistes pour son amélioration. À destination des business analysts et autres data scientists, son modèle est moins granulaire que la donnée opérationnelle et la transactionnalité n’y est pas une priorité. On parlera assez souvent de schéma en étoile ou flocon, mais il n’est pas nécessaire d’aller plus loin dans le cadre de cet article.
La donnée opérationnelle se concentre sur l’entité business…
…là où la donnée analytique cherche à comprendre le business comme un tout.
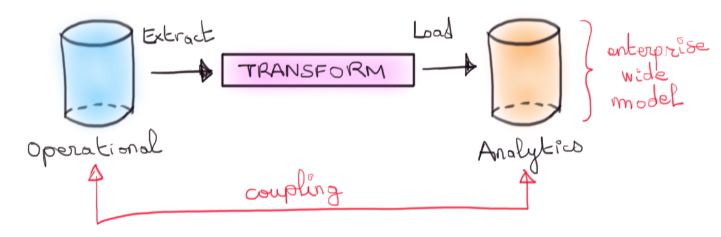
Assez souvent, on observe le passage du paradigme opérationnel vers celui de l’analytique par une multitude de pipelines dits ETLs (Extract Transform Load) qui déversent la donnée opérationnelle dans une plateforme commune : en général, une plateforme spécialisée dans l’analyse de données, i.e un Data Warehouse.
Vue à 40.000 pieds du lien communément admis entre la donnée opérationnelle et analytique.
Dans cette approche, les pipelines d’extraction se sourcent souvent directement au niveau de tables contenant la donnée opérationnelle. En procédant ainsi, un schéma de base de données est implicitement compris comme un contrat d’interface par vos pipelines. Or, ces schémas peuvent changer selon les besoins métiers et l’existence de pipelines s’y sourçant ne saurait être une raison valide d’en retarder la mise à jour. L’approche classique crée donc un couplage fort entre deux mondes à l’agenda différent, l'opérationnel et l’analytique.
Autre inconvénient, le Data Warehouse compris à travers un tenant unique tend à donner un sens global à votre métier dont la potentielle complexité plaide plutôt pour un découpage en sous-domaines plus simple à appréhender.
Essayer de faire tenir un modèle d’une organisation entière dans un Data Warehouse ne contribue pas à sa compréhension.
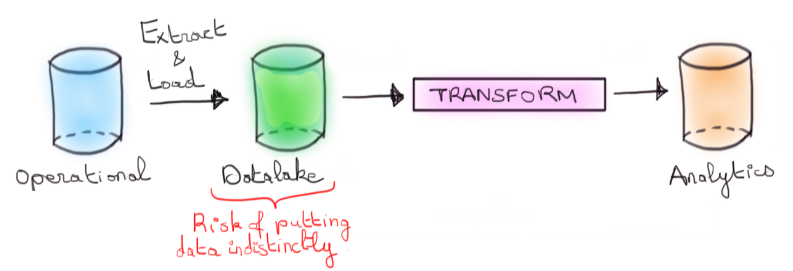
Le Data Lake atténue le couplage précédent en introduisant une sorte de zone tampon au Data Warehouse dans laquelle la donnée brute et non structurée est déversée et sur laquelle l’équipe de Data Engineering a la propriété.
Le Data Lake permet de récupérer une propriété sur la donnée extraite, mais se transforme souvent en data swamp i.e un lake sans structure claire.
L’esprit reste cependant le même. La transformation de la donnée est essentiellement pensée à travers un gros ETL allant de l'opérationnel vers l’analytique.
Cette vision peut passer à l’échelle technique du fait d’une offre pléthorique de fournisseurs Cloud en services managés. Le passage à l’échelle sera plus compliqué d’un point de vue organisationnel.
Le pipeline ETL apparaît comme l’élément atomique de cette organisation. Habituellement, il s’agit d’une équipe spécialisée qui se charge de leur cycle de vie. Leur métier est concentré sur l’aspect technique de l’ETL et moins sur ce qui a trait au métier traité.
Ce cloisonnement de compétence conduit à un goulot d’étranglement, car le traitement des demandes émanant d’équipes de data analysts différentes vont entrer en concurrence.
Plus contraignant, cela conduit à un manque de fédération métier autour de la donnée opérationnelle traitée, chaque métier ayant sa vision. Il est compliqué de tirer un sens de la donnée accumulée dans le Data Lake qui se transforme peu à peu en Data Swamp.
Une illustration de la loi de Conway : le découpage de vos équipes par compétence technique passera difficilement à l’échelle.
Du côté du code applicatif, cette notion de Data Swamp a un nom bien connu : Le Big Ball Of Mud. Écrire du code maintenable, évolutif, testable, scalable, ne se limite pas à des conditions et des boucles. C’est une discipline à part entière appelée le Software Design.
Passez outre et vous vous retrouvez dans une situation où la croissance de votre code s’apparente à des applications de rustines sur rustines pour finir à ne plus rien comprendre à ce qu’il s’y passe. Le Big Ball Of Mud donc.
Parmi les approches à succès de ces dernières années, le DDD tient une bonne place. Une phrase pourrait la résumer :
“Il n’y a aucun intérêt à discuter d’une solution si l’on ne s’est pas mis d’accord sur le problème. Il n’y a aucun intérêt à discuter d’une implémentation si l’on ne s’est pas mis d’accord sur la solution.”
Efrat Goldratt-Ashlag
Ce qu’il y a en substance derrière cette citation, c'est qu’il est nécessaire de se parler entre métiers avant de coder quoi que ce soit.
Le DDD incite à prendre la mesure de ce qu’on l’on cherche à résoudre avec un programme en précédant son implémentation par une phase stratégique.
Plutôt que de raisonner avec des éléments techniques de langages de programmation, il est important de commencer par modéliser son domaine métier à travers un langage commun. Par exemple, définir des acteurs, des entités et des relations entre ces dernières par des verbes.
En général, un langage ne suffira pas pour modéliser un domaine business trop vaste et des ambiguïtés apparaîtront. Le DDD suggère dans ce cas de définir des frontières nommées Bounded Context, chacune avec son propre langage.
Une division supplémentaire de ces contextes en sous-domaines décide d’un point de vue stratégique où mettre les efforts d’implémentation et où plutôt se servir de solutions sur étagère.
Le bounded context est primordial dans le cloisonnement des responsabilités d’une équipe. Son scope est décidé par une équipe pluridisciplinaire.
Vient ensuite une phase tactique où la technique prend le pas en profitant des leçons tirées par la phase stratégique.
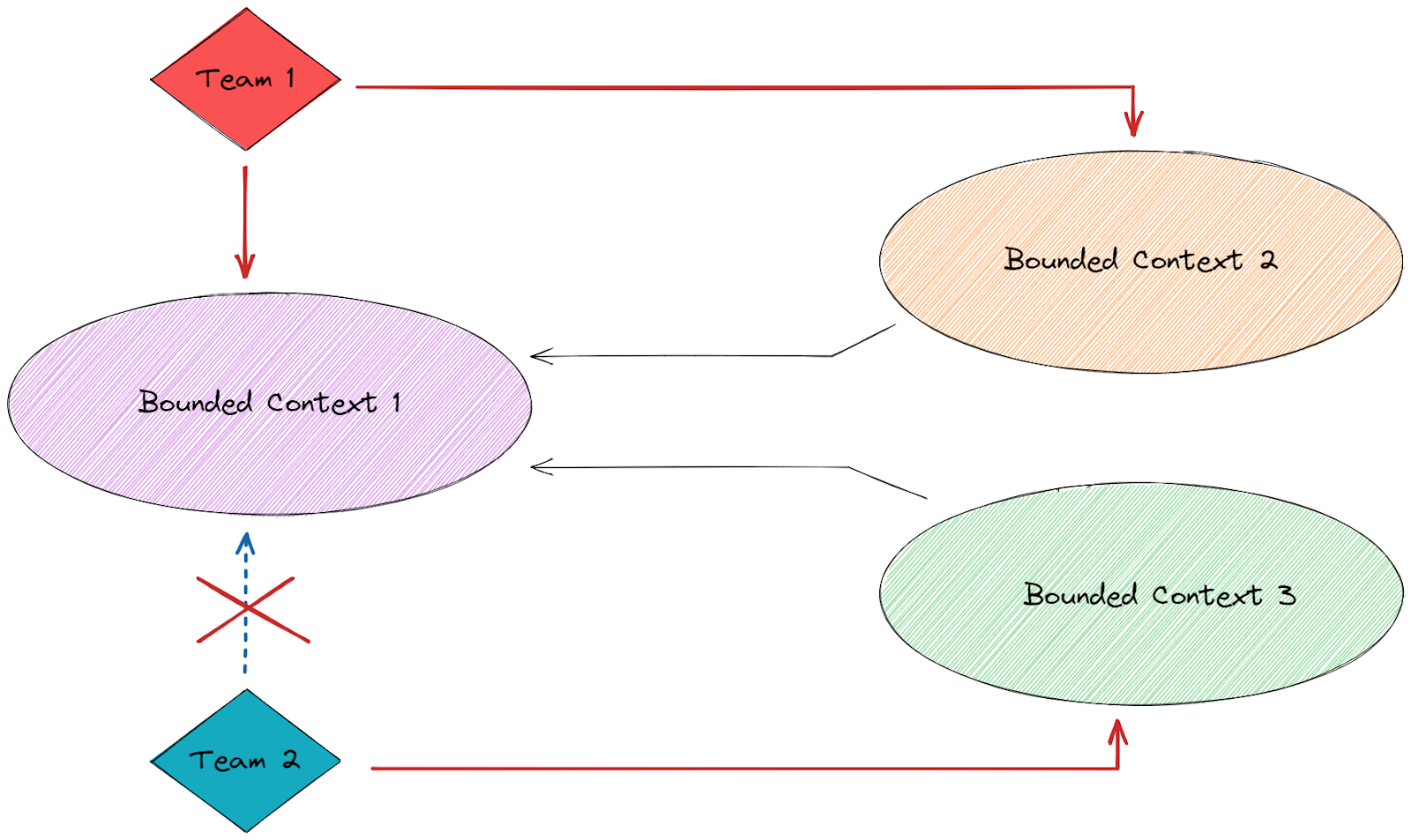
En associant un Bounded Context à une équipe unique, des responsabilités claires émergent.
À noter qu’une équipe peut être en responsabilité de plusieurs Bounded Context mais un Bounded Context ne doit pas être associé à plusieurs équipes pour des raisons d’ownership à respecter.
Cette équipe composée de plusieurs compétences (développeurs, scrum master, spécialistes domaines, data engineer, …) doit utiliser le langage associé au Bounded Context.
Les user stories, le code applicatif, les tests unitaires sont autant d'éléments qui se reposent sur le socle sémantique de ce langage commun.
Les ambiguïtés entre les différents corps de métiers sont ainsi minimisées et la théorie veut qu’un expert métier saisisse l’esprit du code à sa lecture.
Équipes et Bounded Contexts ont une relation one to many.
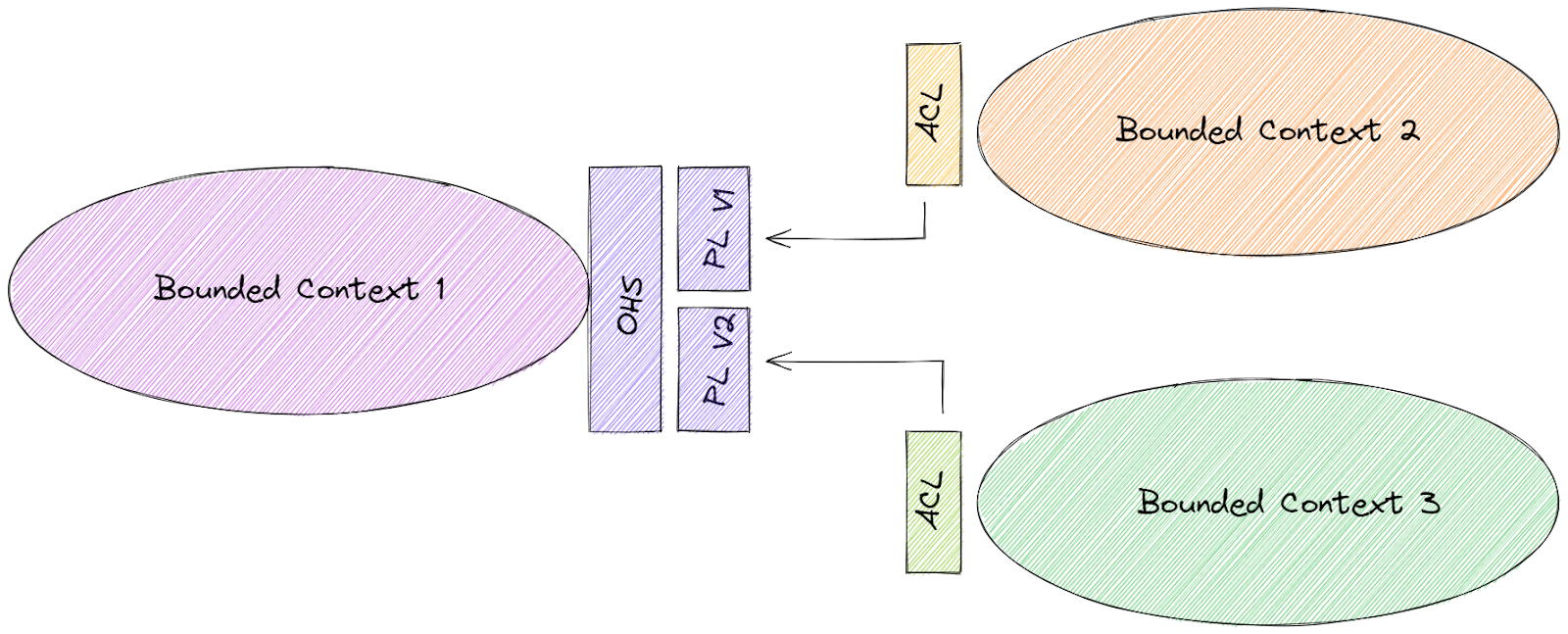
Ces Bounded Contexts sont issus d’un domaine business commun et ne peuvent donc vivre en vase clos. La relation entre contextes peut se ramener à une relation fournisseur / consommateur et des approches permettent d’en isoler le modèle pour respecter un couplage faible.
Avec le pattern de couche d'anticorruption, le consommateur ne se conforme pas au modèle du fournisseur et se protège de notions dont il n’a pas l’usage.
Inversement, le fournisseur, grâce à un service Open-Host, protègera son modèle en publiant un modèle secondaire adapté aux diverses intégrations envisagées.
Ensemble, les Bounded Contexts forment les nœuds d’un graphe que l’on nomme context-map.
Les Bounded Contexts communiquent en respectant des contrats tout en faisant de la programmation défensive via des couches d’Anticorruption.
* OHS : Open-Host Service; **PL : published language; ***ACL : Anticorruption layer
Ces approches sont intéressantes pour garantir l’indépendance de chaque modèle (fournisseur comme consommateur) et par extension de chaque contexte.
Organisationnellement, les équipes deviennent autonomes et peuvent commencer à penser produit à travers des APIs avec leurs propres modèles, SLA et SLO.
Fort de ce rappel de haut niveau sur le DDD, voyons dans quelle mesure la notion de Data Mesh y prend source.
Le Data Mesh peut se voir comme du DDD adapté au contexte analytique.
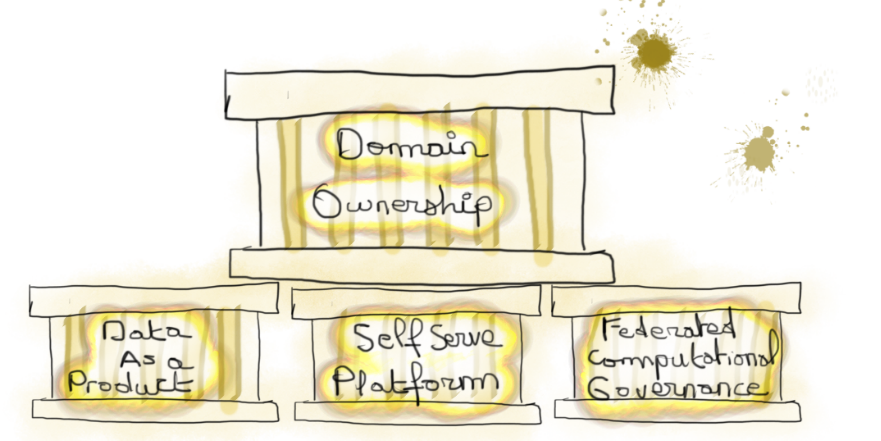
Selon Zhamack, le Data Mesh est porté par les piliers suivants :
Des 4 piliers du Data Mesh, celui de l’articulation de la donnée analytique autour des domaines (domain ownership) est le plus important.
Assez naturellement, on y note des parallèles avec le DDD. Explicitons-les.
Plutôt qu’une approche classique du Data Lake ou Data Warehouse monolithique qui cherche à unifier des métiers dans un modèle unique, on préférera l’idée des Bounded Contexts du DDD.
Autrement dit, plusieurs modèles “data” pour s’adapter à la richesse du métier que l’on considère.
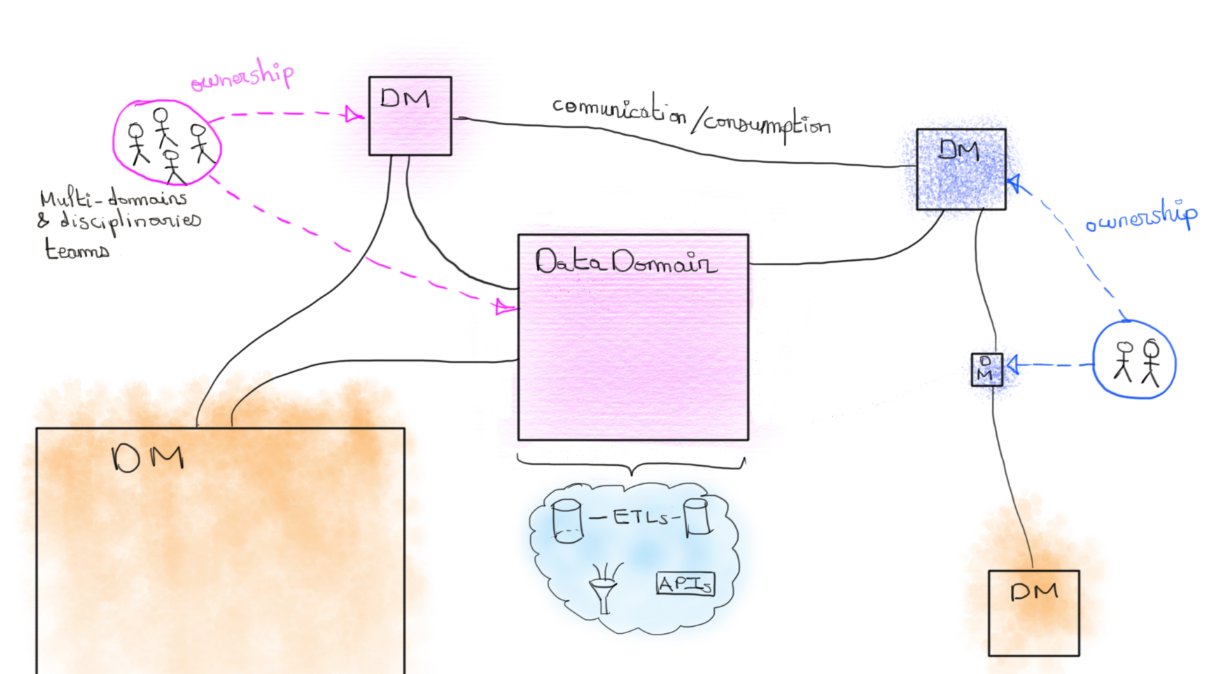
Dans le cadre du Data Mesh, on parle de “Data Domain” qui tombe sous la responsabilité d’une équipe (produit) en charge de sa donnée opérationnelle et de sa transformation en modèle analytique. Ce passage data opérationnel vers analytic peut tout à fait se concevoir comme une implémentation du pattern Open-Host du DDD où un modèle est transformé pour l'adapter à la consommation. Ici, la consommation des business analysts ou data scientists.
Le data domain apparaît comme un concept architectural contenant un certain nombre de schémas, de vues, de triggers, de pipelines, etc, tous associés par un contexte business commun.
Dans un Data Lake monolithique, il est compliqué d’explorer et de comprendre la donnée analytique à disposition. Dans un souci de rendre cette donnée consommable, chaque domaine Data est en responsabilité d’exposer des “ports” de consommation (tout comme les “ports” définis dans une architecture hexagonale), de les documenter et d’en fournir des SLA et SLO.
Le parallèle avec le DDD n’est ici pas évident. On notera cependant un rapprochement intéressant avec ce qu’on l’on a l’habitude de voir dans les bonnes pratiques de gestion des API publiques, voire des micro-services. Preuve supplémentaire, s’il en est, que le Data Mesh ne vient pas de nulle part.
Comme dans le DDD avec les Bounded Contexts chaque domaine data est associé à une unique équipe produit. Cette dernière est en contrôle de son modèle opérationnel et analytique ainsi que du choix des technologies. Elle est décisionnaire de la donnée analytique créée et exposée, le tout dans un souci d’interopérabilité avec les autres domaines.
Pour se conformer à cette règle, certaines équipes vont mettre en place des couches d'anticorruption comme dans un Bounded Context qui souhaite se protéger d’un modèle à consommer non adapté. À l’inverse, l’approche Open-Host permet de s’adapter aux besoins des consommateurs tout en protégeant son modèle.
Ce principe est fondamental dans la compréhension du terme “mesh”.
Chaque nœud du Data mesh est le domaine data autonome qui expose un contrat de consommation (data as a product). Nous retrouvons ce principe avec la “Context Map” décrivant le graphe formé par les Bounded Contexts de notre métier.
Il s’agit de créer des règles de gouvernance pour chaque domaine, garantissant leur interopérabilité et leur “santé”. Bien que le DDD ne porte pas de notion d’écosystème et de règles associées, nous noterons toutefois que l’interopérabilité recherchée entre les Bounded Contexts via les patterns ACLs ou OHS tend vers cela.
La finalité de ces principes est de ne plus considérer le pipeline ETL comme central à la stratégie data, mais plutôt comme un élément anecdotique d’un domaine data qui encapsule la technique au profit de considérations métiers et produits.
Dans le Data Mesh, l’ETL n’est plus qu’un détail d’implémentation et laisse place à des Data Domains qui apparaissent comme des boîtes noires exposant le “nécessaire” à leurs consommateurs selon des règles établies au niveau de la plateforme qui les supporte.
Les promesses du Data Mesh ne viennent pas sans effort. Tout comme l’approche du Domain Driven Design, une étape stratégique de la compréhension de vos domaines métiers est un passage obligé. Aucun outil ne vous fera l’économie de penser ni d'articuler votre métier à travers des concepts tel que le data domain ou data as a product.
En ce sens, il faut arrêter de voir le Data Mesh comme un concept purement technique et ne plus s’illusionner sur telle ou telle technologie se présentant comme la solution de Data Mesh. C’est ce que nous pouvons appeler un concept socio-technique qui repose certes sur une implémentation technique, mais reste en premier lieu guidé par une culture et une compréhension business commune dans les différents corps de métier autour de la data.
C’est à ce prix que l’on peut envisager tirer profit de sa donnée et finalement devenir data-driven.
Pour aller plus loin :

Service Mesh Maesh : La guerre des services Mesh dans Kubernetes continue toujours, et cette fois c’est l’annonce de Maesh. Il s’agit d’un nouveau...

La mesure de la consommation énergétique des applications est un sujet d’actualité, d’une part pour en prendre conscience et d’autre part pour...

Adoptez la démarche Cloud Native ! Téléchargez ICI gratuitement ce nouveau CloudRadar.