 Sébastien Lavayssière
Sébastien Lavayssière
Kubernetes : Utiliser Traefik comme LoadBalancer
Une solution que j’affectionne particulièrement est Traefik, car elle est simple à prendre en mains et propose suffisamment d’options pour ce que je...

J’ai voulu partager les différentes étapes par lesquelles je suis passé et qui m’ont permises d’atteindre l’objectif fixé. Chacun pourra s’inspirer d’une étape sans forcément suivre les autres, c’est une réponse à un cas particulier et non un tutoriel à suivre dans tous les cas.
Dans la suite de cette article, pour une simplification des explications, cette application prendra le nom de “app”.
Dans cet article, j’ai choisi de ne mettre que les lignes me permettant d’illustrer certains points. Vous n’y retrouverez donc pas l’ensemble des configurations et du code m’ayant servi à refactoriser le projet.
La première phase d’un projet est souvent la découverte de l’application. On doit se poser quelques questions pour pouvoir avancer par étapes.
Voilà quelques questions que je me suis posées dès le début en tant qu’opérationnel :
Quelques questions que je me suis posées en tant que développeur :
Bien sûr, il existe de nombreuses questions à se poser, mais celles-là me paraissent structurelles pour bien commencer mon audit.
Suite à ces questions, j’ai pu identifier quelques problèmes aussi bien fonctionnels qu’opérationnels :
Je devais également pouvoir tester que le front et le backend étaient bien stateless et donc que je pourrais dimensionner ces services en fonction du besoin.
Bref, du boulot en perspective.
Nous verrons ces étapes dans cet article :
Pour une question de coût et de facilité de mise en place, j’ai choisi de mettre en production sur Google Cloud Platform (GCP) et en particulier pour l’application sur Google Kubernetes Engine (GKE).
Le choix de Kubernetes fut également déterminé par la volonté de pouvoir intégrer d’autres applications dans le futur au sein de la même infrastructure, tout en diminuant le coût au maximum. Il était donc nécessaire de pouvoir densifier notre système d’information dès que possible. L’utilisation des conteneurs était également présente au coeur de cette application dès la phase de développement et permet également ce choix.
J’allais pouvoir utiliser la grande intégration de GCP au sein de Kubernetes pour accélérer la création de mon infrastructure, en particulier la gestion des volumes persistants et des services de type LoadBalancer. C’est également un service managé, je n’ai donc presque pas besoin de me préoccuper de la santé de ce cluster mais juste de lui allouer suffisamment de ressources.
L’utilisation de Google Container Registry (GCR), le repository de conteneurs privé chez Google, tombait également sous le sens dans ce cas d’utilisation.
Une bonne pratique aurait été d’utiliser Cloud SQL pour la gestion de ma base de données plutôt d’un conteneur. J’aurais économisé du temps lors de mes opérations mais c’est également un coût supplémentaire. Il sera possible de migrer vers cette solution si notre application devient très utilisée.
Conformément aux conclusions de mon audit, je devais séparer le conteneur unique en trois. L’objectif étant de gérer au mieux la scalabilité et la montée de version.
Le front est un processus configuré par Webpack qui permet de servir des fichiers presque statiques. Il nécessite néanmoins un conteneur “node” pour faire tourner le serveur.
Quelques modifications sont nécessaires pour permettre un découplage du front et du backend et en particulier l’ajout d’une variable d’environnement pour définir la route vers le backend.
FROM node:6.2
RUN mkdir -p /app
ENV API_URL http://localhost/api/v1
ENV PORT 80
EXPOSE $PORT
WORKDIR /app
COPY package.json /app/package.json
RUN npm install
COPY build /app/
CMD [ "node", "server.js" ]
Le backend est une application NodeJS, qui nécessite donc lui aussi le conteneur “node” en tant que parent.
Les modifications apportées sont principalement liées au développement.
Un point à noter est l’ajout de la configuration des éléments de connexion vers la BDD dans des variables d’environnements.
Sortir le script de migration de la base de données est essentiel dans le processus de mise à jour de mon application.
En effet, dans le cas où une mise à jour se ferait avec plusieurs instances du backend déployées, il y aurait un risque non nul de collision entre les différentes instances lançant en parallèle le script de migration.
Cela aurait pour conséquence au mieux un blocage de certaines instances et donc une dégradation du service, et au pire un état de base de données incohérent et donc une reprise d’activité depuis un backup.
Rien de complexe à réaliser dans ce cas, le développeur a bien fait son boulot et j’ai juste à lancer un conteneur héritant de “node” et qui appelle le script souhaité.
Un petit changement est nécessaire pour pouvoir faire passer les configurations de la BDD à l’instanciation du conteneur.
L’objectif étant de pouvoir récupérer les nouvelles versions du software au fur et à mesure de leur sortie, il était nécessaire de limiter les changements du code pour une simplification des unifications à venir, du moins tant que le changement fait n’est pas encore accepté par les développeurs de l’application.
Les modifications du front étant essentiellement esthétiques et fonctionnelles, il n’y a pas lieu de les énumérer ici.
Le seul point d’attention est de bien s’assurer que le lien vers le backend est défini via une variable d’environnement. Ici il s’agit de “API_URL“ que nous avons injecté dans le conteneur du front précédemment.
Pour cela nous pouvons utiliser le processus NodeJS qui récupère la variable d’environnement.
API_URL: process.env.API_URL
Un des principaux problèmes rencontrés avec le backend était l’ajout d’un préfixe dans l’url pour pouvoir faire un routage HTTP et indiquer la version de mon backend.
Bonne surprise, cela se fait sans difficulté grâce à la librairie Express qui assure le routage dans cette application NodeJS.
var router = express.Router();
UserRouter.register(router);
DomainRouter.register(router);
...
app.use('/api/v1', router);
app.listen(process.env.PORT || 8080, () => {
…
}
Le problème fonctionnel qui venait du manque de droit pour un nouvel utilisateur créé a été résolu par l’ajout d’une commande SQL supplémentaire.
Dans ce cas d’utilisation, la migration de la base de données se fait par une librairie NodeJS qui exécute une série ordonnancée de scripts fournis en enregistrant à chaque étape si le script a été un succès.
Le développeur doit donc fournir un script permettant la montée de version et un autre permettant le retour en arrière pour chaque changement.
Un des soucis que j’avais noté lors de ma découverte était l’absence d’utilisateur par défaut lors de l’initialisation de l’application.
Il me suffit donc d’ajouter une étape de création de l’utilisateur et de lui ajouter tous les droits :
INSERT INTO User (name, email, password) VALUES ('ADMIN','admin@app.fr', 'sha1(‘fakepassword’)');
INSERT INTO UserRole(user_id,roles_id) VALUES ((SELECT id FROM User WHERE email LIKE 'admin@app.fr'), 1);
...
INSERT INTO UserRole(user_id,roles_id) VALUES ((SELECT id FROM User WHERE email LIKE 'admin@app.fr'), 6);
et le script de retour arrière :
DELETE FROM UserRole WHERE User_id=(SELECT id FROM User WHERE email LIKE 'admin@app.fr');
DELETE FROM User WHERE email LIKE 'admin@app.fr';
Pour pouvoir tester mes modifications, j’ai du revoir le fichier docker-compose de l’application pour ajouter les variables d’environnement et un loadbalancer. J’ai choisi Traefik, un loadbalancer adapté aux conteneurs, qui les découvre en se basant sur leurs labels. De nombreux articles sur Traefik sont disponibles sur notre blog.
version: "3"
services:
loadbalancer:
image: traefik
command: --web --docker --logLevel=DEBUG
networks:
- backend
ports:
- 80:80
- 8080:8080
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /dev/null:/traefik.toml
db:
image: mysql:5.7
environment:
- MYSQL_ROOT_PASSWORD=admin
- MYSQL_DATABASE=app
- MYSQL_USER=app
- MYSQL_PASSWORD=app
ports:
- 3306:3306
labels:
- "traefik.enable=false"
networks:
- backend
back:
image: app/back:latest
links:
- db
networks:
- backend
environment:
- RDS_HOST=db
- RDS_USER=app
- RDS_PORT=3306
- RDS_DATABASE=app
- RDS_PASSWORD=app
expose:
- 8080
labels:
- "traefik.backend=back"
- "traefik.frontend.rule=Host:app-back"
dbmigrate:
image: app/dbmigrate:latest
depends_on:
- db
links:
- db
networks:
- backend
environment:
- RDS_HOST=db
- RDS_USER=app
- RDS_PORT=3306
- RDS_DATABASE=app
- RDS_PASSWORD=app
web:
image: app/front:latest
networks:
- backend
environment:
- API_URL="http://app-back:80/api/v1"
- PORT=80
expose:
- 80
labels:
- "traefik.backend=front"
- "traefik.frontend.rule=Host:app-front"
networks:
backend:
Pour lancer et tester la scalabilité de mes instances, il me suffit de lancer la commande suivante :
docker-compose up -d --scale back=2 --scale web=2
Le choix de création d’éléments d’infrastructure s’est rapidement tourné sur Terraform, c’est une solution très complète et qui a bien intégré GCP. De nombreux articles sur Terraform sont disponibles sur le blog.
L’objectif est de gérer uniquement la partie réseau, sécurité, ressources et cluster Kubernetes avec Terraform. Tout ce qui relève de l’architecture sera géré par Kubernetes.
La première chose à faire est de configurer Terraform pour GCP. Dans GCP il est possible, via IAM, de générer un fichier json lié à un compte de service pour authentifier celle-ci. J’enregistre celui-ci en local sous le titre de "wescale-site-credential.json". Premier réflexe à avoir : pensez bien à ajouter ce fichier dans votre “gitignore” ;-)
Ma configuration de mon projet :
variable "MOD_JSON_PATH" {
default = "wescale-site-credential.json"
}
variable "MOD_PROJECT" {
default = "wescale-site"
}
variable "MOD_REGION" {
default = "europe-west1"
}
provider "google" {
credentials = "${file("${var.MOD_JSON_PATH}")}"
project = "${var.MOD_PROJECT}"
region = "${var.MOD_REGION}"
}
Vous pouvez également exporter le contenu du fichier dans la variable d’environnement “GOOGLE_CREDENTIALS” avec la commande suivante. Terraform va vérifier le contenu de cette variable si le champ credentials est vide.
GOOGLE_CREDENTIALS=$(cat wescale-site-credential.json)
Enfin si vous utilisez la CLI “gcloud”, Terraform est automatiquement configuré avec vos droits utilisateurs une fois la connexion faite avec la commande/
gcloud auth login
Ensuite je crée un réseau “custom” c’est-à-dire sans génération automatique des sous-réseaux : "app-net", et je crée un sous réseau particulier "app-subnet".
J’attribue ensuite des règles firewall à ce réseau et donc j’autorise en TCP les ports suivants :
Enfin, je crée un Persistent Disk, c’est-à-dire un bloc de stockage géré par GCP, que j’utiliserai pour persister les données de ma base. Je crée un bloc de seulement 20 Go mais cette taille est suffisante pour le peu de données de l’application.
resource "google_compute_disk" "app-1" {
name = "app-1"
type = "pd-standard"
zone = "europe-west1-b"
size = "20"
}
On peut noter que Kubernetes dans GCP peut également créer son Persistent Disk automatiquement à la création du Persistent Volume.
Enfin le cluster Kubernetes se crée facilement :
resource "google_container_cluster" "app-cluster" {
name = "app-cluster"
zone = "${var.MOD_REGION}-b"
initial_node_count = 1
network = "${google_compute_network.app_net.name}"
subnetwork = "${google_compute_subnetwork.app_subnet.name}"
...
}
Une fois ce projet Terraform lancé, j’ai les ressources disponibles pour lancer l’architecture.
Pour récupérer mes credentials de connexion Kubernetes, GCP me fournit un outil simple :
gcloud container clusters get-credentials "app-cluster" --zone europe-west1-b
L’objectif de ce chapitre est de regarder l’architecture nécessaire à cette application et définie dans Kubernetes.
Il faut déjà configurer quelques éléments dans Kubernetes pour les utiliser ensuite dans mon application. Ces éléments pourront également être utilisés par plusieurs autres applications de mon cluster.
Pour lier mon PersistentDisk créé avec Terraform dans GCP, je dois créer un PersistentVolume dans Kubernetes. Ce lien permettra à Kubernetes de créer ensuite des PersistentVolumeClaim dans cette ressource.
apiVersion: v1
kind: PersistentVolume
metadata:
name: app-pv-1
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
gcePersistentDisk:
pdName: app-1
J’ai choisi de déployer Traefik comme IngressControler. C’est un outil complet qui permettra de résoudre certains problèmes dont je parlerai après.
Dans un premier temps, je vous invite à suivre la documentation, très bien faite, disponible ici si vous souhaitez le déployer.
Dans le cas de ce tutoriel, le type de “Service” est défini à “NodePort” dans ce cas j’utilise plutôt un type “LoadBalancer” de manière à laisser GCP gérer la distribution du trafic entre les différents “Node”. Ce service de type “LoadBalancer” me permet également de lui lier une adresse IP persistante.
Cette adresse IP fixe me permettra de lier un nom de domaine à ce service. De plus, lors d’un redimensionnement de mon cluster il sera à la charge de GCP de modifier la configuration et ce sera donc transparent pour moi.
kind: Service
apiVersion: v1
metadata:
name: traefik-ingress-service
namespace: kube-system
spec:
selector:
k8s-app: traefik-ingress-lb
type: LoadBalancer
ports:
- port: 80
name: web
- port: 8080
name: admin
- port: 443
name: web-secure
J’ajoute également le port 443 me permettant de rendre accessible mon site en HTTPS.
Lors de la création de Kubernetes, le namespace kube-system est créé pour les applications relevant de l’administration du cluster. On y retrouve de nombreuses applications implémentées par GCP dans ce cas.
Je vais créer deux namespaces : un pour mon application et un pour le monitoring du cluster et de ses applications.
apiVersion: v1
kind: Namespace
metadata:
name: app-namespace
L’objet est identique au nom près pour le namespace “monitoring”.
Par défaut dans Kubernetes toutes les communications réseaux sont permises, je commence donc par un DenyAll sur toutes les connexions.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
namespace: app-namespace
spec:
podSelector: {}
policyTypes:
- Ingress
Enfin, j’ajoute le secret de ma base de données, pour cela je lance la commande suivante :
kubectl create secret generic app-db-mysql --from-file=password.txt
Dans le cas de la création d’un secret en utilisant cette méthode, une erreur fréquente est d’ajouter, sans le savoir, un saut de ligne. Certaines applications vont l'interpréter de façon différentes !
Pour déployer le front j’utilise un objet Deployment :
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: app-front-deployment
namespace: app-namespace
spec:
template:
metadata:
labels:
app: app
tier: front
spec:
containers:
- env:
- name: API_URL
value: '''https://app.wescale.fr/api/v1'''
image: eu.gcr.io/wescale-site/app-front:0.0.1
name: app-front
ports:
- containerPort: 80
name: app-front
J’utilise aussi un objet HorizontalPodAutoscaler pour dimensionner mes pods. Pour l’instant je ne dimensionne mon service qu’en fonction de la charge CPU. C’est lors de l’utilisation que je saurai quand le produit doit vraiment se redimensionner. C’est une approche pragmatique que je choisis ici.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: app-front-hpa
namespace: app-namespace
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: app-front-deployment
targetCPUUtilizationPercentage: 80
Un service permet de rendre accessible mon front.
apiVersion: v1
kind: Service
metadata:
labels:
app: app
name: front-svc
namespace: app-namespace
spec:
ports:
- port: 80
targetPort: 80
selector:
app: app
tier: front
sessionAffinity: None
A noter que seul le port 80 est disponible dans l’application. La gestion du certificat SSL est donc reportée à l’IngressControler.
En terme de sécurité, j’applique une NetworkPolicy permettant à mon front d’être accessible depuis l’IngressController.
Pour l’instant les NetworkPolicy ne permettent pas de cibler un Pod dans un autre namespace. J’autorise donc toutes les connexions depuis le namespace kube-system. C’est une limitation qui devrait être levée dans les prochaines versions de Calico.
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: access-front
namespace: app-namespace
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
name: kube-system
podSelector:
matchLabels:
app: app
tier: front
policyTypes:
- Ingress
Pour déployer le backend j’utilise un objet Deployment :
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: app-back-deployment
namespace: app
spec:
replicas: 1
template:
metadata:
labels:
app: app
tier: back
spec:
containers:
- env:
- name: RDS_HOST
value: app-db-mysql
- name: RDS_USER
value: appdbuser
- name: RDS_PORT
value: "3306"
- name: RDS_DATABASE
value: app
- name: RDS_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-password
name: app-db-mysql
image: eu.gcr.io/wescale-site/app-back:0.0.1
name: app-back
ports:
- containerPort: 8080
J’utilise le secret pour connecter mon backend à la base de données.
Le service est très semblable à celui du front ainsi que le HPA.
La NetworkPolicy doit permettre l’accessibilité depuis l’extérieur du cluster. Le front est exécuté côté client en Javascript et les requêtes ne viendront pas de mes pods front mais bien de mes IngressControllers. J’utilise donc un namespaceSelector et je rends accessible le backend depuis le namespace kube-system.
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: access-back
namespace: app-namespace
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
name: kube-system
podSelector:
matchLabels:
app: app
tier: back
policyTypes:
- Ingress
Le déploiement de la BDD est différent sur plusieurs aspects par rapport aux autres applications vues précédemment.
Premièrement, je souhaite faire persister les données, je dois donc créer un PersistentVolumeClaim.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: app-db-mysql
namespace: app-namespace
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: standard
Je dois lier ensuite le volume /var/lib/mysql, dans lequel mysql stocke ses données d’après la documentation.
La mise en place du “readinessProbe” et du “livenessProbe” permettra de corréler les états de Kubernetes avec les états de la base. En cas d’erreur fonctionnelle de la base, elle sera également redémarrée automatiquement.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: app-db-mysql
namespace: app-namespace
spec:
replicas: 1
strategy:
rollingUpdate
template:
metadata:
labels:
app: app-db-mysql
spec:
containers:
- image: mysql:5.7
name: app-db-mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-root-password
name: app-db-mysql
- name: MYSQL_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-password
name: app-db-mysql
- name: MYSQL_USER
value: dbuser
- name: MYSQL_DATABASE
value: app
ports:
- containerPort: 3306
name: mysql
livenessProbe:
exec:
command:
- sh
- -c
- mysqladmin ping -u root -p${MYSQL_ROOT_PASSWORD}
readinessProbe:
exec:
command:
- sh
- -c
- mysqladmin ping -u root -p${MYSQL_ROOT_PASSWORD}
resources:
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- mountPath: /var/lib/mysql
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: app-db-mysql
Le “Service” lié à ce déploiement est très simple également. La NetworkPolicy est définie pour permettre le lien entre le backend et la base de données.
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: access-bdd
namespace: app-namespace
spec:
ingress:
- from:
- podSelector:
matchLabels:
app: app
tier: back
podSelector:
matchLabels:
app: app-db-mysql
policyTypes:
- Ingress
Le cas de la migration BDD est différent des cas des autres conteneurs. Il faut le lancer une fois, soit à la création de la BDD soit au moment d’une migration, et ne pas le monitorer en continu.
Un objet Kubernetes permet de n’être exécuté qu’une seule fois : le Job. Le cas le plus courant d’utilisation étant un CronJob.
Ici je peux donc lancer ma commande une seule fois pour créer ou migrer la database. Attention à ne pas oublier la NetworkPolicy pour permettre la connexion à la base.
apiVersion: batch/v1
kind: Job
metadata:
name: db-migrate-job
namespace: app-namespace
spec:
template:
metadata:
name: db-migrate-job
spec:
containers:
- name: db-migrate
image: eu.gcr.io/wescale-site/app-dbmigrate:0.0.1
restartPolicy: Never
Pour rendre mes services accessibles depuis internet je dois faire un lien entre l’IngressController et le loadbalancer extérieur géré par celui-ci.
La règle d’Ingress doit permettre d’accéder au front et au backend et donc router les paquets arrivant avec le nom de mon site vers le front pour toutes les requêtes sauf celles portant sur “/api/v1” qui doivent être routées au backend.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: traefik
name: app-ingress
namespace: app-namespace
spec:
rules:
- host: app.wescale.fr
http:
paths:
- backend:
serviceName: back-svc
servicePort: 8080
path: /api/*
- backend:
serviceName: back-svc
servicePort: 8080
path: /api
- backend:
serviceName: front-svc
servicePort: 80
path: /
- backend:
serviceName: front-svc
servicePort: 80
path: /*
Traefik peut gérer une mise à jour des certificats SSL de manière automatique grâce à Let’sEncrypt et j’ajoute également à la configuration une redirection de http vers https.
Il est possible de gérer la redirection avec une règle ressemblant à une “rewrite url” sinon la redirection est par défaut sur “/”.
Pour déployer la configuration de Traefik, je crée une ConfigMap.
apiVersion: v1
kind: ConfigMap
metadata:
name: traefik-conf
namespace: kube-system
data:
traefik.toml: |
defaultEntryPoints = ["http","https"]
[entryPoints]
[entryPoints.http]
address = ":80"
[entryPoints.http.redirect]
entryPoint = "https"
[entryPoints.https]
address = ":443"
[entryPoints.https.tls]
[acme]
acmeLogging = true
email = "moi@wescale.fr"
storage = "acme.json"
entryPoint = "https"
onDemand = false
OnHostRule = false
[acme.httpChallenge]
entryPoint = "http"
[[acme.domains]]
main = "app.wescale.fr"
Puis je modifie le déploiement de Traefik, en ajoutant dans les arguments au lancement du conteneur la lecture du fichier de configuration.
- args:
- --api
- --kubernetes
- --logLevel=INFO
- --configfile=/config/traefik.toml
Puis j’insère la ConfigMap dans un volume et je le monte dans “/config” :
volumeMounts:
- mountPath: /config
name: config
volumes:
- configMap:
name: traefik-conf
name: config
L’application est maintenant accessible depuis internet sur HTTPS !
Je dois maintenant monitorer l’application, pour cela j’ai déployé un Prometheus et un Grafana.
Le déploiement de ces deux produits n’est pas décrit ici pour ne pas alourdir l’article, mais vous trouverez un exemple ici.
J’ajoute dans la configuration de Traefik, c’est à dire dans ma ConfigMap, les lignes ci-dessous.
[metrics]
[metrics.prometheus]
Pour m’assurer de la découverte de mon Pod par Prometheus, j’ajoute l’annotation suivante dans les metadatas de mon template dans mon Deployment de Traefik.
annotations:
prometheus.io/scrape: "true"
Après un ajout d’un dashboard dans Grafana.
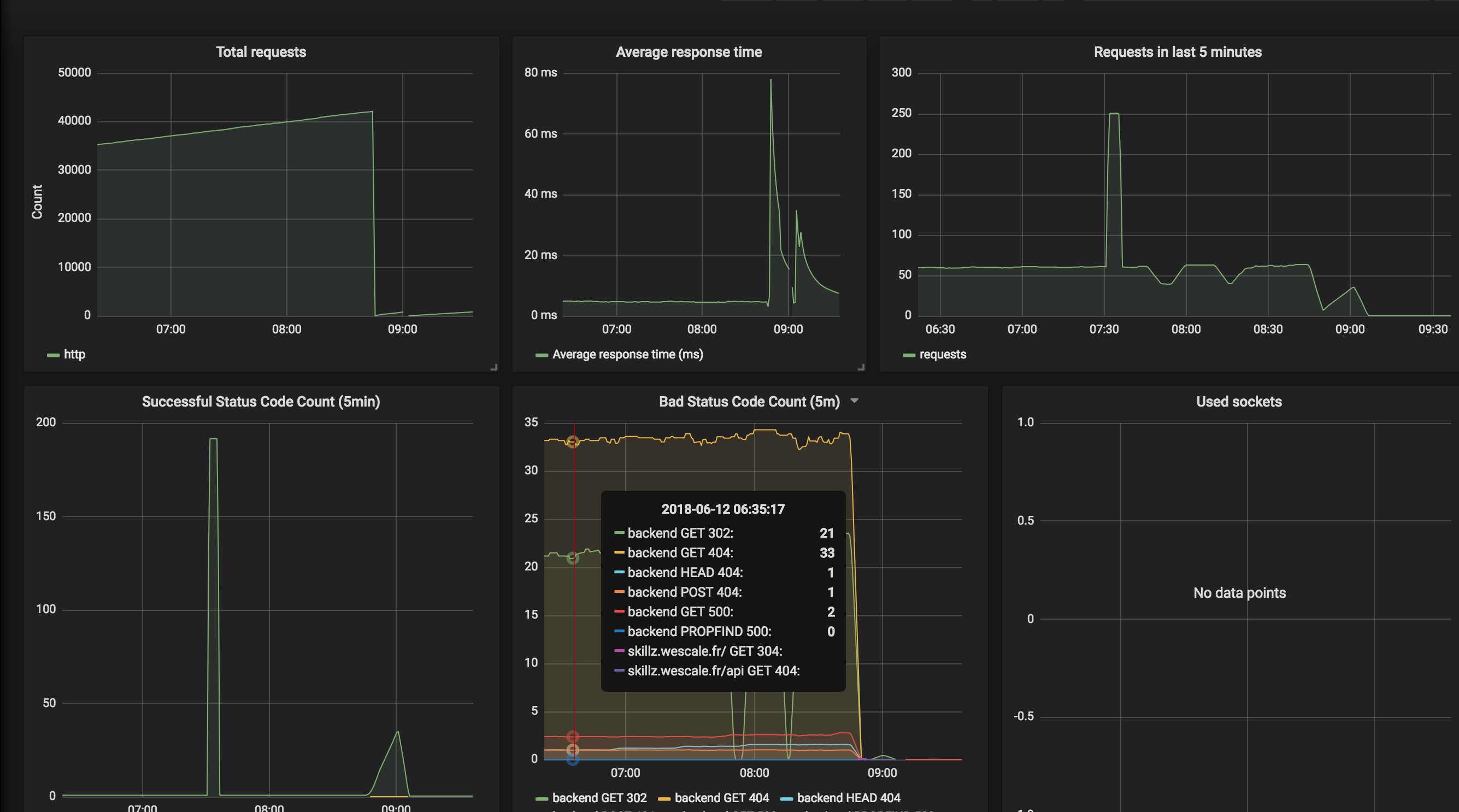
Pour la base de données, j’ajoute au déploiement de la base un nouveau conteneur qui contient un “mysqld_exporter”.
Ce conteneur Docker hérite de “prom/mysqld-exporter:master” mais ajoute un script permettant de définir chaque variable de la chaîne de connexion indépendamment. Le conteneur par défaut propose la forme suivante pour la chaîne de connexion : “DATA_SOURCE_NAME='user:password@(hostname:3306)/'“.
- image: eu.gcr.io/wescale-site/my-prom-mysql:master-v4
name: prom-mysql
env:
- name: MYSQL_USER
value: root
- name: MYSQL_PASSWORD
valueFrom:
secretKeyRef:
key: mysql-root-password
name: app-db-mysql
- name: MYSQL_HOST
value: localhost
- name: MYSQL_PORT
value: "3306"
- name: MYSQL_DB
value: app
ports:
- containerPort: 9104
Pour la découverte et le paramétrage de Prometheus, il faut ajouter les annotations suivantes dans le Deployment de ma base de données.
template:
metadata:
annotations:
prometheus.io/path: /metrics
prometheus.io/port: "9104"
prometheus.io/scrape: "true"
Après l’ajout d’un dashboard InnoDB trouvé dans le GitHub de Percona.
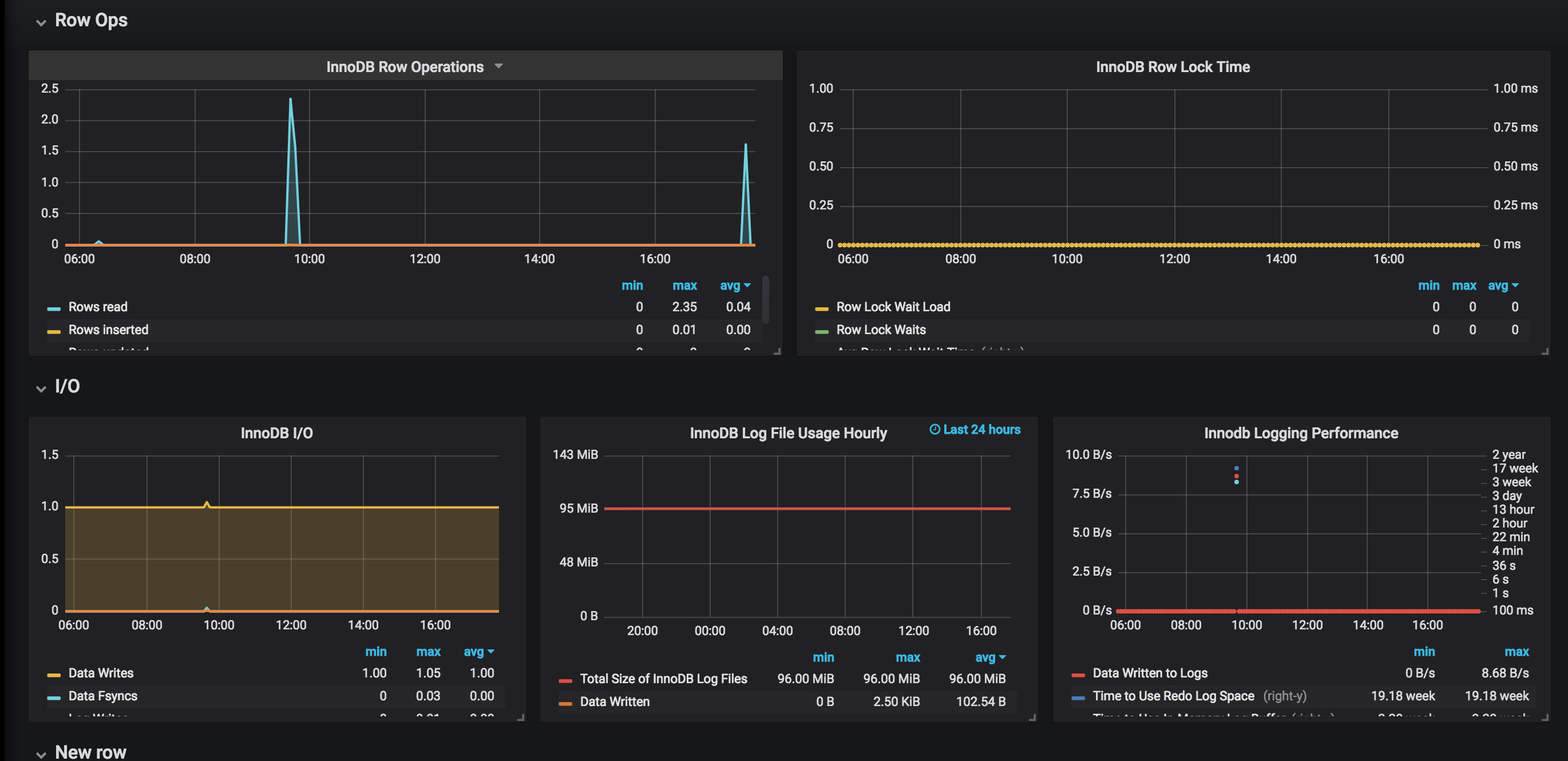
Cette application est maintenant en production depuis quelques semaines et je n’ai pas de problème pour le moment.
Voyons quels seraient les axes d’amélioration possibles :
Ce que cette expérience nous montre c’est la nécessité de respecter dès le début certaines bonnes pratiques de développement qui m’ont permis de réaliser cette conversion.
L’ajout d’un architecte et d’un membre d’une équipe SRE/DevOps/Ops permettra de prévoir les besoins de production et d’accélérer le travail des équipes en amont comme en aval du projet.
L’utilisation de Kubernetes et GCP dans ce cas est un gain de temps, de stabilité mais également de facilité dans la mise en place.
J’espère que cet article vous a plu, qu’éventuellement vous avez appris des choses et encore mieux qu’il vous aura donné envie de nous rejoindre !
Une solution que j’affectionne particulièrement est Traefik, car elle est simple à prendre en mains et propose suffisamment d’options pour ce que je...

Introduction Le sujet de la sécurité, et en particulier la gestion des accès et des autorisations, est traité dans certaines compagnies qui migrent...
