Benoit Petit
Benoit Petit

Nous verrons dans cet article que le panorama des solutions permettant le cloisonnement réseau a bien changé et permet de répondre aux besoins d’une infrastructure Cloud.
La première partie de cet article mettra en lumière les problématiques actuelles concernant le cloisonnement réseau et son automatisation en datacenter, ainsi que les limitations des anciennes méthodes pour y répondre. La seconde partie traitera des réseaux d’overlay, aujourd’hui couramment adoptés dans ce contexte. Ceux ci se retrouvent dans les fondations de nombreux projets tels que Flannel, Contiv, OpenVSwitch, NSX, Cilium, etc… Nous montrerons également comment configurer des réseaux VXLAN sous Linux, nativement.
Si vous êtes familiers des problématiques réseau et des infrastructures Cloud, je vous suggère de passer directement à la partie 2 “Quelles solutions ?”.
AVERTISSEMENT:
Si vous souhaitez déployer des réseaux d’overlay sur l’infrastructure de votre entreprise, gardez à l’esprit que cette technologie ne permet et ne devrait pas permettre de s’abstraire de travailler en bonne intelligence avec l’équipe réseau. Nous verrons par la suite que leur collaboration reste nécessaire, que ce soit pour des raisons techniques que nous allons évoquer ou tout simplement parce que le réseau est leur métier. Leur savoir-faire sera toujours requis pour mieux comprendre votre solution d’overlay ou bien pour dépanner votre installation (par exemple sur des questions de performances).
Avant
Dans le cas d’une infrastructure virtualisée classique, chaque hyperviseur a accès à un ou plusieurs VLANs de production et permet aux machines virtuelles d’accéder ou non à ces réseaux. Cette méthode a fait ses preuves et a toujours sa place dans de nombreux contextes en entreprise ou chez les opérateurs. Cependant, elle soulève plusieurs problèmes dans le cas d’une infrastructure Cloud.
Faire entrer un carré dans un cercle
Le premier problème est que les équipements réseau sollicités ne sont, la plupart du temps, pas nativement automatisables. Il est, certes, de plus en plus courant de gérer la configuration d’un commutateur ou d’un routeur, avec Ansible par exemple, mais encore faut-il que celà soit supporté par le constructeur. Le nombre de modules Ansible proposés pour piloter ces équipements grandit de jour en jour. Ceci étant dit, plusieurs problèmes subsistent et sont détaillés dans les parties suivantes.
La technique n’est pas le seul problème
Admettons que vous ayez techniquement tout en main pour automatiser vos équipements réseau physiques. Selon la taille et l’organisation de votre entreprise, il y a de fortes chances pour que les personnes responsables de ces équipements et vous, ne soyez pas dans la même équipe. Il est alors souvent compliqué de faire accepter à l’équipe responsable que leurs équipements soient configurés automatiquement, qui plus est à une fréquence élevée, par des outils gérés par une autre équipe que la leur.
Performances et scalabilité
Dans un contexte cloud, le besoin de déploiement de nouveaux réseaux propres à un environnement (ou tenant) est présent en continu. Devoir configurer tout ou partie des équipements, automatiquement, à chaque demande d’allocation d’un nouveau VLAN peut se révéler inconfortable. Selon le volume et la fréquence des demandes, outre le risque de propagation d’erreur, un important goulot d’étranglement peut se créer et ralentir globalement la plateforme.
Rappel : Il s’agit ici de configurer automatiquement des équipements qui ne disposent la plupart du temps que de CPU faibles avec des capacités de traitement limitées. Les performances importantes dont ils font preuve pour le trafic réseau, s’expliquent par la présence d’ASICs (Application-Specific Integrated Circuit) dédiés et indépendants du control plane (le CPU et les logiciels qui en dépendent).
À ces contraintes de performance s’ajoute une problématique liée au protocole lui même : le champ VLAN ID inclus dans l’entête ethernet s’étend sur 12 bits, ce qui permet 4096 possibilités. Il est donc possible d’utiliser 4096 VLANs différents sur un même équipement. Cela peut sembler beaucoup, mais dans un contexte cloud où l’on souhaite que les réseaux puissent être créés à la volée et sans contrainte, c’est bloquant.
Le Cloud n’a pas de frontières, les VLANs oui
Par définition, une infrastructure Cloud vise à fournir des ressources (virtuellement illimitées) géographiquement réparties. AWS, par exemple, propose de répartir les ressources allouées sur différentes régions, comprendre, dans plusieurs pays, sur plusieurs continents (nous pourrions également citer les zones de disponibilité, qui, au sein d’une même région, correspondent à des datacenters distants). Un cloud privé ne sera peut être pas aussi étendu, mais il est très probable qu’il s’étende sur plusieurs salles/datacenters. Permettre à un client de déployer des instances (par exemple) dans plusieurs datacenters, en garantissant la communication entre ces instances est incompatible avec l’utilisation des VLANs.
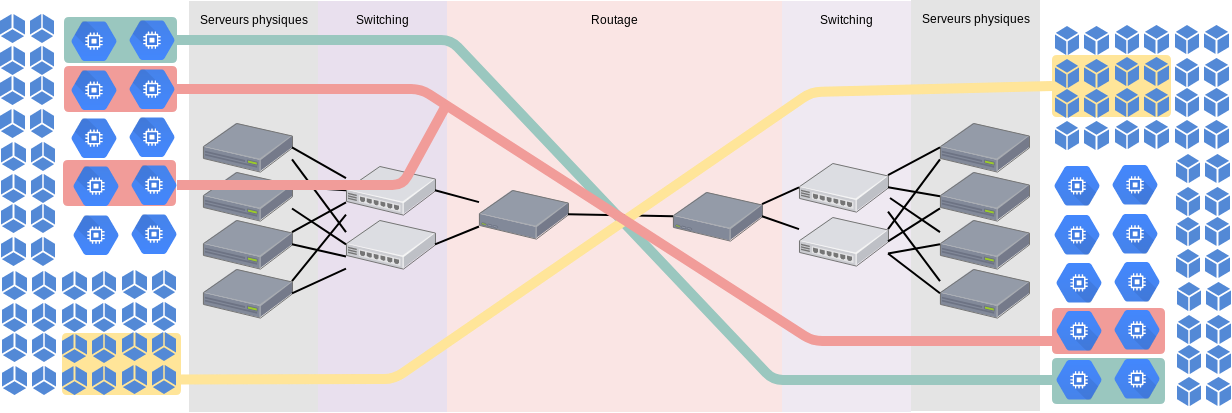
Le schéma est là pour illustrer notre problématique: comment interconnecter les machines virtuelles ou conteneurs de droite et de gauche, au sein de réseaux privés, qui traversent un réseau routé, ou même comprenant des pare-feux ?
Quelles solutions ?
Pour répondre aux problématiques énoncées plus tôt et ainsi proposer une solution réseau cloud-ready, il est nécessaire de disposer d’une technologie capable de :
- faire abstraction de la complexité du réseau existant
- permettre une connectivité directe entre des machines situées sur des datacenters distants, donc séparées par plusieurs couches de routage, voire de pare-feux
- de faciliter le pilotage de ces liens inter machines par un logiciel
La réponse à ces problématiques tient principalement dans un concept : la tunnelisation. De nombreux protocoles réseau existent dans ce domaine, en voici quelques-uns :
- VXLAN (RFC 7348)
- NVGRE (RFC 7637)
- STT (brouillon IETF associé)
- LISP (RFC 6830)
- Geneve (brouillon IETF) : encore au stade de brouillon, ce protocole a pour objectif de combler les lacunes de ses prédecesseurs
Nous allons nous concentrer sur VXLAN car c’est le protocole que l’on retrouve le plus souvent dans les suites logicielles liées aux SDN. Sont dans ce cas, Flannel, Contiv et Cilium pour les produits orientés conteneurs, mais aussi OpenVSwitch (que l’on peut retrouver à la base d’une installation Neutron dans OpenStack ou OVN).
Pour ceux qui resteraient sur leur faim à cause de ce choix, STT est très bien expliqué ici, et Geneve ici.
VXLAN
Comme expliqué plus tôt, VXLAN est très présent dans les technologies réseau liées au Cloud et aux conteneurs. Vous trouverez également sur Internet de nombreux articles qui en vantent les mérites. Voyons comment ce protocole fonctionne.
VXLAN est un protocole de tunnelisation, qui permet d’étendre un réseau de couche 2 au dessus de réseaux routés. On identifie un réseau VXLAN par sa VNI (VXLAN Network Identifier). Celle-ci est codée sur 24 bits, ce qui donne 16777216 possibilités, on est alors bien loin de la limitation de 4096 induite par les VLANs.
Le fonctionnement de VXLAN est simple, il s’agit d’encapsuler une trame ethernet (couche 2 du modèle OSI), dans un datagramme UDP (couche 4). Les éléments chargés de cette encapsulation (et de la désencapsulation) sont appelés VTEP, pour VXLAN Tunnel End Point. Il suffit pour monter un réseau d’overlay VXLAN, que deux VTEP soient en mesure de communiquer en IP et en UDP, sur un numéro de port dédié (le port désigné par l’IANA est 4789, mais selon les implémentations on peut retrouver 8472 comme port par défaut, il est également possible d’en changer).
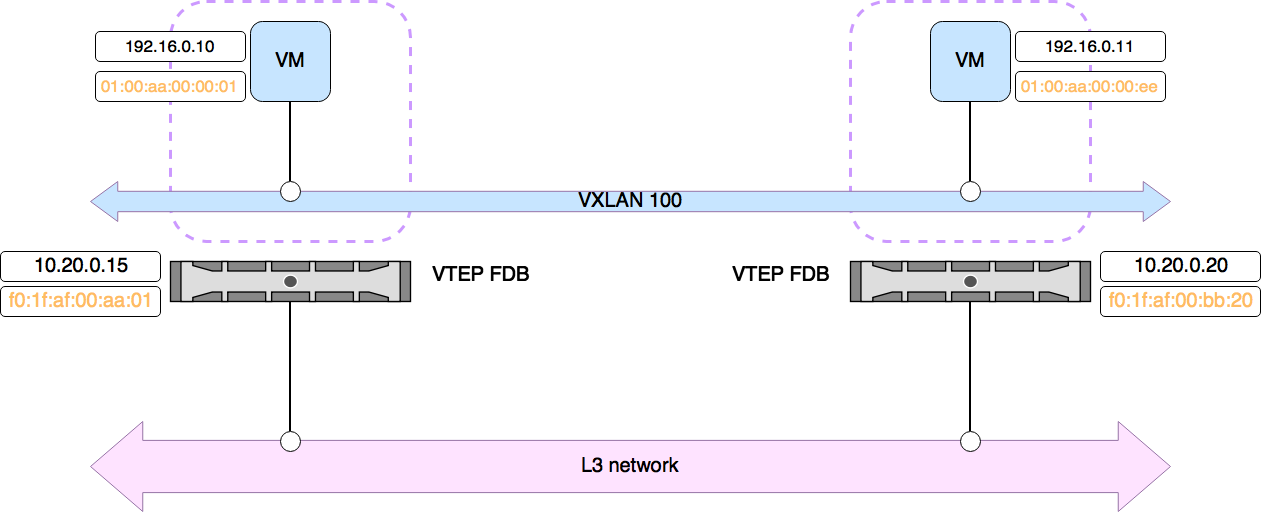
Un VTEP peut être dit matériel, lorsqu’il s’agit d’un équipement réseau physique disposant de cette fonctionnalité, ou logiciel lorsqu’il s’agit d’une implémentation déployée sur un serveur (classiquement un hyperviseur ou un serveur hébergeant des conteneurs).
Pour le détail, voici à quoi ressemble une trame encapsulée par VXLAN :
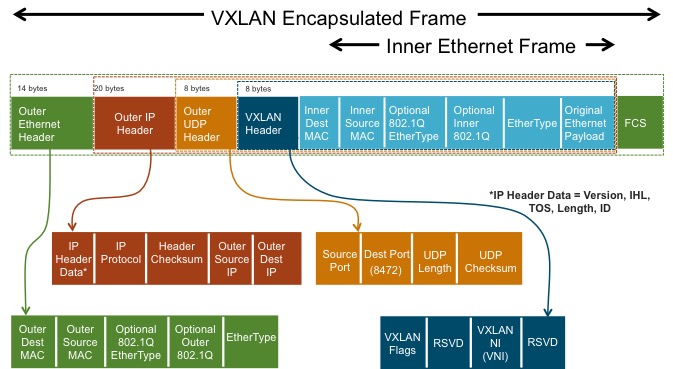
Cette encapsulation induit forcément un overhead, ce qui peut poser des problèmes de MTU (Maximum Transmission Unit) sur votre infrastructure. Il est couramment recommandé de configurer les équipements réseau sous-jacents (le réseau d’underlay) de manière à utiliser une MTU supérieure aux 1500 bytes habituels (VMWare recommande une MTU d’au moins 1600 bytes pour sa solution NSX, certains déploiements se font carrément sur un réseau d’underlay avec une MTU en “jumbo frame”: 9000 bytes). Vous voyez ici de quelle collaboration je voulais parler en introduction.
Certains auront peut-être identifié deux problématiques liées à la nature même de VXLAN. Imaginez un scénario où l’on souhaite déployer un même VXLAN (avec le même VNI) entre plus de deux VTEP (ce qui est plus que courant dans une infrastructure Cloud).
La première question qui se pose est de savoir comment un VTEP apprend l’existence des autres VTEP. La seconde concerne les clients du VTEP. Pour rappel il s’agit de faire fonctionner un réseau de couche 2 au dessus d’un réseau de couche 3. Derrière chaque VTEP sont présents plusieurs équipements, soit d’un point de vue réseau, plusieurs adresses MAC. Comment fait le VTEP A pour savoir si l’adresse MAC 00:00:5E:00:53:01, se trouve derrière le VTEP B ou bien derrière le VTEP C, avant de transmettre une trame à son attention ?
La réponse est simple, il va falloir qu’un mécanisme soit mis en place pour que chaque VTEP apprenne les adresses MACs déployées derrière ses homologues. Pour ce faire, le VTEP dispose d’une table de correspondance (adresse MAC → adresse IP d’un VTEP) que l’on appelle la FDB (pour Forwarding DataBase). La question est maintenant de savoir comment la FDB de chaque VTEP va être remplie. Plusieurs modes de déploiement de VXLAN adressent cette problématique :
- multicast : la découverte automatique des VTEP est permise par multicast, les adresses MAC sources et leur localisation sont retenues par le VTEP
- unicast en automatisant la découverte des VTEP et en s’appuyant sur la capacité d’apprentissage des VTEP pour retenir la localisation des adresses MAC source
- unicast en automatisant par un moyen externe, la découverte des VTEP et de la localisation des adresses MAC (les solutions SDN ou BGP EVPN en sont un exemple)
Exemple pratique : VXLAN en unicast sous Linux
Sous linux, VXLAN est utilisable grâce au module du même nom :
filename: /lib/modules/4.9.0-4-amd64/kernel/drivers/net/vxlan.ko
alias: rtnl-link-vxlan
description: Driver for VXLAN encapsulated traffic
author: Stephen Hemminger <stephen@networkplumber.org>
version: 0.1
license: GPL
srcversion: 7C0AD193D8ABFD97E2F11B1
depends: udp_tunnel,ip6_udp_tunnel
intree: Y
vermagic: 4.9.0-4-amd64 SMP mod_unload modversions
parm: udp_port:Destination UDP port (ushort)
parm: log_ecn_error:Log packets received with corrupted ECN (bool)
Dans mon exemple, je dispose de trois machines virtuelles dans le même réseau local : 10.0.0.0/24: vm01 (10.0.0.2), vm02 (10.0.0.3), vm03 (10.0.0.4). Utiliser VXLAN au dessus d’un mếme réseau ethernet n’est pas très utile, mais il permet tout de même d’en montrer le fonctionnement.
Avant de monter notre réseau d’overlay, voyons comment on peut lire le contenu de la FDB, c’est important pour la compréhension de cet exemple :
bridge fdb show
Pour ce test, nous mettrons en préfixe du nom de nos interfaces VXLAN : “vxlan” (surprise !). Nous pouvons donc filtrer les résultats trouvés dans la FDB par ce nom, et en surveiller le contenu en continu dans un autre terminal (tmux, screen ou byobu sont nos amis) :
watch -n 1 "bridge fdb show | grep vxlan"
La création d’une interface de type VXLAN se fait simplement via la commande ip. Montons un tunnel, avec le VNI 10, entre vm01 et vm02 :
root@vm01:~# ip link add vxlan10 type vxlan id 10 local 10.0.0.2 remote 10.0.0.3
root@vm01:~# ip link set vxlan10 up
Nous devrions maintenant voir apparaître dans la FDB une entrée indiquant comment joindre le VTEP de vm02 :
00:00:00:00:00:00 dev vxlan10 dst 10.0.0.3 self permanent
Nous pouvons également voir que nous sommes en écoute sur le port udp/8472, ce qui est bon signe :
root@vm01:~# ss -lnpu
...
UNCONN 0 0 *:8472 *:*
…
Ici nous avons précisé dès le départ comment joindre le VTEP distant, nous retrouvons donc une entrée dans la FDB à cet effet, nous verrons par la suite qu’il est possible d’ajouter ces entrées dans la FDB manuellement.
Nous pouvons effectuer les mêmes actions sur la vm02 pour que les deux VTEP se connaissent :
root@vm02:~# ip link add vxlan10 type vxlan id 10 local 10.0.0.3 remote 10.0.0.2
root@vm02:~# ip link set vxlan10 up
Nous retrouvons alors une entrée similaire dans la FDB de vm02 :
00:00:00:00:00:00 dev vxlan10 dst 10.0.0.2 self permanent
À ce stade, il est possible de communiquer à travers le tunnel. Ajoutons une adresse IP à chaque interface VXLAN pour ce faire :
root@vm01:~# ip addr add 192.168.0.2/24 dev vxlan10
root@vm02:~# ip addr add 192.168.0.3/24 dev vxlan10
Lançons un ping depuis vm01 :
root@vm01:~# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3) 56(84) bytes of data.
64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=1.55 ms
64 bytes from 192.168.0.3: icmp_seq=2 ttl=64 time=0.790 ms
Nous devrions avoir dans la FDB une entrée indiquant que l’adresse MAC de vxlan10 sur vm02 est accessible derrière l’adresse IP du VTEP distant :
96:3d:d7:db:24:ee dev vxlan10 dst 10.0.0.3 self
Vérifions sur vm02 que c’est la bonne adresse MAC :
root@vm02:~# ip a s vxlan10
4: vxlan10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 96:3d:d7:db:24:ee brd ff:ff:ff:ff:ff:ff
inet 192.168.0.3/24 scope global vxlan10
valid_lft forever preferred_lft forever
inet6 fe80::943d:d7ff:fedb:24ee/64 scope link
valid_lft forever preferred_lft forever
C’est le cas. On constate ici que le VTEP source apprend de lui même la localisation des adresses MAC de destination. Si l’on regarde la FDB du VTEP de destination, vm02, une entrée est également apparue :
2e:f0:64:67:76:9f dev vxlan10 dst 10.0.0.2 self
Le VTEP de destination retient donc également la localisation de l’adresse MAC source.
Note : Comme nous l’évoquions plus tôt, ce mécanisme d’apprentissage peut être désactivé, si au moment de la création de l’interface VXLAN, on passe l’option nolearning. La déclaration des entrées dans la FDB sera alors également à notre charge (en plus de la découverte des VTEP). Les solutions SDN gèrent généralement ces deux aspects d’apprentissage en maintenant une FDB centralisée. Une autre approche consiste à utiliser BGP pour communiquer la localisation des adresses MAC (voir BGP EVPN).
Voyons également ce qui se passe sous le capot, avec tcpdump :
root@vm02:~# tcpdump -i eth0 -n udp
[ 586.437046] device eth0 entered promiscuous mode
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
19:55:48.030298 IP 10.0.0.2.34495 > 10.0.0.3.8472: OTV, flags [I] (0x08), overlay 0, instance 10
IP 192.168.0.2 > 192.168.0.3: ICMP echo request, id 1048, seq 10, length 64
19:55:48.030375 IP 10.0.0.3.40315 > 10.0.0.2.8472: OTV, flags [I] (0x08), overlay 0, instance 10
IP 192.168.0.3 > 192.168.0.2: ICMP echo reply, id 1048, seq 10, length 64
19:55:49.032138 IP 10.0.0.2.34495 > 10.0.0.3.8472: OTV, flags [I] (0x08), overlay 0, instance 10
IP 192.168.0.2 > 192.168.0.3: ICMP echo request, id 1048, seq 11, length 64
19:55:49.032317 IP 10.0.0.3.40315 > 10.0.0.2.8472: OTV, flags [I] (0x08), overlay 0, instance 10
IP 192.168.0.3 > 192.168.0.2: ICMP echo reply, id 1048, seq 11, length 64
19:55:50.033625 IP 10.0.0.2.34495 > 10.0.0.3.8472: OTV, flags [I] (0x08), overlay 0, instance 10
Nous pouvons voir les paquets ICMP encapsulés. tcpdump ne nous montre ici qu’une partie des informations mais il est tout à fait possible d’exporter cette capture en pcap avec l’option -w, puis de l’interpréter avec wireshark.
Ajoutons maintenant une troisième machine à notre architecture, vm03, en montant une interface VXLAN et en ajoutant le VTEP de vm02 à la FDB :
root@vm03:~# ip link add vxlan10 type vxlan id 10 local 10.0.0.4 remote 10.0.0.3
root@vm03:~# ip link set vxlan10 up
root@vm03:~# bridge fdb append 00:00:00:00:00:00 dev vxlan10 dst 10.0.0.2
On donne une adresse ip à vm03 dans le réseau d’overlay :
root@vm03:~# ip addr add 192.168.0.4/24 dev vxlan10
vm01, vm02 et vm03 peuvent maintenant communiquer sur le réseau 192.168.0.0/24, grâce à VXLAN.
Conclusion
Nous avons vu dans cet article les principes des réseaux d’overlay ainsi que le fonctionnement d’un protocole répandu dans le domaine, VXLAN. Nous avons également expérimenté le déploiement de réseaux VXLAN sous Linux. Le prochain article traitera de Flannel, nous montrerons comment VXLAN est utilisé dans cette solution et nous parlerons du positionnement de Flannel parmis les technologies dites de SDN (Software Defined Networking).
Il est à noter que les réseaux d’overlay ne font pas l’unanimité. Certains préfèreront disposer d’un plan de transmission (data plane) plus simple et donc plus facilement dépannable, dépourvu d’encapsulation et basé uniquement sur du routage dynamique. C’est l’approche choisie par Calico notamment. Nous étudierons aussi ce produit dans un prochain article ;)
Merci à Yann pour le schéma ;)
Sources
- VXLAN, des VLANs dynamiques et routables pour les clouds
- How VTEP learns and creates forwarding table
- Linux native VXLAN support on KVM hypervisor
- VXLAN & Linux
- Geneve
- VXLAN NSX
- How VXLAN works on Linux
En savoir plus :