

Sommaire
Licence Oracle Cloud : Nouvelle politique d’utilisation
Ceux qui utilisent Oracle connaissent bien les prix de leur ‘consommation’, calculés à base de nombre de Coeur (Core CPU). Ces prix étant déjà compliqués à gérer pour les serveurs dédiés, cela l’est d’autant plus pour l’univers du Cloud. Leur nouvelle politique de licence apporte beaucoup plus d'éclaircissement sur les vCPU des différents fournisseurs. Notamment, pour AWS, 1 vCPU possède 1 Intel hyper-thread, il en faut donc 2 pour faire un Core. Tel n’est pas le cas côté Azure qui ne possède pas d’hyper-threading. De ce fait, un vCPU égale à un Core.
Il faudra cependant faire attention au tableau des facteurs de Core où certaines de ces notes ne sont pas applicables pour le Cloud, ce qui risque de doubler le prix par rapport à un serveur dédié.
Sécurisez votre infrastructure, façon GCP
Les ressources que vous utilisez ou les données que vous stockez sont primordiales pour votre business. Chacun possède ses méthodes de protection d’infrastructure et cela va de même pour les Clouds publics tels que Google. Fin janvier, l’équipe de sécurité de GCP a regroupé dans un livre blanc les stratégies qu’ils ont adoptées pour sécuriser l’ensemble de leur infrastructure. En commençant par l’accès à leur Datacenter, ils décrivent leur gestion des chiffrements et l’intégrité des données, pour terminer par une vue sur le fonctionnement de gestion d’identités autour des différents services que comporte leur plateforme.
Afin de suivre leur avancement autour de la sécurité, GCP propose maintenant de suivre leurs mises à jour directement sur leur blog avec le label Security and Identity.
Docker 1.13

Docker continue son rythme de release soutenu. Dans cette nouvelle version de nombreux outils attendus, pratiques ou simplifiés sont de sortie. L’intégration de Swarm dans DockerCompose permettra de simplifier et d’accélérer encore son utilisation et encouragera les discussions autour de son intégration directement dans Docker. La version propose de nouveaux verbes et une réorganisation des commandes pour une meilleure expérience utilisateur en ligne de commande, bien sûr les anciennes commandes restent pour le moment supportées. Une autre nouveauté attendue depuis longtemps est la gestion des secrets. Enfin, des outils de cleanup sont également disponibles et vont remplacer les scripts que tous les utilisateurs de Docker avaient dans leurs favoris.
Update Hashicorp : Terraform et Consul

Hashicorp annonce les mises à jour de Terraform et Consul qui passent respectivement aux versions [v0.8.5](https://www.hashicorp.com/blog/terraform-v085.html) et [v0.7.3](https://www.hashicorp.com/blog/consul-v073.html). Après plus de 50 corrections de bugs, ainsi que de nouvelles ressources pour AWS et GCP, Terraform supporte à présent 3 nouveaux providers Cloud :
- ProfitBriks
- AliCloud
- NS1.
Consul apporte également son lot de nouvelles features autour de la gestion des key/value et des metadatas lors des entrées KV. De plus, chaque agent Consul possède maintenant un identifiant, généré lors de son lancement. Cela permettra alors de les retrouver plus facilement même après un changement de configuration (nom, adresse, ...).
RethinkDB
La base de données NoSql RethinkDB est désormais disponible en licence Apache et sous la gouvernance de la Linux Foundation après la cessation des activités commerciales de la compagnie du même nom. En effet suite aux turpitudes qui ont conduit à l'arrêt de l’activité commerciale, La Cloud Native Computing Fondation (CNCF) a racheté le code rethinkDB et a mis à disposition de la communauté le code source sous licence “Apache” ( anciennement AGPL).
RethinkDB est une Base de donnée NoSql orientée document (à la MongoDb), conçue pour le real time web. Les points forts de rethinkDB sont :
- Query language
- Realtime web : capacité de push (json) vers un client web.
- Clustering
- GUi d’administration puissante.
- Websocket technologie
Les use cases courants sont : connected devices (iot), stream analytics, mobile, time series, location-aware apps etc ...
Le dénouement heureux, concrétisé par l'hébergement du projet à la Linux Foundation a été accueilli de manière positive par la communauté, qui s’est déjà mise au travail pour effectuer la release de RethinkDB en version 2.4 .
Le projet est disponible sur Github : https://github.com/rethinkdb/rethinkdb
RethinkDB a également permis l'émergence du framework web open source Horizon basé sur un backend NodeJS+RethinkDB, pour simplifier le développement d’application web real time avec les websockets.
Le serverless Computing
Janikaramm MSV, certifié sur les 3 principales plateformes de cloud, définit dans l’article de thenewstack les 10 caractéristiques principales que doivent proposer, à son avis, les offres serverless (autrement appelé FaaS) chez nos fournisseurs de cloud préférés. Au programme : différents langages de programmation, le support des APIs, etc … Ceci constitue donc pour les utilisateurs une checklist pour faciliter le choix d’une plateforme serverless.
Redhat Openshift 3.4 est de sortie

Avec cette nouvelle version, Redhat entend faciliter encore l’adoption des conteneurs dans les entreprises. Le PaaS de la firme au chapeau rouge embarque désormais Kubernetes 1.4. Parmi les nouveautés mises en avant, nous retiendrons :
L’amélioration de l’intégration de Gluster FS avec désormais la possibilité de faire de l’allocation de stockage dynamique pour les conteneurs. Cette solution repose sur le Red Hat Gluster Storage la solution Software Defined Storage de Red Hat.
Plus de multi-projets, avec l’enrichissement de l’interface pour aller à la recherche de projets particuliers et obtenir la description de chacun. Mais c’est aussi la possibilité de mieux isoler les projets hébergés sur la plateforme en reposant sur les namespaces Kubernetes. Chaque projet peut désormais évoluer dans son propre environnement.
L’hybridation cloud public/cloud privé est aussi de la partie avec la mise à disposition d’architectures de référence permettant de réaliser des déploiements mêlant AWS, Google Cloud, Azure, VMWare, et OpenStack.
Un retour d’expérience sur Firebase

La startup Crisp qui fournit un service de chat en ligne a publié un article racontant son expérience avec Firebase la base de données pour le realtime web de Google.
Ils expliquent comment la solution est passée à leurs yeux de l’outil magique leur permettant de finaliser un MVP en 3 semaines au cauchemar de la production quelques mois plus tard.
Parmi les retours, ils nous parlent de problèmes de performance sous forte volumétrie lorsque la startup a été mise en avant sur Product Hunt. Retenez bien que Firebase a des limites techniques en matière de scalabilité et de performance.
Un autre point, pour nos amis développeurs, est le côté spaghetti code. En effet, l'accès à la base se fait côté client, ce qui signifie bien sûr plus de code dans les frontaux et applications mobiles. Cela implique aussi et surtout un problème potentiellement explosif lors des mises à jour du modèle en base de données. Comment garantir que tous vos clients déployés sont bien capables de travailler avec le nouveau modèle ?
L’utilisation côté backend est manifestement elle aussi problématique, dans un contexte micro-services car les performances se dégradent très vite avec le nombre d’instances de service qui grandit depuis un même accès réseau.
Nous ne ferons pas ici la liste complète des retours de Crisp, qui parlent aussi du pricing, de problèmes d'inconsistance lorsque les clients passent offline, de l’impossibilité de faire des requêtes paginées et bien d’autres encore liés à la pauvreté du langage de requête.
Attention tout de même, une note positive pour finir, les équipes Google cherchent en permanence à améliorer leur produit et ont sauté sur l’occasion pour discuter avec l’équipe de Crisp. Pour Crisp, Firebase reste un très bon produit, mais qu’il ne faut pas utiliser comme base de données principale.
Une base SQL ACID scalable à l’infini chez Google c’est Spanner

Dans son théorème de CAP Eric Brewer, directeur des infrastructures Google, l’a bien dit:
il est impossible sur un système informatique de calcul distribué de garantir en même temps (c'est-à-dire de manière synchrone) les trois contraintes suivantes :
Cohérence (ou consistance des données) (Consistency en anglais) : tous les nœuds du système voient exactement les mêmes données au même moment;
Disponibilité (Availability en anglais) : garantie que toutes les requêtes reçoivent une réponse;
Tolérance au partitionnement (Partition Tolerance en anglais) : aucune panne moins importante qu'une coupure totale du réseau ne doit empêcher le système de répondre correctement (ou encore : en cas de morcellement en sous-réseaux, chacun doit pouvoir fonctionner de manière autonome).
Et pourtant, voilà Google qui nous propose son nouveau service Spanner dont voici les fonctionnalité en image :
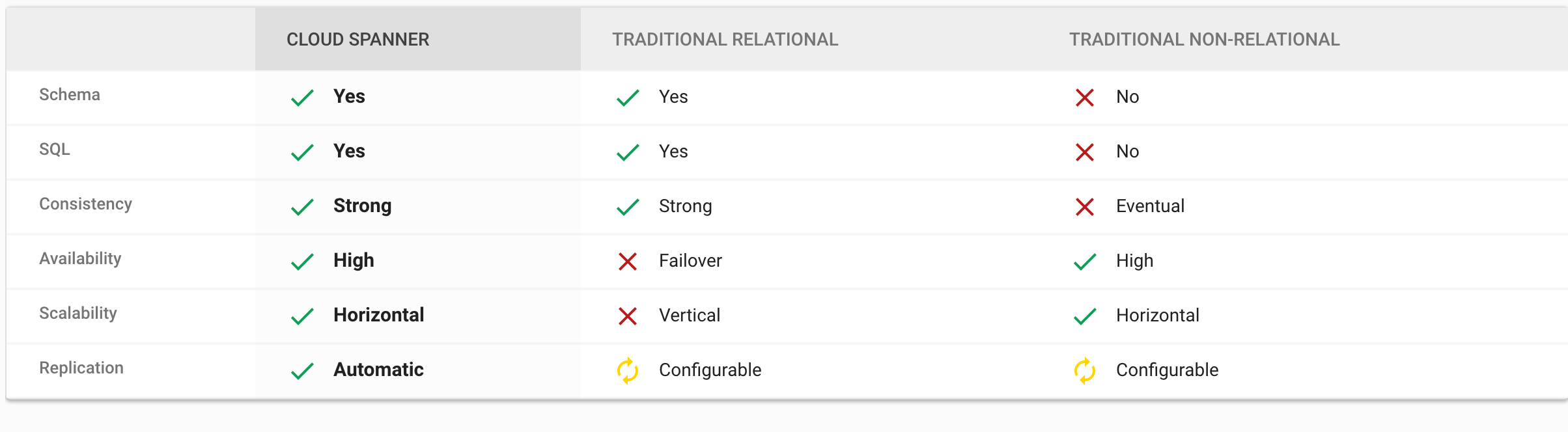
Le service est directement issu de l’expérience de Google sur AdWords, son offre de publicité. La promesse est belle : ne choisissez plus entre scalabilité et transaction, faites du SQL standard (ANSI 2011) avec des performances à la milliseconde et une disponibilité de 99.999%. Vous l’aurez compris, Spanner ne remet pas réellement en cause le théorème de CAP, il s’agit en fait d’une base consistante et tolérante au Partitionnement réseau donc CP.
Avec Spanner, Google fait trembler le monde des NoSQL devenus standards de-facto pour adresser la scalabilité horizontale.
Un produit à tester au plus vite, pour vérifier que le service est à la hauteur de la promesse.



