{kind=link}
Réinventer le Serverless avec Knative
Qu’est ce que Knative ? Il serait faux de dire que Knative est un simple logiciel, car en fait Knative c’est aujourd’hui trois composants distincts...
4 minutes de lecture

Si vous désirez utiliser OpenShift dans un cadre de production, son installation nécessite une réflexion pointue sur plusieurs sujets notamment : implémentation (on premise versus cloud), stockage, réseau, ressources nécessaires, authentification et autorisation, monitoring…
Cette installation avancée utilise les playbooks ansible que vous trouverez dans Github.
L’objectif de cet article est de simuler une installation avancée dans une infrastructure de production “on premise” ou en cloud privé de production.
L’idée est d’avoir une architecture qui se rapproche le plus de la cible. L’architecture que je vais implémenter est la suivante : un seul master et plusieurs nœuds.
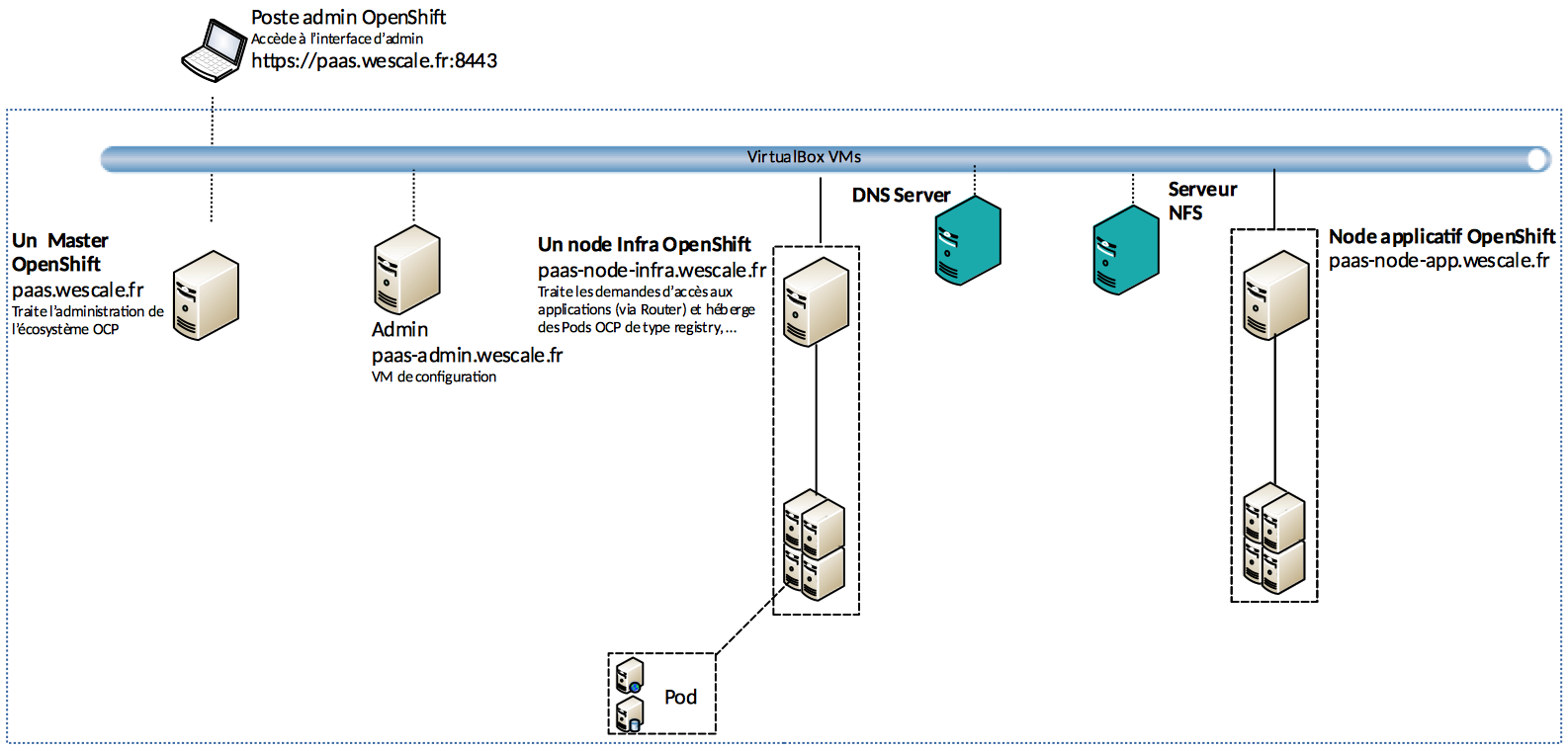
Notre cluster sera composé de cinq VMs :
VM d’admin : il s’agit de la VM qui servira à configurer et à installer le cluster OpenShift.
VM Master : les composants permettant la gestion du cluster OpenShift s’installeront ici. Dans un cadre de production, et pour assurer la haute disponibilité, il est préconisé d’installer au minimum trois instances du Master réparties sur plusieurs sites.
VM d’un noeud d’infra : le routeur OpenShift sera installé dans le nœud d’infra qui s’occupera du traitement des demandes d’accès aux applications. Le registry OpenShift est aussi hebergé au niveau de ce nœud, comme la partie logging et monitoring.
Dans un cadre de production, et pour assurer la haute disponibilité d’accès aux applications, il est conseillé d’avoir au minimum trois instances du nœud d’infrastructure répartis sur plusieurs sites.
VM d’un nœud applicatif : les applications seront hébergées au niveau d’un nœud applicatif.
Dans un cadre de production, et pour assurer la haute disponibilité des applications, il est conseillé d’avoir au minimum deux instances du nœud applicatif réparties sur plusieurs sites.
VM serveur NFS : il s’agit du serveur de stockage persistant. Il n’est pas géré par OpenShift. Dans un cadre de production, il est conseillé d’utiliser un serveur de stockage déjà existant dans votre infrastructure ou d’installer un nouveau tout en garantissant sa haute disponibilité et sa visibilité depuis le cluster OpenShift. Dans le cadre de cet article, j’ai configuré NFS au sein d’une VM pour simuler le stockage persistant. Il est toutefois possible d’utiliser l’un de ces providers de stockage: Gluster FS, OpenStack Cinder ou Ceph RBD.
Choisir le meilleur type de stockage correspondant à votre besoin est un sujet à part que je détaillerai dans un article à part.
Prérequis:
1.Installation de VirtualBox et Vagrant:
Nous utiliserons Vagrant avec VirtualBox pour provisionner l’ensemble des VMs du cluster OpenShift. L’installation de VirtualBox est détaillée ici et celle de Vagrant ici.
2.Installation des plugins Vagrant:
Nous allons installer les plugins suivants : vagrant-hostmanager et landrush.
Le plugin hostmanager met à jour le fichier /etc/hosts lors du provisionnement ou de la destruction des VMs Vagrant.
Le plugin landrush quant à lui permet de fournir un serveur DNS aux VMs Vagrant. Une fois que l’installation est terminée, n’oubliez pas de démarrer le serveur DNS en lançant la commande vagrant landrush start.
3.Provisionner les VMs:
Faites un git clone depuis github au projet Vagrant : advanced install OpenShift.
Monter l’infrastructure OpenShift en lançant :
vagrant up
4.Configuration du serveur NFS:
Le détail d’installation d’un serveur NFS est ici
Lancer l'installation:
Dans la VM d’admin, clonez le repo ansible d’OpenShift https://github.com/openshift/openshift-ansible , faites un checkout sur la release 3.7 et executer /home/vagrant/deploy.sh.
Ce script permet de générer et copier les clés ssh aux différentes vms puis de lancer l’installation avec :ansible-playbook /home/vagrant/openshift-ansible/playbooks/byo/config.yml
Si l’installation se passe bien, le résultat est :
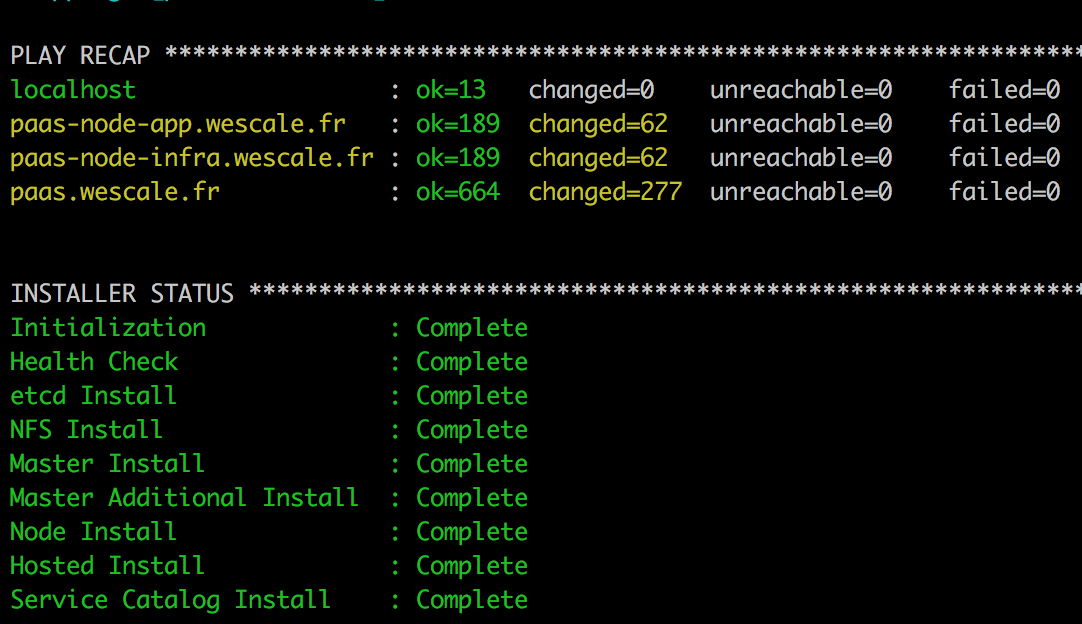
La préparation des VMs pour l’install OpenShift est faite à son provisionnement, et plus précisément dans un Vagrantfile.
Au niveau de toutes les VMs:
yum -y install git wget net-tools bind-utils iptables-services bridge-utils bash-completion kexec-tools sos psacct nfs-utils
Au niveau du master, noeud d’infra et applicatif:
sudo yum -y install centos-release-openshift-origin37
Au niveau de la VM d’admin:
sudo yum -y install atomic-openshift-utils
Un inventory ansible etc_ansible_hosts est présent au niveau du repo et il est copié au provisionnement de la VM d’admin dans /etc/ansible/hosts. Il s’agit de l’inventory utilisé dans la construction de notre cluster OpenShift.
Au niveau de l’inventory, j’ai positionné :
Le groupe OSEv3 qui contient l’ensemble des machines masters et nodes.
L’ensemble des variables permettant de customiser l’installation. Dans notre cas, nous avons choisi :
Au niveau du master :
$ oc login -u system:admin --config=/etc/origin/master/admin.kubeconfig
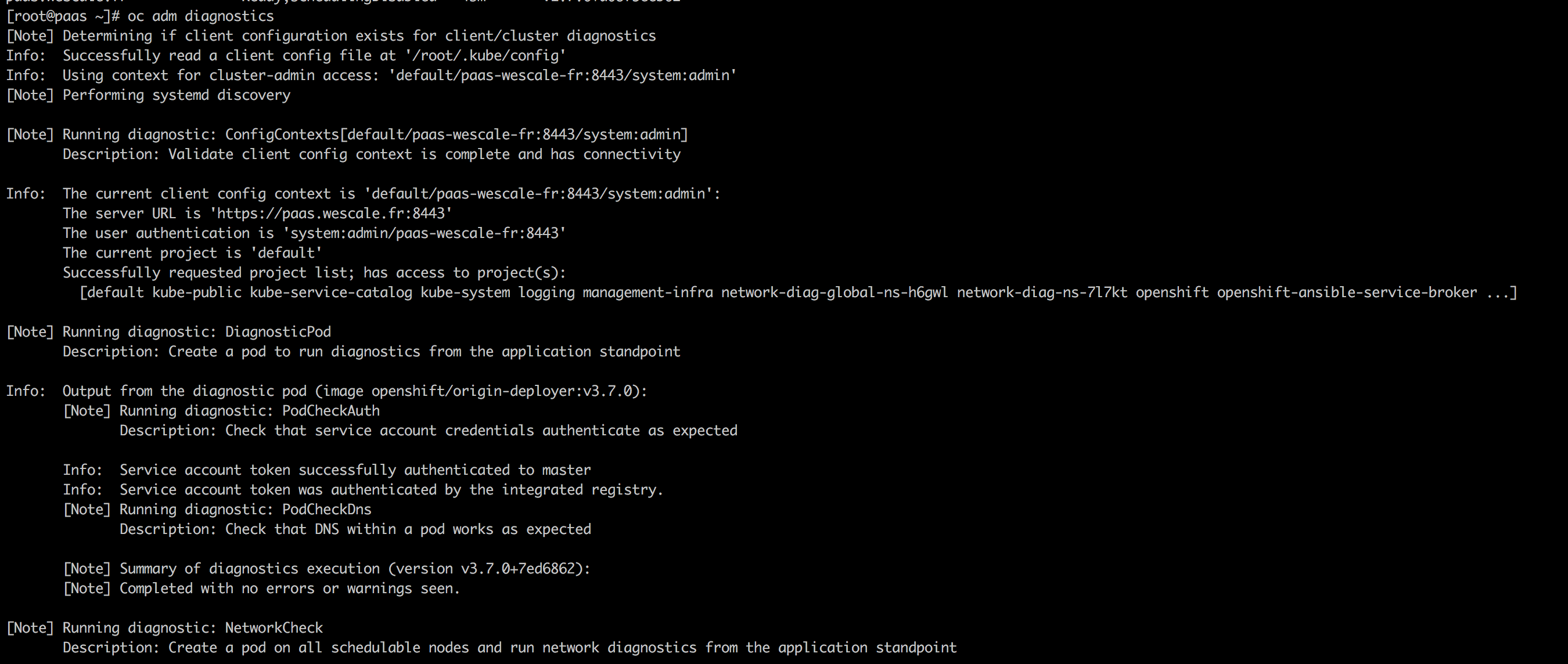
$ oc adm diagnostics
qui effectue l'ensemble des vérifications suivantes:
Une partie du résultat que vous devez avoir:
$ oc get nodes

$ htpasswd -b /etc/origin/master/htpasswd wescale wescale
$ oadm policy add-cluster-role-to-user cluster-admin Wescale

Autres vérifications :
Vérifier l'accès à la console OpenShift
https://paas.wescale.fr:8443/console
Tester l’authentification wescale/wescale:

Dans cet article, je vous ai montré que la méthode utilisée en production pour installer OpenShift est similaire à celle utilisée pour l’installer sur votre ordinateur.
Ceci permettra de valider au préalable la configuration souhaitée de votre cluster avant de l’appliquer sur l'infrastructure cible et ainsi fiabiliser vos déploiements.
Image d'illustration de l'article par DigitalOcean. Lien de l'image originale ici
Qu’est ce que Knative ? Il serait faux de dire que Knative est un simple logiciel, car en fait Knative c’est aujourd’hui trois composants distincts...

Dans un précédent article nous présentions Google Cloud Shell, un environnement de développement provisionné à la demande sur le Cloud.Sa...

Introduction Dans l’article Les outils incontournables pour accélérer votre utilisation de K8s !, nous avons découvert l’utilisation de K9s...