 Damien Vergnaud
Damien Vergnaud
Platform Engineering, EKS, Kubernetes... Le WeShare de septembre 2023
Le WeShare, c’est le premier lundi de chaque mois, journée pendant laquelle l’ensemble de la tribu se retrouve pour du partage. En septembre, à...

La mesure de la consommation énergétique des applications est un sujet d’actualité, d’une part pour en prendre conscience et d’autre part pour pouvoir l’optimiser. Dans cet article, nous allons présenter Scaphandre, un outil open source répondant à cette problématique de mesure, et son utilisation dans un contexte Kubernetes Kosmos.
Scaphandre est un projet open source sous licence Apache 2.0 qui a gagné en popularité avec plus de 1.3k stars sur GitHub fin 2023. Cet outil est créé et maintenu par @bpetit ainsi que d’autres contributeurs. Il est écrit en Rust.
Scaphandre a pour objectif d’initier la collaboration entre les sociétés de la tech et les enthousiastes du sujet autour d’un moyen simple, robuste, léger et clair de mesurer la consommation énergétique dans le but de prendre des décisions éclairées. (Source)
Pour cela, Scaphandre accède aux fichiers de métriques localisés dans /sys/class/powercap, /proc/stats et /proc/{PID}/stats. Cela lui donne accès à la consommation instantanée du serveur et la répartition par processus. Pour plus d’informations, veuillez consulter la documentation du projet.
En plus de la collecte des mesures, l'un des points forts de Scaphandre est sa capacité à exposer des métriques Prometheus. Cela permet de s’intégrer parfaitement à la stack d’observabilité. Voici le dashboard exemple du projet :
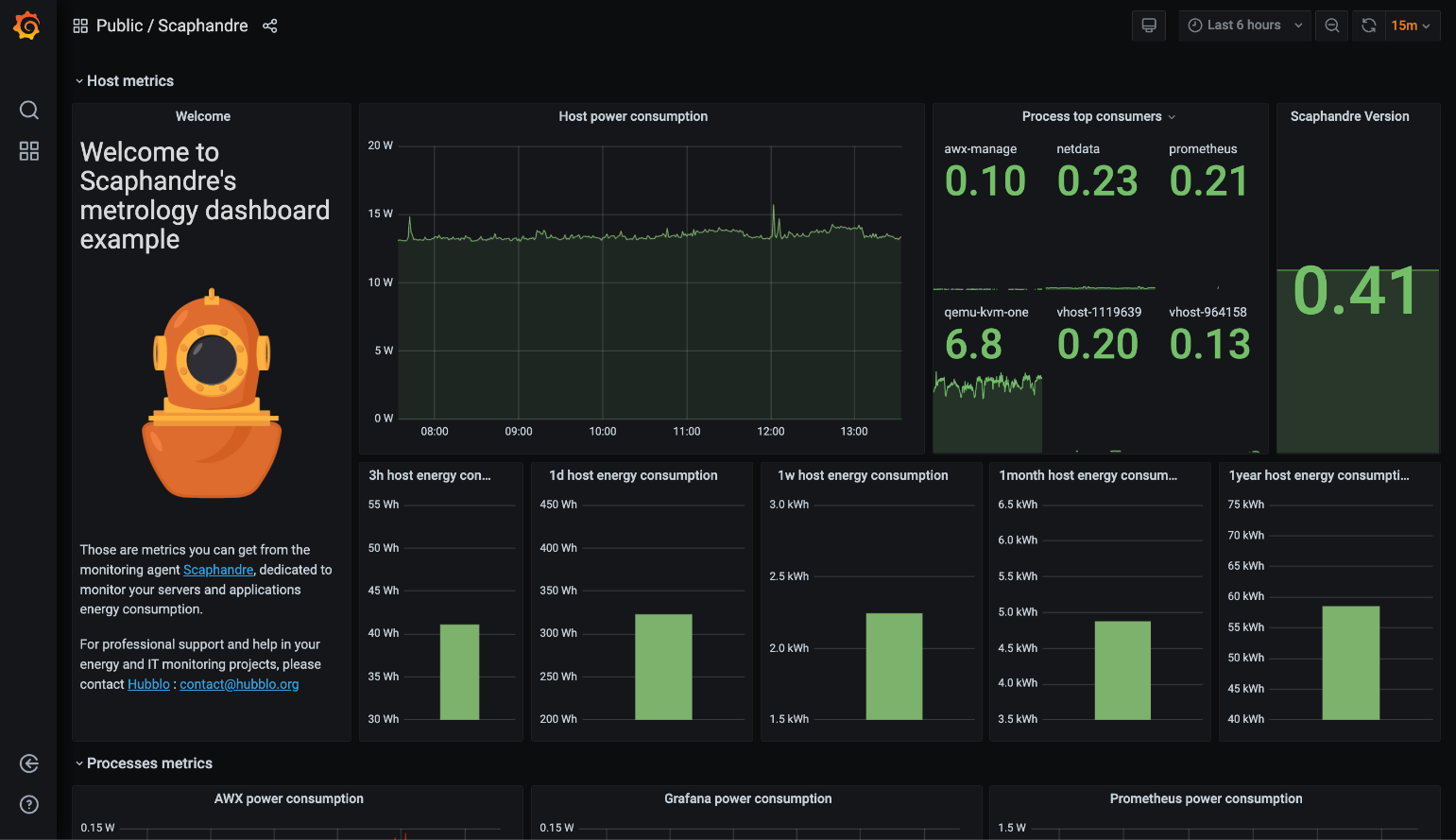
Dashboard exemple du projet Scaphandre
Sur ce dashboard, nous visualisons la puissance électrique consommée par les processus de la machine sur laquelle Scaphandre est installé, ainsi que sa conversion en quantité d’énergie consommée sur des intervalles de temps.
Pour résumer, Scaphandre offre les fonctionnalités suivantes :
Cependant, Scaphandre vient avec quelques contraintes, liées, notamment, aux capteurs implémentés :
Pour utiliser Scaphandre dans un contexte Kubernetes, nous avons besoin d’un cluster qui répond aux contraintes que nous venons d’évoquer. Nous avons utilisé la solution Kosmos de Scaleway qui nous permet de facilement créer un cluster Kubernetes avec un nœud Elastic Metal qui permettra à Scaphandre d’obtenir les mesures.
Afin de pouvoir déployer Scaphandre dans un environnement Kubernetes Scaleway, vous devez avoir coché ces prérequis :
Pour notre POC, nous avons utilisé la branche développement de Scaphandre, nous avons dû effectuer des actions manuelles afin de contourner des issues ouvertes sur le projet :
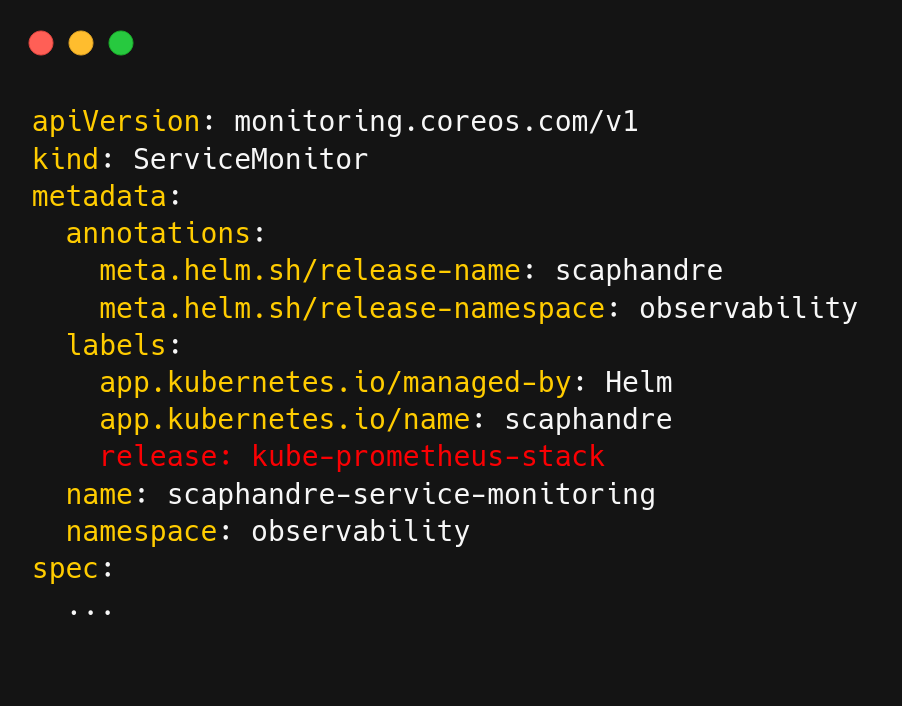
Manifeste de l’objet ServiceMonitor avec le label “release: kube-prometheus-stack”
Premièrement, il nous faut une pile d’observabilité sur le cluster. Nous allons utiliser kube-prometheus-stack qui simplifie grandement l’accès à prometheus et grafana :
helm repo add prometheus-community
https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack
prometheus-community/kube-prometheus-stack --namespace observability
Ensuite nous déploierons Scaphandre dans notre cluster via la Chart du projet :
git clone https://github.com/hubblo-org/scaphandre
git switch dev
cd scaphandre
helm install scaphandre helm/scaphandre \
--set serviceMonitor.enabled=true \
--set serviceMonitor.namespace=observability \
--set serviceMonitor.interval=30s \
--namespace observability
Pour réaliser nos tests, nous avons besoin d’une application pour mesurer sa consommation, idéalement avec plusieurs pods pour avoir de belles visualisations. Nous avons choisi de déployer dans le cluster l’application microservice démo de Google online boutique.
Peut-être n’aurez vous pas besoin de déployer Scaphandre sur tous vos nœuds ? ;
Cas :
Cette partie optionnelle répond à ce type de besoin.
En utilisant le même principe que décrit ici, vous pouvez labelliser le nœud Scaleway dédié de cette manière :
kubectl get nodes
Identifiez les nœuds répondant aux prérequis puis appliquez un label :
kubectl label nodes scw-k8s-metal-pool-metal-{ID} powercap_rapl=true
Cette labellisation vous permet de conditionner le déploiement de Scaphandre et de vos applications à surveiller.
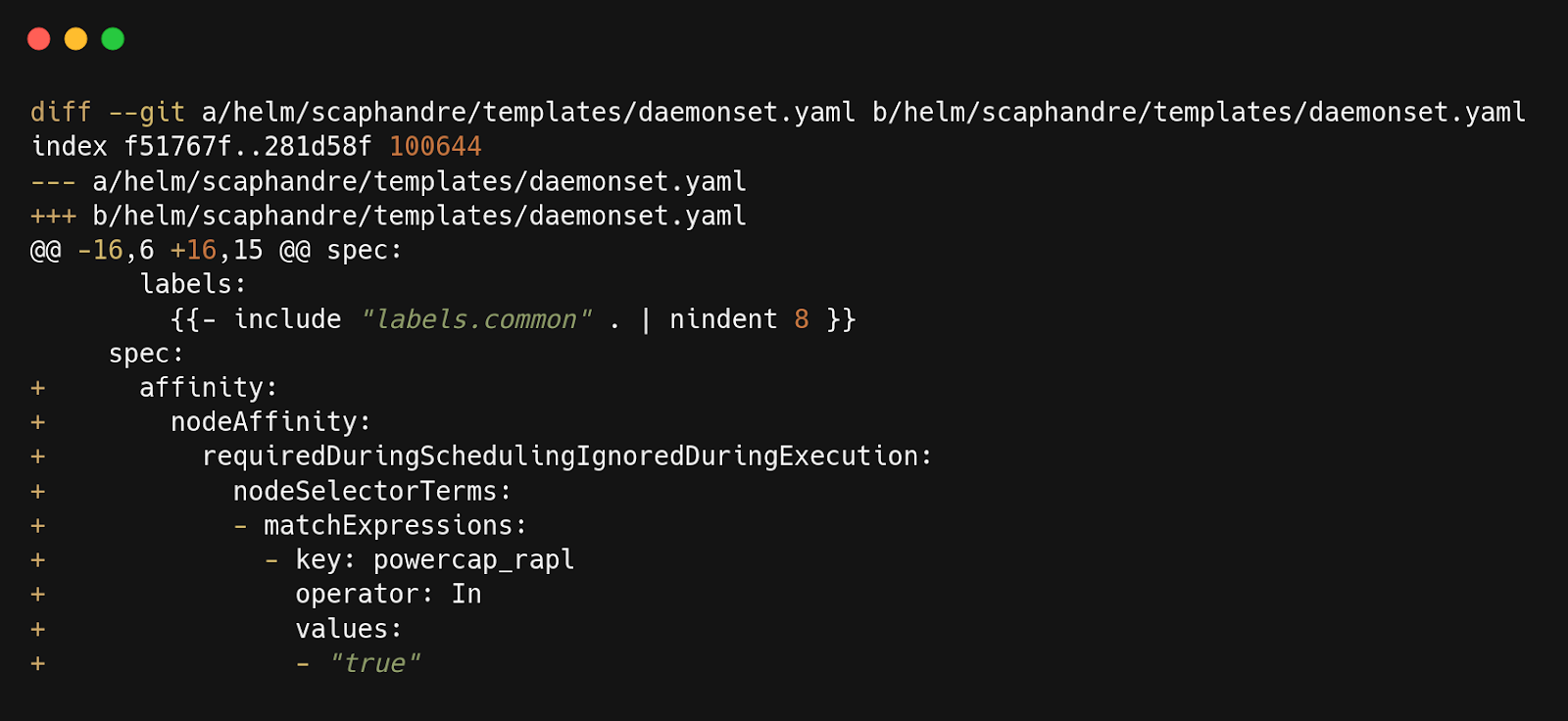
Pour Scaphandre, en fonction de la version actuelle, vous pourriez avoir à rajouter également la sélection de nœuds dans le template du DaemonSet de la Helm chart avant de faire le déploiement.
Suggestion de changement pour l’objet DaemonSet de Scaphandre
Vous aurez à faire le même type de manipulation pour toutes les applications que vous souhaitez mettre sous le radar de Scaphandre, en utilisant :
Maintenant que nous avons notre contexte Kube Scaphandre fonctionnel, avec notre stack d’observabilité et notre application témoin, nous pouvons passer à l’objectif de cet article : tenter de “mesurer” la consommation énergétique de notre application.
Tout d’abord, faisons une mise au point sur les deux métriques principales exposées par Scaphandre : scaph_host_power_microwatts et scaph_process_power_consumption_microwatts.
La première donne en temps réel la puissance en watt consommée par la machine. La seconde donne la puissance en watt en temps réel pour chaque processus, il y a une valeur par PID de la machine.
Ces données brutes ne reflètent pas directement la puissance nécessaire pour faire fonctionner le CPU. Pour essayer de coller le plus possible à la réalité, nous multiplions les métriques Scaphandre par le PUE (Power Usage Effectivness, ratio entre la puissance totale consommée par le datacenter et la partie qui est effectivement consommée par les systèmes informatiques). Nous obtenons alors une mesure de la puissance consommée par notre serveur et les processus tournant dessus relativement proche de la réalité.
Les mesures que nous avons sont sous forme de métriques Prometheus, nous pouvons donc facilement les visualiser sur Grafana :
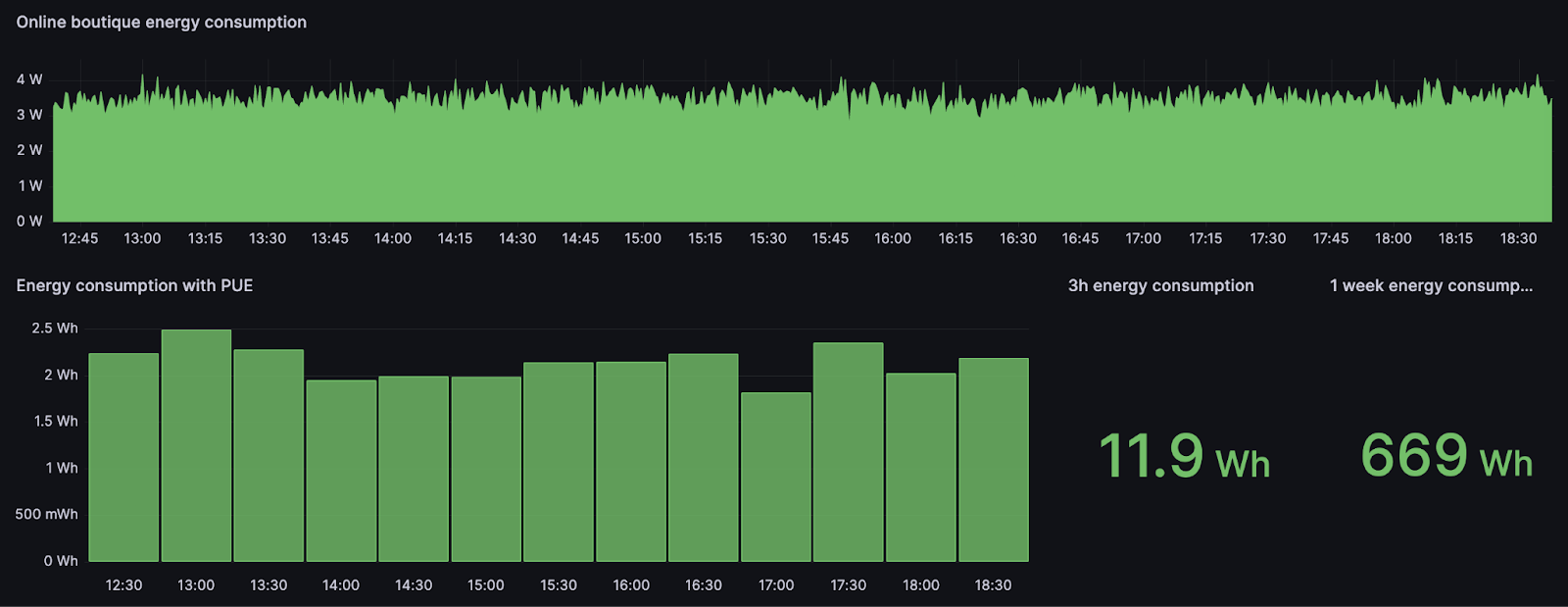
1ère ligne : Puissance consommée par l'application
2ème ligne : Énergie consommée par l'application sur différents intervalles de temps
Sur cette première visualisation, nous montrons l’évolution de la puissance consommée en Watt par notre application onlineboutique. De cette mesure de puissance, nous pouvons obtenir l’énergie en watt-heure sur différents intervalles de temps.
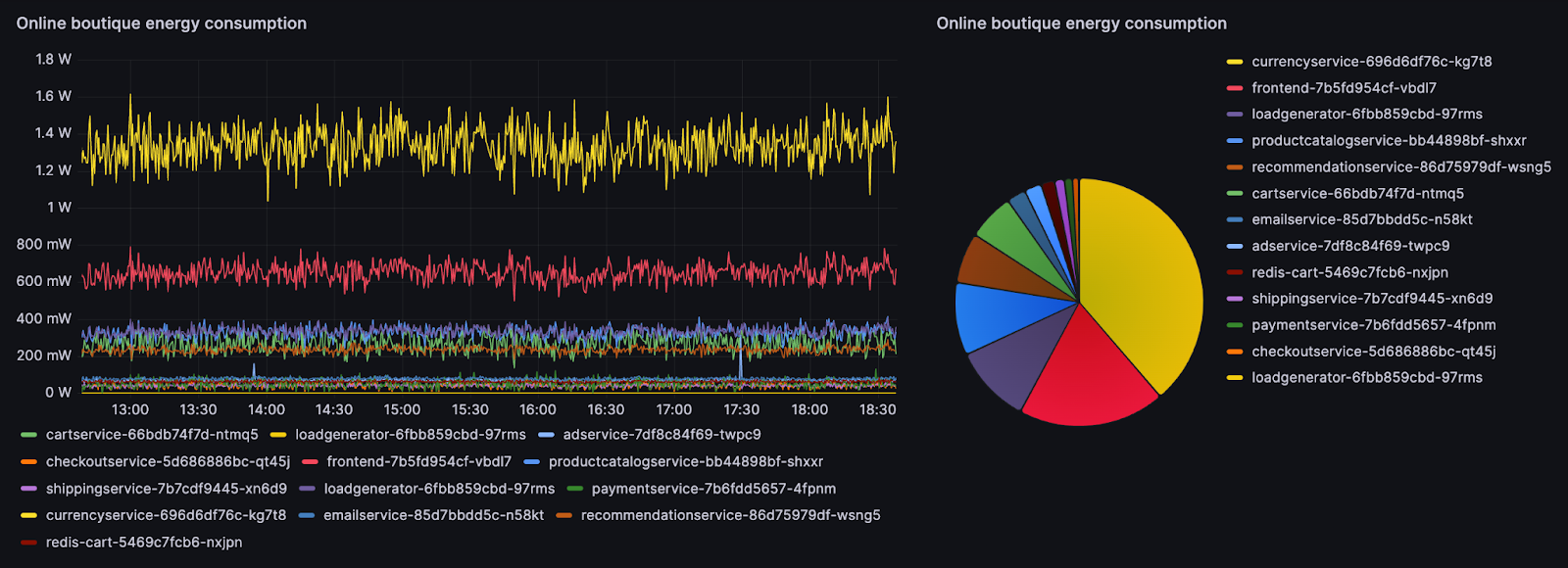
Scaphandre s’il est déployé avec l’option –containers et qu'il est installé sur un nœud Kubernetes, enrichi ses métriques avec le nom et le namespace du pod, ce qui rend très facile le filtrage par namespace ou pod. Ici, nous visualisons la puissance consommée par chaque pod du namespace onlineboutique.
Puissance consommée par chaque pod du namespace onlineboutique
Ces visualisations sont très intéressantes et permettent d’extraire pas mal d’informations : le micro-service qui consomme le plus, l’impact des pics de charges, l’évolution suite à une release, et d’autres.
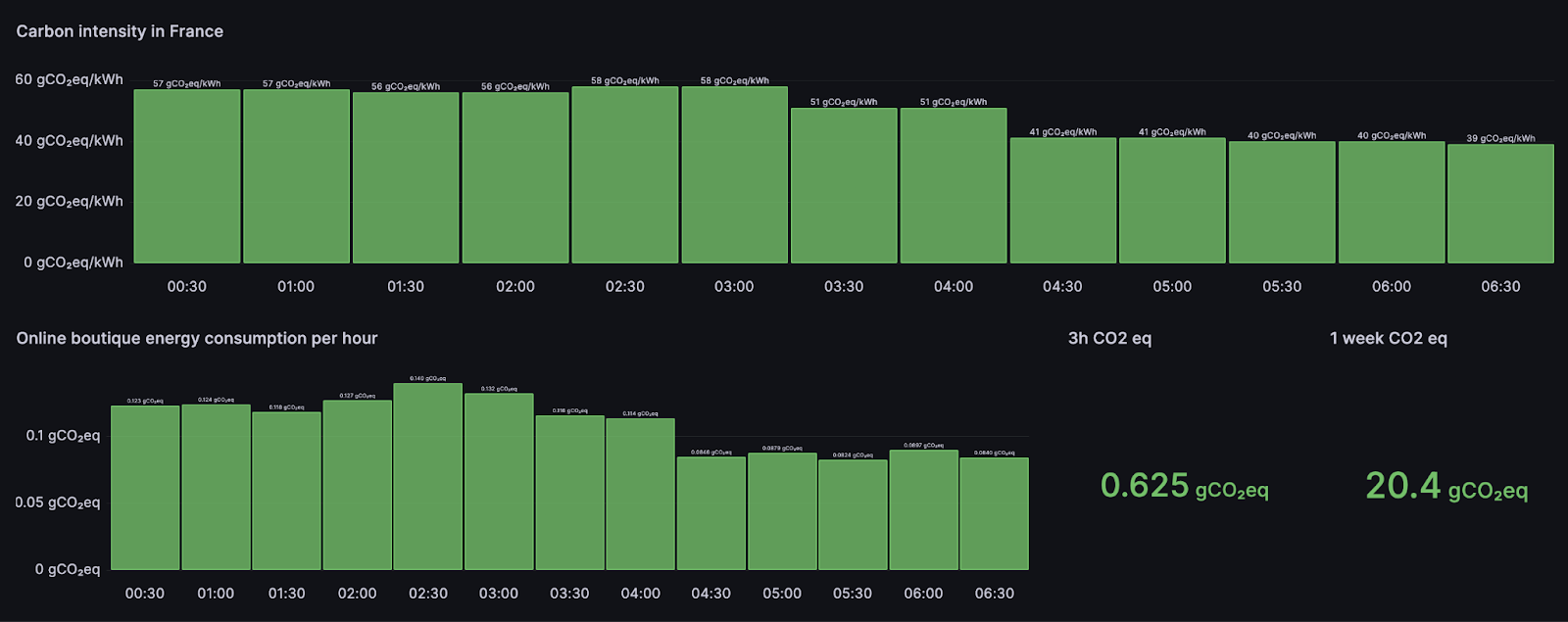
Pour aller plus loin, il est connu qu’un des premiers gestes GreenOps à mettre en place est de faire tourner les processus lourds (comme des entraînements ML ou des migrations databases) à des moments de la journée où l’électricité à une faible intensité carbone (gCO₂eq/kWh). C’est le principe des heures creuses et des heures pleines que nous connaissons tous. Il est possible de rajouter cette notion dans notre dashboard de mesure de la consommation de notre application. Nous rajoutons une métrique Prometheus de l’intensité carbone de la France, grâce à l’API d’ElectricityMaps et en multipliant cette métrique avec la métrique de Scaphandre (avec la prise en compte de PUE), nous obtenons l’équivalent CO₂ de notre application. Le code utilisé pour créer la métrique d’intensité carbone peut être trouvée dans ce référentiel. On remarque par exemple qu’à consommation électrique constante, les émissions d’équivalent CO₂ ne sont pas constantes et varient en fonction de l’intensité carbone.
1ère ligne : Intensité carbone récupérée sur le site ElectricityMaps
2ème ligne : Consommation (électrique et CO2eq) de l’application onlineboutique
Pour sensibiliser les équipes, nous pourrions même continuer les équivalences en parlant en heures de lampe allumée ou en km de voitures parcourus.
La mesure de la consommation énergétique d’une application est complexe et nous sommes arrivés à des métriques qui sont satisfaisantes pour nous, elles n’en restent pas moins limitées sur certains points.
Tout d’abord au niveau des métriques exposées par Scaphandre. Scaphandre utilise des fichiers de métriques qui mettent à disposition les mesures du capteur RAPL (Running Average Power Limit). Ce capteur est le plus communément utilisé, mais présente des limitations comme expliqué dans cet article de Boavizta qui compare une mesure au niveau châssis et la mesure du capteur RAPL au niveau système. La plus grosse limitation étant que RAPL ne prend en compte que le CPU et donc omet la consommation des autres composants : SSDs, GPUs, etc.
Ensuite au niveau de notre prise en compte du PUE. Le PUE (Power Usage Effectivness) est une mesure au niveau du datacenter et ne représente pas nécessairement le ratio entre la puissance totale consommée et celle effectivement consommée par le CPU de notre serveur.
Après avoir expérimenté Scaphandre, nous trouvons que ce projet répond bien à la promesse de départ, à savoir mesurer la consommation énergétique des applications sur Kubernetes. Nous avons essayé de montrer à travers nos différentes visualisations que son utilisation permet d’intégrer la notion de consommation énergétique, à la fois pour sensibiliser, mais aussi pour orienter les prises de décisions qui visent à réduire cette consommation.
À ce jour, Scaphandre vient avec des contraintes fortes pour pouvoir fonctionner. Notamment l’accès au capteur RAPL. Celui-ci n’étant pas propagé, par défaut, d’un hyperviseur aux machines virtuelles ; les instances des clouds providers ne peuvent pas utiliser les métriques. Nous ne pouvons qu’espérer qu’un travail conjoint entre les clouds providers et le projet Scaphandre permettra à l’avenir d’accéder aux métriques depuis des instances virtualisées. Pour que celà arrive, chez Scaleway, vous pouvez up-voter cette feature request.
Scaphandre est un projet open source qui sert la transparence énergétique par l’observabilité. Le projet est ouvert aux contributeurs sous plusieurs formes, visualisez le guide de contribution à votre disposition, ne sous-estimez pas votre impact 🙂
Retrouvez cet article en anglais sur le blog de Scaleway.
.jpg)
Le WeShare, c’est le premier lundi de chaque mois, journée pendant laquelle l’ensemble de la tribu se retrouve pour du partage. En septembre, à...

Introduction à Nomad et Consul par HashiCorp Nomad est un orchestrateur de conteneurs développé par HashiCorp. Allié à Consul, c’est une excellente...
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...