 David Drugeon-Hamon
David Drugeon-Hamon
Mise en place d'un assistant avec l'IA : Bilan
Dans nos articles précédents, nous avons décrit la mise en place d’un agent conversationnel qui assiste nos collaborateurs dans leurs tâches...

Dans notre premier article, nous avons exploré les défis de la création d’un assistant virtuel capable de communiquer avec les utilisateurs de manière fluide et naturelle, sujet de notre hackathon.
Nous avons abordé plusieurs concepts, notamment les langages de modèles étendus (LLM - Large Language Models) et leurs limites. Nous avons également exploré les architectures « Retrieval-Augmented Generation ». Elles offrent une solution pour répondre à notre question : comment offrir aux collaborateurs de WeScale un outil convivial pour exploiter les archives des messages Slack ?
Après avoir étudié la théorie, nous vous invitons à découvrir notre analyse de la solution open source DAnswer (https://www.danswer.ai), qui nous a aidés à relever notre défi.
Tout d’abord, nous avons étudié diverses options pour saisir ces concepts. Dans la communauté des Data Scientist, le langage Python est très répandu. Nous avons découvert que le cadre langchain (https://python.langchain.com/v0.2/docs/introduction/) est devenu indispensable pour concevoir des applications intégrant des LLM.
Cette boîte à outils propose une bibliothèque standardisée qui nous permet de nous abstraire des différentes briques que nous avons vues dans le premier article, soit le connecteur, le calcul des représentations vectorielles à l’aide d’embeddings, leur stockage dans une base de données vectorielle et l’interrogation d’un modèle de langage.
Au cours de la phase exploratoire, nous avons créé différents prototypes pour des fonctionnalités telles que la récupération des archives des messages Slack ou la consultation de notre LLM.
Pendant une conversation avec l’un de nos collègues sur notre problème, il nous a proposé une solution prête à l’emploi. Il s’agit d’une implémentation d’une architecture RAG : le projet open source DAnswer.
Ce projet vise à simplifier la collecte de données provenant de diverses sources d’entreprise, telles qu’un système de fichiers local, un système de stockage objet, des canaux Slack ou des services de messagerie.
À noter que certaines fonctionnalités ne sont pas disponibles dans la version communautaire du projet (comme la gestion des droits des utilisateurs sur les documents confidentiels).
Ce système propose une interface web permettant de gérer l’application. Il offre également aux utilisateurs finaux divers moyens d’interagir avec le modèle de langage, que ce soit par l’intermédiaire d’un agent conversationnel intégré au Slack de l’entreprise ou directement sur l’interface web.
Cette solution nous semblait parfaite pour répondre à notre problématique et elle était réalisable pendant un hackathon.
Nous avons effectué nos premiers tests sur nos machines de développement en utilisant Docker Compose, selon les recommandations de la documentation.
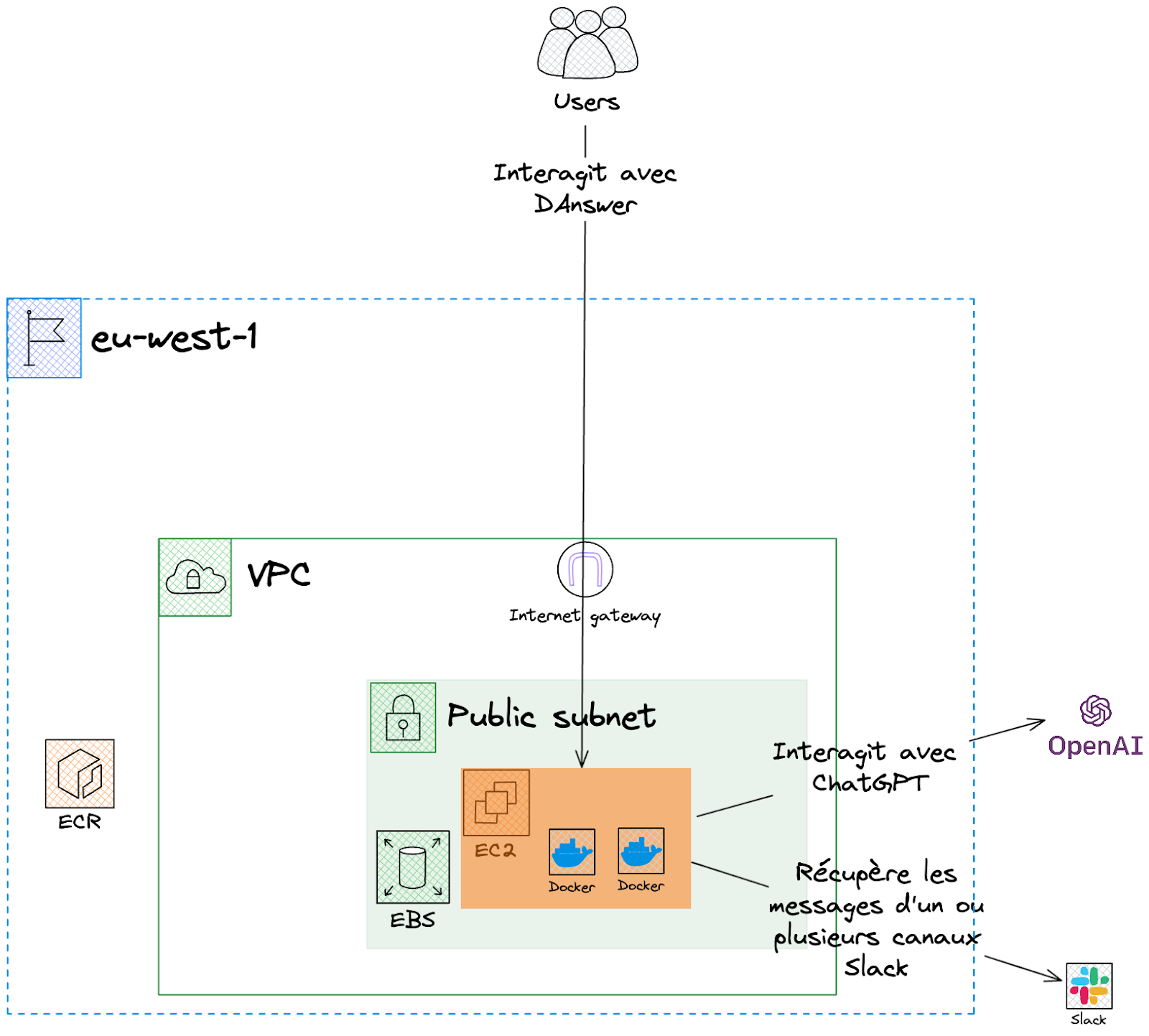
Pour le jour du hackathon, il était crucial de déployer la solution dans un environnement « bac à sable » pour des raisons de sécurité et de test. La plupart des membres de notre équipe ayant une expérience avec les services Amazon, nous avons opté pour AWS.
La documentation est très complète et recommande, dans un premier temps, d’exécuter la solution sur une instance EC2 autonome.
L’infrastructure sous-jacente est plutôt simple : une instance EC2 est déployée sur un sous-réseau public pour un accès direct à la machine. Pour des raisons de sécurité, nous n’avons autorisé que les adresses IP des locaux de WeScale.
DAnswer propose un fichier docker-compose permettant de déployer les différents composants directement sur l’instance.
Pour stocker les données de la base vectorielle et celles de la base de données servant à configurer l’application, nous avons ajouté un volume EBS de 500 Go pour s’assurer de la persistance des données si notre instance est renouvelée. Cette capacité est plus que suffisante pour le démonstrateur.
Par défaut, l’application DAnswer utilise le modèle de langage naturel (LLM) d’OpenAI, ChatGPT 3.5 Turbo. Pour calculer les embeddings, la solution permet de récupérer différents modèles proposés par Hugging Face.
Hugging Face (https://huggingface.co/) est une plateforme communautaire qui propose à ses membres des données d’entrainements que des modèles d’IA pré entraînés. Cette plateforme est très prisée pour simplifier la recherche, le développement et l’intégration d’algorithmes d’intelligence artificielle. On peut le définir comme le “ GitHub ” de l’intelligence artificielle.
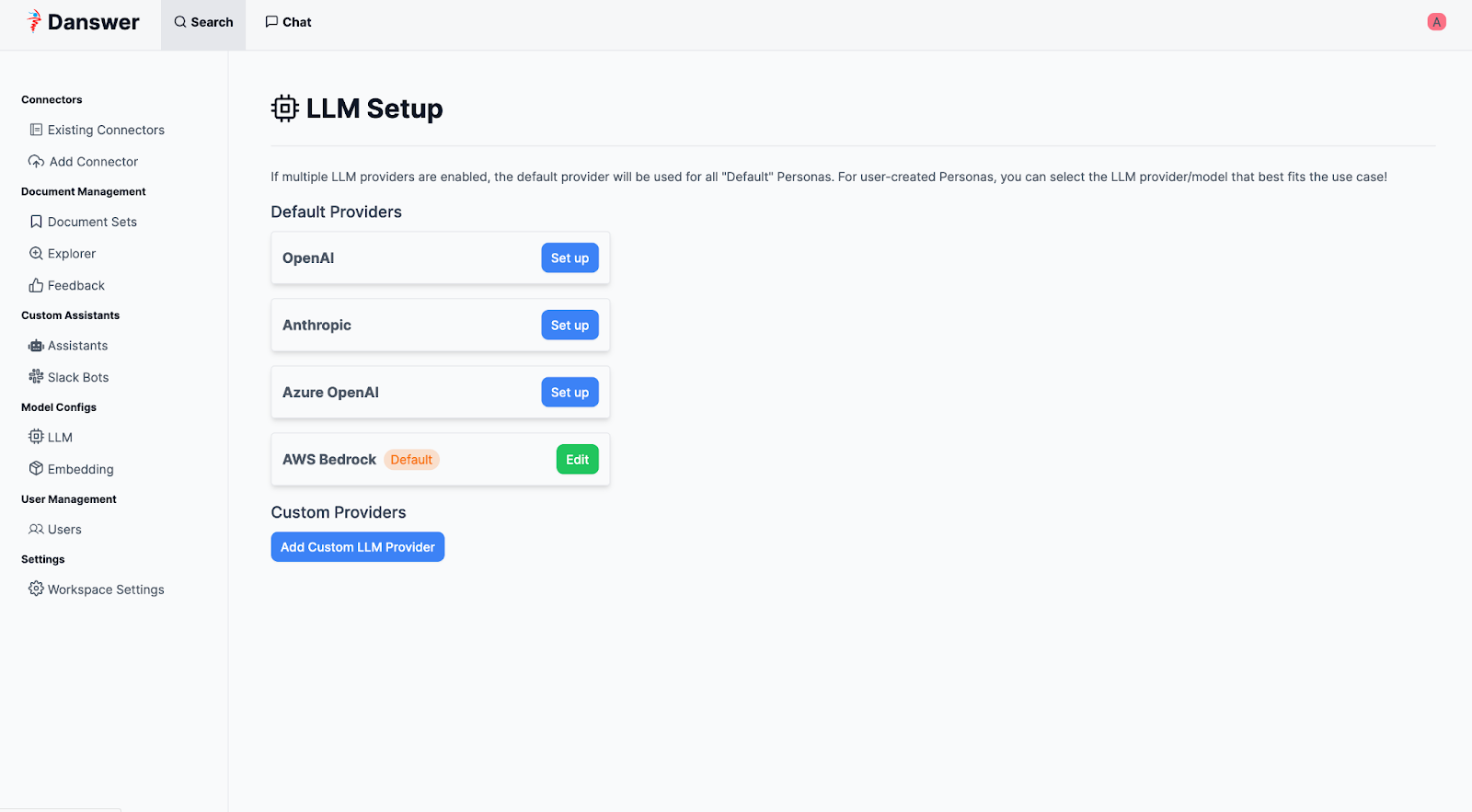
Une fois déployé, la configuration de l’outil se fait en se connectant sur l’interface web. On peut notamment y modifier le modèle de LLM (en fournissant les clés API), le modèle d’embeddings ou encore personnaliser les directives, pour ne citer que ces exemples.
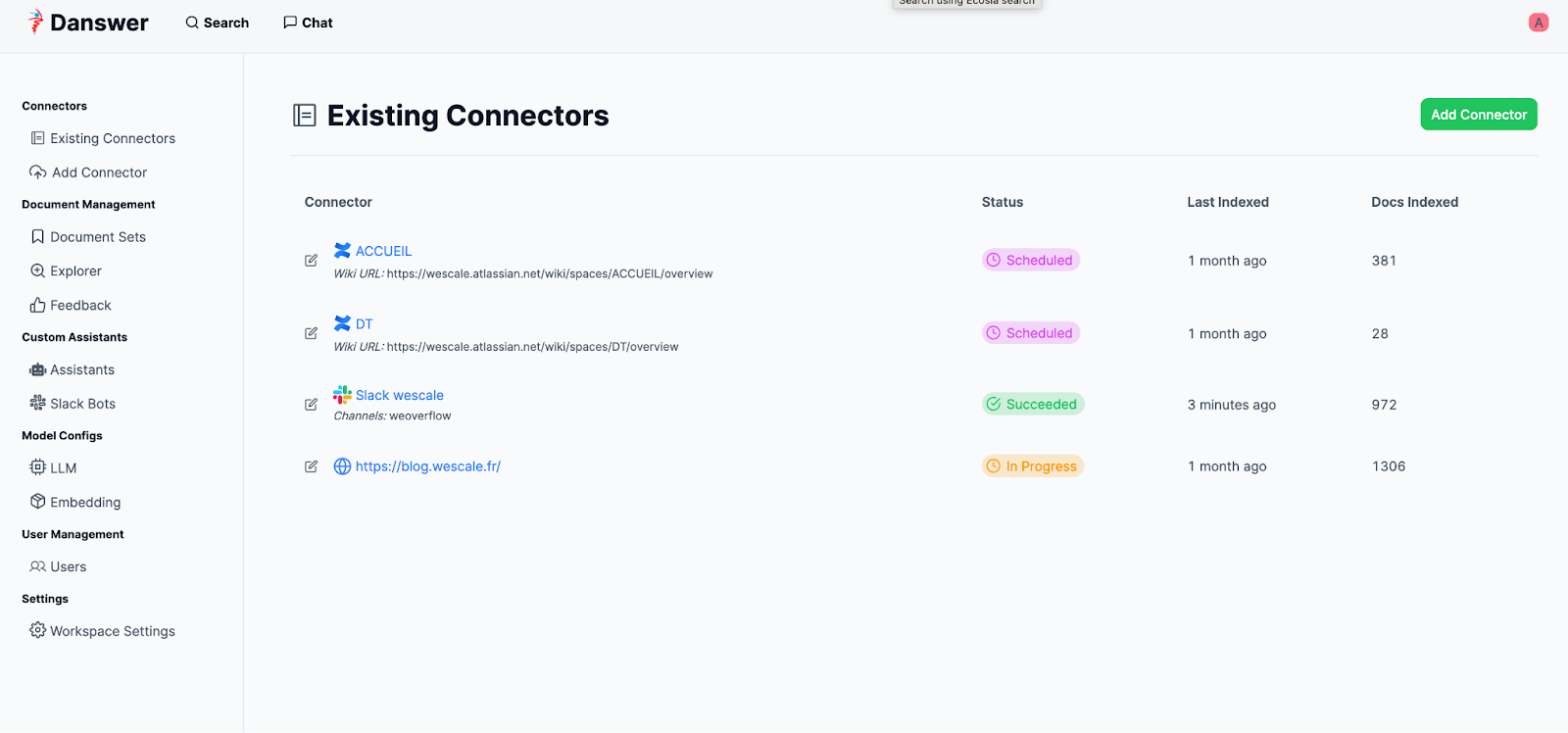
Une fois configuré, nous pouvons ajouter une ou plusieurs sources de données qui seront ensuite indexées. Le connecteur le plus simple est celui permettant de récupérer le contenu d’un site Web.
Dans notre cas, nous avons décidé d’indexer le blog de WeScale de manière récursive. Le temps nécessaire pour effectuer l’indexation dépendra du type d’instance sélectionnée.
Les premières impressions semblent plutôt bonnes. La documentation est claire et les performances sont au rendez-vous.
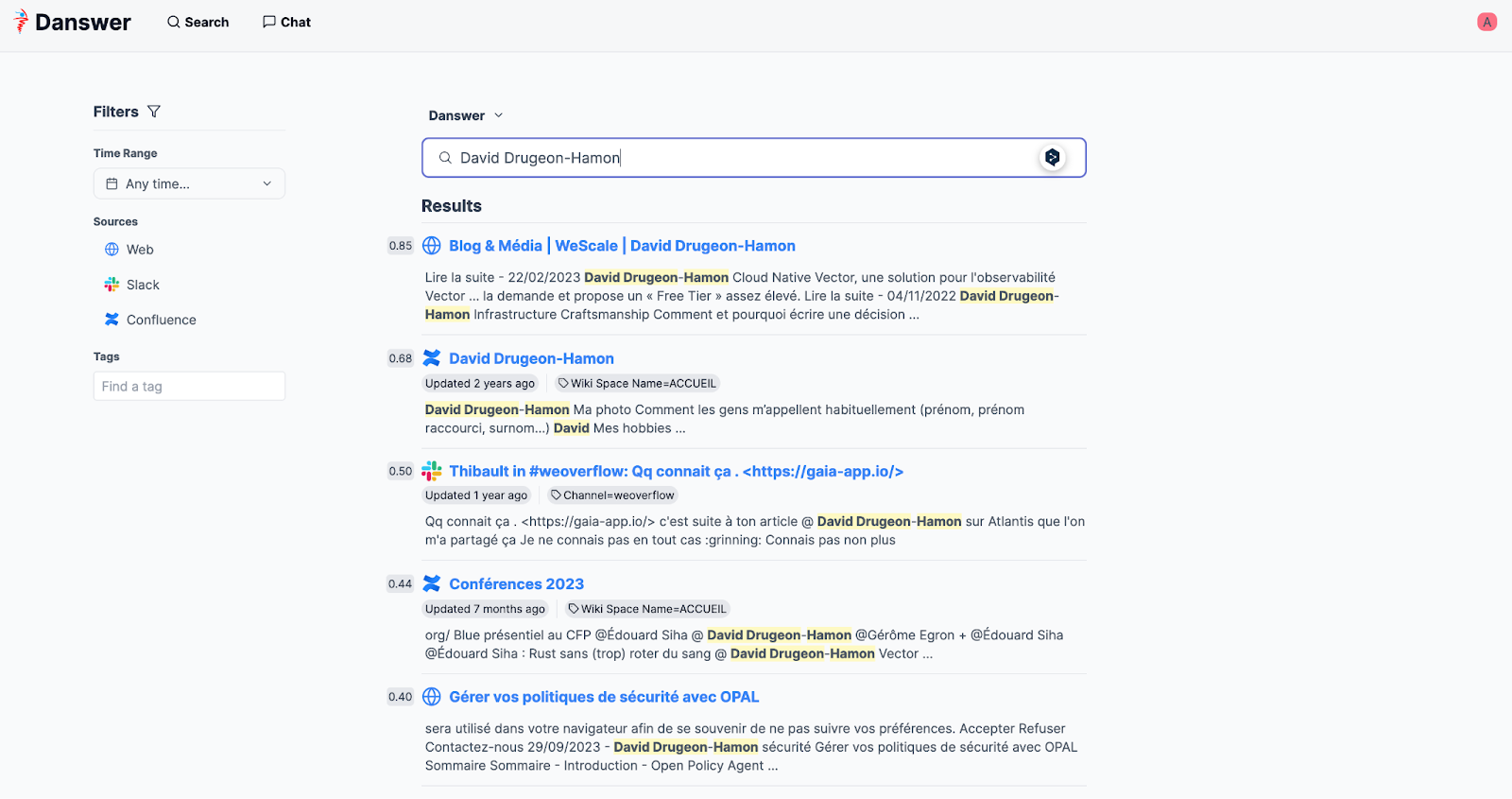
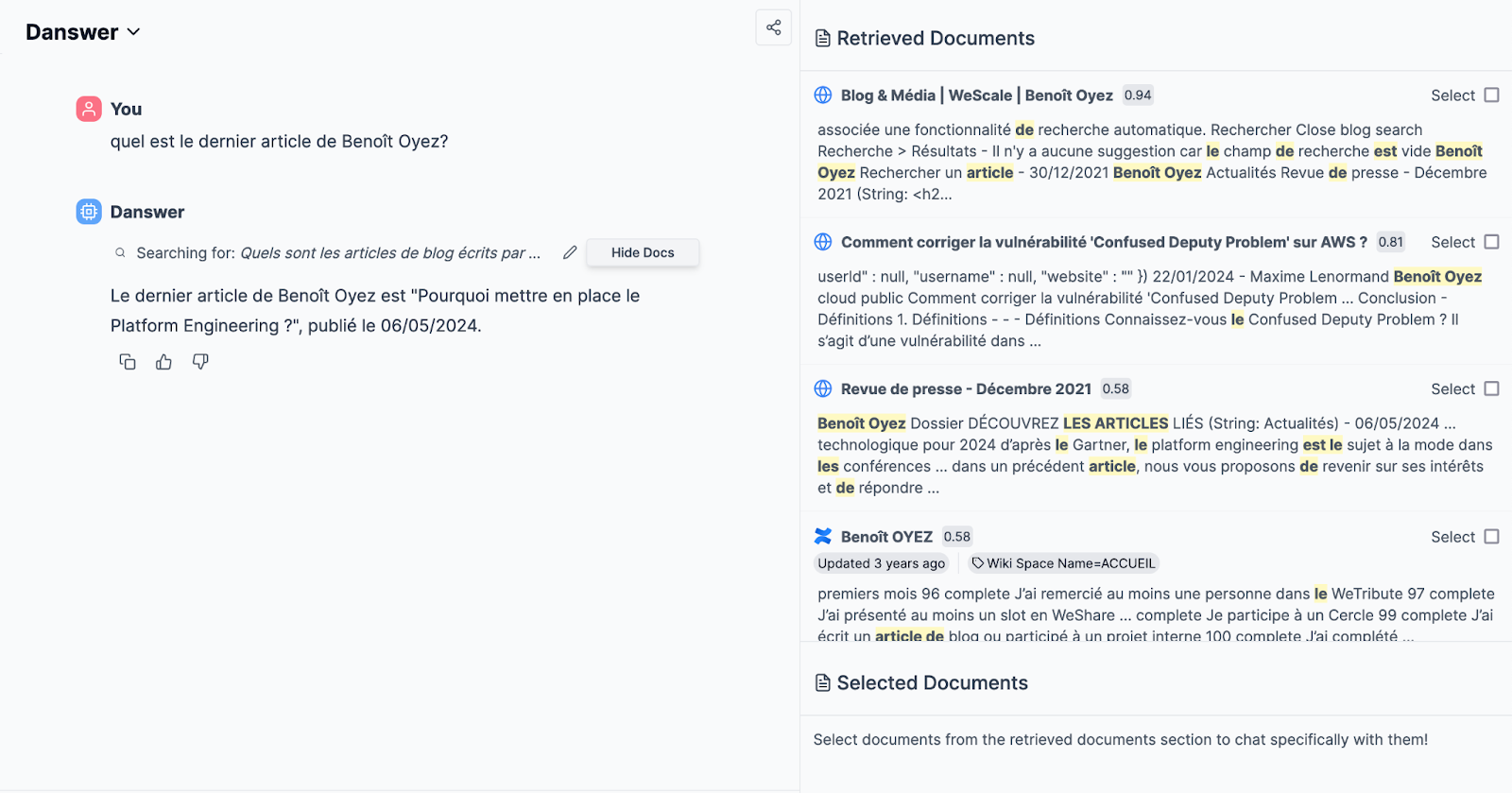
L’interface utilisateur propose un moteur de recherche mais aussi un agent conversationnel. Lors des interactions avec celui-ci, l’interface affiche le résultat de la recherche dans la base de données vectorielle. L’utilisateur peut alors retrouver les documents sur lesquels se sont appuyés le LLM pour répondre à l’utilisateur lorsqu’il génère sa réponse.
Dans cette configuration de base, nos données d’entreprise sont envoyées dans le contexte de la requête vers le LLM et donc à OpenAI.
Pour des raisons de confidentialité, nous préférons utiliser un LLM privé déployé dans notre infrastructure.
La version que nous avons mise en ligne ne permettait pas d’utiliser des LLM hébergés par un fournisseur de cloud. Nous devions donc trouver une solution simple pour déployer rapidement un LLM sur notre infrastructure.
Le projet Ollama (https://www.ollama.com) est devenu une solution pour exécuter des LLM en local sans dépendre d’un modèle hébergé uniquement sur le web. Il offre une interface en ligne de commande (CLI) pour télécharger et exécuter des modèles à partir de sa bibliothèque, tout en proposant une API Rest pour s’interfacer avec le LLM.
La bibliothèque de cet outil offre une grande variété de modèles open source de différentes tailles adaptables à diverses fonctions, tels que les modèles de Meta et Mistral.
Pendant que le programme fonctionne, Ollama adapte ses paramètres en fonction des spécifications matérielles de l’ordinateur. Il détecte la présence d’un GPU, par exemple, afin d’optimiser les performances. Par défaut, il utilise le CPU de la machine.
Outre l’exécution en mode binaire, Ollama peut également être lancé sous forme de conteneur. Il est important de noter qu’un plugin pour Docker sera nécessaire pour permettre l’accès au GPU (Nvidia uniquement pour l’instant).
DAnswer étant compatible avec Ollama, nous avons décidé de le déployer sur la même instance que les autres composants de la solution.
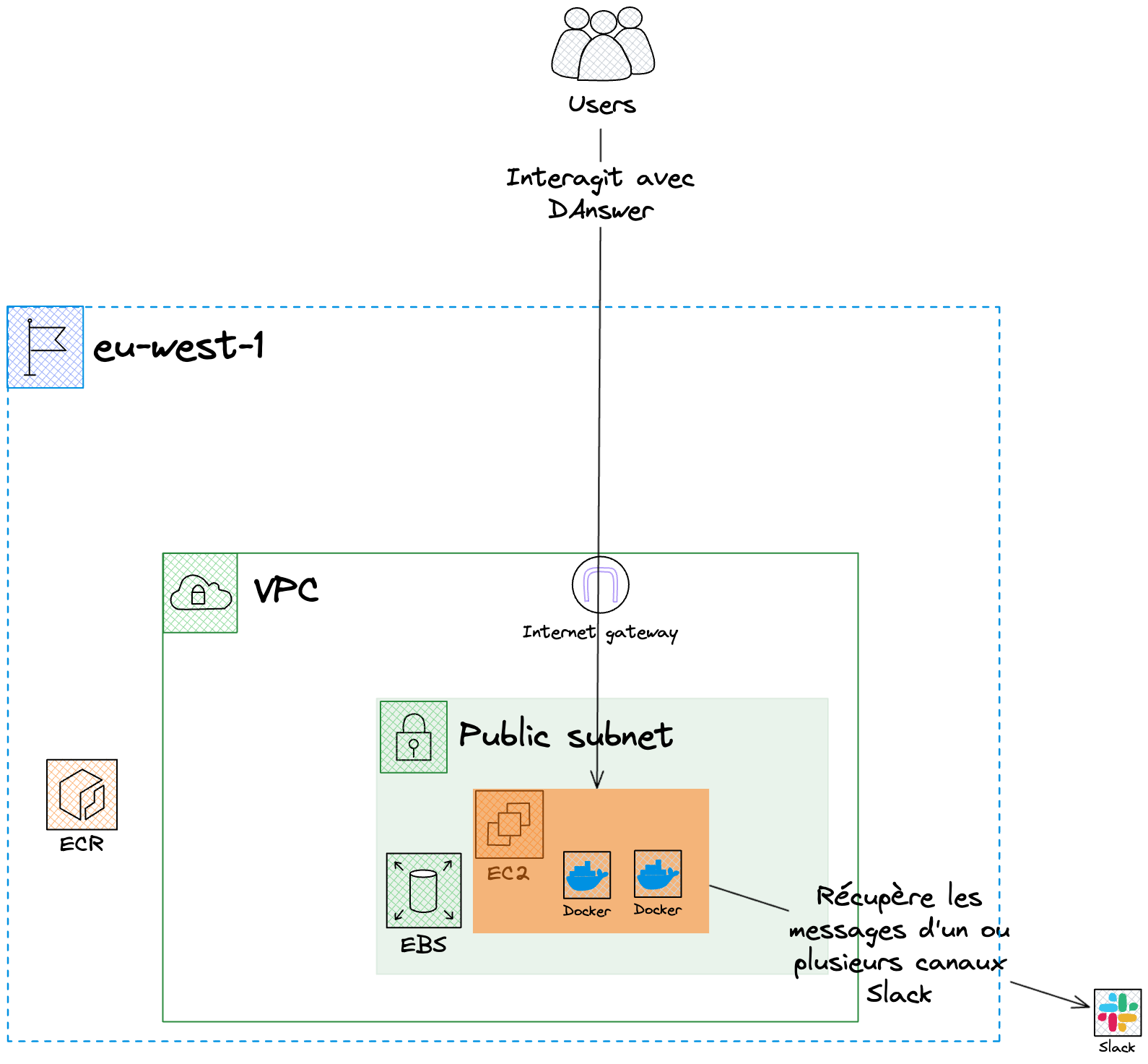
L'infrastructure est restée relativement inchangée, à l’exception de la disparition de la dépendance à OpenAI. Nous avons choisi le modèle de Meta, Llama 3.1 8b, (https://huggingface.co/meta-llama/Llama-3.1-8B) qui a montré de bonnes performances pour notre cas d’utilisation.
Bien que cette version soit opérationnelle, ses performances laissent à désirer. Autant l’indexation n’est pas affectée, autant la partie interaction avec le LLM en pâtit: les calculs demandés par le LLM sont trop importants pour obtenir une réponse de manière fluide. La plupart du temps, nous devions attendre près d’une minute pour obtenir une réponse du LLM.
Pour des raisons économiques, nous avons déployé la solution sur un serveur T4g.xlarge (Server Graviton 4 vCPU / 16 Gio). Pour améliorer les résultats, il serait judicieux d’allouer une instance spécifique à notre LLM local, optimisée pour un GPU, comme une instance G5g, par exemple.
Lors de l’hackathon, la version d’Ollama n’était pas multitâches. Cette contrainte ne permettait pas de déployer la solution à l’échelle pour la proposer à tous les membres de l’équipe.
Il était donc indispensable de choisir une solution de gestion pour déployer un LLM privé et pouvoir l’interroger.
AWS offre depuis la fin 2023 un ensemble de services managés permettant d’utiliser un LLM sous l'appellation AWS Bedrock.
Voici quelques exemples de modèles disponibles : Anthropic avec Claude, ceux de Mistral, ou encore ceux proposés par AWS.
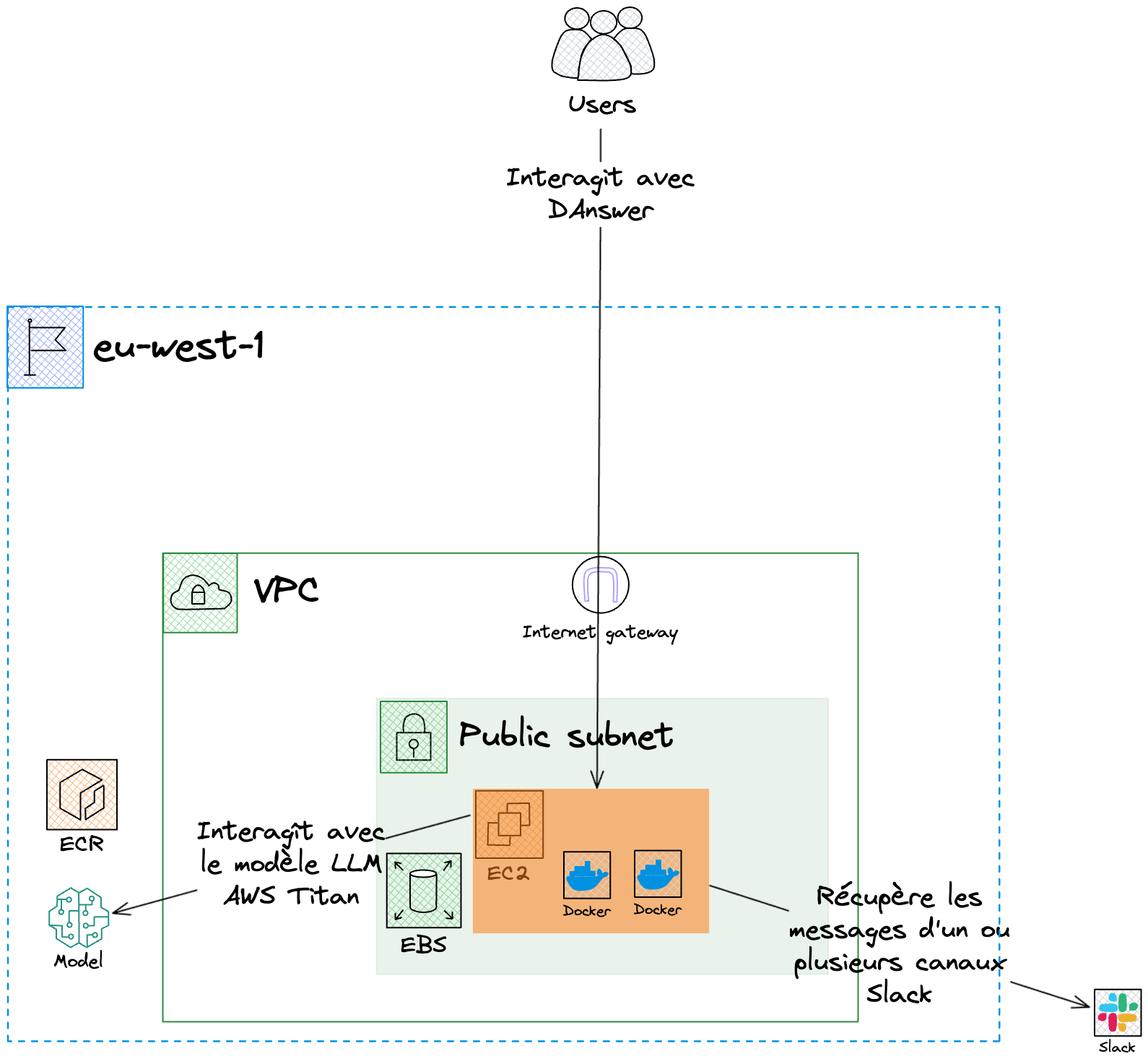
Grâce au déploiement des modèles sur le compte AWS, les données restent confidentielles. C’est un aspect crucial pour résoudre notre problème de confidentialité des informations.
La tarification se fait en fonction du nombre de jetons traités et créés, ainsi que du type de modèle de LLM utilisé.
Pour utiliser AWS Bedrock, vous devez activer le service sur votre compte et sélectionner un modèle de déploiement. Ensuite, vous devrez lui accorder des autorisations IAM.
Pendant le hackathon, le trafic était relativement faible, ce qui rend le coût de cette version insignifiant.
Au départ, l’application DAnswer n’était pas compatible avec Bedrock. Cette fonctionnalité a été développée par la communauté depuis notre première version.
Voici l’infrastructure déployée sur la troisième itération:
Grâce à Bedrock, les temps de réponse sont similaires à ceux de la première version. Notre infrastructure étant déployée sur la région de Paris, peu de modèles étaient disponibles au moment du déploiement. En plus de Claude d’Anthropic, seul le modèle d’AWS était disponible.
Nous avons choisi le modèle AWS Titan en raison de ses avantages financiers. Il est conçu pour des tâches telles que la création de contenu, la synthèse de textes, ou encore la rédaction d’agents conversationnels.
Les premiers résultats sont assez pertinents et sont comparables à ceux du modèle ChatGPT 3.5.
Lors de la journée de restitution, nous avons configuré DAnswer afin de montrer les capacités de notre assistant.
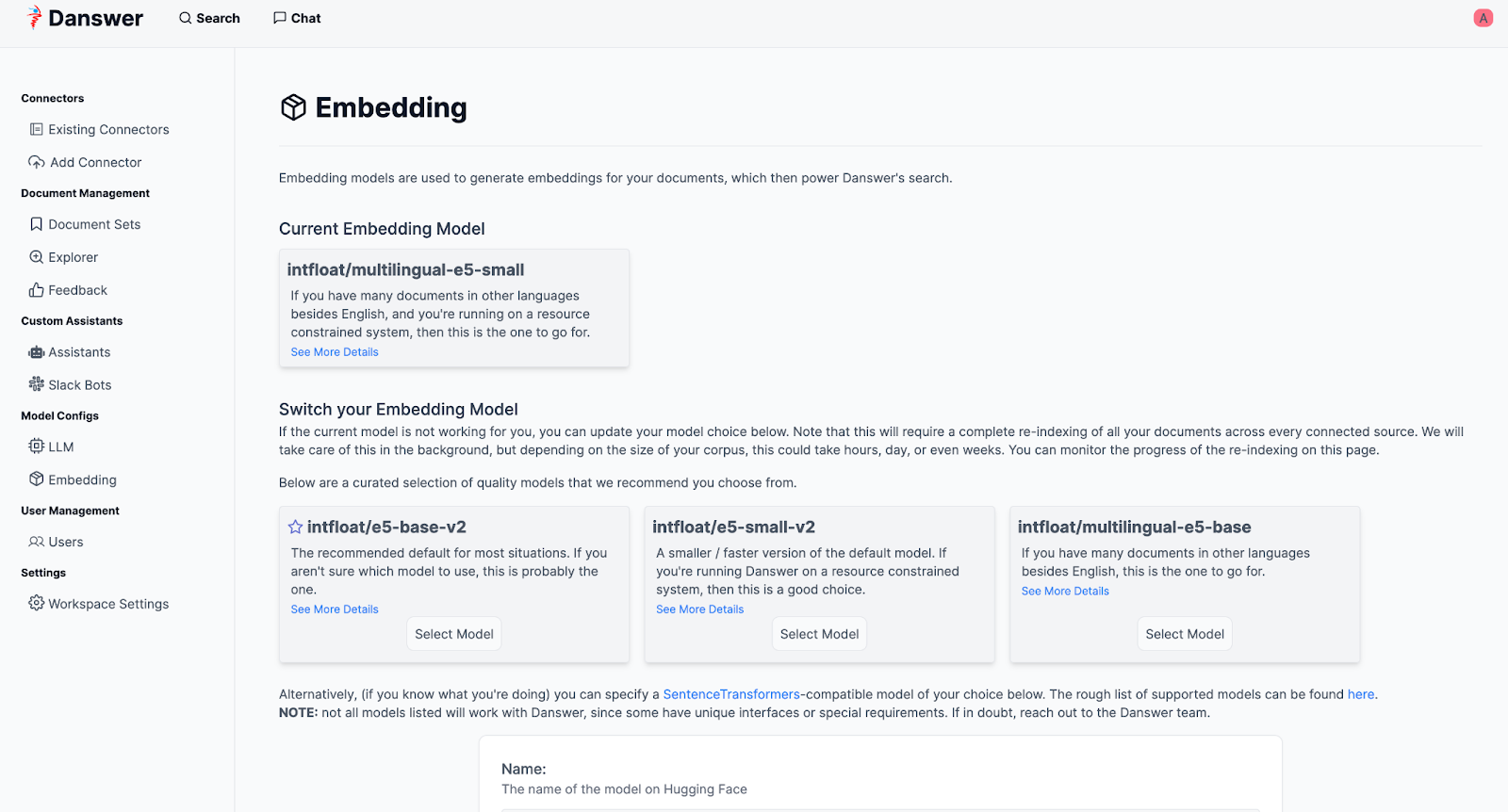
En ce qui concerne le modèle d’embeddings, DAnswer ne recommande que des modèles provenant de la plateforme communautaire Hugging Face.
Nos documents sont principalement rédigés en français. Nous avons choisi le modèle proposé par infloat, soit le multilingual e5 base (https://huggingface.co/intfloat/multilingual-e5-base).
Enfin, pour prouver les compétences de notre assistant, il faut configurer des sources de données.
Nous avons rendu l’assistant intéressant en configurant l’outil pour qu’il indexe non seulement certains canaux de notre Slack interne, mais aussi notre wiki et l’ensemble des articles de notre blog.
Une fois configuré, chaque connecteur ira automatiquement chercher les derniers documents dans sa source de données et les indexera.
Nous ne sommes pas allés plus loin dans la configuration de cet outil. Néanmoins, il est possible d’ajouter des agents qui répondront à certaines tâches spécifiques en personnalisant leur prompt, de restreindre la recherche à certaines sources de données en fonction de l’agent, etc.
Nous n’avons pas eu l’occasion de déployer l’agent conversationnel Slack qu’il propose.
Après avoir établi un fondement de connaissances, nous pouvons enfin nous connecter à la section utilisateur. Celle-ci se décompose en deux volets :
Dans notre article précédent, nous avons vu que l’administrateur peut modifier le prompt qui sera utilisé dans le chat. Cette fonctionnalité est cruciale pour assurer la pertinence de l’assistant.
Notre expérience lors de ce hackathon nous a fait comprendre les différents défis liés au développement et au déploiement d’un chatbot d’entreprise. Il y en a plusieurs, dont le choix du modèle de langage, la gestion de la confidentialité des données à traiter, l’optimisation des performances et du coût.
Ce projet nous a permis d’apprendre, de comprendre et de découvrir les dernières avancées en matière de traitement du langage naturel avec les LLM.
Grâce à l’outil DAnswer, nous avons pu réaliser un prototype d’assistant rapidement, mais nous sommes loin d’avoir une solution à déployer en production. Dans notre prochain article, nous allons examiner les pistes d’amélioration possibles pour que notre chatbot soit encore plus efficace.

Dans nos articles précédents, nous avons décrit la mise en place d’un agent conversationnel qui assiste nos collaborateurs dans leurs tâches...

Depuis peu et en se démocratisant, les modèles de langage comme ChatGPT, Claude ou Mistral, transforment profondément notre manière de coder. Il ne...
