

Sommaire
Qu’est ce que c’est ?
Consul est un “service registry” ainsi qu’un stockage de dictionnaire (key/value) qui permet de mettre en place un service de gestion de configuration dynamique. Grâce à Vault il peut également servir de service de gestion des mots de passe pour les applications et combiner à Terraform, Consul permet également de faire un monitoring des services.
Ce n’est pas une alternative à de la gestion de configuration mais il permet de supporter des éléments de configuration qui évoluent régulièrement et dynamiquement dans le temps. Voir l’exemple.
Il est clusterisable très facilement et se base sur un protocole “gossip” et sur l’élection d’un leader. Il peut être interrogé en utilisant des requêtes REST mais également via le DNS.
Problématique
Mettons-nous dans un contexte micro-services avec une gestion “classique” de la configuration avec Saltstack, Puppet, Chef ou Ansible.
On peut schématiser le fonctionnement de ces solutions : un référentiel de données (hiera, pillar, etc.) est inséré en input d’un engine (playbook, module, state, etc.) et l’output est un ensemble d’actions réalisées, des binaires récupérés et des fichiers de configuration.
On veut maintenant scaler un des services, il suffit de mettre à jour le référentiel de données et de relancer notre outil de gestion de configuration. Pour mettre à jour le référentiel de données et dans le cas d’une scalabilité “automatique”, il va donc falloir faire un script qui le modifie en fonction des données issues du mécanisme qui demande et réalise cette scalabilité. Bien sur il faut que cela soit possible pour un scale “up” et un scale “down”.
La problématique se pose dans un contexte de forte montée en charge : nos serveurs sont davantage sollicités et en plus on leur impose la charge du client ou de la connexion de notre gestionnaire de configuration !
Dans un contexte de containers c’est encore plus flagrant : pour respecter le principe de mono-processus, il n’est pas possible de mettre en place un client qui tournerait en “parallèle” du processus métier. Il vous faut donc le gérer depuis le serveur qui contient les containers en faisant des liens vers des volumes et … ça devient compliqué !
Une autre solution est l’utilisation importante de loadbalanceurs internes qu’il va falloir également configurer. Un loadbalanceur pour toutes les applications A, B, C, etc qui ressemble à un Single Point Of Failure à moins de faire confiance au LBaaS de votre cloud provider qui vous facturera le trafic dessus éventuellement.
Avec un service registry
Mettons en place un service registry comme Consul dans notre infrastructure. Pour que nos services le trouve c’est un des points à configurer… avec les problèmes vus précédemments… On pourra cependant conclure que ces problèmes se posent dans un cas de services dynamiques et moins dans le cas d’un service “clusterisé”.
Nos micro-services (applications) comme nos “services” (BDD, Bus, Gestion des logs) vont s’enregistrer sur le service registry:
- avec leurs noms DNS/ip et leurs ports
- avec un healthcheck permettant d’identifier leur état
- avec un ensemble de tags, permettant d’identifier la caractéristique de chacun :
- la version de l’API (pour en avoir plusieurs en parallèle)
- la version de l’application
- s’il est en mode “lecture” ou “écriture”
- une information métier (pour isoler le bus de logs d’un bus métier)
- tout ce que vous pouvez imaginer en fait, rien n’est obligatoire
Chaque service va ensuite pouvoir faire des requêtes telles que : “j’ai besoin de la liste service appelé A avec la v3 comme API et seulement les services dont le healthcheck est up”.
Lors de la suppression de service lors du scale down il est préférable de les désenregistrer même si les healthcheck finiront par supprimer le service (c’est configurable).
Comme vous le constatez, ce sont aux développeurs de gérer les réponses du service registry et non plus aux opérationnels de savoir avec qui et avec quelle version les services communiquent. C’est plus logique à mon sens, puisque c’est un choix métier. Il est possible d’implémenter une solution de type “moi en tant qu’application A tant que pour l’application B la v4 est indisponible j’utilise la v3” est ainsi de déployer indépendamment A et B. C’est testable facilement et cela simplifie le travail de la production.
On peut également utiliser la gestion clef/valeur de Consul pour activer/désactiver des fonctions via des variables de configuration. C’est très utile sur les environnements de tests/QA/développement mais également en production. Une activation n’étant plus qu’une clef à changer dans votre consul, un curl fera l’affaire.
Comment je l’installe ?
Consul est disponible en mode Docker comme sur un packaging classique sur la plupart des plateformes.
Je commence par monter trois vm “virtualbox” (idem avec un autre driver).
# create machine
docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox leader1 docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox worker1 docker-machine create \
--engine-env 'DOCKER_OPTS="-H unix:///var/run/docker.sock"' \
--driver virtualbox worker2
Puis je récupère les informations :
ip_leader1=$(docker-machine ip leader1) ip_worker1=$(docker-machine ip worker1) ip_worker2=$(docker-machine ip worker2) ip_gateway="172.17.0.1"
Pour créer le cluster je dois publier les ports de mes containers. Ici j’ouvre toutes les fonctionnalités.
#create consul cluster
eval "$(docker-machine env leader1)" docker run -d -h node1 -v /mnt:/data \
-p $ip_leader1:8300:8300 \
-p $ip_leader1:8301:8301 \
-p $ip_leader1:8301:8301/udp \
-p $ip_leader1:8302:8302 \
-p $ip_leader1:8302:8302/udp \
-p $ip_leader1:8400:8400 \
-p $ip_leader1:8500:8500 \
-p $ip_gateway:53:53/udp \
progrium/consul -server -advertise $ip_leader1 -bootstrap-expect 3 -ui-dir /ui eval "$(docker-machine env worker1)" docker run -d -h node2 -v /mnt:/data \
-p $ip_worker1:8300:8300 \
-p $ip_worker1:8301:8301 \
-p $ip_worker1:8301:8301/udp \
-p $ip_worker1:8302:8302 \
-p $ip_worker1:8302:8302/udp \
-p $ip_worker1:8400:8400 \
-p $ip_worker1:8500:8500 \
-p $ip_gateway:53:53/udp \
progrium/consul -server -advertise $ip_worker1 -join $ip_leader1 eval "$(docker-machine env worker2)" docker run -d -h node3 -v /mnt:/data \
-p $ip_worker2:8300:8300 \
-p $ip_worker2:8301:8301 \
-p $ip_worker2:8301:8301/udp \
-p $ip_worker2:8302:8302 \
-p $ip_worker2:8302:8302/udp \
-p $ip_worker2:8400:8400 \
-p $ip_worker2:8500:8500 \
-p $ip_gateway:53:53/udp \
progrium/consul -server -advertise $ip_worker2 -join $ip_leader1
J’ai activé l’UI ce qui me permet maintenant de voir les informations suivantes :
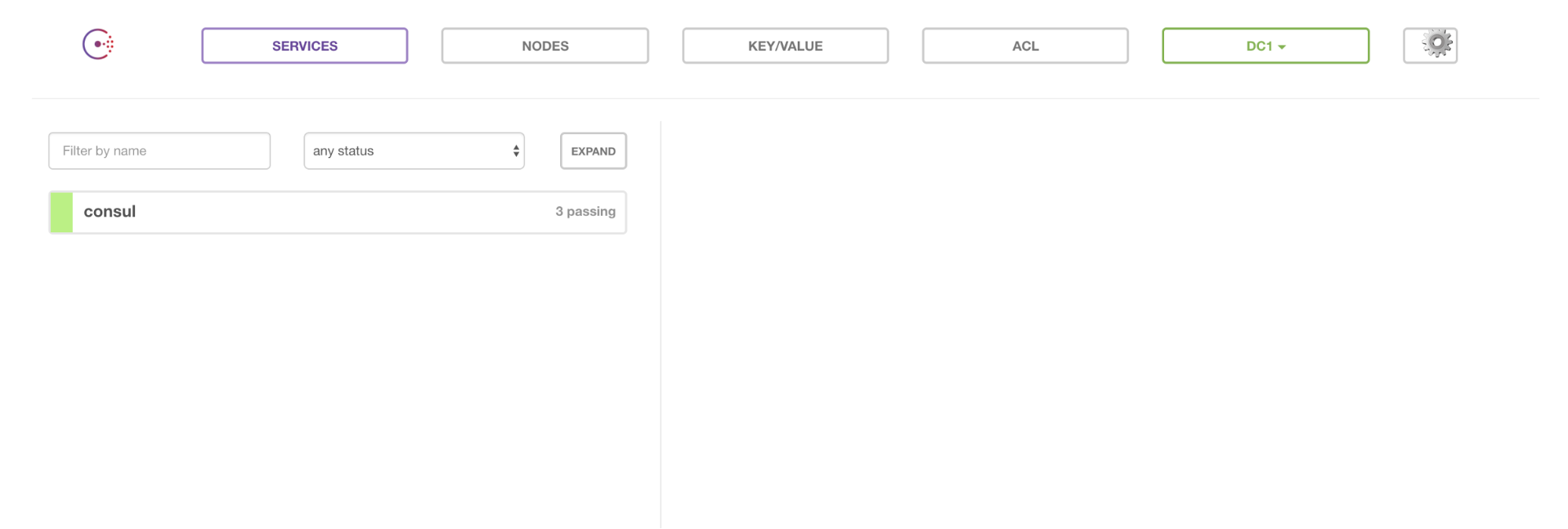
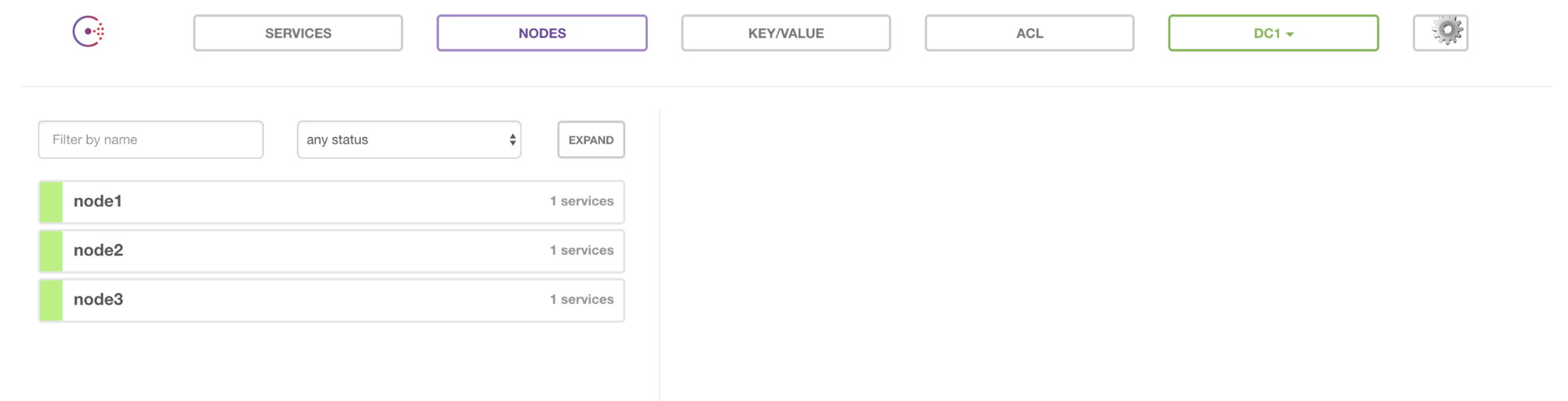
Note : pour simplifier je n’ai pas activé les ACLs. Pour ce faire, il faut builder sa propre image Docker en ajoutant un fichier de configuration.
Pour la suite je rajoute à mes VMs un cluster Swarm:
# create swarm cluster
eval "$(docker-machine env leader1)" docker swarm init \
--listen-addr $ip_leader1 \
--advertise-addr $ip_leader1 token=$(docker swarm join-token -q worker) eval "$(docker-machine env worker1)" docker swarm join --token $token --advertise-addr consul://$ip_worker1:8500 $ip_leader1:2377 eval "$(docker-machine env worker2)"
docker swarm join --token $token --advertise-addr consul://$ip_worker2:8500 $ip_leader1:2377
# visualizer
eval "$(docker-machine env leader1)" docker run -it -d -p 5000:5000 \
-e HOST=$ip_leader1 \
-e PORT=5000 \
-v /var/run/docker.sock:/var/run/docker.sock \
manomarks/visualizer
Je n’ai pas de visibilité sur mes dockers Consul dans le visualizer puisque je les ai créés hors Swarm.
J’ai créé un docker avec SpringBoot qui se connecte sur ce consul : https://github.com/WeScale/consul-spring-docker
Il est disponible sur le DockerHub : wescale/democonsul.
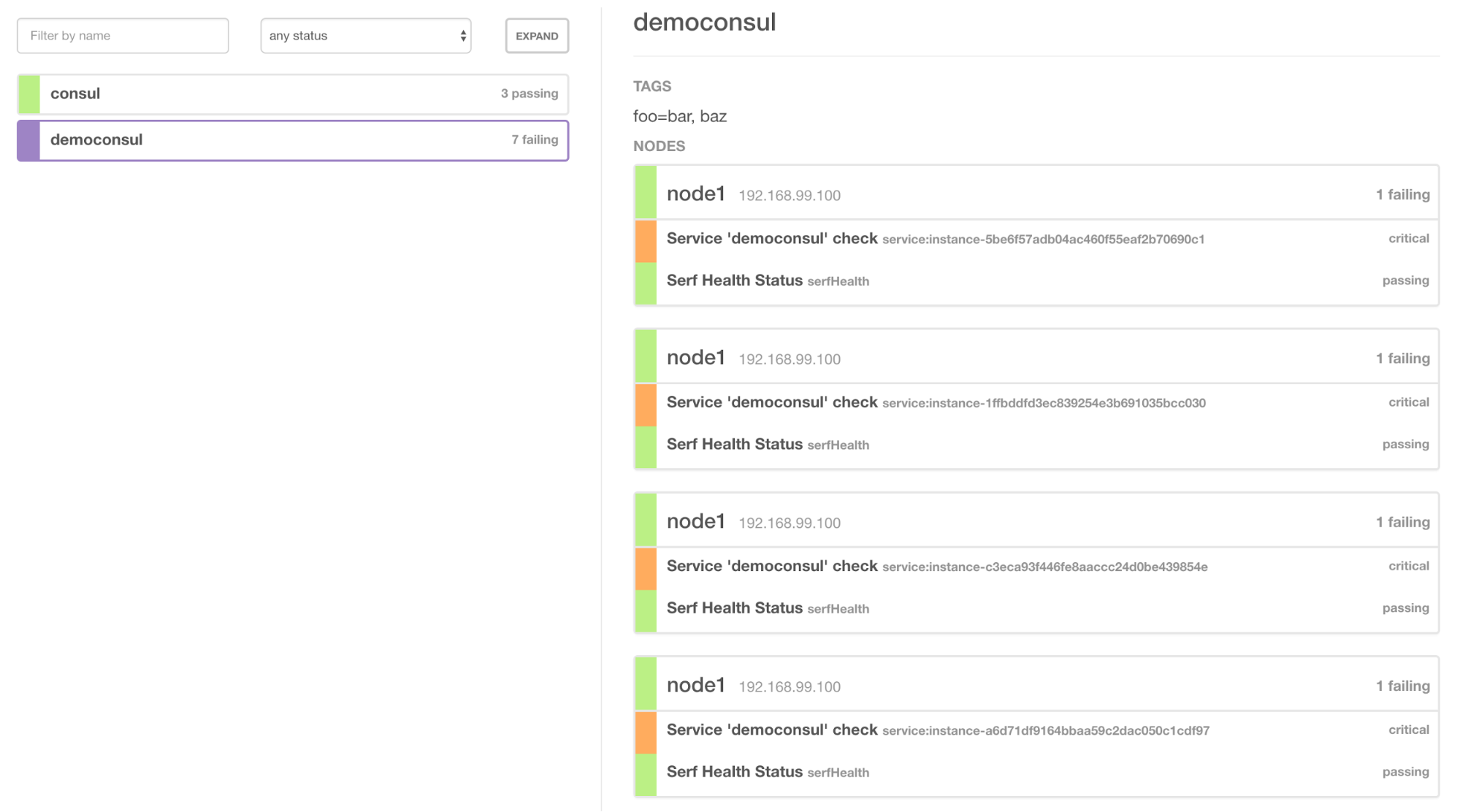
Quand je le lance dans mon Swarm :
docker service create –replicas 3 –name web wescale/consuldemo
Regardons quand je scale up :
docker service scale web=10
Conclusion
Un service registry est un élément aujourd’hui indispensable dans une architecture micro-services. Celle-ci impose des solutions dynamiques pour gérer la configuration.
Il existe trois phases lors d’un déploiement de microservices pour avoir un temps de latence et de scalabilité améliorée. Une phase de packaging avec Packer ou Docker, le déploiement et la configuration via le service registry.
Il est également très facile de faire un état des lieux quasi temps réel de ce qu’il y a en production. L’analyse des logs du service registry peut également renseigner sur l’utilisation des services (en fonction des versions, la fréquentation, …).
Les concurrents à Consul sont Etcd, Apache Zookeeper et Eureka.



