 Bastien Cadiot
Bastien Cadiot


Dans notre premier article nous avons créé une machine virtuelle et démarré un serveur web. Cette solution fonctionnait bien mais n’est pas résiliente à une panne, ni à une montée en charge du trafic. Je vous invite à me suivre dans la mise en place de mécanismes simples pour couvrir ces risques.
Créer et instancier un modèle de serveur reproductible
Alors que nos premiers serveurs étaient démarrés directement, cette fois nous allons devoir procéder en deux temps : d’abord définir un modèle de déploiement qu’on pourra lancer autant de fois que nécessaire, puis nous le déploierons sur toutes les régions souhaitées.
Préparer le modèle
La préparation du modèle ressemble fortement à la création d’une simple machine virtuelle. En effet, les étapes sont exactement les mêmes sauf qu’on ne lance pas d’instance à la fin.
Nous allons donc reprendre la même configuration que lors de notre premier article à la différence qu’on ne spécifie pas la région de déploiement. Nous modifions également le script de démarrage afin que le nom de la région de déploiement apparaisse sur la page web (nous utilisons le serveur de métadonnées propre à la machine virtuelle). La création des modèles se fait ici.
#!/bin/bash
yum install -y httpd
systemctl start httpd
zone=$(curl http://metadata.google.internal/computeMetadata/v1/instance/zone -H "Metadata-Flavor: Google" | cut -d"/" -f4)
echo "Hello GCP FromScratch from $${zone}" > /var/www/html/index.html
Notre modèle est prêt, continuons avec son instanciation.
Note : sachez qu’il était possible également de créer une “golden image”. Ce type de déploiement permet de gagner beaucoup de temps au démarrage des instances. L’objectif est de construire une image où toutes les installations ont déjà été réalisées, ainsi le modèle utilisera cette image et le script de bootstrap sera fortement réduit (voire inexistant !).
Déployer les Instances Groups
Dans l'environnement Google Cloud, un groupe d'instances permet, comme son nom l’indique, de grouper les instances dans une unité logique. Ce groupement peut être de deux types : géré ou non géré.
La différence entre ces deux types est la présence ou non d’ajouts (addons) permettant de réaliser des adaptations dynamiques du groupe.
Parmi ces ajouts, on citera les tests de vie et l’autoscaling. L’idée est justement de bénéficier de ces ajouts pour rendre notre déploiement résilient aux pannes et auto adaptatif aux variations de charge. La gestion des Instances Groups se fait ici.
Pour notre test, nous allons créer trois “Instances Groups” qui seront répartis en Belgique (région europe-west1), en Californie (région us-west1), et au Japon (région asia-northeast1).
Pour chacun de ces groupes, nous allons mettre en place un test de vie sur le port 80 des instances, ainsi toute panne sera détectée et réparée.
Pour terminer, nous allons activer l’autoscaling basé sur le nombre de requêtes par seconde. L’idée est de s’assurer que chaque instance ne va gérer qu’un nombre déterminé de requêtes (10 en l’occurrence) et que tout dépassement provoquera le lancement automatique de nouvelles instances.

Nos groupes sont créés, et les instances déployées. Techniquement, le service est actif, géographiquement distribué et s’adapte au trafic.
Néanmoins, comme vous pouvez le voir, nos groupes sont en erreur. Cela est lié au fait que nous avons activé l’autoscaling sur la charge du répartiteur mais que nous n’avons pas encore configuré ce composant.
Répartir le trafic sur tous nos serveurs
Même si nos instances sont déployées, il reste maintenant à fournir un mécanisme d'accès cohérent et conscient de l’état de la plateforme.
Déployer un répartiteur de charge devant nos instances
Lors du précédent article nous avons évoqué les répartiteurs de charge gérés par Google Cloud, n’hésitez pas à vous faire un petit rappel ici. Pour toutes les étapes suivantes c’est ici que ça se passe.
Comme notre service est un service web, et est accessible depuis l’extérieur, nous allons choisir le répartiteur HTTP. Ce dernier nous permettra de nous distribuer sur tous nos groupes d'instances et ainsi diriger nos clients vers le groupe le plus proche d’eux.
Notre répartiteur va être composé de deux éléments, une partie “Frontend” servant de point d'entrée commun à tout le monde, et une partie “Backend” agrégeant l’ensemble de nos Instances Groups.
La partie frontale utilise le protocole HTTP sur le port 80, et nous allons réserver une IP statique.
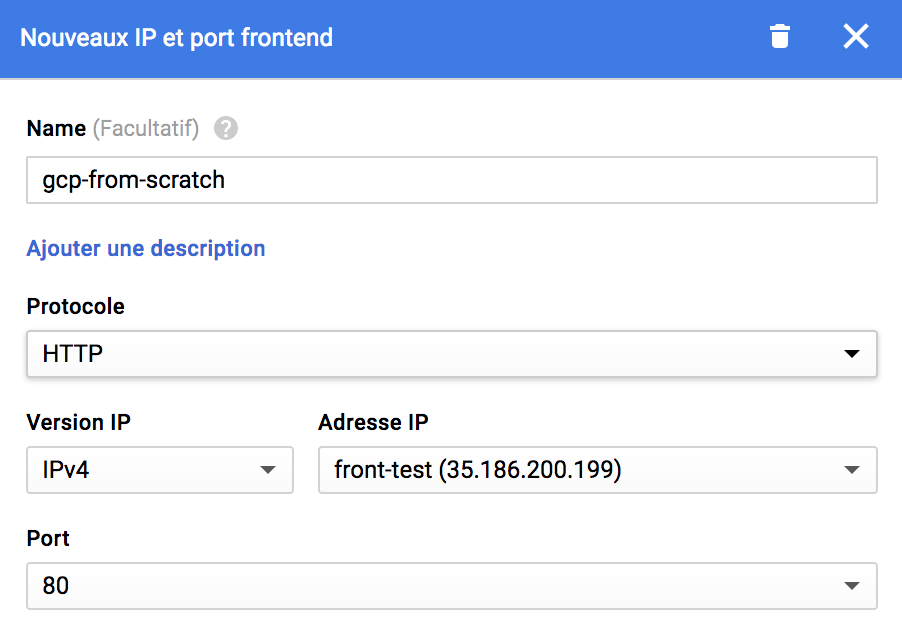
La partie backend permet de gérer plusieurs éléments suivant l’url d'accès. Il s’agit typiquement des architectures microservices. Comme nous n’utilisons pas ce type d'architecture, nous créons simplement un service backend par défaut qui peut gérer toutes les URL. Nous ajoutons tous les Instances Groups ainsi que les tests de vie, toujours sur le port 80, n’oublions pas également de reporter les valeurs des seuils d’équilibrage !
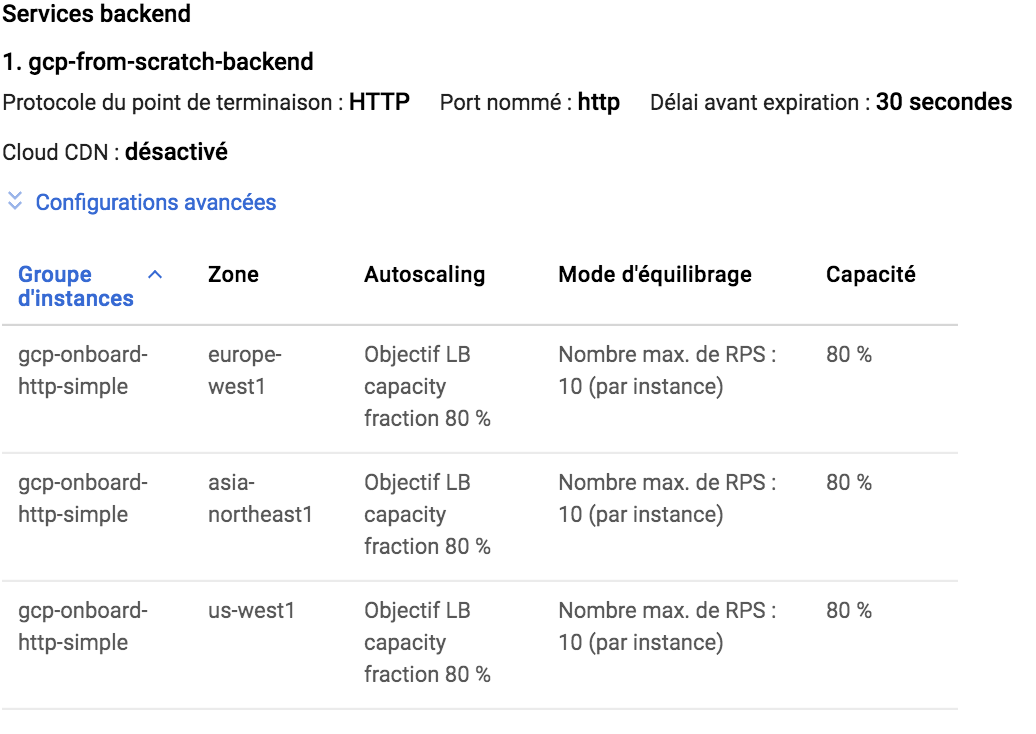
Après la création de notre répartiteur de charge, ce dernier communiquera avec les groupes d’instances pour vérifier leur état et leur permettre de gérer l’autoscaling suivant le nombre de requêtes envoyées par seconde.
Tester les pannes et l’évolution de la charge
Les services sont déployés, mais il ne faut pas négliger la phase de test afin de s’assurer que l’ensemble fonctionne comme souhaité.
Nous allons consulter directement le trafic sur le backend, pour cela suivez ce lien.
Panne simple d’un serveur web
Commençons par une étape simple, simulons une panne d’un des serveurs web. Pour cela rien de plus simple, il suffit de se connecter à l’instance et arrêter le service httpd :
sudo systemctl stop httpd
Au bout de quelques secondes la panne sera détectée et le groupe d’instances va procéder au remplacement de l'instance. Si dans l’intervalle vous essayez d’accéder à votre application via le répartiteur de charge, vous pourrez observer que la page a changée :
Hello GCP FromScratch from asia-northeast1-a
[OU]
Hello GCP FromScratch from us-west1-c
L’instance la plus proche n’est plus disponible, et celle-ci n’a pas encore été remplacée, pour autant hors de question d’interrompre le service. Le répartiteur nous a renvoyé vers le groupe d’instances le plus “proche” de nous. Visiblement, depuis Paris le plus proche peut être alternativement Tokyo ou Los Angeles.
Si nous consultons la répartition du trafic sur notre backend cet état est assez flagrant :
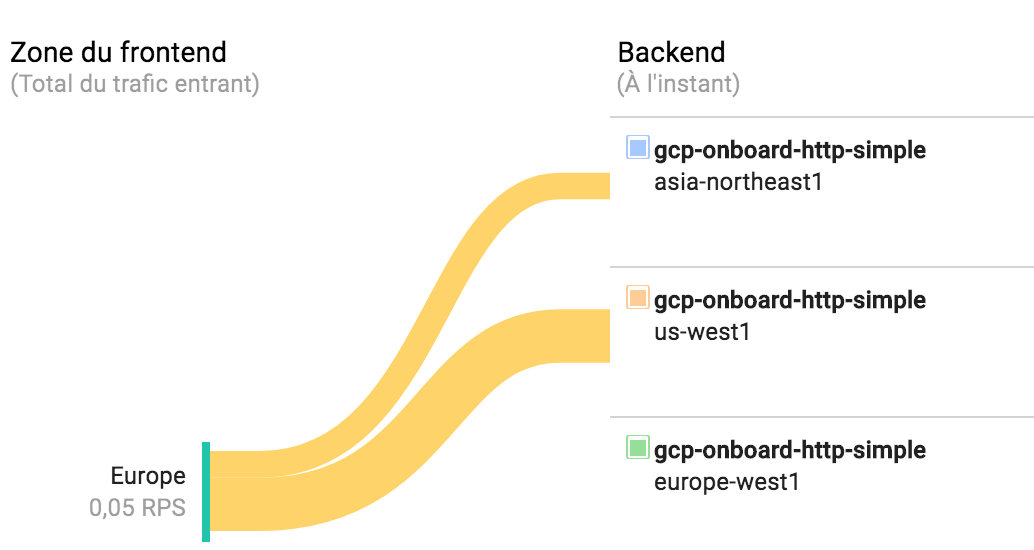
Le trafic en provenance d’europe est bien distribué vers us-west1 et vers asia-northeast1, tandis que europe-west1 ne reçoit plus rien. La couleur jaune indique le trafic n’est pas dirigé vers la région la plus proche.
Au bout de quelques minutes, l’instance défectueuse sera remplacée et le trafic reprendra son chemin normal.
Montée en charge du trafic
Pour les étapes suivantes nous allons avoir besoin de générer un peu de trafic, pour cela je vous suggère d'utiliser un outil comme hey, qui permet de simuler du trafic simple. Par exemple, pour 15 requêtes par seconde sur un seul thread et un total de 54 000 requêtes (cela nous laisse 1h car 15x1x3600 = 54000) :
hey -q 15 -c 1 -n 54000 http://35.227.205.160/
Au bout de quelques dizaines de secondes, le répartiteur constatera que sur la région de destination nous dépassons le nombre de 10 requêtes par seconde que peut gérer l’unique instance déployée par l’Instances Group de la région. Ce dernier entrera en phase d’autoscaling pour s’adapter à la demande.

Tout ceci est possible car le nombre d’instances maximales sur notre groupe d’instances n’a pas été atteint. D’ailleurs, nous voyons que nos 15 requêtes par seconde sont bien absorbées par la région Europe. La couleur verte indique que la région la plus proche est bien utilisée.
Observons ce qu’il se passe si nous allons au-delà de ce nombre maximal. Actuellement, il est défini à 3 instances par région, soit 30 requêtes par seconde, nous allons donc relancer hey pour lancer 50 requêtes afin de dépasser cette limite :
hey -q 50 -c 1 -n 180000 http://35.227.198.185/
Au bout de quelques dizaines de secondes, l’autoscaling se met en place et atteint la limite.
Que se passe-t-il pour notre trafic ? Allons vérifier sur le monitoring du répartiteur :
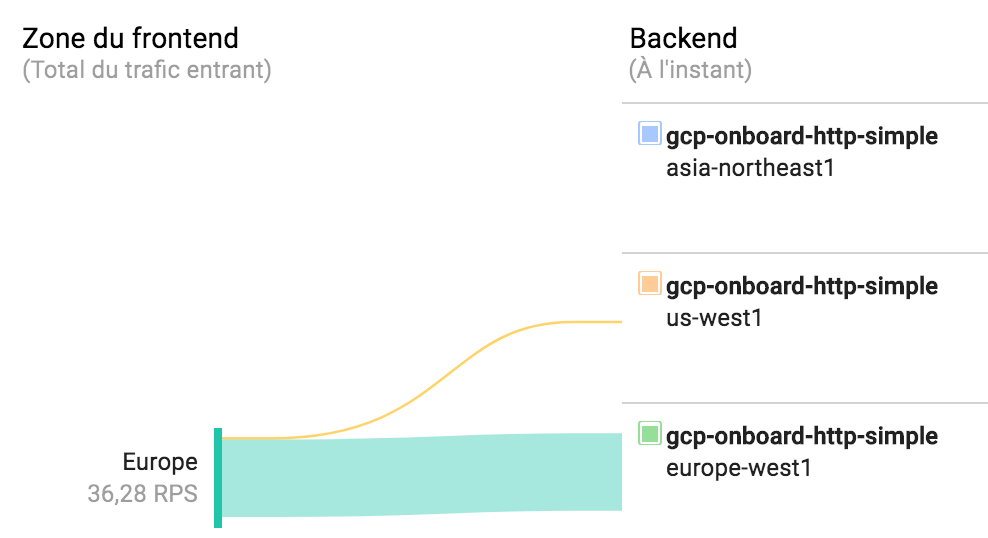
Le trafic en surplus a été automatiquement redirigé vers le groupe d’instances le plus proche pouvant encore accueillir des requêtes !
Ce mécanisme est très pratique car il nous garantit qu’aucune interruption de service ne se produira si une région ne peut plus gérer de trafic supplémentaire que ce soit à cause d’une surcharge ponctuelle ou d’une panne.
Conclusion
Nos services peuvent maintenant résister à la panne et s’adapter à la demande ! Le code de nos exemples est disponible sur GitHub : https://github.com/bcadiot/gcp-from-scratch.
Vous avez des questions ? Vous voulez plus de détails ? N’hésitez pas dans les commentaires de l’article ou via Twitter.
À très vite pour la suite de notre découverte de Google Cloud ! Restez à l’écoute, la prochaine fois nous évoquerons le stockage objet !
Et la saga continue...
A lire et à relire, les articles de la saga "Google Cloud From Scratch".
-Episode 1 : "Commencer par la base"
-Episode 2 : "Parlons Réseau"
-Episode 3 : "Garantir la performance et la stabilité"

