 Jérôme Devoucoux
Jérôme Devoucoux
Traefik 2.3 + ECS + Fargate : Reverse proxy serverless dans AWS
Mise à jour le 22/12/2021 Ce contenu a été mis à jour le 22/12/2021 pour pointer vers la version 2.5.5 de Traefik Proxy. La gestion d'ECS n'est...

Si vous voulez créer un cluster ElasticSearch de prod, il y a globalement deux méthodes.
Soit vous utilisez un service managé, dans ce cas là vous déléguez la configuration d'ES au provider (par exemple AWS ou Elastic Cloud).
Cette méthode est rapide et simple car elle permet de dédier la configuration du cluster au provider. Le problème est que vous allez payer ce service, donc cela reviendra sur la facture plus cher que de créer son propre cluster (à contrebalancer bien sûr avec les coûts de mise en place d’un tel système).
D’autre part, n’ayant pas totalement la main sur la configuration, vous serez confrontés à des limitations induites par ces services, potentiellement critiques pour l'application.
Vous ne pourrez pas non plus optimiser la plateforme sous-jacente afin de réduire les coûts.
Soit vous créez un cluster directement sur des serveurs, cette méthode demande plus d’expertise en interne, mais est rentable, car elle permet d’avoir accès à l’intégralité de la configuration d’ElasticSearch, ainsi qu’aux versions les plus récentes.
Elle permet également d’optimiser le plus finement possible les coûts et la gestion du cluster.
Le cas du logging est intéressant car aujourd’hui, il existe un certain nombre de services (comme Datadog, Loggly, Logmatic, etc.) qui prennent entièrement en charge la gestion des logs. Il vous restera à prendre en main l’outil mais l’administration d’ES est dans ce cas totalement gérée par le provider.
Si vous voulez gérer vos logs directement en service managé, c’est un bon choix, mais il faudra probablement ajouter des compléments au service d’AWS. Le curator, qui est un programme écrit en python qui permet notamment de supprimer les anciennes index, ne pourra pas être installé sur les machines. Il faudra créer par exemple des lambdas pour l’exécuter. Pour utiliser Logstash, qui permet d’ingérer un nombre conséquent de logs venant de différentes sources, vous devrez l’installer sur une EC2 et le connecter à votre service ES.
Si vous voulez créer un ElasticSearch pour stocker les données d’une application développée en interne, vous pourrez toujours vous poser la question d’utiliser le service managé AWS ou pas.
Dans ce cas là il faut vérifier si votre application a besoin de certaines fonctionnalités comme la possibilité de close/open ses index ou de faire du scripting inline, si c’est le cas il est utile de créer son propre cluster.
Mon objectif est donc de vous expliquer comment mettre en place un cluster ElasticSearch 6.X sur AWS, que vous configurez vous-même, ainsi que de vous présenter toutes les considérations à avoir pour répondre à des besoins de production :
résilience, sécurité, scalabilité, gestion des coûts, automatisation et performance.
C’est donc un choix pertinent lorsque vous voulez un cluster ElasticSearch optimisé, avec toutes les fonctionnalités d’ElasticSearch, plutôt adapté pour une application métier, quelqu’en soit sa configuration.
Afin d’assurer les besoins de production, nous allons accompagner ES de toute une série d’outils, qui, comme nous le verrons, ne doivent pas être laissés de côté.
Il peuvent évidemment être interchangés par d’autres outils équivalents, l’important étant de couvrir l’intégralité des services qu'ils assurent.
Nous prenons le parti d’utiliser directement des EC2 et non des conteneurs, cela se justifie dans notre cas, pour plusieurs raisons. D’une part nous allons créer des machines assez volumineuses avec un minimum de 4Gb pour héberger ES, ce qui ferait des conteneurs assez lourds. D’autre part, étant dans le cadre d’une base de données, nous voulons une gestion stateful de nos données, ceci est actuellement moins complexe à gérer en EC2 qu’en conteneurs.
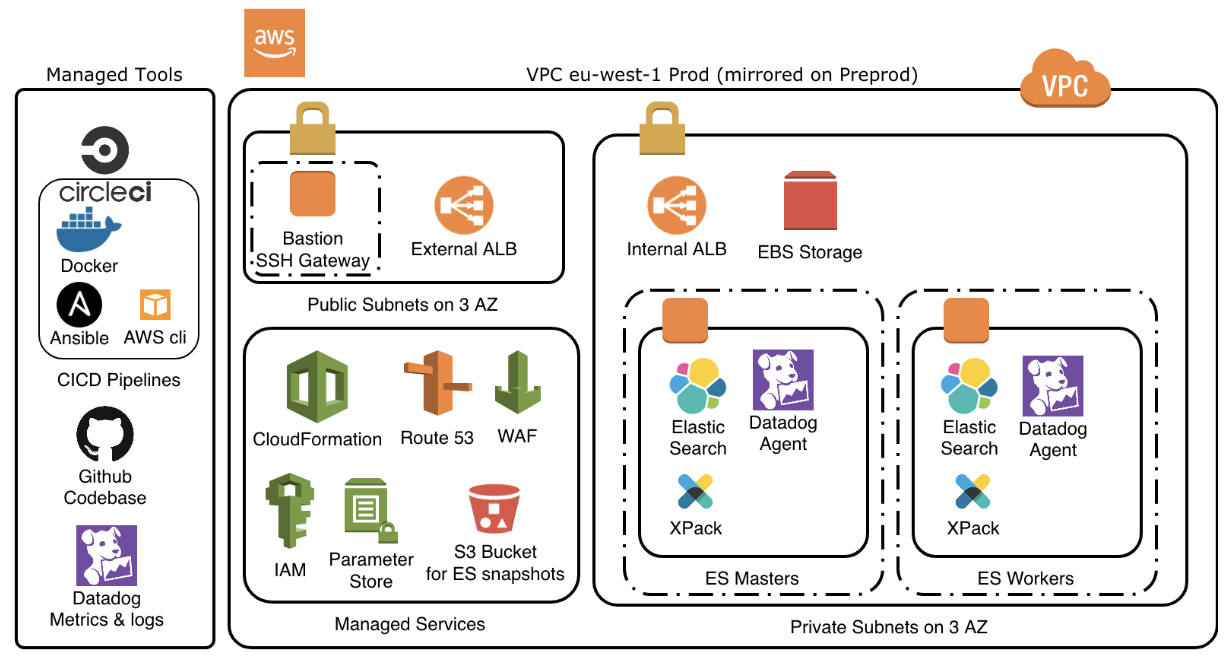
Nous allons présenter point par point les éléments qui constituent le cluster.
Les masters ElasticSearch servent à réceptionner et dispatcher les requêtes sur les workers ElasticSearch.
Un autoscaling group permet d’assurer la constitution d’un quorum (2n +1).
Ces machines seront très peu sollicitées en CPU, RAM et storage, par contre il faut assurer une bande passante réseau suffisante.
Un master leader unique centralise la gestion du cluster, les autres prenant la relève directement si le leader tombe.
Les workers ElasticSearch sont les data nodes, ce sont eux qui feront le travail d’indexation, et seront donc fortement sollicités en CPU, RAM et storage.
Un autoscaling group permettra d’adapter le nombre de workers à la charge effective du cluster.
Dans ce cadre vous aurez accès à toute la configuration d’ElasticSearch, vous pouvez récupérer la configuration par défaut qui est fonctionnelle puis l’adapter pour l’optimiser, notamment sur la gestion des shardings ou des réplications, ainsi que la gestion des plugins, comme Xpack.
Les ES Masters et workers sont des EC2 réparties sur différentes zones, chacune étant liée à un disque dur SSD EBS afin de gérer la persistance des données.
Un bucket S3 permet de stocker les snapshots d’ElasticSearch qui sont fait régulièrement afin de s’assurer que la base puisse être complètement restaurée en cas de problème.
L’IAC nous permet de construire toute l’infrastructure sous forme de code via Ansible et Cloudformation (piloté via l’AWS cli).
Le déploiement de cette infrastructure se fera à travers CircleCI.
Lorsque le code, stocké sur Github est validé, il sera exécuté via des conteneurs Docker sur CircleCI, qui pilotent la mise en place de l’infrastructure en suivant un workflow de CICD, depuis les tests d’intégration jusqu’au déploiement effectif.
Afin de surveiller l’état de santé des machines, nous mettons un agent Datadog sur chacune des EC2. Les métriques et les logs sont restitués sur l’interface de Datadog qui nous permet d’avoir des graphiques et de déclencher de l’alerting sur des événements.
L’API ElasticSearch est exposée via le service DNS d’AWS, Route 53, puis répartie sur les différents nodes master via les ALBs. Ceux-ci exposent l’API soit en interne dans AWS, soit sur internet, ce qui peut éventuellement être restreint à certaines IPs via le WAF.
Nous assurons la sécurité à différents niveaux. Tout d’abord nous découpons le VPC en subnets privés et publics, le public ne contenant que les éléments accessibles sur Internet et le privé les éléments que l’on souhaite protéger.
Le bastion, en zone publique, sert de passerelle SSH pour les tâches d’administration sur les serveurs. Nous utilisons également IAM pour gérer les différents accès via le client AWS et certains éléments du cluster. Nous utilisons de plus Parameter Store qui permet de stocker des paramètres confidentiels.
Une des premières choses que nous voulons garantir est que notre cluster soit toujours disponible.
Pour cela nous appliquons des bonnes pratiques pour assurer la haute disponibilité.
Nous faisons du multi-zones, pour répartir géographiquement les données entre plusieurs groupes de datacenters.
Le multi-master permet d'assurer que la chute d'un master ne soit pas critique pour le cluster.
Les différents workers prennent en charge le fait qu'un des workers peut tomber.
Les systèmes de réplication et de snapshot permettent de gérer les cas de pertes de données dans le cycle de vie du cluster.
La centralisation du monitoring et du logging permet de diagnostiquer rapidement les défaillances du système. On doit coupler ces systèmes à des mécanismes d'alerting qui permettent de réagir le plus rapidement possible.
On peut encore perfectionner les choses en assurant une réparation automatique du cluster en fonction des défaillances détectées, ce qui peut être testé en continu via des pratiques de Chaos Engineering.
La sécurité ne doit être en aucun cas négligée, cela passe par une analyse et une réduction de la zone d’attaque, le principe étant de limiter au maximum les droits que l’on accorde aux différents éléments, pour qu’ils aient accès uniquement à ce dont ils ont besoin.
Les droits IAM doivent donc être limités le plus possible pour chaque élément.
On stocke les instances qui hébergent les données sur les subnets privés du cluster.
Le bastion sert de passerelle d’entrée pour les accès SSH et sert de point d’entrée unique pour accéder à la plateforme depuis l’extérieur.
L’accès à AWS peut également être renforcé par du MFA.
AWS fournit également Cloudtrail qui permet d’auditer toutes les actions qui sont effectuées sur l’infrastructure.
Le service Trust Advisor peut être utile pour fournir des suggestions de sécurité sur le cluster.
La scalabilité est l’adaptation de la taille du cluster en fonction de la charge.
Cela passe notamment par les autoscaling groups qui permet d’augmenter ou réduire dynamiquement le nombre de workers ElasticSearch, en fonction de la sollicitation CPU et RAM.
Le réajustement des espaces disques est à gérer avec précaution. Pour cela on peut mettre en place un système de rolling upgrade qui permet de faire un roulement lors des changements de configuration, afin de ne pas avoir de perte de données et s’assurer que le système de réplication répartisse les données correctement sur les différents nodes.
La notion de scalabilité est fortement liée à l’optimisation des coûts car elle permet d’ajuster la consommation exactement au volume consommé, tout en restant dans une limite de budget maximum.
Le coût total de l’infrastructure doit être géré, si on prend les éléments choisis pour le cluster il y aura des factures venant de Github, CircleCI, Datadog et AWS.
Github et CircleCI représentent des coûts relativement fixes.
Pour Datadog il faudra optimiser le volume des logs et metrics envoyés, puis gérer une rétention qui pourra être déportée en archivage sur S3, puis Glacier via une policy.
Pour AWS, une interface de facturation permet de suivre les coûts de chaque composant.
Pour optimiser le coût des instances EC2 on peut utiliser les instances réservées ou les spot instances afin de diminuer les coûts par rapport au tarif de base en On Demand.
Pour approfondir le sujet, vous pouvez consulter l’article d’Aymen détaillant la facturation chez AWS.
L’infrastructure est construite sous forme de code, via CloudFormation pour les ressources AWS et nous utilisons Ansible pour la partie applicative. Ceci permet de versionner les modifications qui sont faites sur l’infrastructure, être capable de la reconstruire intégralement en cas de problème, ainsi qu’appliquer des méthodes de développement comme les tests de validation avant d’effectuer les déploiements. L’intérêt est aussi de pouvoir réutiliser et partager les techniques.
Les actions sont déclenchées par des événements Github (push, merge), et exécutées au niveau de CircleCI sur des conteneurs Docker. Ceci permet de respecter un workflow commun et d’assurer la compatibilité des programmes utilisés.
L’application qui communiquera avec ElasticSearch déterminera les métriques les plus critiques à observer sur le cluster : CPU, RAM, Espace Disque, Trafic réseau, etc.
Il faudra donc optimiser certains points selon les besoins de l’application.
Cela sera déterminé par le nombre et les types de machines, la taille des espaces disques, ainsi que la configuration d’ElasticSearch qui peut être optimisée.
Pour envisager une mise en production, la méthode que je recommande est de faire des tests de charge sur l’environnement de Preprod, les plus proches possible de ce que va recevoir l’application finale et seulement ensuite de faire la mise en production effective.
Nous avons vu pourquoi et comment mettre en place un cluster ElasticSearch non-managé sur AWS, à travers un exemple complet, puis nous avons évoqué les points à travailler pour que le cluster soit prêt pour un environnement de production.
Certains de ces aspects pourront être approfondis lors de prochains articles.
En attendant, il ne tient qu’à vous d’adapter ce cas d’usage pour vos besoins, d’approfondir ces outils (ou d’autres équivalents) pour construire votre propre cluster.

Mise à jour le 22/12/2021 Ce contenu a été mis à jour le 22/12/2021 pour pointer vers la version 2.5.5 de Traefik Proxy. La gestion d'ECS n'est...

Le cloud est l’un des sujets les plus en vue et discutés dans l’informatique, de plus en plus d’entreprises l’utilisent pour ses capacités à répondre...

Définitions Connaissez-vous le Confused Deputy Problem ? Il s’agit d’une vulnérabilité dans laquelle une entité qui n’a pas l’autorisation...