Devoxx France 2019
Voici donc un retour partagé et personnel des différentes conférences qui nous ont marqués et que nous espérons que vous pourrez voir prochainement...
.jpg)
Le salon Devoxx 2023 s’est tenu sur trois jours du 12 au 14 avril 2023.
Avec près de 200 sessions autour de sept thématiques et des formats différents proposés, le choix était difficile. Voici une sélection des conférences que nous avons particulièrement appréciées.
Devoxx ne serait pas Devoxx sans ses keynotes. Ces moments qui permettent d'ouvrir nos chakras sur des sujets d'actualité dépassant le simple cadre technologique. Ce Devoxx ne fait pas exception à la règle. Jeudi matin nous alternons entre moral en berne et espoir. En effet Philippe Bihouix nous alerte sur la surconsommation des ressources de la planète et, chiffres à l'appui, nous montre le mur qui se rapproche inexorablement. Il faut agir au plus vite pour changer notre mode de vie et cela passe par revoir notre système économique. La tâche paraît insurmontable. Tandis qu'avec Céline Lazorthes et Sophie Cahen, nous plongeons dans le monde médical avec deux histoires différentes, mais où nous voyons les bienfaits de la technologie lorsqu'elle est utilisée pour améliorer le suivi des patients et la vie des soignants.
Vendredi le ton est donné avec Thomas C. Durand qui nous pousse à être optimistes en développant notre esprit critique, un véritable atout dans notre monde d'aujourd'hui. On enchaîne avec Benjamin Bayart qui secoue la salle afin de lui faire prendre conscience de l'importance des data et de ce qui se passe au niveau juridique européen. Enfin, Marion Poitevin nous partage son histoire où elle a réussi à briser des plafonds de verre ou plutôt de glace dans des contextes trop souvent misogynes...
La première journée était consacrée essentiellement à des Hands-on et des universités.
Justin Reock, CTO chez Gradle, nous rappelle combien le métier de développeur est difficilement compatible avec des métriques de performance. Au-delà d’être compliqué à catégoriser, cela peut même être contre-productif avec des effets pervers qui consisteront à s’adapter aux métriques (ex : nombre de commits) là où elles avaient pour but d’être transparentes pour les équipes observées.
Pourtant, selon Justin, il existe un chemin efficace pour augmenter la vitesse de développement tout en satisfaisant les développeurs avec des méthodes non intrusives. Celui de la discipline du DPE pour Developer Performance Engineering.
Cette jeune discipline, portée en partie par Gradle, se concentre sur des métriques purement techniques liées au SDLC (Software Delivery Life Cycle) en explicitant des métriques objectives sur le temps mis pour un développeur pour avoir du feedback. Le but étant de prendre des actions pour le minimiser.
L’outil de build Gradle mise beaucoup sur ce concept pour mettre en avant ses différentes features qui entrent dans cette logique d’exposer et de partager des KPIs à même de pointer les longueurs anormales dans un temps de build. Grâce à une utilisation agressive du cache en local, l’usage d'algorithmes prédictifs pour lancer les tests, la détection de tests inutiles et d’autres capacité intéressantes, Gradle pousse pour une réelle prise de conscience qu’un temps de build non optimisé est synonyme de perte de productivité substantielle.

par Louis Jocomet et Hervé Boutémy
Louis Jacomet, mainteneur de Gradle et Hervé Boutémy, mainteneur de Maven, nous rappellent les bonnes pratiques de sécurité dans la distribution de nos artefacts. Nous avons tous déjà utilisé Maven Central pour récupérer un bout de code en dépendance.
Toutes ces librairies, nous les utilisons sans mettre en doute leur provenance. Nous sommes aujourd’hui en mesure de nous assurer que ces livrables n’ont pas été compromis grâce à la signature apposée par les contributeurs lors du déploiement sur Maven Central. Hervé et Louis nous proposent de faciliter la signature de ces livrables en intégrant Sigstore.
La promesse de Sigstore est de fournir une sécurité des livrables sans avoir à gérer ses clefs. Les clés existent mais sont générées à la volée par Sigstore qui va identifier le demandeur via OIDC et consigner la session d’identification et d’émission de clés dans un log de transaction public et immuable.
L’intégration de cette solution dans Maven et Gradle ne va pas être simple. Cela nécessite de nombreuses évolutions dans l’infrastructure de Maven Central. Ces évolutions sont en cours actuellement. Si vous souhaitez donner vos besoins en tant que fournisseur de contenu sur le central de Maven, c’est le bon moment !
par Adrien Blind
Adrien Blind nous a fait une présentation et une démonstration des possibilités offertes par Crossplane. Si vous aimez gérer vos ressources applicatives dans Kubernetes et que vous avez des ressources dans un cloud provider, Crossplane est fait pour vous.
Crossplane permet de décrire des ressources managées d’un cloud provider dans une Custom Ressources. Adrien a pu nous faire la démonstration du pilotage de plusieurs ressources Cloud chez différents fournisseurs depuis un même namespace Kubernetes.
Nous avons aussi pu découvrir d’autres fonctionnalités telles que la composition de ressources ou le fait d’avoir des ressources configurées à la demande.
Couplé à un outil GitOps, Crossplane peut devenir un puissant outil de synchronisation des ressources.
Pour en savoir plus, Stéphane Teyssier a d’ailleurs écrit un article à ce sujet sur notre blog : https://blog.wescale.fr/infra-as-code-depuis-kubernetes-avec-crossplane

Philippe Charrière et Pierre-Antoine nous expliquent ce qu’est un pipeline d’intégration continue et de déploiement continue (CICD).
Cette université se veut être très exhaustive et agnostique de l’outil qui sera utilisé.
Les différentes étapes nécessaires pour déployer du code en production et s'assurer qu’il sera testé, robuste, sécurisé et fiable sont présentes.
La chaîne de CICD ne se contente pas uniquement du build, tests unitaires, tests d’intégration et packaging de l’application mais nous pouvons aller beaucoup plus loin : tester les API, tester le comportement de l’application ou de l’infrastructure en faisant des tirs de charge, scanner les failles de sécurité aussi bien sur l’infrastructure que sur le code produit, détecter les versions obsolètes des dépendances etc.
Quant au déploiement, différentes options sont possibles avec un focus sur l’approche GitOps. Flux est maintenant directement intégré à Gitlab
Si vous voulez en savoir plus, vous pouvez lire nos articles de blog ici : Appréhender le GitOps, le déploiement continu façon Kube Native et Flux et ArgoCD, deux visions du GitOps sur Kubernetes.
par Hila Fish
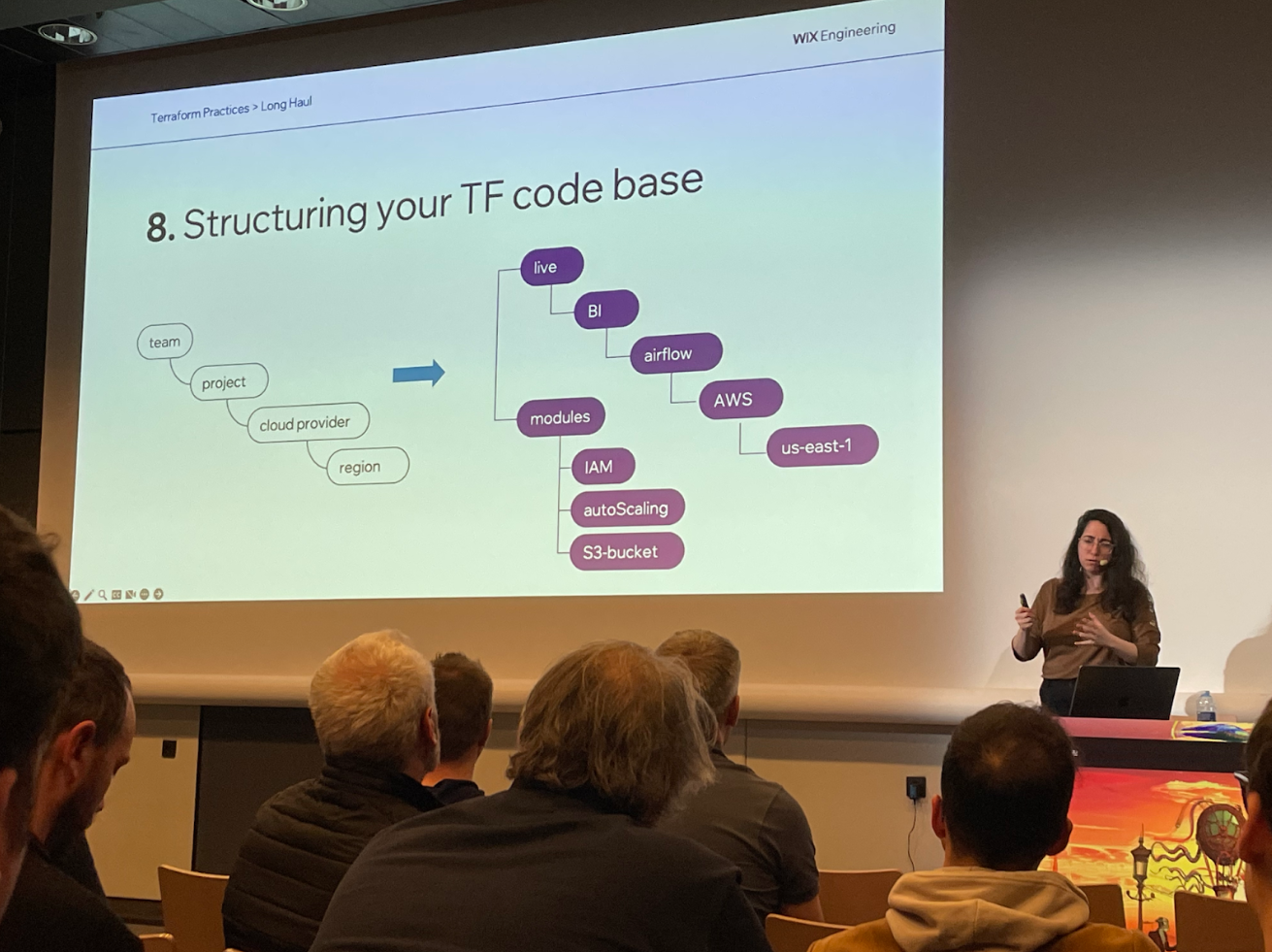
Hila Fish nous présente, dans ce Tool-inAction, les aspects à ne pas négliger dès le démarrage d’un projet sur Terraform sur un format du “Good, Bad, Ugly”. Elle suit un cheminement classique mais condense que l’on rencontre lorsque l’on démarre un projet Terraform et que celui-ci devient de plus en plus gros et atteint une masse critique (un apply qui dure plusieurs minutes).
L’objectif est de permettre de garder un code rapide, maintenable et évolutif tout en conservant les bonnes pratiques de l’usage de Terraform. Elle aborde les sujets de base (versionning, tags, state) puis vient le bloc plus organisationnel (modules, variables, structures/convention, apply) et pour finir les sujets aux limites (workspaces, exec, clean code + sécurité).

Elles présentent aussi des bonnes pratiques autour de la sécurité, de l’optimisation des coûts, la gestion des tags, etc. De nombreux outils existent qui peuvent vous faciliter la vie.
par Jérôme Gauthier

Jérôme Gauthier nous présente très rapidement l’outil OPA (Open Policy Agent) ses avantages et ses limites d’un point de vue de développeur. Ce moteur de règles simple mais puissant est de plus en plus utilisé aussi bien pour des vérifications de règles de conformité, de vérification de règles sur les droits des utilisateurs ou autres. Il est de plus en plus utilisé dans des outils que les développeurs comme les ops utilisent tous les jours.
Tout d’abord, il nous donne ses plus gros points forts (découplage, normalisation avec rego, généricité et expérience de dev). Puis place à la démo, une appli NodeJS + le binaire go OPA et du WebAssembly pour packager tout ça sont le cœur de celle-ci. Ici, OPA est utilisé pour des règles de validations des requêtes de contrôles de conformité sur des routes /POST.
par Aurélie Vache

Aurélie Vache nous partage les principaux problèmes qu’elle a pu rencontrer en Go et une solution ou bonnes pratiques pour éviter de tomber dans les mêmes pièges. La complexité et l’approche est graduelle et couvre même des sujets liés à la CI. Elle couvre les aspects du démarrage (avoir un bon IDE et un bon linter), comment mettre en place des tests unitaires efficacement, de la gestion des erreurs/panic, de la gestion mémoire/socket et surtout le linter de linter.
En tant que noob en Go, le traitement du sujet, qui peut s’avérer complexe et indigeste, est rendu simple et fun grâce à l’énergie d’Aurélie et ses petits Gopher… Voilà maintenant, je n’ai plus d’excuses pour ne pas me mettre à Go.
Jérémie Chassaing nous a proposé un slot de live coding de haut vol, mêlant clavier, le Ukulélé et un synthétiseur. Son besoin est simple, ou devons-nous placer nos doigts sur le Ukulélé en se basant sur une tablature ? Jérémie nous décrit comment à l’aide du domaine bien décrit et d’une programmation fonctionnelle il parvient, en un peu moins de 40 minutes, à proposer une application qui répond à son besoin. Le code obtenu étant très explicite, il parvient à en faire un DSL (Domain Specific Language) compréhensible par tous. Cerise sur le gâteau, Jérémie nous explique le vocabulaire et les règles musicales. Le slot se partage entre un live coding et un live musical qui rend le tout très jovial.
par Jérôme Tama

Jérôme Tama, Tech lead chez Onepoint, nous parle de sa découverte et la mise en place d’OpenTelemetry sur un de ses projets regroupant environ une dizaine de briques (dev et outils associés).
Jérôme nous présente rapidement l’outil et son concept de standardisation des données, de ses conventions (désignation des ressources), de son implémentation possible dans plusieurs langages et du fameux “collecteur magique”.
Puis vient la partie technique, l’approche itérative de la mise en place (collecteur, collecte métrique, refacto et améliorations, logging et traces) et surtout des écueils rencontrés dans la mise en oeuvre pour structurer et rendre cohérentes les logs, les métriques et les traces de son applications dans un seul outil (Grafana).
Sujet super intéressant et les problématiques rencontrées sont vraiment intéressantes. Cela fournit en plus un point d’architecture de gestion de métriques / logs / trace avec point central OpenTelemetry. Maintenant, comme Jérôme l’évoquait dans son talk, j’ai envie d'utiliser l’outil suite à une conférence qui parle de ce sujet.
par Alex Casanova

Alex Casanova démontre dans cette session que la prise de parole en public n’est pas aisé pour tout le monde. Tout d’abord en nous demandant quels peuvent être les freins puis en improvisant l’introduction à son talk avec les différentes réponses proposées.
Ensuite, elle cadre le sujet de sa conférence. En effet, trois types de communication sont possibles à savoir:
Son propos couvre les deux premiers types de communication. Elle nous explique alors quelles sont les différentes peurs qui peuvent nous empêcher de parler aux autres comme par exemple le regard de l’autre, la peur de ne pas réussir etc…
Elle nous a proposé différents exercices comme de la sophrologie, des jeux brises-glaces ou encore des exercices d’improvisation.
par Elea Petton

Elea Petton nous présente un talk intéressant. L’idée est de présenter son retour sur l'utilisation d’une IA pour comprendre la langue des signes (un projet parti d’une volonté de mettre au service l’IA au service de l’inclusion). Eléa présente comment, elle a entraîné son IA, comment elle a trouvé son dataset et l'a fait évoluer pour améliorer son IA tout en limitant voir retirer un maximum les biais et limites introduit dans son dataset de base.
Un talk très complet et surtout très instructif sur la possibilité de mettre en place une petite IA et de son entraînement.
par Clément Delafargue et Geoffroy Couprie
L’authentification et l’autorisation sont de plus en plus problématiques surtout avec nos architectures micro-services. Comment s’assurer que les autorisations puissent être vérifiées dans un service distribué ?
Clément Delafargue et Geoffroy Couprie nous font un panorama complet des solutions pour gérer l’authentification et la gestion des droits dans un système distribué avec un focus particulier sur le projet open source Biscuit.

Ils nous donnent ensuite les différents pattern pour facilement distribuer les autorisations en insistant particulièrement sur la mise en place d’un système de révocation des clés dès le début du déploiement et s’assurer que le système soit robuste en cas de divulgation des secrets.
La mise en place d’un système d’autorisation dans une architecture distribuée est un sujet complexe. Ce panorama présenté est complet mais ils n’ont pas montré les avantages et inconvénients de chacune des solutions proposées avant l’introduction de leur projet Biscuit
La présentation des différents patterns à envisager est une source d’inspiration.
par Mickael Roger

Dans ce talk, Mickael Roger fait un retour d’expérience sur la mise en œuvre de Kubevirt et des problématiques d’implémentation qu’il a rencontrées. Le talk commence par un état de l’art de la virtualisation et conteneurisation puis de la philosophie de Kubevirt dans sa vision de la VM in container. Il aborde d’abord les problématique rencontrée avec le stockage et essentiellement le poids des conteneurs selon le mode de déploiement choisi pour ses dernières OCI vs QEMU Qcow2 (qui une des problématique qui sera lié à votre runtime et sa capacité de virtualiser les process de votre conteneur) que l’on pourrait résumer lenteur de démarrage vs maintien de référentiel/difficultés opérationnelles. Le second point de vue, celui du réseau qui amène énormément de problématiques quand on souhaite conserver les avantages de la VM (IP fixe, DNS, NIC) vs la volatilité des orchestrateurs de conteneurs. Mickael, nous préconise de bien étudier le besoin initial pour choisir la bonne CNI qui couvrira correctement notre besoin (mutlus et kube-ovn semblent tout de même être indispensables).
Tout comme l’apparition de Docker et Kubernetes, nous approchons une nouvelle évolution technologique qui doit nous permettre de faciliter l’approche de la virtualisation des processus conteneurisés ou non et offre des possibilités d’uniformisation de l’environnement.
D’ailleurs, notre collègue Aubin Morand a écrit un article sur le sujet et qui devrait sortir prochainement.
par Michael Tavarres

Michael Tavarres en plus de son activité professionnelle s’est engagé dans une association enseignant l’apprentissage du code aux enfants âgés de 8 à 12 ans. Les enfants apprennent les fondamentaux de la programmation à l’aide du langage Scratch du MIT.
Même si le langage est visuel, tous les concepts sont présents comme les variables, conditionnelles, les boucles etc.
Il nous retrace ses interrogations sur comment enseigner ces concepts abstraits, ses victoires et ses échecs.
C’est une source d’inspiration pour commencer à programmer avec mes enfants. Ses enseignements seront bénéfiques pour les parents comme moi qui veulent aborder ces questions avec leurs enfants. Vivement le replay pour pouvoir partager la vidéo.
José Paumard, membre du Java Platform Group chez Oracle, est venu nous présenter Loom, le projet qui va révolutionner la programmation concurrente dans Java dans les releases prévues cette année.
José nous explique le fonctionnement de la programmation concurrente dans Java depuis sa création. Une tâche est attachée à Thread Platform qui représente le Thread sur le système sous-jacent. Jusqu'à présent, une tâche ne pouvait pas être détachée de son Thread Platform. Le problème, c’est quand la tâche réalise une action bloquante, le Thread Platform va être lui aussi bloqué.
NDLR : Les plus anciens se rappelleront que dans les premières années de Java, sous Linux, les Threads étaient implémentées en mode Green Threads (en soft donc) et plus tard ont été appliquées sur les Threads POSIX. C'est une sorte de retour aux sources
Pour pallier ce problème, des librairies de programmation réactives ont fleuri.
C’est là que le projet Loom, en développement depuis 4 ans entre en scène avec ses JEP 429, JEP 437 et la JEP 444. L’idée derrière Loom est simple; Permettre à une tâche d’être détachée de son Thread Platform lors d’un appel bloquant afin de permettre au Thread Platform d’être utilisé par une autre tâche. Les gains de performances sont énormes lorsque vos tâches appellent du code bloquant. A noter que le code s’en trouve simplifié par rapport au du code réactif en termes de syntaxe.
La révolution est en marche, elle devrait être disponible pour Java 21 qui sortira en Septembre 2023.
par Holly Cummins
Dans un contexte où l’écologie et les enjeux climatiques sont de plus en plus présents, Holly Cummins, Senior Principal Software Engineer chez Redhat nous propose des clés pour que nous, artisans de solution numérique, puissions contribuer à la réduction de notre empreinte.
Dans un premier temps, Holly nous rappelle que notre industrie a une empreinte carbone plus importante que le transport aérien, nous avons donc une marge de progression.
Holly nous propose une réflexion sur les axes suivants:
Holly établit un lien entre l'efficacité et la consommation de nos solutions. Plus une application est efficace, moins elle consomme. De la même manière, plus elle est efficace, moins elle coûte cher en infrastructure.
Il y a donc de nombreux intérêts à utiliser des solutions qui permettent à nos solutions d'être plus efficaces, comme Quarkus pour les langages de la JVM.
Vous pouvez retrouver les slides de sa présentation à l’adresse suivante: https://hollycummins.com/greener-applications-devoxx-france/
Sources :
par Emmanuel Remy

Emmanuel Remy nous présente des fonctionnalités méconnues de cette base de données de plus en plus populaire au fil des ans.
Cette session rendue très dynamique par les démonstrations d’Emmanuel, permet de voir par l’exemple les fonctionnalités suivantes :
Je vous laisse découvrir les autres fonctionnalités lorsque le replay sera disponible mais je vous partage ceux que je vais tester sous peu. Avoir la possibilité d’intégrer des contrôles et des manipulations au plus près des données est non seulement un gain de temps mais également une sécurité supplémentaire.
Merci Emmanuel pour ces découvertes et pour le format de ton slot.
par Steven Le Roux et Pierre Zemb
Cette session de Steven Le Roux et Pierre Zemb de CleverCloud nous présente un moteur de base de données peu connu et pourtant de plus en plus utilisé.
FoundationDB est un des rares projets open source proposé en licence Apache 2.0 par Apple. C’est un moteur de stockage de base de données distribué, clé-valeur et transactionnelle. Par contre, elle ne propose pas de modèle de données autre que le clé-valeur et encore moins un système de requêtage évolué.
Grâce à ses performances, il est aisé de s’en servir en rajoutant des couches supplémentaires pour proposer d’autres types de modèles de données comme du relationnel, des queues ou encore des Time series. De même pour le système de requêtage.
Principalement utilisé par Apple pour sa fonctionnalité iCloud, il est de plus en plus déployé par des acteurs comme eBay, Datadog ou encore CleverCloud.
Les principaux avantages de cette solution pour CleverCloud sont sa robustesse et sa scalabilité, et c’est une brique pour facilement proposer d’autres types de bases de données à leurs clients.
Edito David: Cette présentation est enrichissante car elle nous permet de découvrir une brique peu connue des futures bases de données distribuées.
par Olivier Poncet

Olivier Poncet, développeur d’un émulateur CPC pour Linux nous explique comment développer un émulateur pour pouvoir revivre les sensations de notre enfance (enfin pour ma part).
Le plus dur est de trouver les sources d’information permettant de comprendre les différents composants hardware de la machine à émuler. Ensuite pour chacun des composants de ces machines, il nous explique les différentes stratégies ou implémentations possibles avant de nous faire une démo de son émulateur même si le CPC n’est pas capable de comprendre une question simple que ChatGPT pourrait répondre.
Un bon talk qui sent bon la nostalgie. Olivier nous a vulgarisé l’implémentation d’un émulateur. Il dresse les points positifs sur ce que peut apporter un tel développement sur notre vie en entreprise. Bref, plutôt rafraîchissant.
par Fabien Hiegel et David FRANCK

Qu’est ce que la veille ? Comment la pratiquer ? Quel est son but ? Comment s’organiser pour faire une veille technologique efficace ?
Nous sommes en effet dans un métier où apparaissent constamment de nouvelles librairies, langages, concepts. Fabien Hiegel et David Franck nous expliquent le processus efficace pour faire sa veille technologique.
La première étape pour constituer sa veille est tout d’abord de se fixer des buts. Est-ce pour me tenir au courant des dernières nouveautés, pour me former, ou par curiosité ? Une fois ses buts établis, il faut se constituer un processus de veille efficace.
Ensuite, il faut trouver ses sources d’information: articles de blog, personnes sur twitter que nous suivons, podcasts, chaîne Youtube, etc… Attention à ne pas trop les multiplier, car le risque est énorme d’obtenir une surabondance d’information ce qui sera décourageant pour les traiter et digérer.
Les différents éléments doivent être traités pour les mettre dans une liste blanche ou des listes de lecture. Néanmoins, lors de la lecture ou l’écoute de la source, il faut prendre des notes afin de pouvoir en extraire l’information importante à nos yeux. Cette prise de note permet une meilleure mémorisation des informations lues ou écoutées. Lors de la prise de notes, il ne faut pas hésiter à reformuler avec nos propres mots ce qui facilite la compréhension.
Et dernière étape, la valorisation de ses notes en les organisant non pas sous forme de listing à plat mais en essayant de relier les concepts entre eux, en ajoutant des mots clés pour faciliter les recherches, pour obtenir au final un graphe de connaissance.

Cette base de connaissances permettra de faciliter le partage sous forme d’articles de blog, de présentations à des conférences ou en interne.
L’édition 2023 fut encore de très bonne facture et a offert une grande variété de sessions aussi passionnantes qu’ informatives.
Nous repartons avec de nouvelles idées ou de nouveaux outils à explorer pour apporter une meilleure expertise à nos clients et nous attendons avec impatience l'événement de l'année prochaine.
Voici donc un retour partagé et personnel des différentes conférences qui nous ont marqués et que nous espérons que vous pourrez voir prochainement...
Sortie de Docker CE 17.06 Voici la première version de Docker basée sur le projet Moby ! Parmi les nouveautés les plus attendues de cette version :

Découvrez la revue de presse mensuelle, sur les dernières actualités et technologies cloud, préparée par nos "scalers passionnés".