 David Drugeon-Hamon
David Drugeon-Hamon


Prometheus Starter Kit
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...

Vector est une solution permettant de collecter des données d'observabilité (traces, fichiers journaux et métriques) depuis différentes sources de données, pour les transformer avant de les envoyer vers une ou plusieurs systèmes externes comme par exemple des outils d'observabilité ou SIEM.
Créé par la société Timber.io pour améliorer l'ingestion des logs vers leur plateforme, cet outil écrit en Rust a été mis en code ouvert depuis 2020 sous licence Mozilla Public Licence v2. Depuis le rachat de cette société par Datadog, il est intègré dans l'offre Datadog pour définir et superviser des pipelines de données d'observabilité. Ce projet se veut agnostique de la plateforme qui indexe ces données.
L'observabilité nous permet de comprendre l'état d'un système en analysant les données produites sous différentes formes. Un des problèmes les plus communs est que ces données sont produites dans différents formats. Il est ainsi difficile de pouvoir les analyser efficacement.
Pour donner un exemple concret, lorsqu'une requête HTTP est envoyée sur une infrastructure classique, différents composants peuvent être sollicités. Chaque composant génère une entrée dans son fichier journal dans un format spécifique (load balancer, serveur web, cache, serveur d'application).
Nous avons donc besoin d'un outil qui permet d'agréger ces données dans un format commun (généralement au format JSON pour faciliter l'indexation), ou qui permet de supprimer des données sensibles avant l'indexation.
Un autre besoin récurrent est de pouvoir envoyer les données d'observabilité vers différentes solutions : envoyer vers un bucket S3 les données brutes pour archivage, vers Datadog pour les métriques et traces et vers Elastic pour les fichiers journaux.
De même, toutes les données ne sont pas nécessaires à l’exploitation de nos infrastructures de production.. Par exemple, nous pouvons envisager de router certaines données issues des infrastructures de développement ou de pré-production vers un système dédié. Ou encore éviter d'envoyer les logs au niveau DEBUG pour réduire les coûts engendrés.
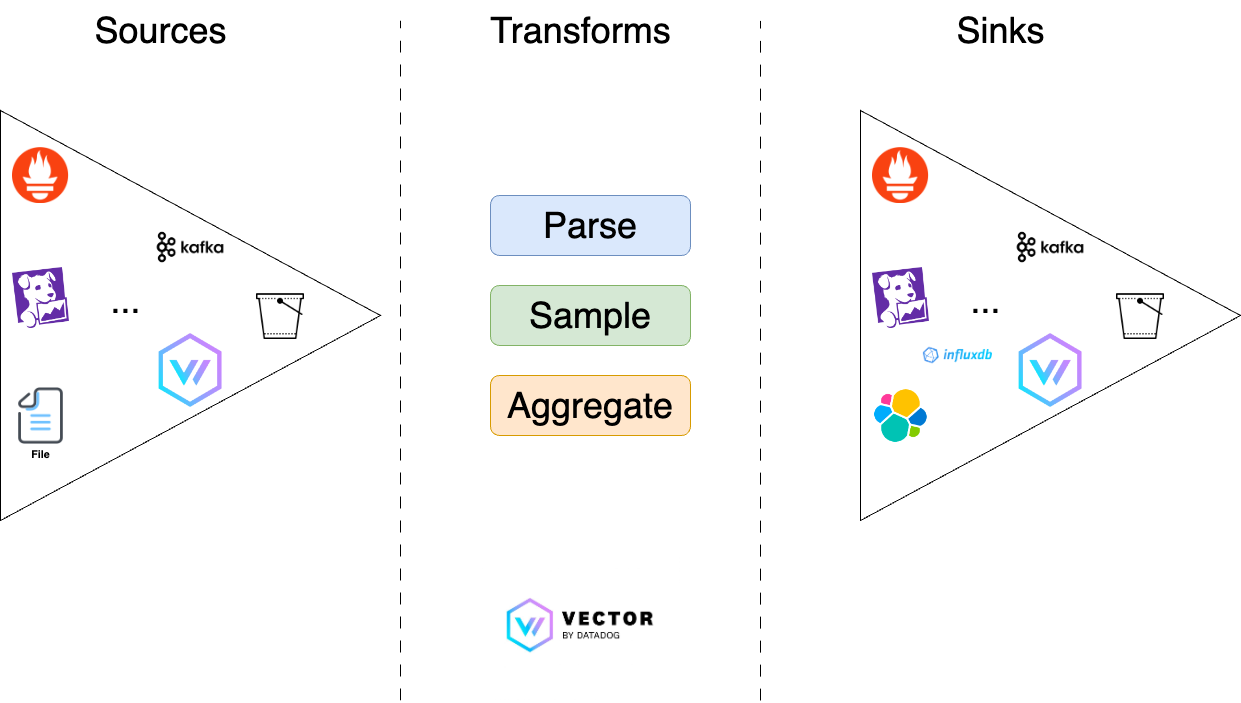
Pipeline d’observabilité
C'est ce qui définit un pipeline de données d'observabilité. Dans la terminologie propre à Vector, nous avons trois étapes nécessaires pour les définir :
Pour pouvoir réaliser ces étapes de transformation, Vector réalisera un décodage de la source de données pour obtenir une représentation interne et uniformisée sous forme d'évènements. Nous pourrons alors réaliser des opérations à l'aide de fonctions prédéfinies et d'un langage spécifique (VRL ou Vector Remap Language). A noter que nous pouvons définir plusieurs étapes de transformation qui serviront à envoyer les données vers différentes destinations.
La définition des pipelines se fait à l'aide d'un ou plusieurs fichiers de configuration au format TOM, YAML ou JSON. Dans l'exemple suivant issu de la documentation officielle, nous définissons le pipeline suivant :
# Set global options
data_dir = "/var/lib/vector"
# Vector's API (disabled by default)
# Enable and try it out with the `vector top` command
[api]
enabled = false
# Ingest data by tailing one or more files
[sources.apache_logs]
type = "file"
include = ["/var/log/apache2/*.log"] # supports globbing
ignore_older = 86400 # 1 day
# Structure and parse via Vector's Remap Language
[transforms.apache_parser]
inputs = ["apache_logs"]
type = "remap"
source = '''
. = parse_apache_log(.message)
'''
# Sample the data to save on cost
[transforms.apache_sampler]
inputs = ["apache_parser"]
type = "sample"
rate = 2 # only keep 50% (1/`rate`)
# Send structured data to a short-term storage
[sinks.es_cluster]
inputs = ["apache_sampler"] # only take sampled data
type = "elasticsearch"
endpoints = ["http://79.12.221.222:9200"] # local or external host
bulk.index = "vector-%Y-%m-%d" # daily indices
# Send structured data to a cost-effective long-term storage
[sinks.s3_archives]
inputs = ["apache_parser"] # don't sample for S3
type = "aws_s3"
region = "us-east-1"
bucket = "my-log-archives"
key_prefix = "date=%Y-%m-%d" # daily partitions, hive friendly format
compression = "gzip" # compress final objects
framing.method = "newline_delimited" # new line delimited...
encoding.codec = "json" # ...JSON
batch.max_bytes = 10000000 # 10mb uncompressed
Vector est un agent multi-plateforme. Il peut être ainsi déployé directement sur une machine Linux, Windows ou Mac ou sous forme de conteneur. Dans ce cas, il peut être déployé à l'aide d'un orchestrateur de conteneurs comme Kubernetes ou encore AWS Elastic Container Service. Il existe principalement trois modèles d'architecture pour l'intégrer dans nos infrastructures.
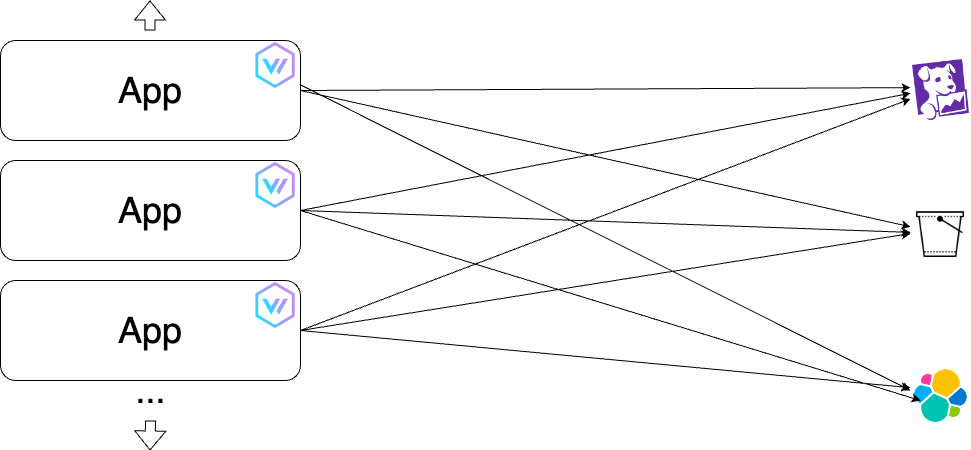
Architecture décentralisée
Dans cette solution, nous déployons un agent Vector par machine hôte ou en sidecar de nos conteneurs applicatifs. C'est la solution la plus simple. Elle convient pour des infrastructures relativement simples et cette solution s'adapte au nombre de machines ou conteneurs déployés.
Un des principaux écueils de ce modèle est que nos systèmes d'observabilité seront fortement sollicités en fonction du nombre de machines ou conteneurs déployés. De plus, les données traitées par Vector sont stockées dans une mémoire tampon qui sera perdue si l'instance ou le conteneur est supprimé.
Architecture basée sur les flux de données
Ce modèle est basé sur des flux de données tels qu'Apache Kafka, AWS Kinesis. Dans cette solution, des agents Vector sont toujours déployés au plus près de la source des données et les publie dans un Topic Kafka / Kinesis. Un ou plusieurs agents Vector sont alors déployés sur des hôtes spécifiques et jouent le rôle d'agrégateur. Ils s'abonnent au Topic pour récupérer les données au fil de l'eau afin de les transformer et les envoyer aux différentes destinations.
Cette architecture est la plus robuste et la plus scalable pour le déploiement de Vector au sein de nos infrastructures. De plus, elle permet de récupérer les données déjà publiées dans le topic Kafka en cas de problème sur nos agents agrégateurs.
Malheureusement, cette solution ajoute de la complexité, de la gestion et des coûts supplémentaires.

Architecture centralisée
Dans ce modèle, un agent Vector est toujours déployé au plus près des sources de données puis les envoie vers un ou plusieurs agents Vector qui serviront d'agrégation des données. Ces agents contrôlent toutes les sources pour efficacement les router vers la bonne destination.
Ce modèle est un compromis entre le modèle décentralisé et le modèle basé sur les flux de données. Néanmoins, nous perdons la résilience en cas de défaillance de nos agents agrégateurs.
Comme toute architecture, il est nécessaire de voir quels seront les compromis que vous concédez pour choisir la meilleure façon de déployer vector dans vos infrastructures (résilience, évolutivité, simplicité etc.).
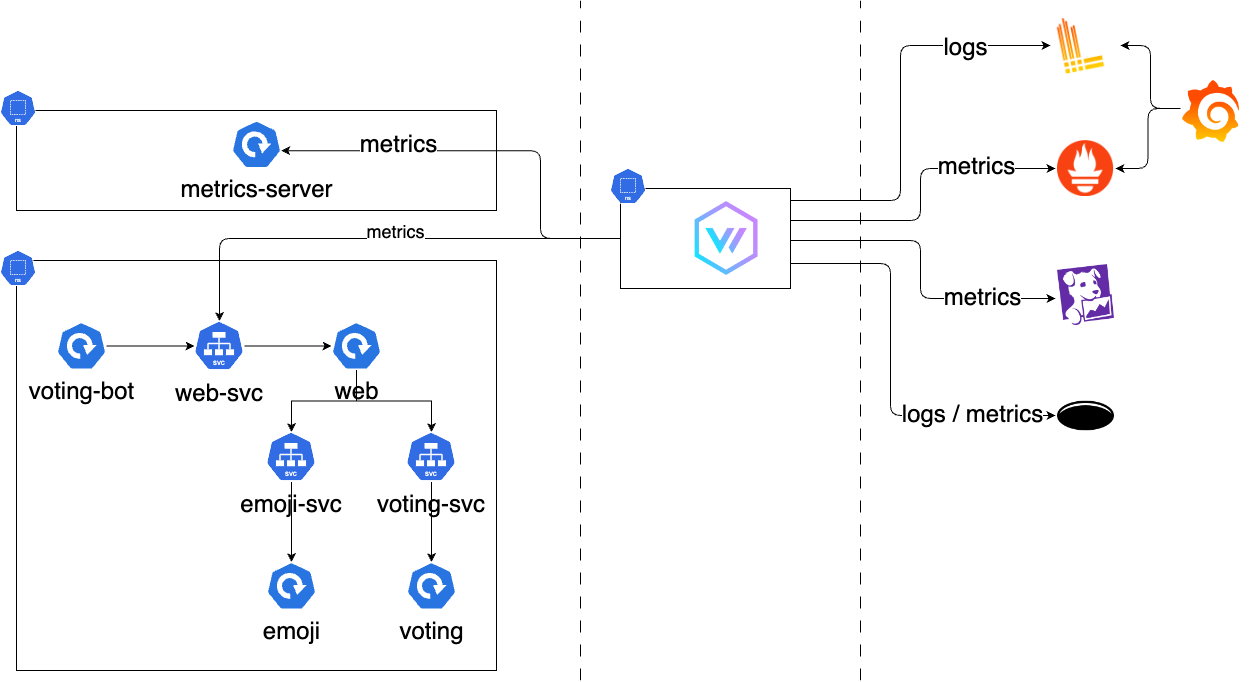
Architecture de la démo
Pour illustrer cet article, nous allons déployer le projet emojivoto sur un cluster Kubernetes. Puis, nous utiliserons Vector pour :
Emojivoto est un simple projet développé par Buoyant pour illustrer le déploiement du service mesh Linkerd. Cette application est une application web simple développée en Go et qui permet de voter pour un ou plusieurs emojis soit via une API Rest soit par gRPC.
Cette application expose des métriques au format prometheus sur le endpoint /metrics.
Pour l'installer sur le cluster, il suffit d'exécuter la commande suivante dans votre terminal :
curl --proto '=https' --tlsv1.2 -sSfL
https://run.linkerd.io/emojivoto.yml \
| kubectl apply -f -
Puis une fois déployée, vous pouvez y accéder via un transfert de port à l'aide de la commande suivante :
kubectl -n emojivoto port-forward svc/web-svc 8080:80
puis aller sur le site http://localhost:8080 pour voir la page de l'application
Emojivoto homepage
Vector peut être déployé via le chart Helm officiel. La configuration des pipelines se fait directement dans le fichier values.yaml.
Pour des raisons de sécurité, Vector permet de récupérer les clés d'API depuis un secret. Il est alors nécessaire de le créer avant le déploiement de la charte Helm sur notre cluster.
Dans notre exemple, nous voulons envoyer les métriques à la fois dans Datadog et dans Grafana Cloud. Il est alors nécessaire de récupérer des clés d'API et de générer le secret associé.
kubectl create secret generic vector \
--namespace vector \
--from-literal=datadog_api_key=XXX \
--from-literal=grafana_cloud_api_key=YYY \
--from-literal=grafana_cloud_prometheus_user=ZZZ \
--from-literal=grafana_cloud_loki_user=WWW \
--from-literal=grafana_cloud_prometheus_endpoint=https://...grafana.net/api/prom/push \
--from-literal=grafana_cloud_loki_endpoint=https://....grafana.net
Le chart Helm est disponible ici: https://helm.vector.dev
helm repo add vector https://helm.vector.dev
helm repo update
Nous pouvons alors déployer Vector sur notre cluster avec les valeurs suivantes :
image:
repository: quay.io/domino/vector
tag: 0.26.X-distroless-static
env:
- name: GRAFANA_CLOUD_PROMETHEUS_USERNAME
valueFrom:
secretKeyRef:
name: vector
key: grafana_cloud_prometheus_user
- name: GRAFANA_CLOUD_LOKI_USERNAME
valueFrom:
secretKeyRef:
name: vector
key: grafana_cloud_loki_user
- name: GRAFANA_CLOUD_API_KEY
valueFrom:
secretKeyRef:
name: vector
key: grafana_cloud_api_key
- name: GRAFANA_CLOUD_PROMETHEUS_ENDPOINT
valueFrom:
secretKeyRef:
name: vector
key: grafana_cloud_prometheus_endpoint
- name: GRAFANA_CLOUD_LOKI_ENDPOINT
valueFrom:
secretKeyRef:
name: vector
key: grafana_cloud_loki_endpoint
- name: DATADOG_API_KEY
valueFrom:
secretKeyRef:
name: vector
key: datadog_api_key
service:
enabled: true
serviceHeadless:
enabled: true
customConfig:
sources:
host_metrics:
type: host_metrics
vector_metrics:
type: internal_metrics
emojivoto_metrics:
type: prometheus_scrape
endpoints:
- http://emoji-svc.emojivoto.svc.cluster.local:8801/metrics
scrape_interval_secs: 60
fake_logs:
type: demo_logs
format: apache_common
transforms:
add_mandatory_tags:
type: remap
inputs:
- host_metrics
- emojivoto_metrics
- vector_metrics
source: |-
.tags.environment = "demo"
del(.tags.host)
.tags.host = "demo-vector"
apache_logs_to_json:
type: remap
inputs:
- fake_logs
source: |-
. = parse_apache_log!(.message, format: "common")
apache_json_logs_remove_user:
type: remap
inputs:
- apache_logs_to_json
source: |-
del(.user)
apache_json_logs_to_metric:
type: log_to_metric
inputs:
- apache_json_logs_remove_user
metrics:
- type: counter
field: status
name: response_total
namespace: front
tags:
host: demo-vector
environment: "demo"
status: |-
metrics_aggregate:
type: aggregate
inputs:
- apache_json_logs_to_metric
sinks:
grafana_cloud:
type: prometheus_remote_write
inputs:
- add_mandatory_tags
endpoint: ${GRAFANA_CLOUD_PROMETHEUS_ENDPOINT}
healthcheck:
enabled: false
auth:
strategy: basic
user: ${GRAFANA_CLOUD_PROMETHEUS_USERNAME}
password: ${GRAFANA_CLOUD_API_KEY}
datadog:
type: datadog_metrics
inputs:
- add_mandatory_tags
default_api_key: ${DATADOG_API_KEY}
site: datadoghq.eu
loki:
type: loki
inputs:
- apache_json_logs_remove_user
auth:
strategy: basic
user: ${GRAFANA_CLOUD_LOKI_USERNAME}
password: ${GRAFANA_CLOUD_API_KEY}
endpoint: ${GRAFANA_CLOUD_LOKI_ENDPOINT}
healthcheck:
enabled: false
encoding:
codec: json
labels:
cluster: minikube-local
trash:
type: blackhole
inputs:
- metrics_aggregate
Il ne reste plus qu'à déployer Vector avec le chart Helm :
helm install --namespace vector \
vector \
vector/vector \
--values ./values.yaml
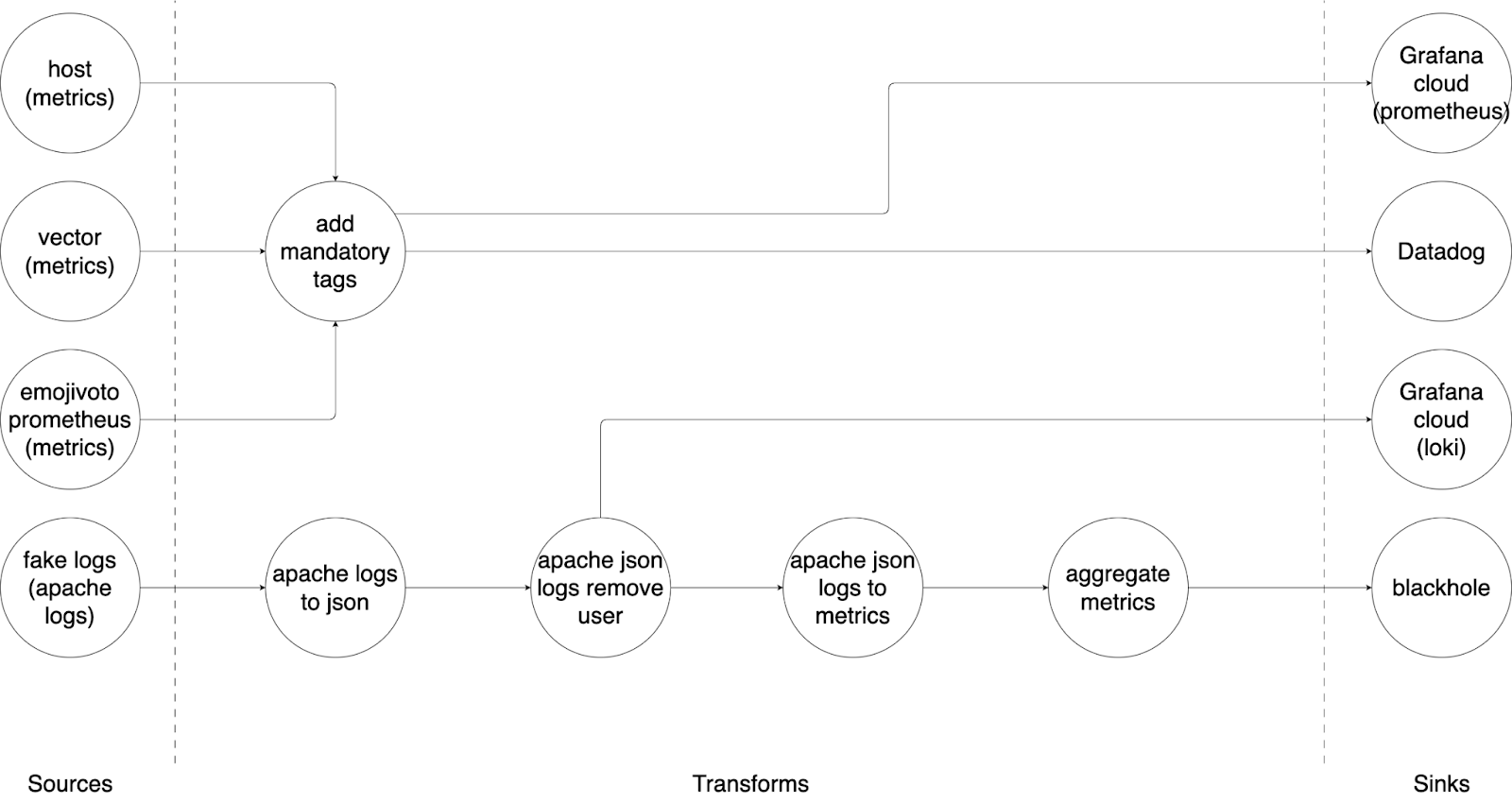
Déchiffrons la configuration de nos pipelines
Pipeline d’observabilité de la démo
Nous avons défini quatre sources de données que nous aimerions traiter, à savoir :
Nous définissons les traitements à effectuer sur nos sources de données :
Enfin, nous pouvons définir les destinations vers lesquelles seront envoyées les données.
Dans les pré-requis de cet outil, il est mentionné que les traitements sont consommateurs de CPU. En effet, voici les chiffres théoriques du débit de données par vCPU (1 CPU ARM ou 0.5 CPU x86)
|
Mesure |
Taille du message |
Vector Throughput |
|
Unstructured log |
~256 octets |
~10 Mib/s/vCPU |
|
structure log |
~768 octets |
~25 Mib/s/vCPU |
|
Métrique |
~256 octets |
~25 Mib/s/vCPU |
|
Trace span |
~1Ko |
~25 Mib/s/vCPU |
Des tests sont nécessaires pour ajuster la taille des instances dédiées. Ainsi, la documentation officielle recommande au minimum 8 vCPU et 16 Gib (2 Gib / vCPU) à savoir les types d’instances suivantes:
|
Cloud Provider |
Type d’instance |
|
AWS |
c6i.2xlarge (recommended) or c6g.2xlarge |
|
Azure |
f8 |
|
GCP |
c2 (8 vCPUs, 16 GiB memory) |
Vector propose ainsi un projet pour réaliser des benchmarks. Ce projet permet de déployer une instance EC2 et de réaliser ces tests de performances.
|
Tests |
Vector |
FluentBit |
Logstash |
|
TCP to blackhole |
86 mib/s |
64.4 mib/s |
40.6 mib/s |
|
File to TCP |
76.7 mib/s |
35 mib/s |
3.1 mib/s |
|
Regex parsing |
13.2 mib/s |
20.5 mib/s |
4.6 mib/s |
|
TCP to HTTP |
26.7 mib/s |
19.6 mib/s |
2.7 mib/s |
|
TCP to TCP |
69.9 mib/s |
67.1 mib/s |
70.4 mib/s |
Je reprends les résultats de ces tests de performance. Pour plus de précisions, je vous convie à aller sur le dépôt GitHub de Vector.
D'autres tests de performances sont disponibles. Je vous recommande l'article de Ajay Gupta de la société IBM Cloud sur une comparaison entre Vector, Fluent Bit et Fluentd.
Après avoir expérimenté Vector sur plusieurs cas d'utilisation, c’est une solution élégante pour définir ses pipelines de données d'observabilité. Il est capable d'ingérer des données issues de différentes sources et peut les envoyer vers différentes destinations. Néanmoins, j'ai rencontré des difficultés à l'intégrer avec différentes solutions. Par exemple, je n'ai pas réussi à récupérer les logs envoyés par l'agent Grafana car cette fonctionnalité est absente. De même, d'autres sources sont encore en alpha ou béta. Ainsi, il n'est pas possible de s'interfacer avec l'agent OpenTelemetry pour récupérer les métriques ou les traces.
La documentation du projet est riche et c'est une des forces de cet outil. Les différents exemples permettent de comprendre et utiliser le langage VRL pour des cas d'utilisation courants.
Même si Datadog l'intègre dans sa suite avec la notion de pipelines, le développement du produit continue mais suit la roadmap définie par les cas d'utilisation des clients de Datadog. Ainsi, la vue pipeline d’observabilité propose de manière graphique de les construire et leur observabilité.
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...

La mesure de la consommation énergétique des applications est un sujet d’actualité, d’une part pour en prendre conscience et d’autre part pour...

Gérer ses dotfiles sur plusieurs environnements Un gestionnaire de dotfiles devient légitime dès lors que l’on jongle entre différents...