 Akram BLOUZA
Akram BLOUZA
La technologie “blockchain”
Il est possible que vous ne puissiez pas passer à côté dans votre métier, et ceci beaucoup plus vite que ne vous le pensez.

Il s’agit d’un PaaS (Platform-as-a-Service) possédant une offre publique, ainsi qu’une version privée on-premise.
Avec Openshift, les développeurs possèdent un moyen simple pour construire, déployer et exécuter des applications dans des conteneurs.
Les deux premières versions d’OpenShift utilisent un moteur et un orchestrateur de conteneurs maison développés par RedHat.
À l'heure à laquelle j'écris cet article, la dernière version d'OpenShift, la version 3, est une évolution majeure de la solution puisqu'elle intègre maintenant le moteur de conteneurs Docker et l’orchestrateur Kubernetes.
Pourquoi RedHat a choisi Docker et Kubernetes pour remplacer leurs outils maison ? :
https://blog.openshift.com/technical-thoughts-on-openshift-and-docker/
et
https://blog.openshift.com/red-hat-chose-kubernetes-openshift/
Je vais traiter le sujet en plusieurs fois, et cet article en est la première partie. Mon objectif ici est de vous donner un aperçu de l’architecture OpenShift.
De mon point de vue, connaître l'architecture OpenShift ainsi que ses composants est un prérequis pour débuter avec le PaaS OpenShift 3.x, et les aspects pratiques que j’aborderai dans les prochaines parties.
OpenShift possède une architecture orientée microservices offrant un découplage important de ses services. On parlera aussi d'indépendance des services.
Chaque microservice peut :
Mais comment OpenShift a pu rendre ses services indépendants ?
RedHat a utilisé des solutions existantes pour construire cette architecture microservices tout en ajoutant d’autres briques.
Les ingénieurs chez RedHat ont mis en oeuvre Docker pour implémenter l'isolation des applications, ainsi chaque service est construit dans sa propre image. Ils ont aussi choisi Kubernetes pour orchestrer l’ensemble des conteneurs déployés dans OpenShift.
OpenShift propose trois stratégies de build d’une image Docker pour une application. La stratégie que je trouve la plus intéressante consiste à indiquer à OpenShift le chemin du gestionnaire de source de votre application, ainsi que le type de l’application (java, php, …) et grâce au mécanisme source to image d’OpenShift, l’image Docker est construite automatiquement. Nous aborderons plus en détails dans le prochain article de cette série ces différentes stratégies.
Chacun de ces environnements peut être déployé (conteneur Docker) de manière isolée dans un ou plusieurs pods appartenant au cluster Kubernetes d’OpenShift .
Dans OpenShift, il n’est pas possible de créer un conteneur sans son pod : le pod est l’unité la plus fine dans OpenShift.
Un pod possède sa propre adresse IP et les conteneurs qui sont présents dans un même pod partagent cette même adresse IP, ainsi que sa plage de ports .
Les conteneurs peuvent ainsi communiquer entre eux via localhost et peuvent utiliser les volumes pour partager les données.
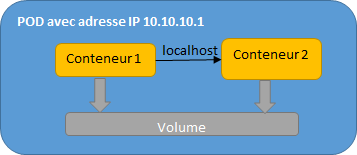
La scalabilité horizontale sera réalisée en instanciant l'application dans de multiples pods, ces derniers possédant leur propre contexte. La gestion des réplicas des pods est réalisée par le composant Replication Controller de Kubernetes.
Comme nous l’avons mentionné, un pod possède sa propre adresse IP, il n’est donc pas possible d’adresser la même application (dupliquée sur plusieurs pods) en passant par l’adresse IP.
La solution à cette problématique arrive ci-dessous.
Ainsi, il devient pratique d’utiliser le composant service de Kubernetes. Techniquement, il s’agit d’un load balancer interne permettant de router les appels d’une application vers l’un de ces pods. Un service possède sa propre adresse IP et un nom DNS.
Un service n’est accessible que depuis le cluster OpenShift et non visible depuis l’extérieur. Pour l’ouvrir depuis l'extérieur, une route doit nécessairement être créée.
La route OpenShift permet donc de relier le service d’un pod qui héberge votre application à une url externe.
Vous pourrez créer une route sécurisée ou non sécurisée. Le nom d'une route est hérité par défaut du nom du service de son pod.
Il existe toutefois une possibilité de changer ce nom à la création de la route.
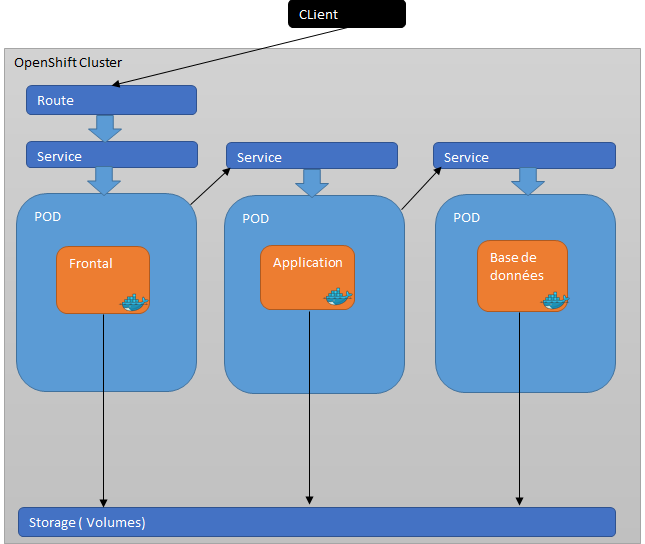
Voici un exemple simple d’architecture dans OpenShift d’une application classique en 3-tiers.
Chaque tiers est hébergé dans un pod différent et stocke les données persistantes dans un espace de stockage distribué. Pour communiquer avec le tiers application, le frontal doit passer par le service exposé au pod qui l’héberge. De la même manière, le tiers application doit passer par le service du pod qui héberge la base de données pour communiquer avec.
L’exposition de service par pod est nécessaire pour que les trois pods qui portent les tiers de l’application puissent communiquer.
Une route est exposée pour le service du pod qui porte le frontal. Ainsi, nous avons le frontal accessible depuis l’extérieur :
D’autres fonctionnalités intéressantes à connaître sont présentes dans Kubernetes :
À part les services de build et de routage, OpenShift a rajouté un service permettant l’agrégation des logs de tous les conteneurs du cluster. Il s’agit de EFK : Elasticsearch, Fluentd, Kibana.
Il y a aussi dans OpenShift une isolation complète des projets, de cette façon un pod d’un projet A ne peut pas communiquer avec un pod d’un autre projet. Nous bénéficions donc d’un cloisonnement fort des projets. Ceci est rendu possible grâce à l’approche software-defined network (SDN) proposée dans OpenShift.
Nous aborderons l’ensemble de ces composants techniques plus en détails, avec des cas pratiques, dans les parties suivantes.
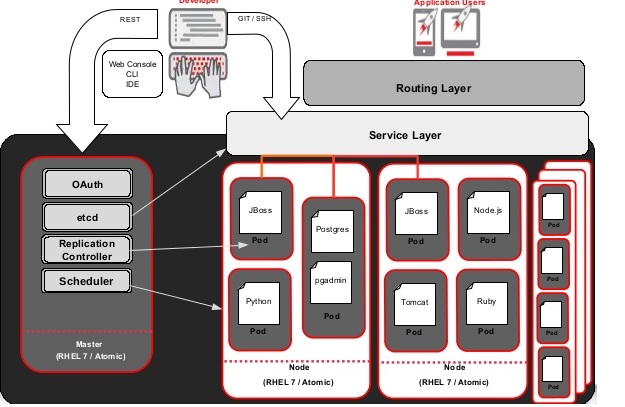
OpenShift est architecturé en un ou plusieurs masters et un ensemble de nodes.
Il s’agit d’une ou plusieurs machines physiques ou virtuelles possédant des composants OpenShift permettant la gestion des nodes et l’orchestration des pods qui sont logés au niveau des nodes. Il utilise l’annuaire distribué clé/valeur etcd pour le partage de la configuration et la découverte des services.
Un node fournit l’environnement d'exécution des conteneurs. Chaque node fournit les services essentiels pour qu’il soit visible depuis le master et pour qu’il puisse ainsi le gérer.
Voici un schéma complet de l’architecture OpenShift avec un master et plusieurs nodes.
Un développeur peut interagir avec OpenShift par plusieurs moyens : l’API Rest, la console Web ou l’OC Cli (command line interface) d’OpenShift. Toutes ses demandes passent forcément par le master qui orchestre leur transfert auprès du composant adéquat.
Maintenant que vous connaissez mieux les bases du fonctionnement des outils sous-jacents à OpenShift, nous allons pouvoir aborder la suite dans de prochains articles.
Ceux-ci seront l’occasion de voir avec des exemples pratiques les différentes stratégies de build, les différentes possibilités de configuration dans un déploiement (service, route, volume persistent …), les différents objets OpenShift, la sécurité …
À très vite pour la suite !
Il est possible que vous ne puissiez pas passer à côté dans votre métier, et ceci beaucoup plus vite que ne vous le pensez.
Qu’est ce que Knative ? Il serait faux de dire que Knative est un simple logiciel, car en fait Knative c’est aujourd’hui trois composants distincts...
